基于LSTM 循环神经网络的岩性识别方法
2021-06-06武中原张春雷王海英
武中原,张 欣,张春雷,王海英
(1.中国地质大学(北京)数理学院,北京 100083;2.北京师范大学统计学院,北京 100875;3.北京中地润德石油科技有限公司,北京 100083)
0 引言
岩性的准确识别是复杂碳酸盐岩储层精细表征和综合评价的基础和前提。地层岩性信息获取的方式主要有钻井取心、岩屑录井及井壁取心等手段,钻井取心成本的高昂和岩屑录井的不精确,使得测井岩性识别方法的研究备受关注[1-3]。测井岩性识别主要是通过建立测井参数与岩石类型之间的映射关系,并利用该映射去识别未取样井段的岩石类型。随着模式识别、统计学习和机器学习等方法的发展,越来越多的数学理论和计算机算法被应用到岩性识别模型的建立过程中,如主成分分析[4]、决策树[5-6]、支持向量机(SVM)[7]、朴素贝叶斯[8],SOM 模糊识别[9]和神经网络[10]等方法。这些方法假定岩性及其与测井参数之间的关系在深度上是彼此独立的,忽略了岩石在沉积和成岩过程中存在的空间上的序列相关性问题。其识别结果常出现深度序列上无法精确表征岩石地质特征的情况或出现地层中不存在的岩石序列组合等现象。
对岩石序列特征的早期表征是由Elfeki[11]等以马尔科夫链理论为基础,采用不同岩石类型之间的转移概率矩阵形式进行表达。后来袁照威等[8]在综合岩石类型与测井参数之间的关系时,结合了混合高斯模型和最大期望算法进行了参数的学习。其中,隐马尔科夫(HMM)[1,12]较为常用,可以融合岩性在深度上的序列相关性及其与测井参数之间的关系,但是在岩石类型转移阶次的确定、不同阶次序列相关性的精确学习等方面依然存在不足。深度学习中的循环神经网络(RNN)模型可以通过自循环结构的学习,使序列相关信息得到很好地保留。该方法应用到岩性识别过程中能够充分表征岩性内在的沉积模式以及不同测井参数对岩性测量和表征方面的承载尺度问题。长短期记忆神经网络(LSTM)是常用的循环神经网络之一,解决了RNN 梯度爆炸和梯度消失的问题[13]。通过在自循环单元中引入门结构,使测井参数信息能够在LSTM 中长期传递下去,从而使得LSTM 在综合考虑数据的邻域信息和历史信息后,有效提取到数据的序列变化信息。
1 方法原理
1.1 RNN 原理
