基于CNN 的点云图像融合目标检测
2021-06-07张介嵩黄影平
张介嵩,黄影平,张 瑞
上海理工大学光电信息与计算机工程学院,上海 200093
1 引 言
无人驾驶汽车主要采用相机、激光雷达实现车辆、行人、骑行者等目标的探测。这两类传感器的数据模态不同,有着各自的优势和缺陷:激光雷达不受季节、光照条件的影响,探测距离长并且能够提供准确的三维位置信息,但雷达的点云数据是稀疏的,难以获得细节丰富的场景信息。相机能够提供稠密的纹理与色彩信息,但是被动传感器的特性使其容易受环境光照变化的影响。单一传感器难以提供满意的解决方案,两种传感器的融合可以利用多源数据的互补优势,弥补各自的缺陷,降低环境光照条件的影响,提高目标探测的鲁棒性和准确性,而且可以提供准确的目标位置信息。近年来,以卷积神经网络(CNN)为代表的深度学习技术在基于图像的目标检测方面取得巨大成功,也为多模态数据融合提供了一个非常有效的工具。
本文采用卷积神经网络,研究融合点云与图像数据的实时交通场景目标检测方法,有如下贡献:1) 提出了基于CNN 的特征级点云与图像融合框架,设计了基于融合特征的目标检测网络,提高了不同光照条件下检测的鲁棒性;2) 采用滑动窗处理控制网络输入,平衡检测与数据采集时间,有效提升小目标的检测精度;3) 实现了对目标的精确检测及获取目标深度信息的多任务网络;4) 使用KITTI 数据集进行实验评估,与多种检测算法的对比分析表明,本文方法具有检测精度和检测速度的综合优势。
2 相关工作
基于CNN 的目标检测方法可以分为基于图像、激光雷达以及数据融合的方法。
2.1 基于图像的目标检测
Girshick 等人[1]借鉴滑动窗的思想提出了基于区域建议的卷积神经网络(RCNN),成功地将神经网络由图像分类迁移到了目标检测中,大大提高了检测精度。然而这种需要在特征图上选择性搜索数千个候选框的方式也使得其检测速度较慢。在此框架下,SPP-Net[2]、Fast R-CNN[3]和Faster R-CNN[4]等通过使用效率更佳的特征提取网络,优化模型结构,改进后处理方法等方式,力图提高基于候选区域的目标检测速度。Redmon 等人通过将目标检测视为回归问题,提出了一种单次检测网络YOLO[5],直接从图像中预测目标框和类别概率,大大提高了检测速度。然而检测时固定划分网格方式,降低了对小目标、彼此靠近目标等情况下的检测精度。随着CNN 网络的不断发展,特征提取的性能也越来越强大,随后的YOLO9000[6]、SSD[7]和YOLOv3[8]等方法通过使用更优的特征提取网络以及引入残差网络的思想不断提高检测精度。总之,基于候选区域和单次检测网络在检测精度和速度上各有优势,难点在于同时取得精度和速度的最优。
2.2 基于激光雷达的目标检测
由于相机对光线和阴影较为敏感,不能提供准确和足够的位置信息,往往会影响系统的可靠性。相比之下,激光雷达可以探测目标的距离和三维信息。因此将激光雷达和深度学习相互结合的方法也获得了很大的发展。Qi 等人将原始的激光雷达产生的点云信息直接作为输入,提出了端到端的点云处理网络PointNet[9]。但是由于对点云特征全部最大池化为一个特征,因此忽略了局部特征的表达导致精度欠佳。随后,PointNet++[10]提出了集合抽象模块和特征传播模块,改善了对局部特征的获取能力。不同于直接对无序的数据做处理,Zhou 等人[11]将激光雷达点云转换为具备一定规则分布的体素(Voxel),在点云上建立三维网格来处理LiDAR 点云。然而,这需要大量的计算来进行后续处理,无法达到实时性的需求。为了提升对点云的处理速度,Complex-YOLO[12],BirdNet[13]和LMNet[14]等提出多视图的投影方法将三维激光雷达点云数据投影到一个或多个二维平面上,以此视为二维图像。从转换视图的角度与前视图相比,鸟瞰图(BEV)上的每个对象都有较低的遮挡率,因此被广泛采用。Li 等人提出的VeloFCN[15]将点云数据投影到图像平面坐标系,利用完全卷积神经网络(FCN)从深度数据中检测车辆,成为当时最快的基于点云的检测方法,但缺乏足够的纹理和色彩信息,检测精度较差。
2.3 基于融合方法的目标检测
点云数据具有精确的几何信息,但是数据非常稀疏。图像作为高分辨率的数据,具有丰富的纹理特征,可以逐个区分物体。最近越来越多的研究工作利用深度学习将点云和图像进行融合,主要分为目标级融合和特征级融合。1) 目标级融合采用2D 候选区域与点云的检测方法相结合,比如F-PointNet[16]提出了一种两阶段的三维物体检测框架,采用基于图像的2D 检测方法提取候选区域并以PointNet 处理点云。与之相似的,FPC-CNN[17]采用PC-CNN[18]检测2D 包围框,将点云数据投影到图像平面上,并对2D 包围框中的点云投影数据进行后续处理。这种方法由于传感器安装高度和遮挡不同,基于图像的候选区域往往会由于遗漏导致检测精度降低。2) 特征级融合将3D 点云数据提取的深度特征与相应图像区域相互结合。例如,MV3D[19]从BEV 生成3D 候选区域,将其投影到激光雷达前视图和RGB 图像上来获取三个视图上的区域特征,以此将所有视图的特征融合。AVOD[20]将3D锚框分别投影到BEV 和RGB 图像上获得对应候选区域的特征图,将特征图融合后进行目标检测。
3 本文方法
本文方法由两部分组成,数据预处理和融合检测网络,方法整体框架如图1 所示。

