基于轻量级神经网络的农作物病害识别算法
2021-06-07洪惠群黄风华
洪惠群,黄风华
(阳光学院 人工智能学院/空间数据挖掘与应用福建省高校工程研究中心,福州350015)
大多数农作物病害在可见光波段会产生某些可见症状,为人工诊断提供可行性[1]。随着图像处理技术的发展,基于深度学习的图像分析技术常被用于农作物叶片病害检测[2],相较于化学病害检测,它能更早地对早期病害特征进行监测,避免对被测农作物造成不可逆转的破坏[2],减少农药使用[3],利于精准农业的发展。与传统图像识别技术[4-5]相比,将深度学习网络[6-10]运用在农作物病害检测准确性更好,但存储计算开销巨大,使其在低功耗领域的应用严重受限。如何解决深度学习网络部署时移动设备的计算资源紧张[11-14]的技术瓶颈?主要采取将深度学习模型部署在服务器端,返回服务器计算结果给移动设备[15]和精简模型,减少深度学习网络参数量[11]两种方法。后者不依赖网络环境,实时处理效果较好,但准确度相较前者有所降低。为保证深度学习模型能正常运行在移动端,且准确度不大幅丢失,研究人员研究了专门用于移动端设备的轻量级神经网络[16-19]。本研究根据需要对比了多种轻量级网络[16-19]在移动端识别农作物病害的表现。
1 轻量级深度学习算法简介
1.1 ShuffleNet V1和V2网络
ShuffleNet V1[19]是基于逐点组卷积和通道混合构建的。图1 给出了ShuffleNet V1 单元的可视化表示,每个单元都是由Group Convolution(GConv)、Channel Shuffle和Shuffle Net单元3个基本操作[19]。

图1 ShuffleNet V1单元示意图Figure 1 ShuffleNet V1 unit
与AlexNet 网络、ResNet 网络等的其他单元相比,ShuffleNet V1 单元通常具有比较少的计算量,如:ShuffleNet V1 0.5x 仅用40MFLOPs 的计算复杂度,就达到了AlexNet 720MFLOPs的性能[19]。