人工神经网络通过构建分层结构,自动提取出输入输出之间的非线性函数关系。BP 神经网络是最常见的人工神经网络,具有典型的分层结构,通常包括输入层、隐含层和输出层(图1)。BP 神经网络中的基本单元是神经元,每一层的每一个神经元只与相邻层的所有神经元相连接,而同层的神经元则互不连接。隐含层的每个神经元对上一层的所有神经元输出进行线性求和,然后经过激活函数输出到下一层的每个神经元,作为下一层的输入。随着BP 神经网络不断进行正向传递和反向传播,网络权重也不断进行调整,最终达到较优的预测效果。
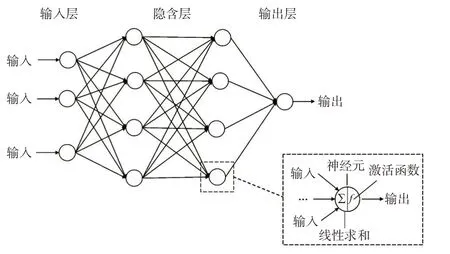
图1 BP 神经网络结构示意图Fig.1 Structure diagram of BP neural network
传统的BP 神经网络隐含层神经元互不相连,且使用固定数量的计算步骤产生固定大小的输出,在处理可变大小的序列数据上限制较大。RNN 通过递归连接的每一层网络的内部节点,使得数据在时间维度上传递,实现了数据序列性的有效学习(图2)[14-17]。
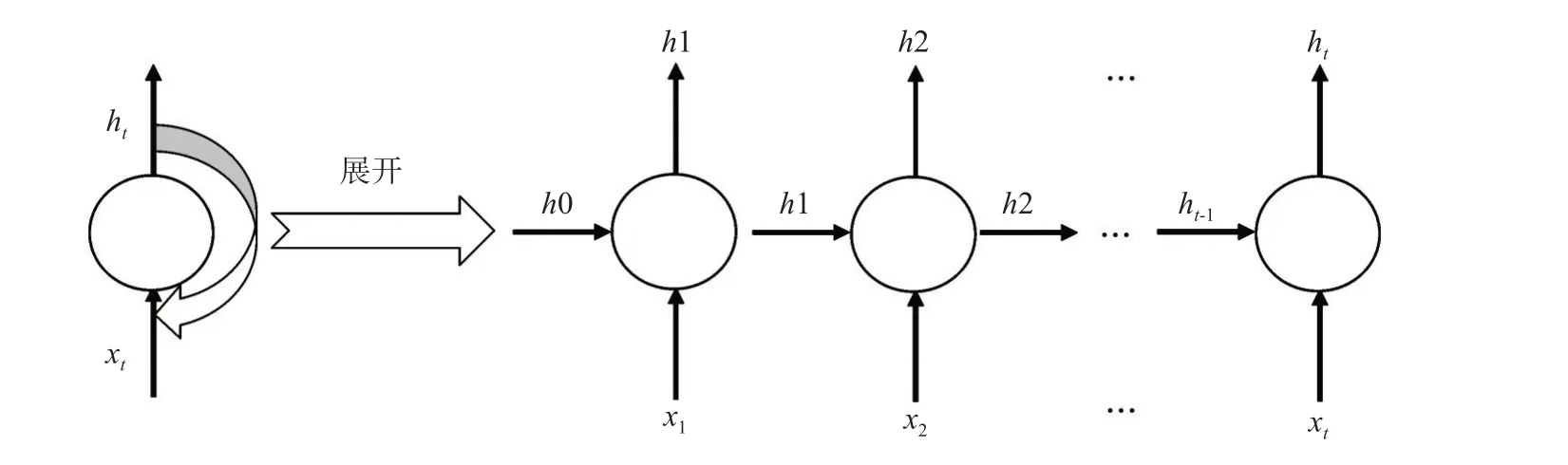
图2 RNN 及其展开示意图Fig.2 RNN and its development diagram
由RNN 中循环单元的计算式[式(1)]可知,RNN 在所有时间维度上实现参数共享,使得网络模型得到简化,同时能够学习任意长度的序列数据。
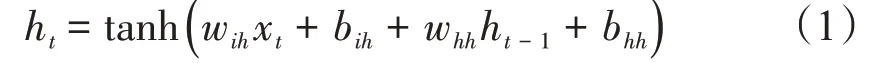
式(1)中:xt是t时刻的输入;ht为t时刻的隐状态;wih,bih是输入层与隐状态间的权重和偏置;whh,bhh是隐状态与隐状态之间的权重和偏置。
1.2 LSTM 基本原理
常规的RNN 容易发生梯度爆炸和梯度消失[18],导致网络预测效果不佳。为此,Hochreiter 等[13]提出LSTM,并由Graves 等[19]对其进行了改良。相较于RNN 较为简单的循环单元,LSTM 通过添加3个门层来控制不同时序对后续信息的影响,同时使用隐状态和细胞状态传递信息,使得LSTM 能够综合局部信息和序列信息。图3 是常见的LSTM 网络重复单元,主要包含3 个门层:遗忘门、输入门、输出门。在LSTM 神经元的每个时刻,神经元的输入包括前一时刻的细胞状态和隐状态以及当前时刻的输入。首先是当前时刻输入和前一时刻隐状态,依次通过遗忘门和输入门,完成细胞状态的更新,然后根据更新后的细胞状态和输出门,完成隐状态的更新。
