基于SVM的视频用户需求预测算法
2021-06-03江翠丽曹腾飞李长哲王晓英
江翠丽,曹腾飞,李长哲,王晓英
(青海大学 计算机技术与应用系,青海 西宁 810016)
0 引 言
随着移动互联网技术的飞速发展,视频点播、视频聊天等流媒体网络业务已成为用户消费的主流[1]。据中国互联网络信息中(CNNIC)第44次《中国互联网络发展状况统计报告》统计,截至2019年6月,国内网络视频用户规模达8.47亿,较2018年底增长3 391万,占网民整体的88.8%[2]。为实现高带宽、大容量、低时延,5G移动通信网络应运而生[3]。5G网络的超高传输速率虽然解决了网络带宽与时延的问题,但仍无法满足不同用户对不同视频业务的体验需求[4]。因此,从用户需求感知出发,提升用户的服务体验是网络视频行业发展的必然趋势。精准的用户需求预测可以减少用户寻找所需视频内容的时间,在提升用户体验的同时有助于运营商精准地掌握用户喜好信息,促进网络平台的发展。
文献[5-6]将网络负荷作为评价指标构建了基于用户感知的网络负荷模型,通过对不同小区的用户使用流量情况分析,从用户感知速率角度实现了流量增长与网络负载能力的平衡。文献[7]为应对不同用户的不同业务需求,提出了一种面向排名的预测方法,通过考虑用户对服务质量的态度和期望,来提高服务等级预测的准确性,发现满意度更高的云服务候选者,以减少负面顾客在排名相似度计算中的影响。文献[8]提出了一种基于卷积神经网络算法构建用户感知评价模型,通过对产品的使用数据进行研究分析,建立了用户感知评估与产品性能之间的映射关系,从用户感知产品性能的角度出发,预测出影响用户感知的产品性能参数。文献[9]从网络业务角度出发,充分考虑不同业务类型对信道资源的占用情况,根据流量与用户体验的变化率来构造网络效益函数,实现无线资源的利用效率。文献[10]基于深度神经网络DNN模型对IPTV视频用户的点播行为进行分析,如用户的在线时长、观看时长等,目的在于帮助IPTV服务提供商进行合理的资源分配,提升对用户的服务质量。