ShuffleNet V2[20]是改进版本,在文献[20]中,作者提出“设计一个高效网络架构,仅用计算复杂度来衡量是不够的,要遵循的 G1-G4 的 4 个准则”[20]。ShuffleNet V1 网络违反其中G1 G2 准则。因此,作者提出了利用通道分割的操作,构建ShuffleNet V2 网络,其单元如图2。图2a 在每个单元的开始,c 特征通道的输入被分为c-c'通道和c'通道两支[20],其中一个分支保持不变,另一个分支由3个卷积组成,令输入和输出通道相同以满足G1准则。此外,图中两个1×1 卷积,不再是组卷积,因为已通过分割操作产生两个组。卷积之后,把两个分支串联起来,可以使得通道数量保持不变,并通过通道混洗,使两个分支间,能进行信息交流。混洗之后,下一个单元开始运算。
空间下采样单元(图2b),将通道分割运算进行移除,使得输出通道数量翻倍。ShuffleNet V2 网络遵循G1-G4 四个准则,因此架构设计十分高效[20]。本设计的ShuffleNet V2的网络结构图如表1。
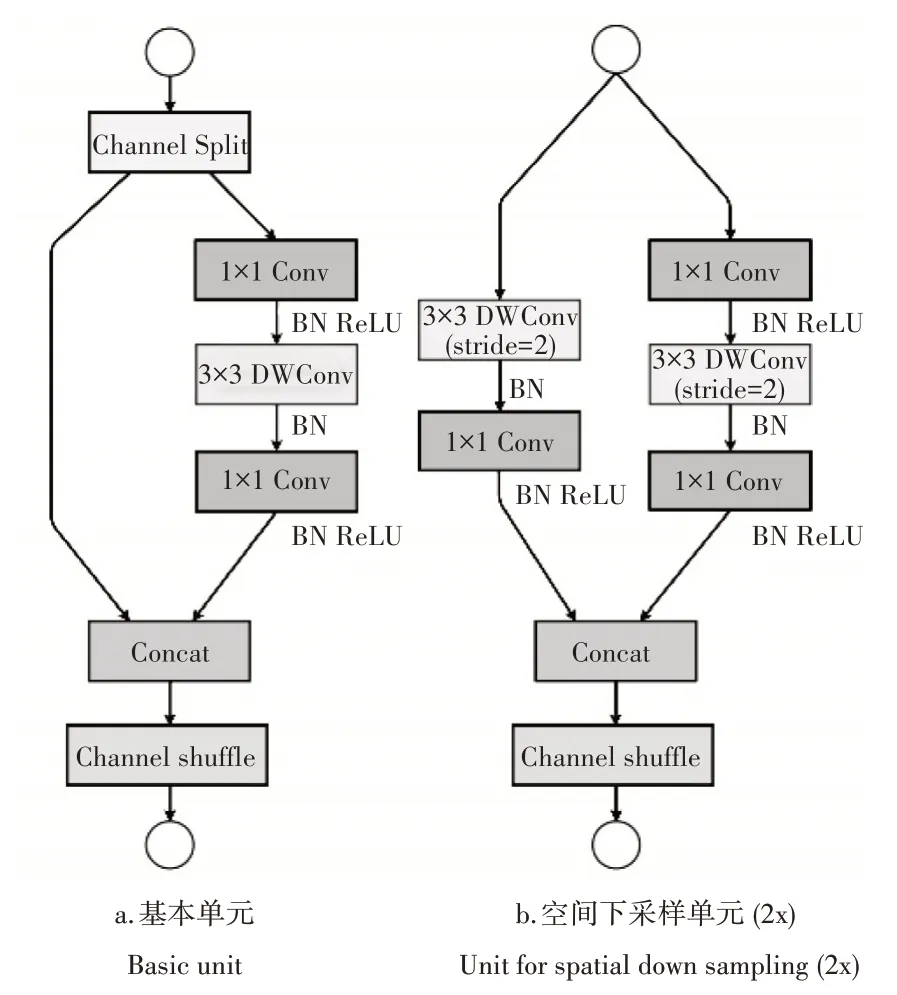
图2 ShufflenetV2 的模块Figure 2 Building blocks of ShuffleNet V2 [20]
1.2 ReLU激活函数和LeakyReLU激活函数
ReLU激活函数是指修正线性单元,只有输入超出阈值时,ReLU的神经元才激活,并且当输入为正的时,导数不为零,因此允许基于梯度的学习。相比Sigmoid/tanh 函数,ReLU 激活函数收敛速度更快。可是,当输入为负值的时候,ReLU激活函数的学习速度可能就会变得很慢,甚至使神经元直接无效,因为此时输入为负值而梯度为零,从而使得其权重无法更新。为解决上述问题,引入带泄露修正线性单元函数,即Leaky ReLU 函数。