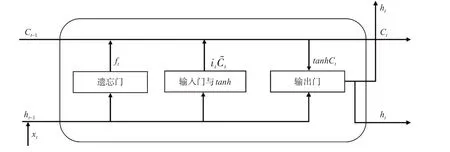
图3 LSTM 重复单元结构Fig.3 LSTM recurrent unit structure
遗忘门:根据当前时刻的输入和前一时刻的隐状态决定细胞状态中要忘记的信息
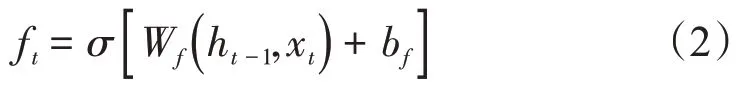
输入门:根据当前时刻的输入和前一时刻的隐状态决定哪些新信息要添加到细胞状态
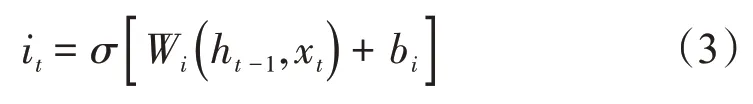
根据遗忘门和输入门的输出,对细胞状态进行更新
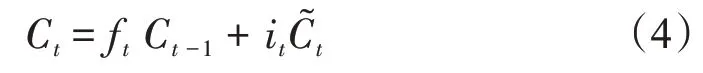
输出门:根据当前时刻输入信息和前一时刻隐状态的合并以及更新后的细胞状态,对隐状态进行更新
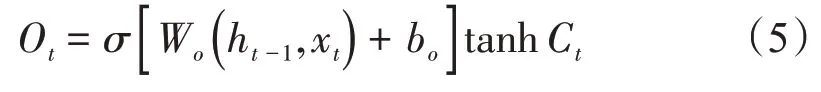
式中:ft是t时刻遗忘门的输出;Ot是t时刻输入门的输出;是t时刻tanh 层的输出;Ct为t时刻的细胞状态;it是t时刻输入门的输出;Wf,bf是遗忘门的权重和偏置;Wi,bi是输入门的权重和偏置;Wo,bo是输出门的权重和偏置。
1.3 基于LSTM 岩性识别模型的构建
在LSTM 中,由于序列维度的存在,使得网络结构本身比较复杂,因此不需要过分堆叠循环层。如图4 所示,首先通过对测井资料的分析选择出对岩性敏感的测井参数,并对其进行均值方差标准化预处理,去除量纲的影响,同时使用One-Hot 编码将岩性数据数字化,然后构建包含LSTM 层和全连接层的岩性识别模型。
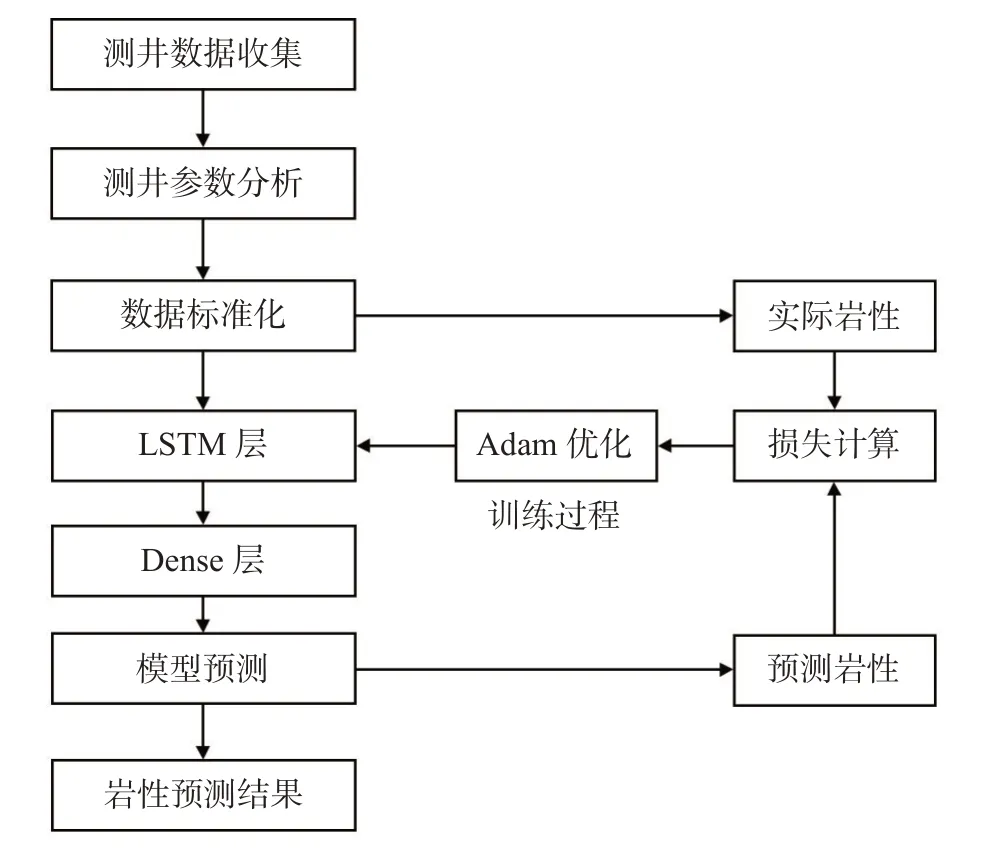
图4 岩性识别模型Fig.4 Lithology identification model
由于岩性识别是多分类问题,网络使用交叉熵作为损失函数对网络学习进行评估。同时使用Adam优化器进行网络学习,不同于常用的随机梯度下降,Adam 优化器能够在迭代过程中自适应调整学习率从而显著提升网络学习速度。为防止网络发生过拟合,使用dropout 学习策略提升其泛化能力。
2 应用实例分析