图1 方法框图Fig.1 Framework of the proposed method
首先,将激光雷达点云投影至图像平面得到稀疏的深度图,然后通过深度补全得到密集的深度图,与相机得到的RGB 图像共同作为网络输入。将RGB 图像与密集深度图进行滑动窗处理,得到近似为方形的数据切片送入融合目标检测网络。融合检测网络以EfficientNet[21]作为特征融合网络,先分别对图像和点云深度图进行特征提取,然后将两组特征图进行级联融合,网络检测部分对融合产生的特征图进行塔式多尺度[22]处理,构建残差网络对多尺度特征进行目标预测,并通过非极大值抑制(NMS)优化提炼,最后输出包含目标类别、位置、置信度和距离的检测结果。
3.1 融合检测网络
融合检测网络基于EfficientNet-B2 构建,网络架构如图2 所示。
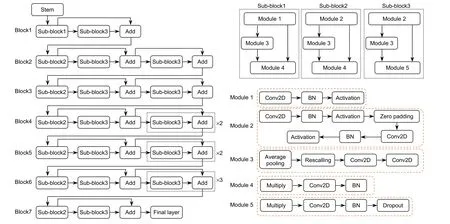
图2 EfficientNet-B2 架构图Fig.2 EfficientNet-B2 architecture diagram
EfficientNet[21]是由Google 的研究人员于2019 年提出的一组深度、宽度和分辨率可变的复合卷积神经网络集合。通常卷积神经网络想提高检测精度,通过增加网络的深度(depth)、宽度(width)和输入分辨率(resolution)实现。但与此同时,网络占用的资源和计算量也会呈非线性的增长。Google 通过对深度、宽度和分辨率三个维度的研究,通过模块化的思想设计网络主体,选取合适的复合系数构建了B0∼B7 八种不同参数量的高效卷积神经网络,相比于ResNet[23]、DenseNet[24]、Inception[25]、GPipe[26]等经典的主干网络,无论在分类精度和运算效率上都有显著提升。本文选取EfficientNet-B2 作为基础网络,其具有9.2 M 参数量,1.0 B 浮点计算操作,相比于DarkNet-53,参数量减少77.56%,浮点计算量减少79.59%。其基本组成单元由5 种Module 构成,其中Module1 和Module2 实现基本的卷积操作和池化功能;Module3 用于跳跃连接不同的Module;Module4 和Module5 用于实现特征图的连接,与Module3 共同构建残差网络。不同模块的组合构成3 种不同的子模块,通过级联成为最终的网络主体。
融合网络利用EfficientNet 的Block1 和Block2 作为特征提取器,分别对输入的RGB 图像和密集深度图进行卷积和下采样,得到深度和尺度一致的特征图。通过图3 所示的融合层进行特征图合并,使用1×1 的卷积核,保持特征图尺度不变的前提下大幅增加特征的非线性特性,降低特征图维度实现跨通道信息交互,充分融合两种模态的数据特征。将融合后的特征图送入网络后续的Block 中,对特征进行进一步提取和下采样,最终输出13×13 的特征图。网络的参数设定如表1 所示。