该函数是在ReLU函数的负值区间,引入一个泄露值(Leaky值),是ReLU函数的变体。Leaky ReLU 函数输出对负值输入有很小的坡度,因此导数总是不为零,能减少静默神经元的出现,可以允许基于梯度的学习。Leaky Re-LU函数数学表达式为:
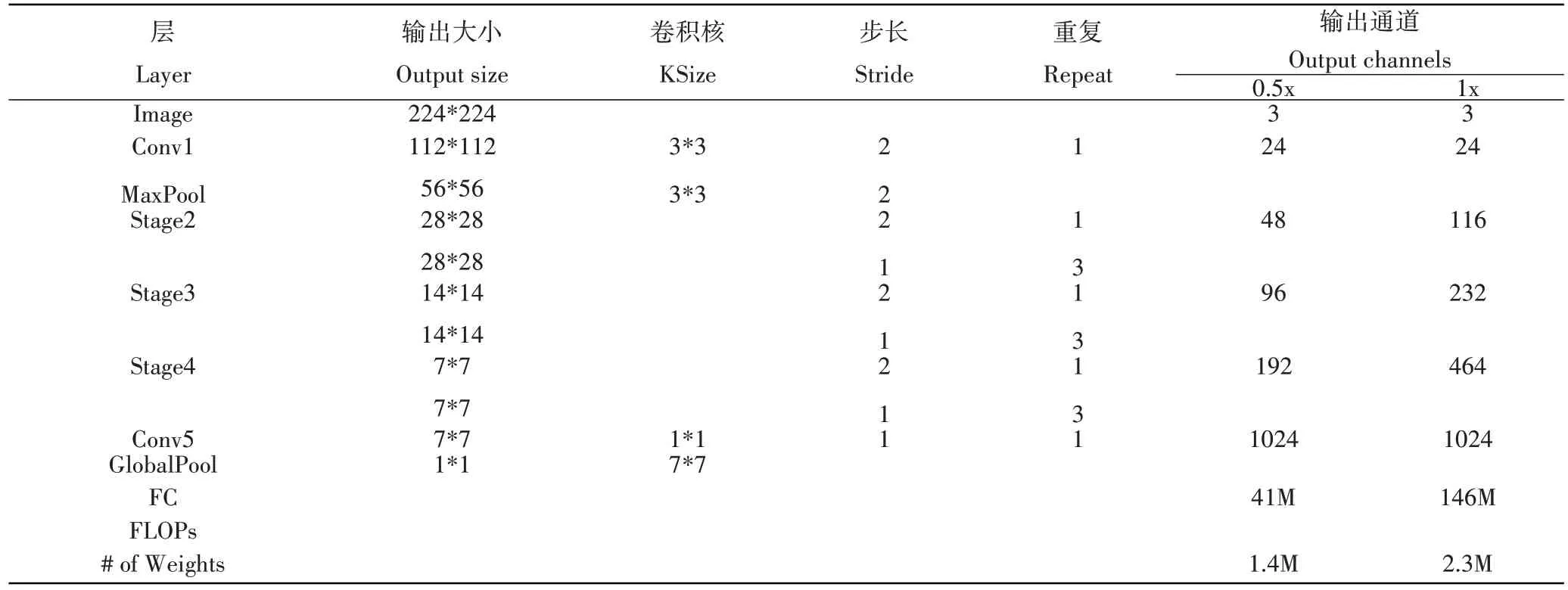
表1 Shufflenet V2的网络结构Table 1 Overall architecture of ShuffleNet V2

式中:ai为(1,+∞)区间内的固定参数;xi为输入;yi为输出。
本研究通过对多种网络结构的迁移学习,研究如何利用轻量级深度学习网络提取农作物图片病害特征,实现对叶片病害图像的精准识别,最后将轻量级深度学习网络ShuffleNet V2 0.5x移植到移动设备端。
2 农作物叶片病害图片数据集
2.1 数据集来源
本研究中病害数据集大部分是从AI Challenger 2018竞赛数据集获取,按照物种、病害程度来分类,剔除两个小样本分类,合计有59个分类,10个物种,26种病害,共45284幅植物叶片图像。为对比分析,将其中的番茄样本(9种病害),共计13112张,另外抽出来做对比数据集。识别过程中,系统将数据集随机分为训练数据集和验证数据集。每张图中主要位置为一片叶子,背景单一。数据集中的部分病害叶片如图3。
2.2 数据预处理
目前,大多数农作物病害识别的研究都是基于深度学习进行的,需要大量的数据样本(大数据集)进行训练、验证,属于高密集计算量的算法,对硬件资源要求高,农作物病害种类比较多,而每一种病在同一个场景下能获得的典型图像数据却不多,也就是小数据集,在无法收集到大量数据样本的情况下,课题组利用迁移学习方法,对大的数据集进行分类预训练,然后微调参数使之适合农作物病害种类的识别,并通过对原始图像数据进行图像增强,扩充农作物数据集,弥补训练数据不足,提高识别准确率。
