网络爬虫在科技文献检索中的应用
2021-06-07龙学磊田萌徐英王虹
龙学磊 田萌 徐英 王虹
摘 要:科技文献检索贯穿于整个科研活动的生命周期,从科研项目的申请、立项,到方案的设计与实现,再到论文的撰写与结题验收,都离不开科技文献检索的支持,传统的科技文献检索方式往往效率低下且准确性不高。近些年,网络爬虫技术被广泛应用于互联网搜索引擎当中,可以按照预先设定好的规则自动地抓取特定网站信息。文章主要介绍了如何使用网络爬虫技术实现科技文献检索,从而大大提高科技文献检索效率及准确性,更好地为科研工作服务。
关键词:科技创新;文献检索;网络爬虫;Python;Selenium
中图分类号:TP391 文献标识码:A文章编号:2096-4706(2021)24-0150-03
Abstract: Scientific and technological literature retrieval runs through the whole life cycle of scientific research activities. From the application and establishment of scientific research projects, to the design and implementation of schemes, then to the writing and final acceptance of papers, it is inseparable from the support of scientific and technological literature retrieval. The traditional scientific and technological literature retrieval methods are often inefficient and inaccurate. In recent years, web crawler technology is widely used in Internet search engines, which can automatically grab specific website information according to preset rules. This paper mainly introduces how to use web crawler technology to realize scientific and technological literature retrieval, thus greatly improve the efficiency and accuracy of scientific and technological literature retrieval and better serve for the scientific research work.
Keywords: science and technology innovation; literature retrieval; web crawler; Python; Selenium
0 引 言
科研工作大致可以分为四个基本步骤,即科研选题、资料收集、研究试验、论文撰写。每一步都离不开科技文献检索的支持,如果能够掌握一种高效准确的科技文献检索方式,可以达到事半功倍的效果,确保科研工作顺利开展。
科技文献检索是以现代信息检索技术为核心,对科技文献进行深层次分析和利用的技术,可以使科研人员从繁重的搜索分析工作中解脱出来,从海量的信息中获得最想要的信息。
科技文献检索为科研人员的选题工作提供基础保障,如果检索一旦出现偏差将直接影响到科研项目的进度,甚至使整个科研项目走向失败。精准的科技文献检索,可以使科研人员快速、准确的获得自己所需的关键信息,大大节省搜集材料的时间,进而积极的推进整个科研项目进程[1]。
传统的检索方式多采用手工操作的方式完成,由科研人员利用互联网在搜索引擎中录入想要获得的关键字,然后对搜索结果进行人工筛选,而海量数据带来的“信息过载”问题,大大增加了科研人员的检索时间,也降低了查找准确性,严重影响了工作效率。
科技文献检索能力的高低,往往影响着科研成果的价值。每年的科研工作中会产生大量的科技文献检索需求,但受制于个人因素及技术限制,往往不能达到理想的效果。如何利用网络爬虫技术进行科技文献检索,协助广大科研工作者做好科研工作,就成为一个新的课题。
1 Python + Selenium + Chrome Driver浏览器爬虫介绍
1.1 Python语言