图3 特征融合层Fig.3 Feature fusion layer

表1 特征提取网络参数Table 1 The parameters of the feature extraction network
检测器部分采用特征金字塔网络(FPN)结构,在32 倍降采样、16 倍降采样、8 倍降采样的三个特征图上进行多尺度目标预测,让网络同时学习浅层和深层特征,获得更好的表达效果,检测器结构如图4 所示。

图4 目标检测器结构Fig.4 Structure of the object detector
检测器通过神经网络的回归实现目标位置、类别和置信度的预测。因此,检测器的损失函数主要有三个部分构成:目标定位偏移量损失 Lloc(l,g),目标分类损失 Lcla(O ,C)以及目标置信度损失 Lconf(o,c):

其中:定位偏移量损失采用平方差损失函数(MSE loss),分类损失采用多分类交叉熵损失函数(cross entropy loss);置信度损失采用二值交叉熵损失函数(binary cross entropy loss);l 为预测矩形框的坐标,g为真实值的坐标,O 为预测框中是否存在目标的概率;C∈{0,1},0 表示不存在,1 表示存在;oij为第i 个目标框中存在第j 类目标的概率,cij∈{0,1},0 表示不存在,1 表示存在;λ1,λ2,λ3为平衡系数。
3.2 数据预处理
3.2.1 点云深度图的产生与稠密化
坐标系标定是多传感器信息融合的首要条件,不同传感器有着不同的采集频率和独立的坐标系,必须统一数据采集频率进行时间配准才能把不同坐标系的数据转换到同一坐标系,实现数据的融合。激光雷达数据投影到像素坐标系的变换流程如图5 所示。
根据常昕等人[27]的研究,由激光雷达坐标系到像素坐标系的转换关系为
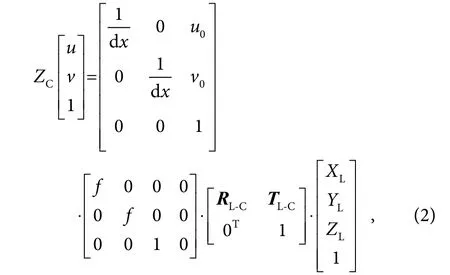
其中:(u,v)为像素坐标,(XC,YC,ZC)为相机坐标,(XL,YL,ZL)为激光雷达坐标,RL-C表示从激光雷达坐标系到相机坐标系的旋转矩阵,TL-C表示从激光雷达坐标系到世界坐标系的三维平移向量,u0,v0是相机的内参,f 为相机焦距。本文相机内参及投影矩阵由实验使用的KITTI 数据集提供,根据式(2)可计算出激光点云在图像平面的坐标(u,v),投影结果如图6 所示。
激光雷达到图像的投影得到的深度图是稀疏的深度图,大量的空像素不足以描述物体的特征甚至干扰网络的计算,深度补全任务的目的是从稀疏的深度图生成密集的深度预测。
该问题可以被表述如下:

其中:I 为图像,Dsparse为稀疏深度图,Ddense为密集深度图。
相比于基于深度学习的方法,传统的图像处理算法在深度补全上具有更快的处理速度,同时不需要大量数据的训练也能保证较好的效果。
由于KITTI数据集中点云数据的深度范围在0∼80 m 之间,没有点云的像素区域深度值为零。若直接采用膨胀操作会导致大值覆盖小值,丢失目标边缘信息。因此在形态学处理之前将深度值反转:

其中:Dinverted为反转后的深度值,Dinput为输入的深度值。通过在有效值和空值之间建立了20 m 的缓冲区,保证膨胀操作时更好地保留对象的边缘。本文所使用的深度补全算法流程图如图7 所示。

图5 坐标系变换Fig.5 Transformation of coordinates

图6 点云投影至图像平面Fig.6 Projection of LiDAR point cloud on the image plane

图7 深度补全算法流程Fig.7 The formation of the dense depth map
3.2.2 滑动窗处理
在将数据输入网络之前,需要保证输入图像的分辨率与网络设定的参数一致。然而,目标检测不同于图像分类等其他神经网络,待检测对象的纹理、色彩、尺寸都是特征之一。因此不能通过拉伸原图进行分辨率的匹配。通常,网络在加载数据时都是以输入图像长边为标准进行缩放,对空余部分进行补零,如图8(a)所示。
这种因长宽比例过大导致在加载数据时的信息丢失,在交通场景数据集中尤为明显。鉴于此,本文考虑使用长宽比例接近1 的滑动窗口对原始图像进行扫描,采用保留重叠的方式对输入数据进行切分,将切分后的滑动窗口进行填充后再传入网络,同时把所有的滑动窗口的结果重新映射到原始图像对应的坐标,经过非极大值抑制(NMS)获得最终检测结果。
4 实验及结果分析
实验在Intel Xeon(R) Silver 4110 CPU@ 2.10 GHz处理器,32 G 内存,11 GB NVIDIA GeForce 1080Ti GPU,Ubuntu 20.04 操作系统的计算机上运行,融合检测网络基于Pytorch 网络框架搭建。
实验数据来自KITTI 的Object Detection Evaluation 2012 数据集,包含训练数据和测试数据两部分。本文选取其中双目相机的彩色左视图,激光雷达点云,激光雷达与相机的标定数据和训练标签进行实验分析。训练集中包含7481 张训练图像和51865 个带有标签的目标,标签中目标被分为9 类,包括一个DonCare类。本文将Pedestrian 和Person_sitting 归为一类Pedestrian;将Car、Truck 和Van 归为一类Car;Cyclist独立作为一类,另外Misc 和Tram 因为数据太少被舍弃。
KITTI 图像序列包含三种场景:Easy、Moderate、Hard。Easy 为最小边框高度大于40 pixels,无遮挡,截断不到15%的目标障碍物;Moderate 为最小边框高度大于25 pixels,部分遮挡,截断不到30%的目标障碍物;Hard 为最小边框高度大于25 pixels,多遮挡,截断不到50%的目标障碍物。
实验结果采用KITTI 的评价方法,如果目标的检测框与标签的边框的重叠度(IoU)达到50%以上,则将该对象视为已正确检测到。选取准确率(Precission)、召回率(Recall)和平均准确度(Average precision,AP)作为性能评价指标。


