基于改进Cascade R-CNN的交通标志牌识别*
2021-06-07徐国整廖晨聪
徐国整, 周 越, 董 斌, 廖晨聪
(1.上海交通大学 船舶海洋与建筑工程学院,上海 200240; 2.上海交通大学 电子信息与电气工程学院,上海 200240;3.东南大学 土木工程学院,江苏 南京 211189)
0 引 言
交通标志牌检测是指在车辆行驶过程中利用计算机视觉技术采集交通标志并实现自动检测与识别。现有的基于深度学习的交通标志牌检测算法可以分为两大类:一类是基于回归方法的目标检测算法,另一类是基于候选框提取的目标检测算法。前者的典型代表有YOLO[1]和SSD[2],它们直接对图像进行划分网格,在每个网格对应位置回归出目标位置和类别信息,检测速度非常快,但是在检测精度上略有欠缺。后者的典型代表是Faster R-CNN[3],它先通过候选区网络(region proposal network,RPN)提取可能存在交通标志的候选框,再用R-CNN[4]对其进行检测,使检测精度得到很大提高,但是在较高IOU(intersection over union)阈值下仍然无法满足该任务的精度要求[5]。文献[6]提出级联R-CNN结构,使得能够在高IOU阈值的情况下训练出高质量的检测器。
本文基于虚拟仿真环境下的自动驾驶交通标志识别大赛提供的数据集,针对雨、雪、雾天等恶劣环境下以及行人状况等干扰因素,交通标志容易被遮挡,且目标较小,难以被高精度识别以及定位的问题,本文首先对数据集进行了去雾、增亮增强;并基于改进的Cascade R-CNN,提出了先粗后精和模型融合的思想和设计了检测算法框架。本文提出的算法模型较其他模型有着显著的优势,能高精度精准的检测并识别复杂环境下道路周边交通标志牌。
1 模型算法
1.1 算法流程设计
本文提出的算法框架如图1所示,首先针对干扰因素对图像做了去雾和增亮的数据增强,然后基于由粗到精的策略,将第一个网络预测出的包含目标的小尺寸区域裁剪出来然后再放大,输入到两个分别基于Resnext[7]和Hrnet[8]的不同的骨干网络中重新训练并预测,最后将模型结果进行融合,输出模型检测出的交通信号灯的精确位置坐标以及类别。
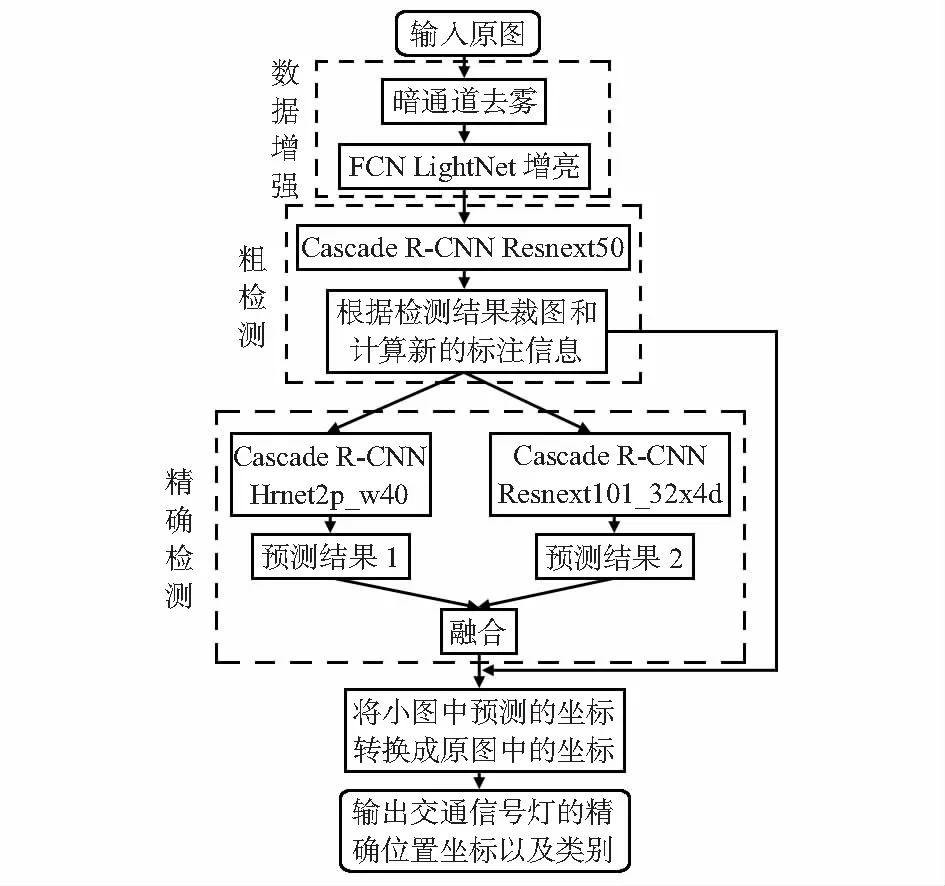
图1 本文提出的算法流程
1.2 Cascade R-CNN 算法
检测问题是分类和定位问题的结合,对于分类问题,可以根据标签直接计算损失,对于定位问题,现有目标检测模型的主要解决办法是回归,同时需要根据IOU阈值来定义正负样本,IOU的选择就会对训练和推断造成很大的影响。通常IOU大于某个阈值会被假定为正样本,当这个阈值设置偏低,易产生噪声;设置偏高则会降低检测器的性能:一方面导致正样本数量的急剧减少,会导致训练过程过拟合,另一方面训练和推断两个阶段的阈值不同会导致不匹配。Cascade R-CNN 采用多个阶段训练,能很好地解决这个问题。