Python是一种面向对象的动态数据类型脚本语言,不仅简洁、易用,而且功能强大[2],具有跨平台性、开发效率高、开源、可移植性好并且支持非常丰富的第三方库等的特点[3],现在广泛应用于科学计算与科学统计工作、人工智能开发、网络爬虫等方面。
1.2 Selenium工具
Selenium是ThoughtWorks公司专门为Web应用程序编写的一个验收测试工具,它直接运行在浏览器中,完全模拟浏览器的操作[4],比如跳转、输入、点击、下拉等,通过代码控制与页面上元素进行交互(点击、输入等),获取指定元素的内容。测试工程师可以使用多种开發语言如Java、C#、Python等来编写测试脚本,并且能够在多种不同的浏览器中执行测试脚本[5]。
Selenium是Web应用程序的自动化测试工具[6],可以模拟网站自动化测试、网站模拟登陆、自动操作键盘和鼠标、测试浏览器兼容性、测试网站功能等操作,就像模拟真实用户的操作,在爬虫中被广泛使用[7]。
1.3 Chrome Driver浏览器驱动
Chrome Driver是实现 Web Driver 有线协议的一个开源工具,Selenium借助Chrome Driver通关操控Chrome的自动代理框架控制浏览器,它提供了导航到网页、用户输入、JavaScript执行等的能力。
1.4 Python + Selenium + Chrome Driver浏览器爬虫优缺点
1.4.1 优点
Python最常用的爬蟲框架为Scrapy框架,引擎控制调度器将request加入其中,调度器处理完成之后再送回引擎[8],但在模拟一些比较复杂的场景时,如输入验证码、滑动验证、登录等操作时,无法解析js运行效果,无法达到最佳爬取效果。
Python + Selenium + Chrome Driver浏览器爬虫模拟浏览器的访问操作,可以较好的执行js运行,当遇到复杂的滑动校验和需要登录时都能实现满意的爬取效果[9]。
1.4.2 缺点
使用selenium本质上是驱动浏览器对目标站点发送请求,那浏览器在访问目标站点的时候,需要把静态资源都加载完毕。html、css、js这些文件都要等待它加载完成,速度特别慢。由于在获取页面的过程中会发起多次交互请求,所以执行效率较低。
2 网络爬虫在科技文献检索中的具体实现
2.1 爬取对象选取
知网已成为当下广大科研工作者进行科技文献查询的首选网站,我们以此网站为爬取对象,通过知网检索关键字,之后抓取相关文章的标题、作者、摘要、关键词等信息。
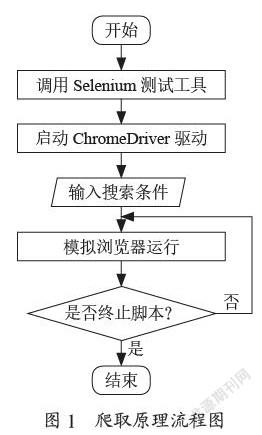
2.2 爬取原理
爬取原理具体内容有:
(1)运行Python脚本程序,调用Selenium测试工具启动Chrome Driver浏览器驱动,开始启动并开启侦听端口,并自动创建session,保持浏览器和对应客户端的会话连接;
(2)输入搜索条件,向浏览器发送http请求;
(3)模拟浏览器运行,将爬取结果记入到列表当中;
(4)判断爬取是否完成,如果完成则终止脚本运行,如未完成则重复执行(3)中操作,如图1所示。
2.3 具体实现
由于知网(http://www.cnki.net)采用反爬技术,无法正常获取相关文章信息,只得选取移动端(http://wap.cnki.net/)作为网络爬虫的入口地址。
2.3.1 引入Selenium测试工具
使用“pip install selenium”安装Selenium测试工具,并将相关头文件放置在程序最开头部分。
2.3.2 启动Chrome Driver浏览器驱动并完成初始化
启动Chrome Driver浏览器驱动并完成初始化的具体步骤是:
(1)设置谷歌浏览器驱动器的环境:
options = webdriver.ChromeOptions()
(2)创建一个谷歌浏览器驱动器:
browser = webdriver.Chrome(options=options)
(3)分析首页信息,模拟搜索过程:
打开移动端访问页面,按F12进入到调试模式,通过分析找到输入框及搜索按钮id值分别为“keyword”和“btn-search”。
(4)找到输入框的id,并将要搜索的关键字传递到输入框当中
browser.find_element_by_id(‘keyword).click()
browser.find_element_by_id(‘keyword_ordinary).send_keys(key_words)
(5)输入关键字之后,模拟点击浏览器搜索按钮事件
browser.find_element_by_class_name(‘btn-search ‘).click()
2.4 进入二级页面获取详细信息