本次研究数据为苏里格气田东部地区奥陶系马沟组马五段复杂碳酸盐岩储层,属于海相沉积地层,因受沉积和成岩等因素的影响,岩石类型复杂多样。钻井取心和岩屑录井显示,主要岩石类型有石灰岩、白云质灰岩、泥质灰岩、白云岩、灰质白云岩和泥质白云岩等6 种,其中灰质白云岩和白云质灰岩是主要的含气储层。
2.1 测井参数敏感性分析
通过对岩性和测井资料的分析[20-21],选取对岩性较为敏感的声波时差、自然伽马、光电吸收截面指数、密度、深侧向电阻率和补偿中子等6 种测井参数。以55-010 井为例,对石灰岩、白云质灰岩、泥质灰岩、白云岩、灰质白云岩和泥质白云岩等6 种岩性的箱形图进行分析。由图5 可知,不同测井属性对岩性的响应特征存在明显差异。总体来说,泥质岩性的自然伽马较高[图5(a)],而非泥质岩性的自然伽马较低且重合在一起,因此通过自然伽马可以有效划分出含泥质较多的泥质灰岩和泥质白云岩。同时泥质灰岩的声波时差[图5(b)]和光电吸收截面指数[图5(c)]均较高,则可以进一步通过声波时差和光电吸收截面指数来划分泥质灰岩和泥质白云岩,而光电吸收截面指数对于白云岩和灰质岩的区分则更为明显。白云岩的光电吸收截面指数基本小于3.2 b/e,而灰质岩则相反。从图5 可以看出,由于数据中一些噪声点的影响,导致个别岩性测井参数取值区间较大,甚至超出正常值,该情况主要影响了箱形图的极值情况,对中位数及上下四分位数影响均较小,因此为进一步统计有实际意义的测井参数响应特征,将第90 百分位数及第10 百分位数作为实际岩性响应范围的上下限(表1)。
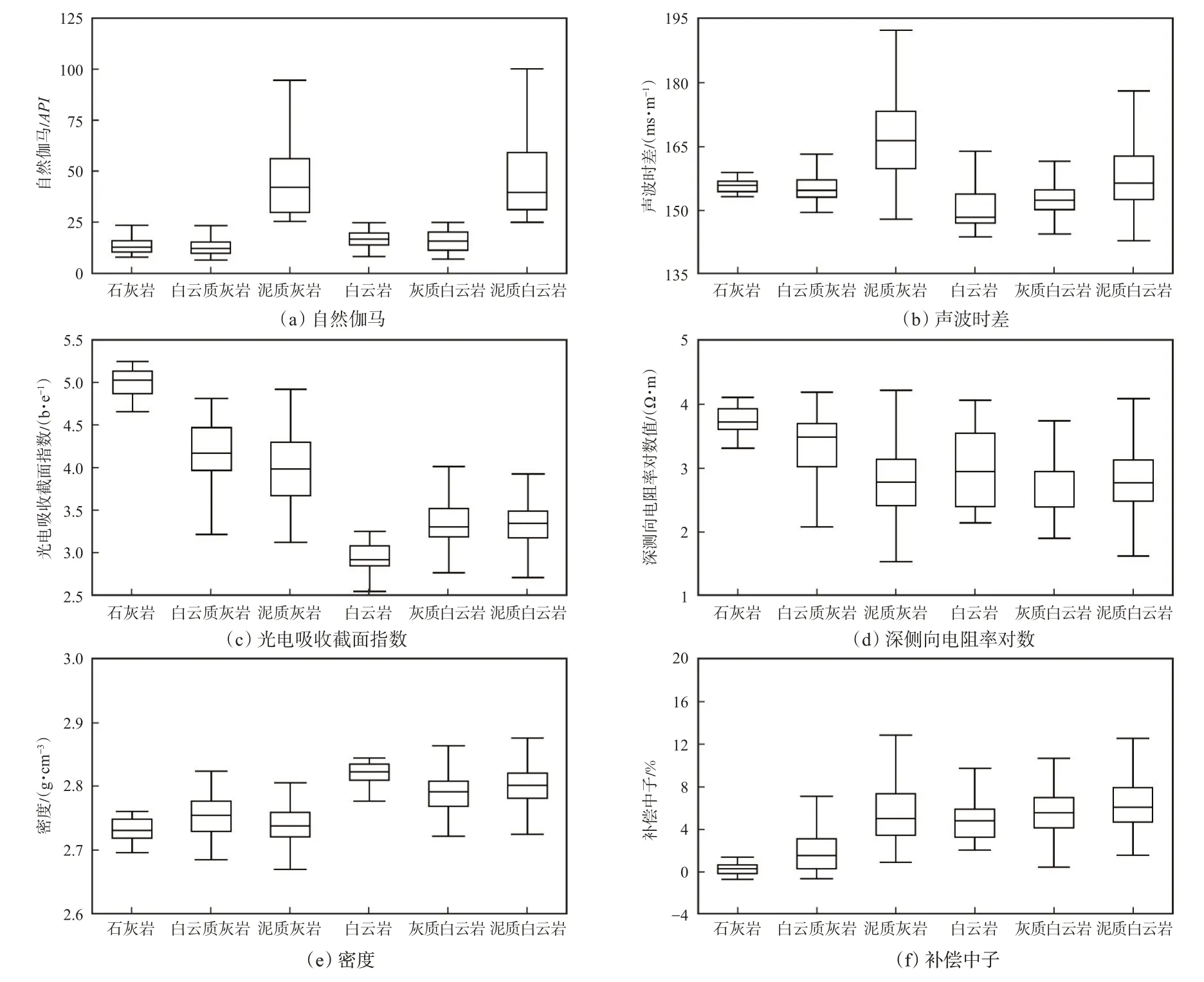
图5 苏里格气田苏东地区55-010 井岩性及其测井参数箱形图Fig.5 Box diagram of lithology and logging parameters of well 55-010 in eastern block of Sulige gas field
综合测井参数箱线图(图5)、岩性测井参数统计表(表1)和岩性间高区分度敏感参数统计表(表2),得出以下结论:①不同岩性的各测井参数响应特征虽各不相同,但存在一定程度的重叠,即测井参数对不同岩性响应的敏感性差异较大。②各测井参数对石灰岩响应特征的变化范围较小,其光电吸收截面指数较高,补偿中子和自然伽马则较小;白云质灰岩和泥质灰岩的光电吸收截面指数取值范围差异较大,其他参数变化范围则相近;泥质灰岩和泥质白云岩的自然伽马值均高于25 API,且声波时差的变化范围较大;各岩性的深侧向电阻率变化范围较为接近;白云岩的光电吸收截面指数较低,且密度取值较高。③由表2 可知,不同岩性对应着不同的高敏感性参数,单一的测井参数只能粗略实现部分特定岩性的划分,只有综合考虑岩性对所有测井参数的响应特征,才能实现所有岩性的有效识别。