本文采用的Cascade R-CNN具体结构如图2所示。首先输入(input)图像,经过提取特征的骨干(backbone)卷积神经网络,本文粗检测模型中采用的是Resnet50,精确检测模型中分别采用的是Resnext101和Hrnet。为了获得更加鲁棒性的高层语义特征,在卷积神经网络之后,本文加上了特征金字塔网络(feature pyramid network,FPN)[9];然后使用RPN生成候选区,对于候选框下采样层(RoI),本文采用了对齐候选区下采样层(RoI Align),RoI Align的准确率显著优于普通的RoI pooling[3],最后经过接头网络(H),再分别进行分类(C)和框回归(B)。对于R-CNN部分,本文进行了三阶段扩展,检测器的级联阶段越深,对相似假阳性就有更多的选择性。三个阶段的IOU取值依次为0.6,0.7,0.8,利用三个串联IOU阈值训练,每经过一个检测器,候选区的IOU都更高,样本质量更好,当使下一个检测器阈值设置得比较高时,也不会出现过多的样本被判为负样本,从而避免过拟合问题。
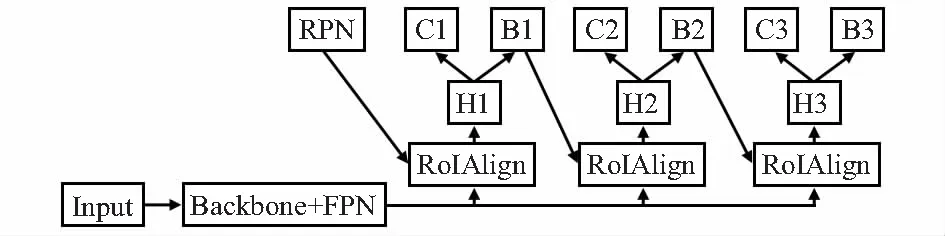
图2 Cascade R-CNN结构示意
1.3 锚设计
Cascade R-CNN 通常是在PASCAL VOC数据集上进行训练评估,默认采用三种高宽比的(0.5,1,2)的锚比例,而在交通信号标志的检测中,目标通常比较小,同时高宽比分布比较固定,本文统计了数据集的全部被检测目标的高宽比,主要分布在0.6~1.4之间。故本文采用了(0.6,1,1.4)的锚比例,这样的锚设计能更好地在区域生成网络中更好地生成适合目标大小的候选区域。
1.4 在线难例挖掘
本文在每个阶段的R-CNN部分使用在线难例挖掘(online hard example mining,OHEM)的方法:针对模型训练过程中导致损失值很大的一些样本,重新训练它们。将原图的所有候选区输入到RoIAlign中,计算它们的分类损失和框回归损失,根据损失从高到低排序,以及利用极大值抑制,来选出前K个候选区,将K个候选区重新输入RoIAlign中训练,并将梯度残差回传给卷积层,从而更新整个网络。
1.5 多尺度训练
对于小目标而言,单一尺度的训练难以检测出小目标,而利用多尺度训练,可以提高模型的鲁棒性。多尺度分为训练阶段多尺度与测试阶段多尺度,其中训练阶段多尺度又分为图像金字塔与特征金字塔。本文在训练阶段采用图像金字塔方法,将多种分辨率的图像送到网络中识别,训练时每隔一定轮回随机选取一种尺度训练,这样训练出来的模型鲁棒性强,其可以接受任意大小的图片作为输入。
1.6 由粗到精
交通信号牌检测的数据集中目标较小而图片尺寸较大,容易导致目标难以检测到或者因为IOU达不到0.9的阈值要求而被过滤掉。并且,图片中包含大量无用信息,而这些又占用了大量的计算资源。因此,本文采用由粗到精的策略,在相同的计算资源下,即先利用一个骨干网络深度和宽度较小的模型来检测全尺寸图片(3 200像素×800像素),得到目标框大致坐标信息,再根据此坐标信息裁取一个包含目标的小尺寸区域,将其适当放大后输入一个骨干网络深度更深且宽度更宽的模型中重新训练并预测。
2 数据增强
针对数据集中存在大量雾天和在夜晚拍摄导致亮度较暗的图片中的交通标志无法辨识的情况,本文采用暗通道去雾与神经网络增亮的方法对数据进行了增强。
2.1 暗通道去雾
本文采用暗通道去雾算法对图片进行去雾处理,计算机视觉和计算机图形学中,图像去雾模型如下
I(x)=J(x)t(x)+A(1-t(x))
(1)
式中I(x)为待去雾的图像,J(x)为无雾图像,A为全球大气光成分,t(x)为折射率(大气传递系数)。