本研究采用旋转、翻转、模糊、光线变换、随机裁剪、叠加噪声等方法对训练集数据进行扩充,增加数据的多样性,减少训练阶段的过度拟合,以提升网络模型的泛化能力。由于原始图像大小不同,可能含有冗余信息,不利于农作物病害的分类。本研究将叶片的图像样本归一化为224*224*3 像素,并将处理后的图像去均值。扩充后数据集有了显著的增加。以其中的番茄病害数据为例,扩充数据前,训练数据集共计包含13112幅图像,扩充后的数据集大小为41263张图像。算法模型使用图像增强后的图像数据集对模型进行训练。

图3 农作物叶片病害图像示例Figure 3 Example of crop leaf disease symptoms
3 试验结果与分析
3.1 训练及验证过程
本研究是在pycharm 平台下选用Python语言开发的,先使用ImageNet大数据集进行网络预训练,对网络参数进行优化,随后将收集到的农作物病害图像数据集,随机分为训练数据集、验证数据集,并进行图像预处理,接着把训练数据集、验证数据集分别送到各个预训练的深度学习网络,进行训练、验证、优化,使网络模型能够更有效地识别出农作物病害,并达到较高的准确率,对比分析Xception、MobileNet V2、ShuffleNet V1 以及ShuffleNet V2等网络。系统总体框图如图4。本研究中,基于Shuffle Net V2网络的农作物病害识别流程如图5。分别采用ReLU 和LeakyReLU 激活函数进行ShuffleNet V2 网络模型的构建及对比,利用模型迁移完成ShuffleNet V2模型训练及优化。

图4 系统总体框架Figure 4 Overall framework of the system

图5 基于ShuffleNetV2网络的农作物病害识别流程Figure 5 The process of crop disease identification based on ShuffleNet V2 network