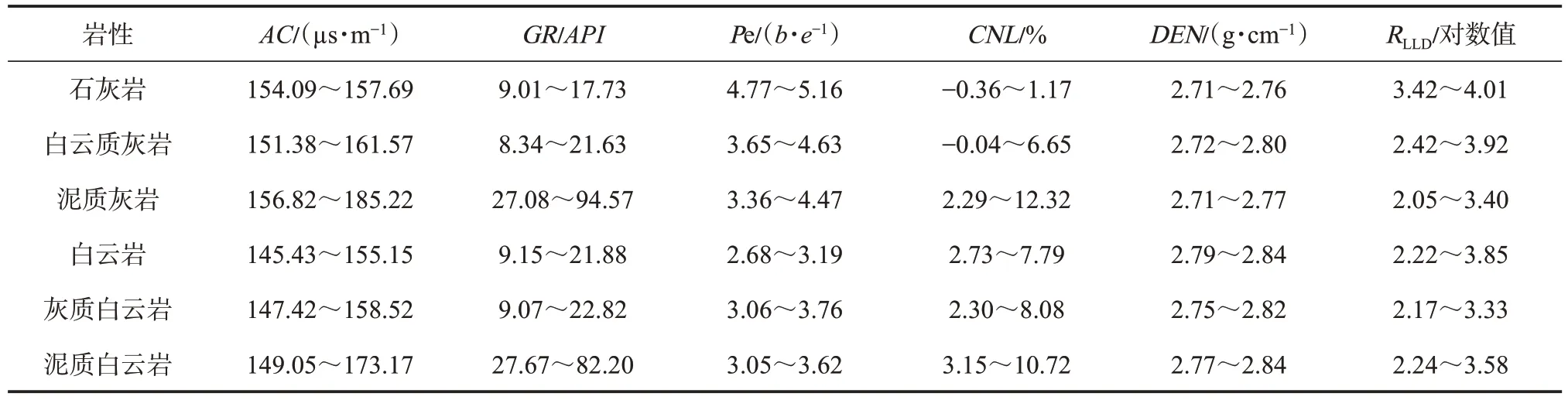
表1 苏里格气田苏东地区不同岩性测井参数响应特征(10%~90%)Table 1 Response characteristics of different lithology logging parameters in eastern block of Sulige gas field
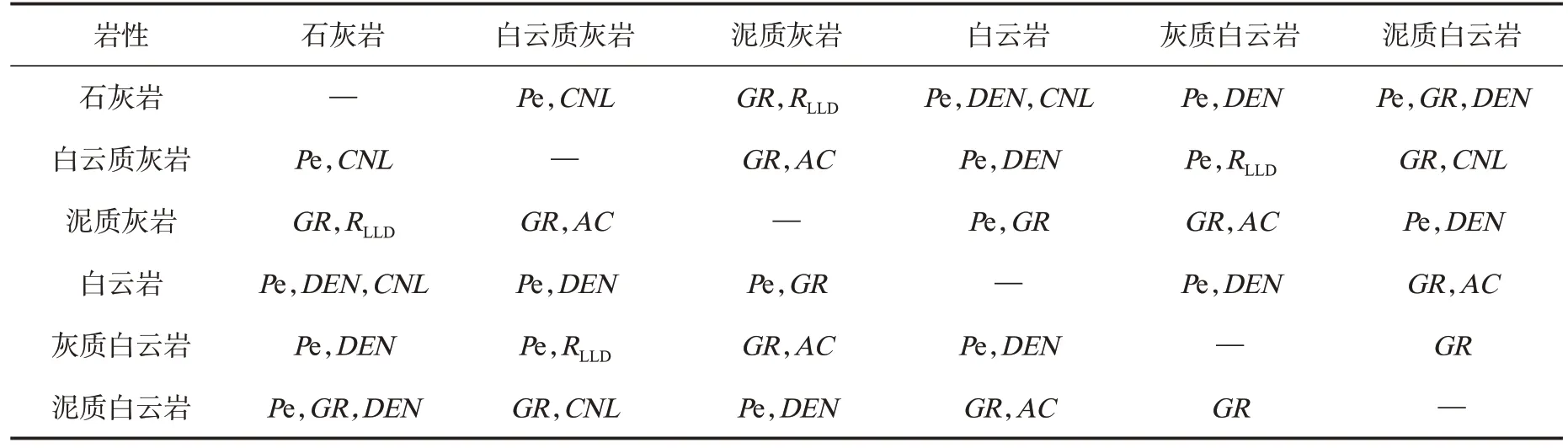
表2 苏里格气田苏东地区不同岩性之间高区分度敏感参数Table 2 High-sensitivity parameters between lithologies in eastern block of Sulige gas field
2.2 网络模型参数分析
本次研究网络模型运行平台如下:Windows10 64 位操作系统,Intel Core i7-8700 CPU @3.2 GHz,16 GB 内存,Nvidia GeForce GTX 1050 显卡,运行环境为python3.6,keras(tensorflow 后台)框架。在LSTM 网络模型建立过程中,对岩性识别效果影响较大的网络参数主要有迭代次数(epoch)、批样本个数(batch)和时间步长(time-step)等。为此,在建模过程中先分析这3 个网络参数的影响。
epoch 是网络使用全部训练集训练所用的次数,其对网络的最终训练结果有很大影响。训练次数过少,网络就不能完全提取出数据的特征信息,即网络欠拟合,从而导致网络的预测结果较差。epoch 过多,则网络可记住训练集中个别样本的特征,即网络过拟合,从而导致网络在训练集中预测效果较好而在测试集上预测效果较差,即网络的泛化性较差。通过控制其他变量不变而改变训练次数,并通过交叉熵损失函数评估网络。可以看出:随着epoch 增加,网络模型的损失值迅速下降,表明网络在快速学习,当epoch 达到1 000 时,损失曲线已基本稳定,表明网络已经充分学习。