现有的视频用户需求感知方法仅依赖于用户对视频播放质量和网络状态需求的感知,忽略了用户自身观看喜好和观看行为对需求感知的重要性,而该文从用户观看视频行为出发,结合用户观看视频喜好,提出了基于SVM的视频用户需求预测模型,目的在于精准预测用户对视频内容的需求,帮助运营商提高视频推荐成功率,在促进网络视频业务发展的同时减少用户搜索视频的时间,提升用户体验。
1 相关理论
用户观看视频的行为受到多种因素的影响,如地区、年龄、终端设备能耗及视频的流行度等因素,不同的地区、不同的人群观看视频的行为具有显著差异[11]。面对海量的网络视频资源,不同的用户对视频内容的需求也不同,挖掘用户观看视频行为数据中各用户与其对视频需求的关系并建立有效的视频用户需求预测模型,可以实现用户对视频内容需求的预测,提升用户体验。
由已知的用户观看视频行为数据来预测用户后续的需求非常符合支持向量机(support vector machine)的应用场景。支持向量机是由Cortes和Vapnik于1995年首先提出的建立在统计学习理论的VC维理论。该理论可以根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳解决策略,以期获得最小化结构风险[12]。SVM预测模型的主要思想是实现样本数据的线性回归,具体地,将线性不可分的样本数据x通过非线性映射φ,映射到更高维的特征空间F,在高维空间F实现样本数据的线性回归。由于SVM可以实现对特定训练样本的学习精度和无错误地识别任意样本能力的折中,从而被广泛应用于函数拟合等其他机器学习的问题中[13]。
为了检测由巨大的网络流量数据引起的网络入侵,文献[14]针对非线性海量数据提出了一种基于深度置信网络和支持向量机(DBN-SVM)的分类算法,提高了分类的准确性,并为实时的网络入侵检测提供了基础。文献[15]将SVM预测模型应用于经济预测领域,研究结果表明,支持向量机可以有效地减少噪声数据的影响,并实现非线性区域经济变量之间的映射,提高了模型的预测精度。
实现用户需求预测的目的在于:当用户浏览视频网站时,运营商可以基于用户需求预测结果为目标用户提供其可能感兴趣的视频内容,从而在提升用户观看体验的同时提高视频资源的利用率,降低网络运营成本。该文基于SVM预测模型实现对用户观看视频需求的预测,主要包括以下5个步骤:先获取用户信息及用户观看视频信息;其次对获取的用户和视频数据进行探索及处理;然后利用训练数据训练模型并生成预测模型;再利用测试数据进行模型预测;最后将预测结果与实际情况进行对比分析,实现对模型性能的评估。