图8 数据加载方式。(a) 缩放与填充;(b) 滑动窗处理Fig.8 Methods of data loading.(a) Resizing and padding;(b) Sliding windows
其中:PT 为真正例(true positive),PF 为假正例(false positive),NF 为假负例(false negative),P (R) 为不同召回率所对应的准确率。
实验主要分为三个部分:第一,通过对比使用滑动窗前后的实验结果,验证滑动窗对小目标检测效果的改善。第二,通过实验结果评估本文方法在复杂光照条件下对障碍物的检测能力,验证本文方法的鲁棒性。第三,通过实验结果比较本文方法和多种目标检测方法对交通场景中障碍物的检测效果,验证多模态数据融合方法对目标检测性能的提升。
4.1 输入数据的构建结果
网络输入数据为相机采集的RGB 图像和激光雷达得到的3D 点云,在数据预处理中,实现对激光雷达点云的图像平面投影、深度补全、滑动窗数据拆分工作。
利用KITTI 数据集提供的点云和图像数据,通过式(2)将雷达点云投影至图像平面,得到稀疏的深度图,结果如图9(a)所示。稀疏的深度图中存在大量的零值,以空洞的形式表现在图像中。在送入网络之前需要进行深度补全。深度补全使用基于OpenCV 的形态学操作,实现膨胀、闭运算、空值填充、模糊处理,补全结果如图9(b)所示,整个运算过程不依赖于神经网络和RGB 数据的引导,在CPU 上运算耗时11 ms。

图9 深度补全前后对比。(a) 稀疏的深度图;(b) 密集的深度图Fig.9 Comparison of depth maps.(a) Sparse depth map;(b) Dense depth map
KITTI 数据集的图像分辨率为1242×375,通过对Car、Pedestrian、Cyclist 三种类别的标签统计,Car的平均目标尺寸为111×66,Pedestrian 的平均目标尺寸为43×103,Cyclist 的平均目标尺寸为55×76,本文方法单帧数据处理时间为0.017 s,激光雷达采样间隔为0.1 s。为匹配网络输入选择方形滑动窗,保证重叠区域大于最大平均目标宽度,总处理时间小于采样间隔。因此,实验采用375×375 的滑动窗,滑动窗口次数为4,步长为217,相邻窗口保留158 个像素宽度的重叠区域,减少因滑动窗的截断导致的漏检。
4.2 特征提取结果
采用EfficientNet-B2 的Block1 和Block2 作为特征提取器对RGB 图像和点云深度图提取特征,其结果与DarkNet-53 的特征提取结果对比如图10 所示。
其中图10(a)、图10(c)、图10(e)分别为场景一、二、三的EfficientNet 融合网络特征提取结果;图10(b)、图10(d)、图10(f)分别为场景一、二、三的DarkNet特征提取结果。采用Grad-CAM++[28]对于网络特征提取的结果可视化,通过将特征提取网络的最后一个卷积层的特征图加权映射到原始图像平面,以热图的形式表征特征提取的效果。结果表明,相比于单模态特征提取方法,融合网络对复杂光线场景中目标所在区域有更准确的响应,如图10(a),10(e)所示;同时,引入深度信息的融合网络对平面广告牌上的假目标没有错误响应,如图10(c)所示。

图10 EfficientNet-B2 与DarkNet-53 特征提取效果对比Fig.10 The feature extraction comparison of EfficientNet-B2 and DarkNet-53
4.3 检测结果及分析
4.3.1 定性分析
检测结果如图11 所示,其中第一行是网络输入的RGB 图像,第二行是网络输入的密集深度图,第三行为进行对比的YOLOv3 网络检测结果(输入仅为RGB图像),第四行为未采用滑动窗的融合方法,第五行为采用滑动窗的融合方法,图11(a)∼图11(d)为四个不同场景。
对比仅采用RGB 图像数据的YOLOv3 算法,本文方法采用多模态数据作为输入,对图像和点云数据进行特征级的融合,综合利用图像数据的密集纹理信息和点云数据的深度信息,有效降低了目标检测的误检率和漏检率,同时获取目标的距离信息;引入滑动窗口的处理方式,显著提升了小目标的检测效果。如图11 所示,在明暗反差剧烈的场景(a)中,本文方法准确地识别出了远近的三辆汽车,以及汽车前阴影中的人,而在YOLOv3 的检测结果中,仅仅检测到了一辆汽车;在隧道场景(b)中,包含了深度信息的本文方法准确检测出了阴影中的车辆和远处过曝的车辆,图像的方法仅检测到了纹理清晰的目标;在曝光不足的场景(c)中,阴影中的行人在图像中难以区分,在深度图中清晰可辨;在存在虚假目标的场景(d)中,图像的方法将广告牌中的车辆误认为目标车辆,在深度图中仅真实车辆与背景之间存在深度差异,广告牌为平面,本文方法没有发生误检。