去除雾霾的目标是从中I(x)恢复J(x),A和对于t(x)个像素的彩色图像I(x),存在3N个约束和4N+3个未知数。等式中的第一项称为衰减项,第二项被称为空气光,空气光在散射光的作用下产生颜色转变,透射率随场景深度呈指数变化,如果能够恢复转化关系,就能将场景深度恢复到未知的范围。在无雾图像中,每一个局部区域都很有可能会有阴影,根据Dark Channel Prior理论[10],每一个局部区域都很有可能存在至少一个颜色通道会有很低的值。如下式所示,通过求出每个像素RGB分量中的最小值,存入一副和原始图像大小相同的灰度图中,然后再对这幅灰度图进行最小值滤波便可得到暗通道。Jc表示彩色图像的每个通道,Ωx表示以像素x为中心的一个窗口。
(2)
算法步骤如下:
1)估计传输率t,假设大气光A已知,则
(3)
2)取两次最小值运算
(1-t(x))
(4)
3)代入暗通道先验假设,令暗通道为0,即
(5)
4)求出窗口内折射率
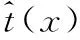
ω∈[0,1],ω=0.95
(6)
5)计算去雾以后回复图像
(7)
当投射图t(x)的值很小时,会导致J(x)的值偏大,从而使得图像整体向白场过度,因此一般可设置一阈值t0,当t(x)值小于t0时,令t(x)=t0,本文中所有效果图均以t0=0.1为标准计算。如图3所示,本文的去雾算法能够很好去除图片中的雾霾,且在一定程度上增加了图片对比度。

图3 暗通道去雾效果
2.2 神经网络增亮
针对数据集中较暗样本以及去雾以后图像变暗的问题,本文提出FCN LightNet,采用训练一个全卷积网络(fully convolutional networks,FCN)来直接处理快速成像系统中的低亮度图像。纯粹的FCN 结构可以有效地代表许多图像处理算法。如图4所示,在图片的每个通道上将空间分辨率降低50 %。原始低分辨率数据以6×6排列块组成;通过交换相邻通道元素的方法将36个通道的数组打包成9个通道。此外,本文消除黑色像素并按照期望的倍数缩放数据(例如,×100或×300)。将处理后数据作为 FCN模型的输入,输出是一个包含12通道的图像,其空间分辨率只有输入的50 %。本文将两个标准的FCN结构作为模型的核心架构,分别是多尺度聚集网络(multi-scale context aggregation network,CAN)和U-net。
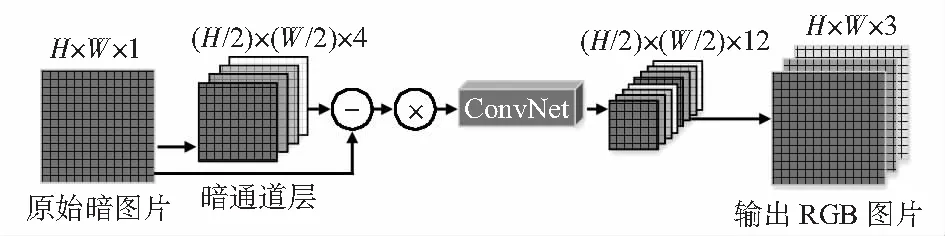
图4 FCN LightNet技术路线
本文网络输入是原始的较暗的原始数据,在RGB空间中的真实数据是相应的光照条件较好的图片数据。在每次训练迭代中,随机裁剪一个512像素×512像素的小图用于训练并利用翻转、旋转等操作来随机增强数据。效果如图5所示。

图5 FCN LightNet增亮效果
3 实验结果与分析
3.1 数据集
数据由虚拟仿真环境下的自动驾驶交通标志识别大赛主办方天津泰达科技发展集团有限公司采集,全部来源于虚拟场景环境下自动驾驶车辆采集的道路交通数据,场景中会有不同的天气状况(雾天、雨天、雪天等)和行人状况作为干扰因素,采用仿真环境下车辆摄像头采集数据,图片大小为3 200像素×1 800像素。
3.2 实验环境与参数设置
本文的模型训练和测试均基于上海交通大学学生创新中心GPU计算平台的Linux 系统进行,使用了4块11 G 显存的NVIDIA GeForce GTX 1080Ti GPU。训练的初始学习率设置为0.01,在第4个轮回的迭代之后降到0.001,在第8个轮回的迭代之后降到0.0001,之后以0.0001的学习率继续迭代4个轮回停止。优化函数采用的是随机梯度下降法,动量、衰减率分别设为0.9000,0.0001,在PYTORCH架构上进行实验。