2 SVM算法
2.1 问题描述
构建基于SVM的视频用户需求预测模型的关键在于寻求一条泛化性比较好的决策边界,使得支持向量距离决策边界尽可能的远。寻求最优决策边界的过程即为最大化支持向量到决策边界的距离d的过程。
定义样本的个数为M={1,2,…,m},假设x表示原来的样本点,用φ(x)表示x映射到高维特征空间F后得到的新向量,那么支撑向量到超平面wTφ(x)+b=0的几何间隔表示为:
(1)
则优化目标表示为:
(2)
注意到几何间隔d与‖w‖是成反比的,且|wTφ(x)+b|为固定值,因此最大化几何间隔d的问题可以转化为最小化‖w‖的问题。为了方便后边求导计算,将目标优化问题(2)进一步转化为(3):
(3)
为提高SVM视频用户需求预测模型的泛化能力,引入松弛变量ξi,则目标优化问题将进一步转化为:
s.t. 1-yi(wTφ(xi)+b)-ξi≤0
ξi≥0,i=1,2,…,n
(4)
其中,C为惩罚因子且满足C>0。分析可知:为使得样本数据线性可分,需满足C为无穷大时,ξi必然无穷小;当且仅当C为有限值的时候,才会允许部分样本不遵循约束条件。
2.2 优化目标求解
通过添加拉格朗日乘子,构造拉格朗日函数,将问题(4)转化为无约束的优化问题,如下:
s.t.λi≥0,μi≥0
(5)
其中,λi和μi为拉格朗日乘子,利用强对偶性转化,将式(5)转化为:
s.t.λi≥0,μi≥0
(6)
分别对w,b和ξi求偏导数,并令偏导数为0,得出如下关系:
(7)
将式(7)中的求导结果带入式(6),得到新的目标优化函数:
(8)
求解式(8),可以得到:
(9)
将支持向量(xs,ys)带入:ys(wφ(xs)+b)=1,求出b为:
(10)
其中|S|为支持向量的个数。求出w和b后,便可以求得超平面wTφ(x)+b=0。
3 数据处理
3.1 数据集
文中用到的数据是利用Python软件爬取的哔哩哔哩网站上的用户观看视频行为信息。首先爬取哔哩哔哩网站上热门番剧的ID,然后根据番剧ID爬取番剧信息及追番用户的相关信息。最终用于实验仿真的数据集是包含10 000行12列的用户-视频信息数据。