图11 不同场景下的检测结果Fig.11 Detection results in different scenarios
4.3.2 定量评估
将本文方法与Faster-RCNN、YOLOv3、VoxelNet、MV3D、F-PointNet 以及AVOD 进行比较,这些方法分别对应的输入数据为RGB 图像、雷达点云和融合数据。各种方法在Easy、Moderate、Hard 三种场景中分别对Car、Pedestrian 和Cyclist 三类目标检测性能见表2,表中的mAP 是在Easy、Moderate、Hard 三种场景中对所有目标统计的平均检测精度。

表2 与其他方法在KITTI 数据集上的性能对比Table 2 Performance comparison of different algorithms on the KITTI dataset
由表中数据可以看出,与YOLOv3、VoxelNet、MV3D 以及AVOD 相比较,融合深度图特征和滑动窗口处理的本文方法(最后一行)在精度上有全面提升。在取得与Faster-RCNN 接近的检测精度的同时,检测速度大幅提升。与多模态目标级融合方法F-PointNet比较,检测精度上稍逊,但检测速度有较大提升。综上所述,本文方法取得了检测精度与检测速度的平衡。
通过计算可知,本文方法在Easy、Moderate、Hard场景中对Car、Pedestrian 和Cyclist 的平均检测精度分别是82.55%、70.73%和57.09%,单帧计算耗时0.087 s,基本满足实时性要求。对比速度最快的单次目标检测方法YOLOv3,在三种场景中对于Car、Pedestrian 和Cyclist 的平均检测精度分别提升13.6%、17.15%和9.37%;对比基于候选区域的Faster-RCNN,检测精度分别提升3.32%、1.46%和-5.17%;对比基于激光点云的目标检测方法VoxelNet,检测精度分别提升23.15%、21.68%和12.56%;对比多模态数据融合的检测方法AVOD,检测精度分别提升11.70%、10.10%和2.12%。
表中后两行分别为不使用滑动窗预处理的检测结果和使用滑动窗预处理的检测结果,相较于前者,附加滑动窗处理的方法对小目标的检测精度提升明显,但单帧计算时间有所增加。
通过对比本文方法与YOLOv3 对汽车、骑行者、行人三类障碍物P-R 曲线下的包围面积可见,本文方法对小目标检测效果提升显著,如图12 所示。

图12 本文方法与YOLOv3 在KITTI 上的P-R 曲线对比。(a) 本文方法的结果;(b) YOLOv3 的结果Fig.12 Comparison of the P-R curve between our method and YOLOv3.(a) Our method;(b) YOLOv3
5 结 论
本文提出了一种基于卷积神经网络的融合激光雷达点云与相机图像的目标检测方法,设计实现了一种点云与图像特征级融合的网络框架,并针对输入图像长宽比过大导致的信息损失提出了一种滑动扫描窗口的数据处理方法。采用KIITI 数据集进行实验验证,对比其他多种检测方法,本文方法具有检测精度与检测速度上的综合优势,并能同时获取目标的距离信息。这些结果表明,本文方法借助多模态数据的优势互补提高了在不同光照场景的检测鲁棒性和准确性,附加滑动窗处理改善了对小目标的检测效果。