使用find_element_by_class_name()方法获取文献的题目、作者、摘要等信息,并存储到列表当中。具体内容有:
(1)获取文献的题目:
name = div.find_element_by_class_name(‘c-company__body-title).text
(2)获取文献的作者:
author = div.find_element_by_class_name(‘c-company__body-author).text
(3)获取文献的摘要:
content = browser.find_element_by_class_name(‘c-card__aritcle).text
(4)声明一个字典存储爬取信息信息:
data_dict = {}
data_dict [‘作者] = author
data_dict[‘题名] = name
data_dict[‘摘要] = content
data_dict[‘关键字] = key_worlds
data_dict[‘来源] = source
data_dict[‘发表时间] = datetime
(5)将获得的所有存储到列表当中:
data_list.append(data)
2.5 将信息存入Excel文件
待信息收集完毕之后,将列表信息中文章的题目、作者、摘要、关键字、来源及發表时间等信息批量写入到Excel文件当中。具体步骤是:
(1)调用open()方法,已写入方式将信息写入到data.cvs文件当中:
with open(‘data.csv, ‘w, encoding=utf-8, newline=) as f:
(2)声明writer对象:
writer = csv.DictWriter(f, title)
(3)批量写入数据:
writer.writerows(data_list)
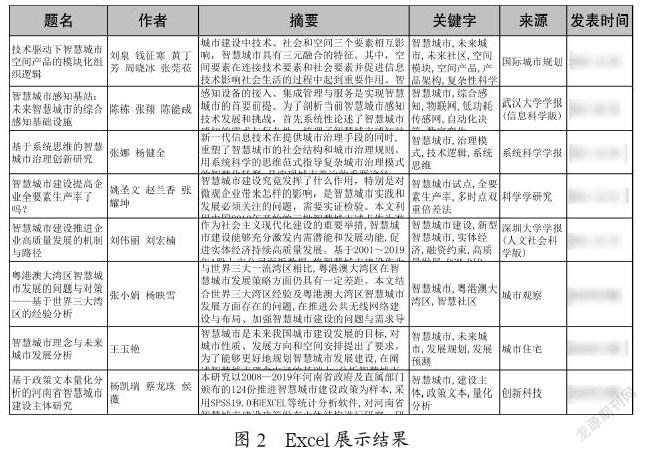
2.6 爬取信息展示
使用本文方法爬取的部分文献信息如图2所示。
3 结 论
21世纪被誉为“知识爆炸”的时代,近百年来,人类创造的知识,特别是自然科学的知识,在短时期里以极高的速度增长起来,逐步改善着我们生活、学习的环境,越来越多的人投入到科学研究当中。科技文献检索伴随整个科研的生命周期,一个好的科研项目从科研项目的申请、立项、方案的设计、试验研究、数据的收集与分析到论文的撰写都离不开科技文献检索的支持。随着人才的不断增长,科技文献的数量急剧增加,如何从大量繁杂的文献中快速准确地查找到所需文献,成为现代人需具备的一项技能[10],能否熟练运用现代科技文献检索技能高效准确的获取科研信息已成为科研成败的关键。
文章主要介绍了如何使用Python + Selenium + Chrome Driver浏览器爬虫对知网相关文献进行智能检索,并将爬取到的题目、作者、摘要、关键字、来源、发表时间等信息保存到Excel表当中,方便科研人员查询。这种浏览器爬虫可以按需自动下载相关文献基础信息,告别老式手工文件检索方式,大大提高了科研人员科技文献检索的效率,为今后科研工作取得成功打下了坚实的基础。
参考文献:
[1] 韩玲.科技文献检索在科研选题中的重要作用 [J].江苏科技信息,2019,36(33):11-13.
[2] 李刚.疯狂Python讲义 [M].北京:电子工业出版社,2018.
[3] 蒋程燕,孟令琴.基于Python语言的自动化测试应用实例 [J].工业控制计算机,2021,34(10):109-110+113.
[4] 羊昌燕,邓印凯.基于Selenium的自动化测试框架设计 [J].信息技术与信息化,2021(10):65-68.
[5] 夏克付,章晓勤.基于Selenium自动化测试框架的数据驱动技术研究及应用 [J].齐齐哈尔大学学报(自然科学版),2019,35(6):18-22.
[6] 虫师.Selenium3自动化测试实战——基于Python语言 [M].北京:电子工业出版社,2019.
[7] 孙瑜.基于Scrapy框架的网络爬虫系统的设计与实现 [D].北京:北京交通大学,2019.
[8] 单艳,张帆.基于Python的网页信息爬取技术研究 [J].电子技术与软件工程,2021(14):238-239.
[9] 樊涛,赵征,刘敏娟.基于Selenium的网络爬虫分析与实现 [J].电脑编程技巧与维护,2019(9):155-156+170.
[10] 岳金鑫.论科技文献检索课程对本科生的必要性 [J].文化产业,2021(28):105-107.
作者简介:龙学磊(1982—),男,汉族,河北秦皇岛人,高级工程师,本科,研究方向:数据分析。