3.2 模型结果比较
综合考虑目前安卓手机的性能水平和不同规模下、不同网络的计算复杂度,本研究通过对比了ShuffleNet V1 网络、ShuffleNet V2 网络、MobileNet V2 网络、Xception 网络,在不同规模的计算复杂度、训练准确率、训练损失率和运算速度(表2)。为了更好地比较,结果按照计算的复杂性级别分组,图像尺寸为224*224,GPU批处理大小选择8,ARM批处理大小选择1。由表2可知,Xception 1x在图像识别方面的表现不错,ShuffleNet V1 0.5x(g=3)计算复杂度最小,同时,训练准确率相对较好,ShuffleNet V2 0.5x网络表现相对不错,计算复杂度也比较小。与ShuffleNet V1 0.5x(g=3)相比,ShuffleNet V2 0.5x 模型在ARM 上的表现稍好,因此,本研究将对ShuffleNet V2 0.5x 模型进行移植。MobileNet V2 0.6 网络在ARM 的表现相对比较不好。总体上各个网络的识别准确率还有待提高,这其中跟数据集也有很大的关系,部分分类的训练数据量不够,后续将继续优化完善数据集。
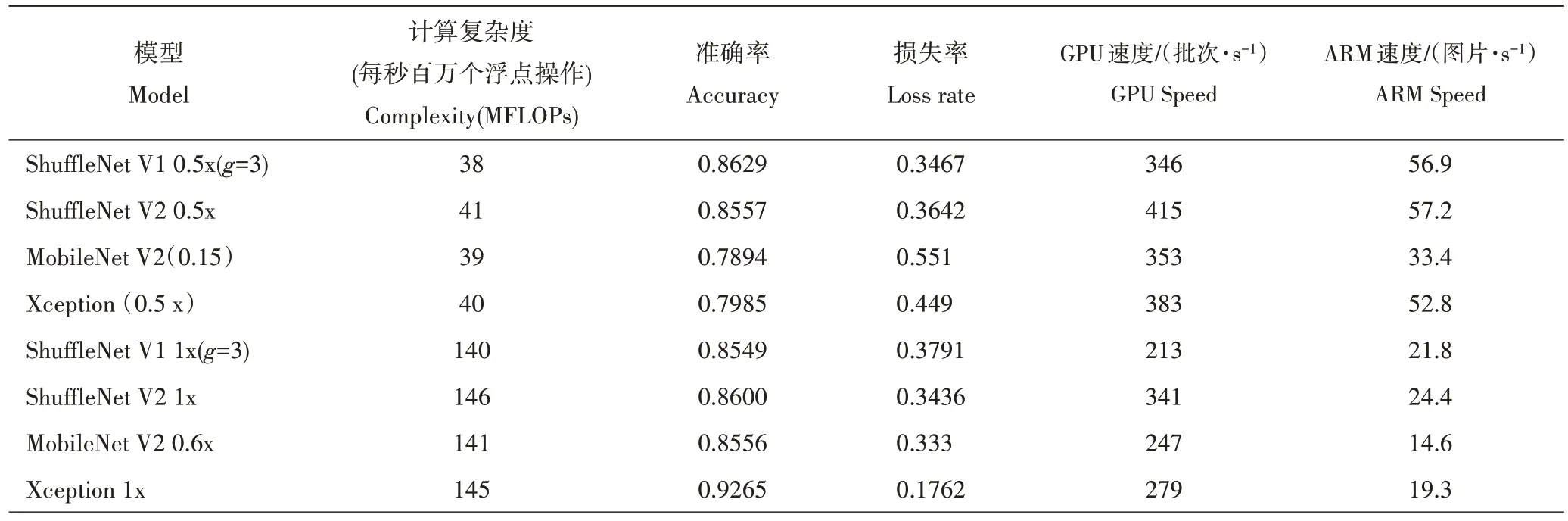
表2 几种网络的计算复杂度、准确率、损失率及速度对比Table 2 Comparison of several network architectures over computing complexity, accuracy,loss rate and speed(the image size is 224 × 224)
为验证分类准确率和数据集的关系,更好地进行对比分析,将其中的番茄样本抽出来做对比数据集。由表3 可知,不同数据集进行模型训练时,准确率不大一样,其中,项目组对番茄病害数据集进行整理,使得每个分类图片数量比较均匀,相较于全部病害的数据集,准确率有所上升。同时,本研究通过多次试验发现,物种的类型和疾病种类的识别准确率比较高,疾病的严重程度的识别准确率相对较低,说明分类错误的部分原因是由于病害的严重程度难以区分。