3.3 模型评估与实验结果
图像检测需要使用矩形框将目标检测物体选中,根据检测结果和目标框之间重叠比率大于0.90,视为合格候选,预测的实例A和真实实例B之间的IOU计算公式为
(8)
式中A为被预测的实例;B为真实实例;IOU为交并比。
根据图片中汽车道路标志牌名称与候选名称是否一致判断图像内容是否匹配。为全面评估模型的有效性,必须同时检查召回率(recall)和精度(precision),检测结果的召回率和精确率的计算公式为
(9)
式中R为召回率;TP为真正例,指模型将正类别样本正确预测为正类别;FN为真负例,指将负类别样本正确地预测为负类别
(10)
式中P为精确率;FP为假正例,指将负类别样本错误地预测为正类别。
当精确率和召回率评估指标都为最优时是最理想的情况;但一般情况下,精确率高,召回率就低,反之,召回率高,精确率就低、故本文采用综合评价指标F1,来综合考虑精确率和召回率,从而更合理地评估模型的性能,F1的计算公式为
(11)
通常来说,图的大小增大,能提高检测的准确率,故在本文的实验中,采用了一张卡训练一张图的策略。本文提出的改进算法记为Our-Cascade R-CNN,并与其他模型结果对比如表1所示。模型1和模型2的输入为原图,模型3~模型6是采用C to F的思想之后,将目标裁减出来之后,再次进行训练,输入为裁剪并放大之后的小图;模型1和模型2的骨干网络均采用了Resnet50,没有采用更深更宽的网络的原因是原图的尺寸是3 200像素×1 800像素,比较偏大,采用Resnet 50的骨干网络,GPU已经占用了95 %以上,模型3~模型6则是采用了C to F的策略之后,同样的计算资源之下,采用了更深更宽的网络;模型1~模型3是没有经过改进的模型,模型4~模型6均采用了本文的改进策略。

表1 模型计算结果对比
实验结果表明:模型1的得分是显著低于模型2的得分,其原因是因为当IOU>0.9的框才算目标被检测到,级联RCNN结构体现了巨大的优势,它让检测到的目标定位更加的精准;而模型4~模型6的得分均高于模型2超过1 %,验证了本文提出的由粗到精检测的方法在高精度检测方面的优势;模型4和模型5其他参数均相同,但是采用Resnext 101和Hrnet 2p两种不同的提取特征的骨干网络,这两个模型的性能表现相似;模型6是将模型4和模型5进行了融合,结果表明两个不同的骨干网络的模型进行融合,模型将表现更加的优异,泛化能力也能会更好。
4 结 论
本文基于Cascade R-CNN的网络思想设计了一种更适用于复杂环境下交通标志识别的算法系统,在验证集上F1指标取得了0.997 2的分数,实现了对交通标志的精准检测和识别,并得到如下结论:1)当对检测目标的定位准确率要求高时,Cascade R-CNN的优势显著高于Raster R-CNN;2)针对交通信号牌检测数据集的特点,对图片进行去雾和增亮处理,适当修改Anchor ratio,并结合难例挖掘、多尺度等方法,能显著增强模型的检测效果;3)当被检测图片大小远超过被检测目标的大小时,采用本文提出的由粗到精的方法,能在节省计算资源的前提下还能大幅提升检测的准确率;4)将性能相近,但是网络结构不同的模型进行融合,能更好提高模型的泛化能力和检测的效果。