batch 是指每次进行网络训练时所传入的训练集样本个数。由于深度学习中的数据量较大,一般要采取小批量处理的方法。由于每次传入数据后都会更新网络权重,所以相较一次传入全部数据,小批量训练网络的速度更快。但是,过小的batch则会使网络学习变得过于随机,过大的batch 则需要更多的epoch。本次在固定其他参数的前提下,调节batch,并通过岩性识别准确率评估batch 对网络训练的影响效果,可以看出,当batch 小于32 时,准确率较高,而随着batch 的进一步增大,准确率迅速下降,因此选择batch 为32。
time-step 是指使用多少组测井曲线数据来预测当前时刻的岩性。如果time-step 过小,则由于输入信息过少,使得网络只能根据附近时刻的信息来预测当前时刻,忽视了序列信息的连续性。如果time-step 过大,由于不同测井段的岩性特征和孔隙特征变化,导致训练集中包含与当前时刻无关的信息,从而既加大了网络的训练时间,又影响了预测效果。于是,在保证其他各参数不变的前提下,调节time-step,通过岩性识别准确率来评估time-step对网络训练的影响。由图6 可看出,当time-step 为4 时,准确率较高,而随着time-step 的增大,准确率则在96%左右波动,因此选择time-step 为4。

图6 网络模型参数选择Fig.6 Parameter selection of network model
2.3 实验结果
从苏里格气田苏东地区选取42-12 井、44-7 井、49-13 井共计3 122 个样本点和57-04 井共计1 355个样本点作为训练数据,其中前3 口井的石灰岩、白云质灰岩、泥质灰岩、白云岩、灰质白云岩和泥质白云岩的样品个数分别为272 个、314 个、335 个、590 个、596 个、1 015 个。分别采用KNN、朴素贝叶斯、决策树、SVM,HMM 和LSTM 进行训练学习,并在测试集上进行分类预测,从而评估模型的岩性识别效果。
表3 为KNN,朴素贝叶斯、决策树、SVM,HMM,LSTM 这6 种算法的岩性识别效果,传统模式识别方法KNN 和朴素贝叶斯的岩性识别准确率平均值低于90.00%,决策树、SVM 和HMM 相比之均有显著提高,而采用LSTM 的平均岩性识别准确率可达97.12%,岩性识别效果优异。从岩性识别效果来看,传统机器学习方法对不同岩性的识别效果差异较大,尤其对石灰岩及其过渡岩性的识别效果较差,导致整体正确率较低。而LSTM 的识别准确率则相对平稳,仅对石灰岩的识别准确率为80.95%,对其他岩性的识别准确率均在97.00%以上。相较于传统的机器学习方法,LSTM 模型更好地学习到了岩性数据的空间结构特征,从而有效提升了岩性识别效果。