3.2 消 噪
为避免噪声数据对数据体量、复杂度以及处理结果准确率和时效性的影响,利用小波方法对样本数据进行消噪处理,消除数据集中无效或异常的数据,提高数据的收敛速度和模型预测的精度[16-18]。
由图1可以看出,经小波去噪后的数据与原数据相比,数据的大体趋势并未发生变化。小波消噪可以在保证数据连续性和科学性的前提下,避免噪声数据对预测模型的扰动。
图1 小波消噪前后对比
3.3 降 维
为避免多个属性间强相关性对数据集分析产生干扰,提升预测模型的可靠性,需从番剧标签、追番人数、番剧评分、用户性别、用户等级、用户粉丝数、用户关注人数、用户评论点赞数这8个属性标签中选取对预测用户评分贡献较大的特征属性,降低预测模型的复杂度。在对数据集进行降维处理的过程中,需要保证筛选出的属性要尽可能多地表征样本数据的大部分信息,否则将不会降低数据分析的难度和复杂度,甚至会导致分析失败。
将番剧标签、追番人数、番剧评分、用户性别、用户等级、用户粉丝数、用户关注人数、用户评论点赞数这8个属性标签分别编号为1-8,通过递归特征消除法对样本数据中各属性的贡献值进行筛选[19]。
图2为各属性对预测结果的贡献值,设定阈值0.85可以将原来的8维数据集降为5维数据集。选出的5个主要特征属性分别为:番剧标签、追番人数、番剧评分、用户性别、用户等级。将筛选出的5个属性用于模型训练。
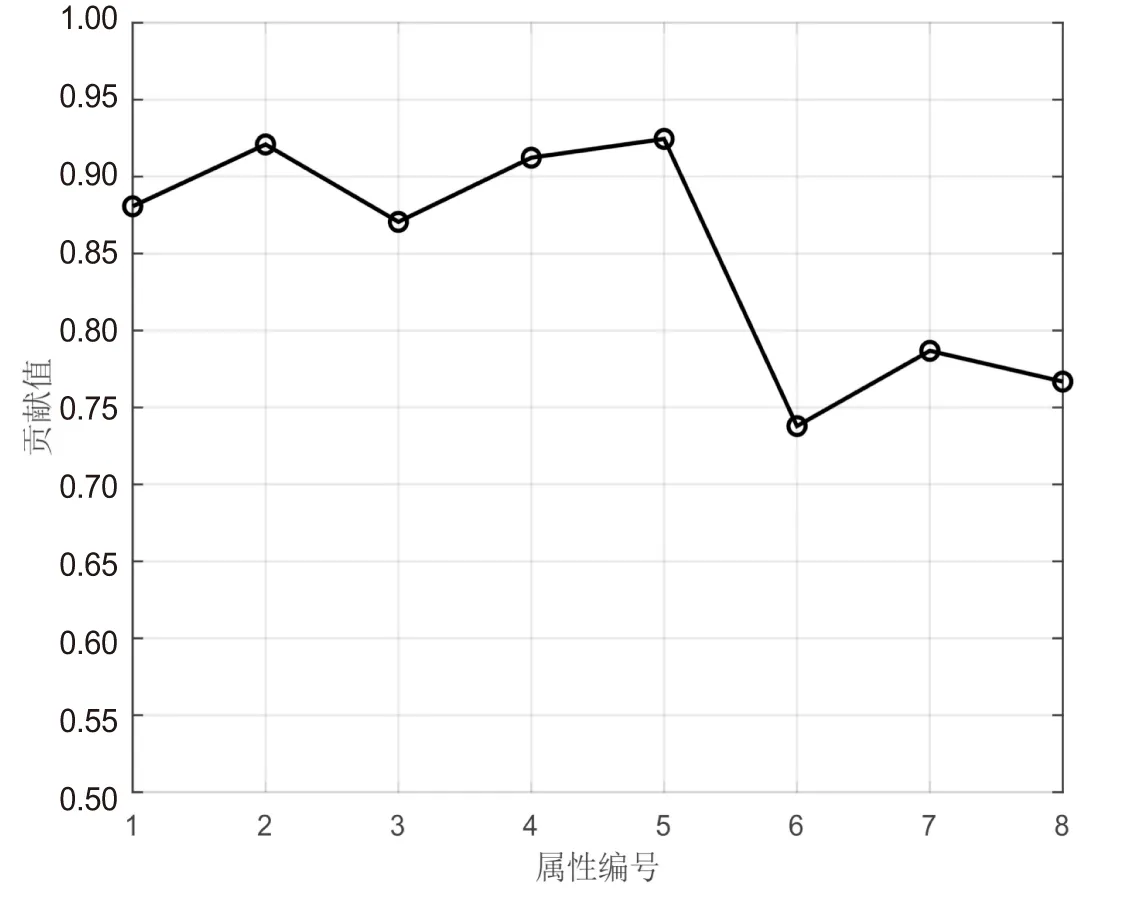
图2 各属性贡献值
3.4 归一化
为避免因属性量化级不同带来的预测偏差,利用min-max标准化公式对样本数据进行归一化处理。
(11)
其中,xi为属性中第i个样本的数据;xmax和xmin为属性的最大值和最小值。
图3为数据集中原始的番剧评分数据与归一化处理后的番剧评分数据对比图。归一化处理后避免了因样本数据各属性间量化级不同造成的误差,可以提升模型的收敛速度和精度。
图3 归一化处理前后对比
4 实验与分析
4.1 基于不同核函数的SVM视频用户需预测模型
首先将数据集分为训练集和预测集两类,将数据集的70%作为训练集,30%作为测试集。在模型训练的过程中,分别基于表1中三个不同的核函数构造SVM视频用户需求预测模型,预测结果如图4所示。