3.3 模型的改进方案
多种网络比较后,针对选用的ShuffleNet V2 0.5x 模型,笔者进行了改进。对比了LeakyReLU 激活函数和ReLU 激活函数在模型中的表现后,发现LeakyReLU 激活函数能改进当输入为负值时,ReLU 函数的缺陷,并进行相应的测试。由于在深度学习中,对数据集的要求通常是数量庞大的、质量高的,且有标签,自采集的数据集,由于受到人力、物力的影响,往往达不到要求。因此,本研究利用迁移学习技术,在Image Net 数据集上预先进行预训练,以解决上述问题。在迁移学习中,将网络参数前面几层进行固定,最后一层进行微调,以改善因数据集不大造成的模型过拟合问题,并在验证集上进行验证,得到了较好的准确率。预训练后,在自有数据集上分别采用不同的激活函数进行训练。通过对比Leaky ReLU 激活函数和ReLU 激活函数,在ShuffleNetV2模型上的表现,发现采用Leaky Re-LU 激活函数能较好地解决部分落到硬饱和区的输入的对应权重无法更新的问题。在自有数据集上进行训练,采用不同激活函数的训练集与验证集的准确度如图6。由图6 可知,当模型采用ReLU 激活函数,验证集的识别准确度是85.6%,训练集的识别准确度是84.8%,而当模型采用Leaky ReLU 激活函数,训练集的识别准确度是86.5%,验证集的准确度是85.1%。因此,在ShuffleNet V2 网络结构不发生改变的情况下,选用Leaky ReLU 激活函数,可在稍微提高了网络模型的准确度。
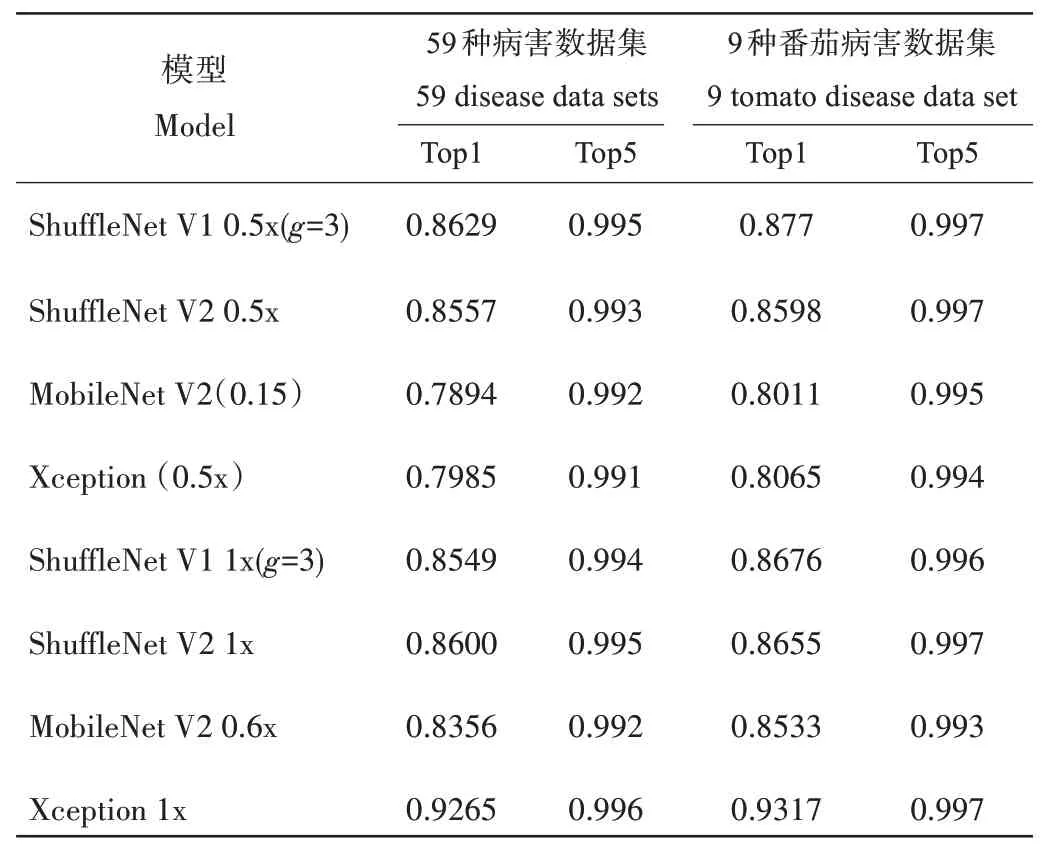
表3 两个数据集在不同网络下的准确率Table 3 Accuracy of the two data sets in different networks