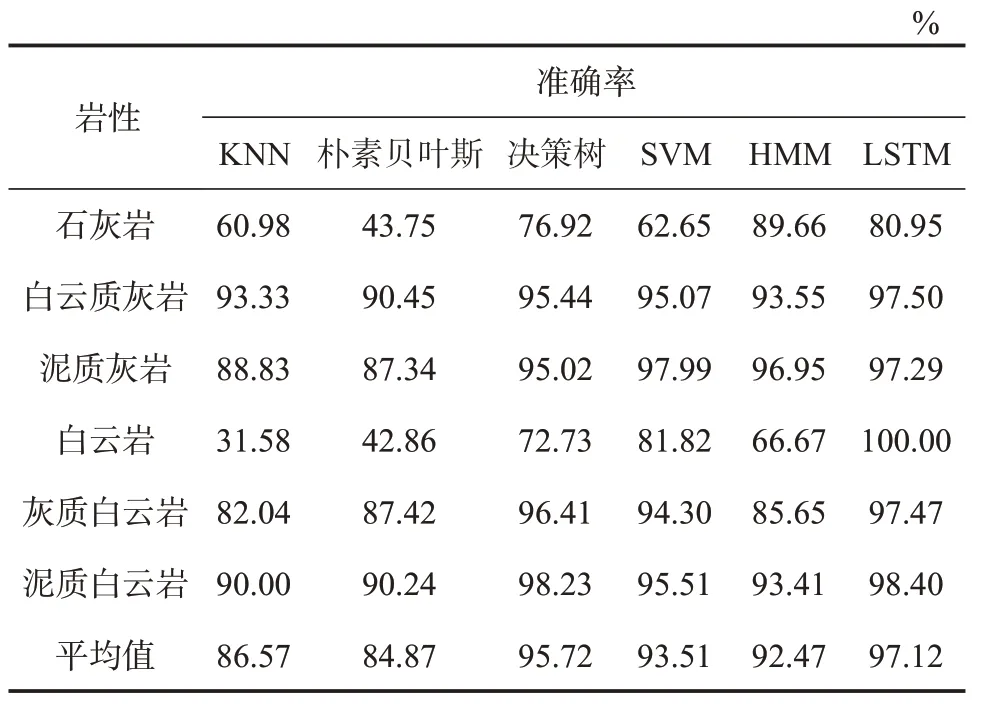
表3 苏里格气田苏东地区57-04 井不同方法的岩性识别准确率Table 3 Lithology identification effect by different methods in well 57-04 in eastern block of Sulige gas field
图7 为部分实际录井岩性与不同岩性识别模型预测对比图,表4 采用混淆矩阵定量分析准确率及召回率,并以此对比LSTM 算法的改进效果。可以看出,LSTM 的预测结果与录井岩性基本一致。召回率较低的白云岩样本数目较少,导致其错分的样本对召回率影响较大,除白云岩外整体召回率在93.00%左右,实现了各岩性的有效召回。误分岩性基本为相邻的过渡岩性,且白云岩主要被误分为灰质白云岩,这2 种岩性转换较为频繁,导致LSTM在岩性转换过程中容易发生误分。
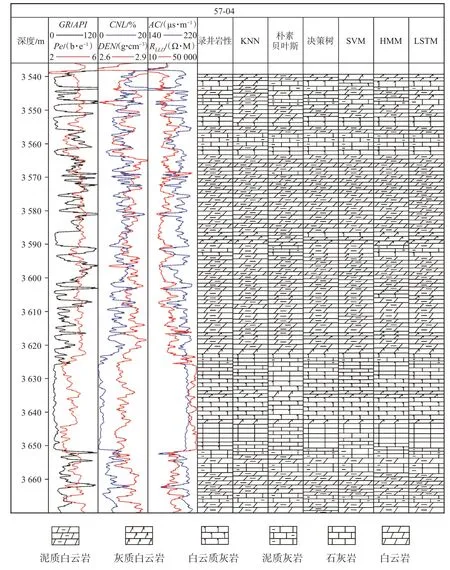
图7 苏里格气田苏东地区57-04 井不同方法的岩性识别结果Fig.7 Lithology identification results of well 57-04 in eastern block of Sulige gas field
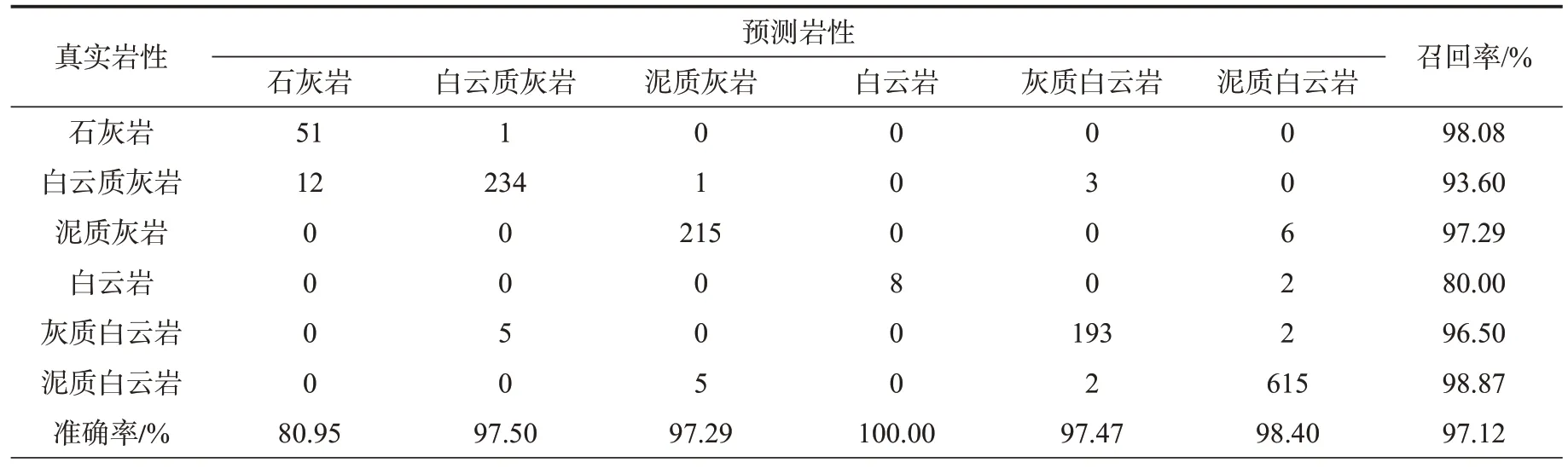
表4 苏里格气田苏东地区57-04 井LSTM 岩性识别混淆矩阵Table 4 LSTM lithology identification confusion matrix of well 57-04 in eastern block of Sulige gas field