表1 不同核函数的表达式
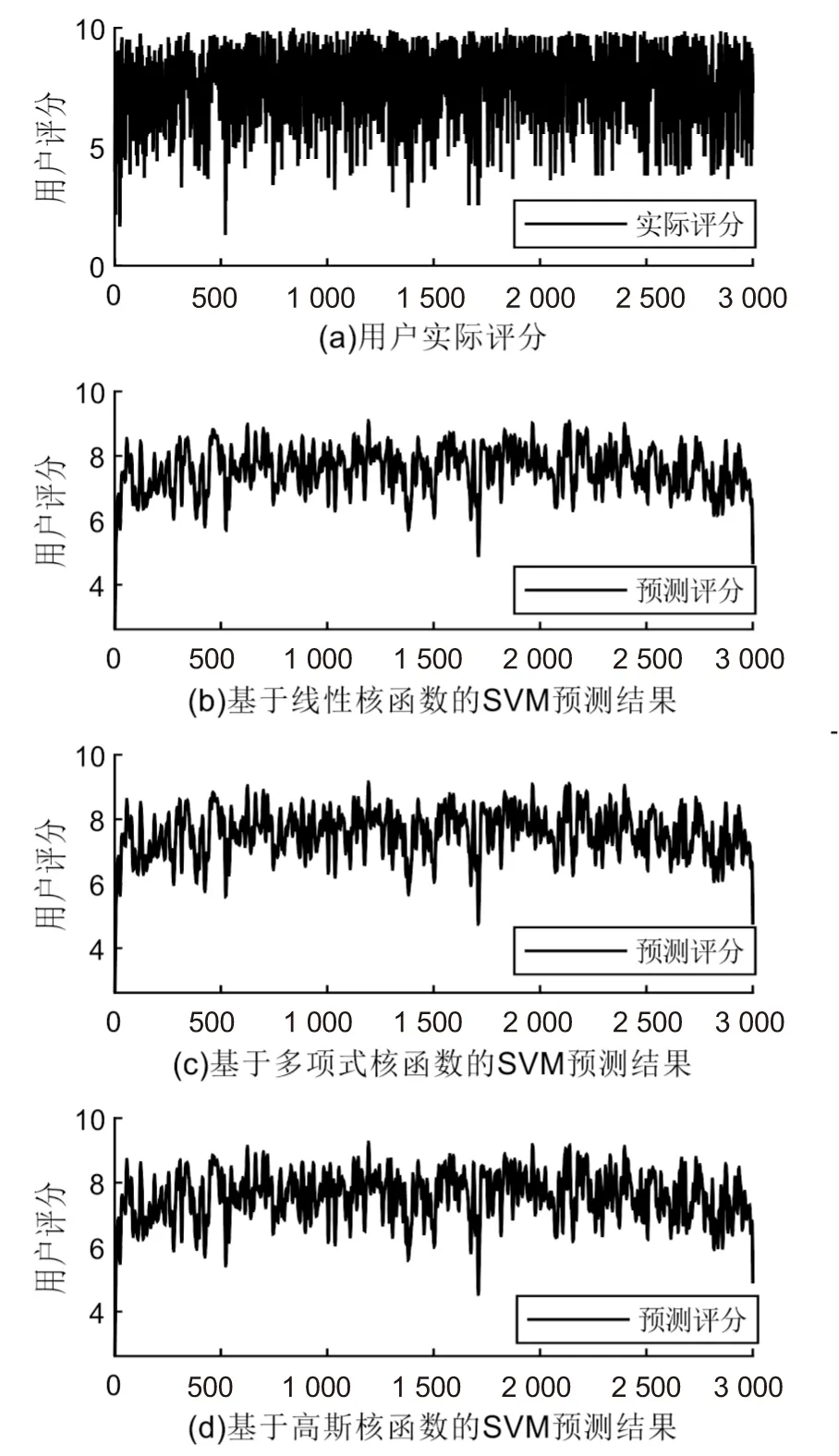
图4 基于不同核函数的SVM预测结果对比
选取均方误差(MSE)、平均绝对百分比误差(MAPE)和准确率(Accuracy)三个评价指标分别从预测误差和预测精准度两个方面对不同核函数下的SVM视频用户需求预测结果进行对比,结果如表2所示。

表2 基于不同核函数的SVM用户需求预测效果对比
根据统计学原理可知,MSE、MAPE两者的数值越小,表示预测值与真实值的误差越小,即预测结果越接近于真实值,而准确率越高表明预测模型的预测效果越好。对比表2中不同核函数下的SVM预测结果可知,基于高斯核函数的SVM视频用户需求预测模型预测效果较好。
4.2 参数调优
为降低视频用户需求预测模型的预测误差,提高预测的准确率,现针对高斯核函数下的SVM视频用户需求预测模型进行参数调优。随机选取4组参数对(C,δ)进行对比实验,其中C为惩罚系数,δ为高斯核函数系数,预测对比结果如图5所示。

图5 基于不同参数对的SVM预测结果对比
通过对比表3中不同参数对SVM视频用户预测模型的MSE、MAPE和Accuracy,可以得到C=2.25,δ=1.25时的SVM视频用户需求预测模型最佳。
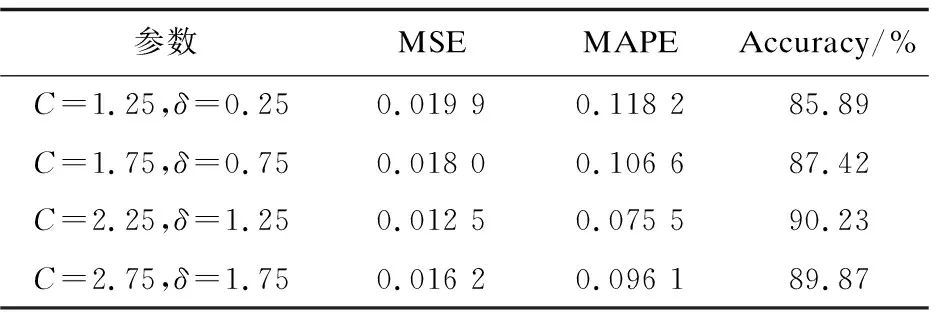
表3 基于参数C和δ的SVM预测效果对比
5 结束语
文中将用户观看视频行为的数据作为训练集,以用户数据及其对视频需求的关系为基准,提出基于不同核函数下的SVM视频用户需求预测模型,并对高斯核函数下的SVM视频用户需求预测模型进行参数调优,通过对预测结果的误差和准确度进行对比分析,验证了参数优化的有效性。优化后的SVM视频用户需求预测模型的预测结果的MSE为0.012 5,MAPE为0.075 5,准确度为90.32%。该研究成果有助于运营商精准掌握用户需求,提升平台为用户推荐视频的成功率,减少用户在海量网络视频资源中搜索视频内容的时间。未来还需进一步考虑如何结合神经网络算法对参数进行智能调优,进一步降低模型预测的误差,以提高预测的准确度。