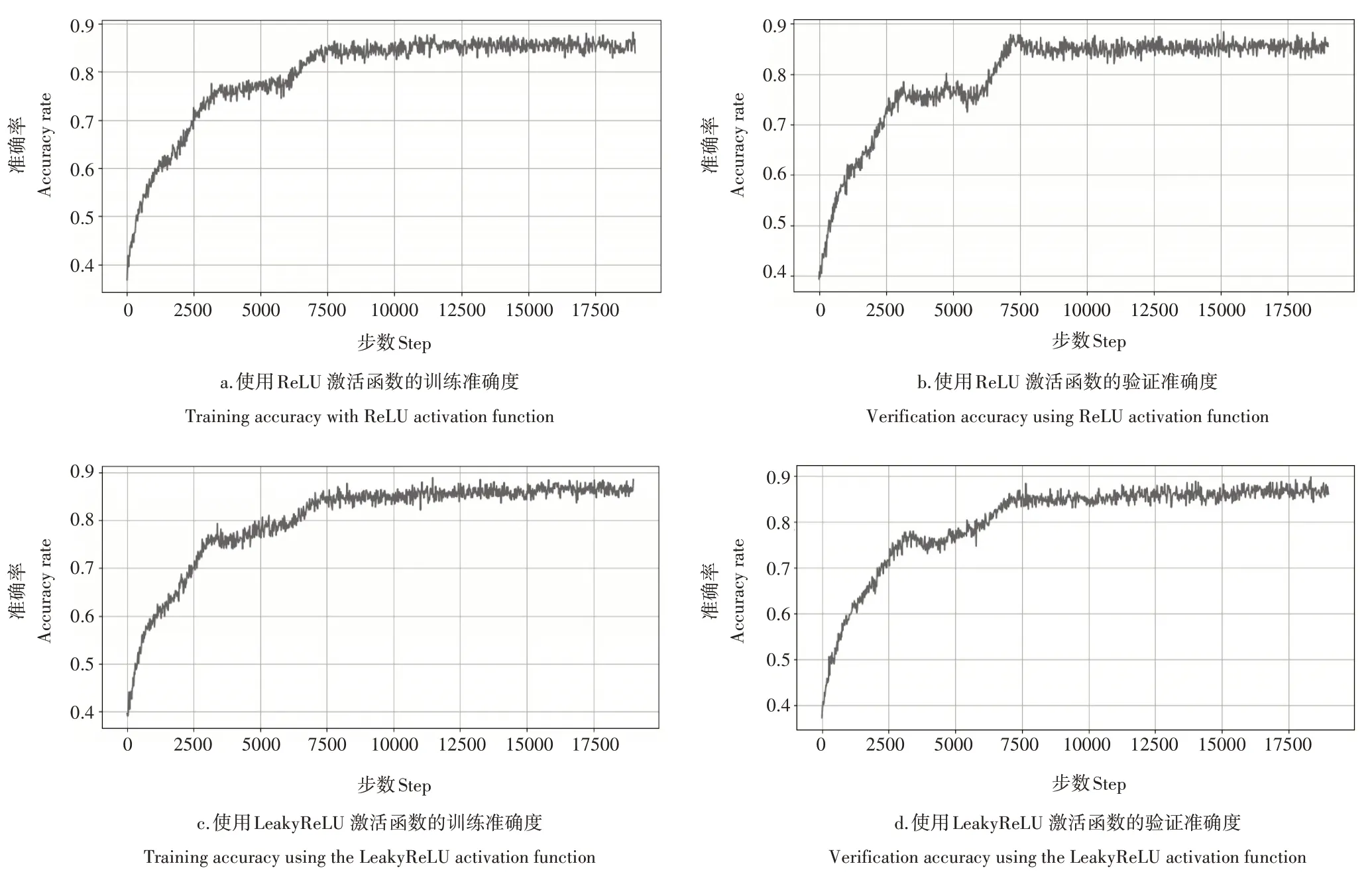
图6 不同激活函数下的训练集与验证集的准确度Figure 6 Accuracy of training sets and verification sets under different activation functions
4 讨论与结论
传统的农作物病害识别主要依赖专业人员进行判断或化学检测[1-3,7],耗时长,成本高,无法广泛推广,基于图像处理的农作物病害识别[4-10]可以实时对早期病害特征进行监测,并能广泛推广,避免对被测农作物造成不可逆转的破坏,利于精准农业的发展。基于图像处理的农作物病害识别分为基于传统图像识别技术[4-5]和基于深度学习的图像识别技术[6-10],其中,后者准确率更高,但对计算机资源要求较高。为更广泛地帮助农民朋友进行农作物病害监测,需要将深度学习网络部署在手机端上,解决移动端资源有限与深度学习网络所需资源巨大的矛盾。目前,主要采取将深度学习模型部署在服务器端,返回服务器计算结果给移动设备[15]和精简模型,减少深度学习网络参数量[11]两种方法,后者不依赖网络环境,实时处理效果较好。因此,本研究采用精简模型,减少深度学习网络参数量的方法,即轻量级别级深层神经网络进行研究。
本研究结果表明,使用ShuffleNet V2 0.5x网络可以较为快速有效地对多种作物叶片的病害类型进行分类。在识别过程中,物种的类型和疾病种类的识别准确率比较高,疾病的严重程度的识别准确率较低。不同数据集对训练过程稍有影响,可通过数据扩充来提高模型训练的效率。通过对比Leaky ReLU 和ReLU 激活函数在ShuffleNetV2 模型上的表现,发现采用Leaky ReLU 激活函数能较好地解决部分落到硬饱和区的输入的对应权重无法更新的问题,并稍微提高识别的准确率由原来的85.6%提高到86.5%。