为了进一步展示LSTM 模型对于岩性数据的序列特征学习能力,表5 为不同岩性识别方法的一阶状态转移数目矩阵。可以看出:KNN 的识别结果中石灰岩发生了过多的自转移,同时大量的白云质灰岩和泥质灰岩的自转移没有被预测到,从而导致岩性识别效果较差,这也说明了KNN 这类传统方法局限于点对点的识别,忽略了岩性序列的局部信息和序列的整体变化情况;传统的序列统计方法HMM 虽然能够考虑到岩性数据的序列性,但同时也假定岩性序列相互独立,从而使得预测结果有所偏差,使得在泥质灰岩的预测误差较大。LSTM 与钻井数据的转移基本一致,表明LSTM 模型预测岩性时充分考虑到岩性序列的沉积模式,使得岩性预测结果与实际地质情况相符。
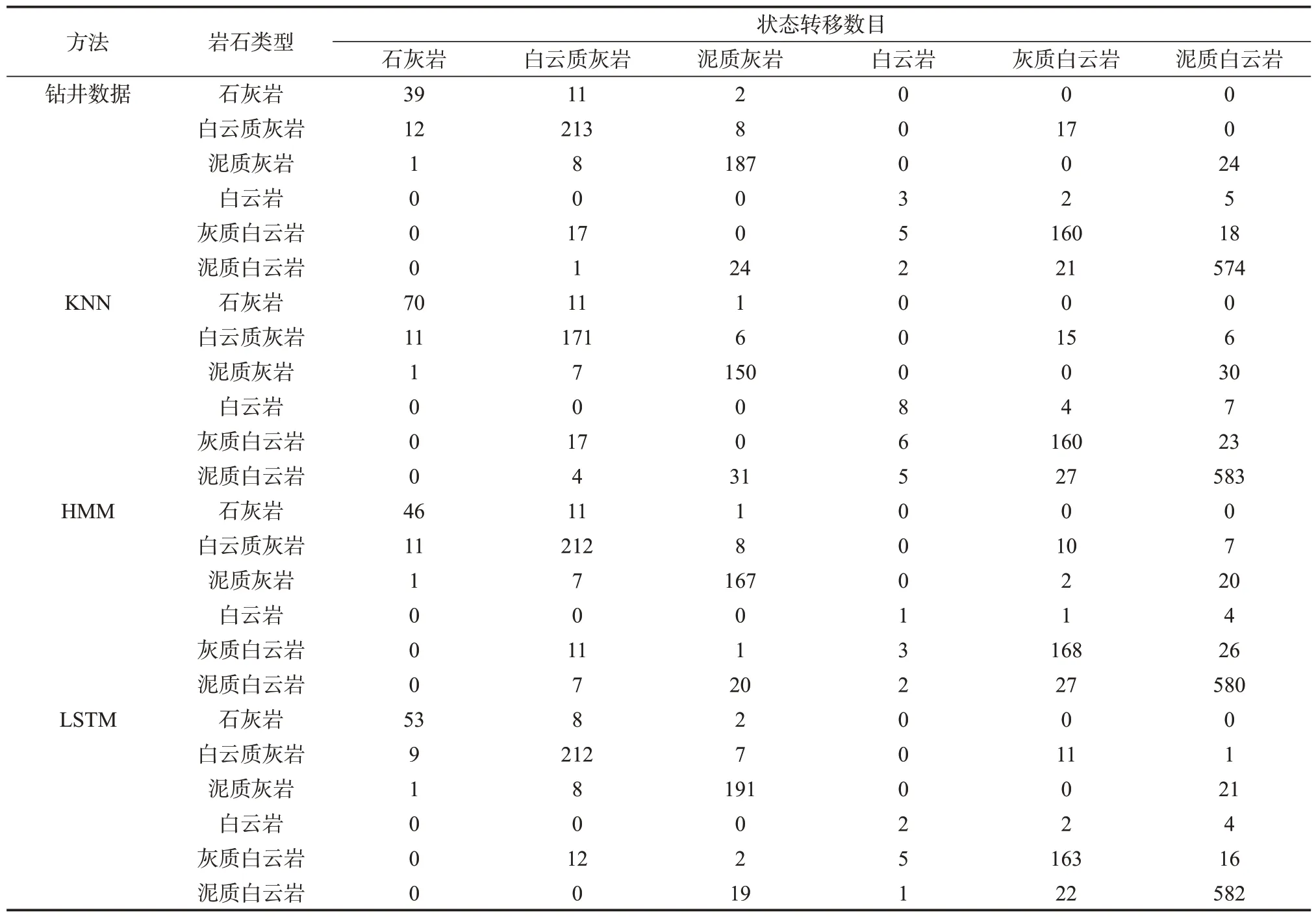
表5 苏里格气田苏东地区57-04 井不同岩性识别方法一阶状态转移数目Table 5 Number of first-order state transitions for different lithology identification methods in eastern block of Sulige gas field
为进一步说明该方法的泛化能力,基于上述过程,选择55-010 井开展岩性识别,其识别结果如表6 所列。从表6 可看出,LSTM 模型仍然具有较高的识别精度,也体现了LSTM 模型具有较强的泛化性。

表6 苏里格气田苏东地区55-010 井不同方法的岩性识别准确率Table 6 Lithology identification accuracy of different methods of well 55-010 in eastern block of Sulige gas field
3 结论
(1)LSTM 模型有效地反映了岩性序列的时序空间特征,有助于岩性识别效果的提升。相对于传统方法无序点集的学习识别,LSTM 算法的岩性识别模型从测井数据的序列出发,有效捕捉到了岩性沉积模式和测井参数承载尺度信息,实现了测井序列和岩性序列的整体匹配。
(2)与决策树、朴素贝叶斯、KNN,SVM,BP 神经网络等方法对比显示,基于LSTM 模型的岩性识别方法更加精确,准确率可提高1.40%~12.25%,并对白云岩及其过渡岩性识别效果更好,同时对主要含气储层灰质白云岩和白云质灰岩的召回率和准确率均达到93.00%以上,解决了实际生产需求。
(3)LSTM 模型对于测井数据具有良好的适用性,通过引入3 个门层,保证了信息传递的持续性,实现了自动提取测井数据的序列特征,挖掘空间结构,进而有效提升了岩性识别的精度,对于数据挖掘具有重要意义。
