基于空间及图像信息融合的目标智能识别技术
2021-05-31程勇策
程勇策,郑 尧,赵 涛
(1.中国电子科技集团第三研究所,北京 100015;2.陆航研究所,北京 101121)
0 引 言
目前,目标检测能力在光电侦查、光电监视及导航制导等领域的应用受到越来越多的重视[1-3]。单纯依靠图像信息进行检测方法存在实时性较差、弱小目标检测困难以及易受环境影响等问题。因此,为获得更为精确的目标检测和识别率,光电侦查系统往往采用多光(如可见光和红外等)架构,或借助激光或毫米波雷达的信息对目标识别进行辅助判别。多源信息融合可以对同一目标进行全面详尽的描述,异源信息可以提高互补性,增加对图像理解的可靠性,但这也极大地增加了系统的复杂度。
目前,基于多源信息融合的目标检测方法受到研究人员越来越多的关注,其更多地应用在自动驾驶和光电监测等领域。卡耐基梅隆大学的Urmson等人[4]在自动驾驶的研究中,提出使用激光雷达和彩色图像信息融合的目标检测方法,实现车辆周围环境的快速感知。
SAIC公司推出了一款光电与雷达融合监控系统[5]。该系统用于地空、海洋、陆地或者岸基警戒等安全领域,可将光电与雷达的数据进行软件集成,使用导航雷达探测目标后,自动引导光电调整到位进行目标进一步识别。Karpathy等人[6]开展了基于红外和可见光图像数据源融合的行人和车辆目标检测方法的研究,提出了基于孪生深度卷积神经网络,在不同融合机制下,很好地实现了目标检测和分类。Zhang等人[7]根据监视台站长期积累的可见光图像和红外图像,建立了相关多光谱的数据集,利用Matlab的深度学习组件对双光谱的舰船图像进行了训练,并且在可见光图像无法获取目标时,利用红外光谱图像对目标进行识别。上海大学的奚玉鼎等人提出一种红外、可见光以及雷达融合探测的低、慢、小目标识别系统,系统可针对海基和岸基的应用进行调整,信息处理系统可以将雷达、红外及可见光图像进行融合,实现目标的融合判决。国防科技大学的项目[8]提出以激光雷达和可见光立体视觉为基础,基于深度学习的方法,实现障碍物识别以及行人和车辆感知。虽然采用多光谱相机或者加装雷达和激光等设备后,光电监视系统对目标特性的检测能力大大增强,尤其在距离信息与速度信息提取方面更具有优势,但是这将大大增加系统的成本,同时,存在系统待处理数据量过大的情况,这也对信息处理硬件的处理能力提出了很高的要求。
本文提出一种基于Dezert-Smarandache(D-S)信息融合理论的目标识别方法。该方法采用了准确率较高且可以在移动硬件端部署的轻量级网络——MobileNet+SSD的卷积神经网络作为图像信息的依据。在该网络中,通过密集链接实现特征层的快速增广,有效降低了模型的参数数据量,实现了模型的轻量化。该方法借助光电伺服系统提供的目标空间特征,获取目标的空地位置、角速度及速度等信息,最终采用Dezert-Smarandache理论对识别结果进行融合判决,实现对目标类型(人、车、船及飞机)的检测和分类。
1 目标的智能识别方法
1.1 基于MobileNet+SSD卷积神经网络的图像目标检测
目前,移动设备端的计算能力很难满足当前表现较好的目标检测网络对计算能力的需求,因此需要对网络进行结构剪枝和参数蒸馏等操作。MobileNet+SSD系列卷积神经网络是一种新结构的轻量型目标检测网络[9],可以在保持较高检测准确率的情况下,有效减少网络中的参数量与计算量。因此本文选取MobileNetV2网络作为特征提取网络并进行适当改进。相较于MobileNetV1网络,MobileNetV2网络引入了线性瓶颈(Linear Bottlenecks)和 反 向 残 差 块(Inverted Residual block)。在网络输出维度较小层后,线性瓶颈只采用线性激活函数而非ReLu非线性激活函数,这种改进降低了使用ReLu非线性激活函数造成的信息损失。反向残差块的设计采用了先升维、后降维的结构,与传统的残差块先降维、后升维的结构相反。反向残差的结构可以解决训练时随着网络深度增加而出现的梯度消失问题,使得反向传播过程中深度网络的浅层网络也能得到梯度,使得浅层网络的参数也可被训练,从而增加了特征表达能力。MobilenetV2的瓶颈结构如图1所示。

图1 MobilenetV2瓶颈图
瓶颈层中图像参数的输入与输出情况如表1所示。其中,k和k´分别是瓶颈层输入和输出图像的通道数;h和w分别是输入图像的高度和宽度,t是扩张系数;s是步长。

表1 MobilenetV2瓶颈层的输入输出
瓶颈的设计还采用了反向残差块的整体结构模式,特征图在计算中采用先升维、后降维的策略。本文采用的瓶颈结构如图2所示。与原网络不同的是,借鉴在s=1时的残差连接结构,在输出特征图大小一致的瓶颈之间采用图像拼接代替残差连接。实验证明,这样的结构可以借助特征复用来提升信息和梯度在网络中的传输效率。尽管特征图拼接会造成瓶颈输出通道数的快速增加,从而导致网络参数和计算量的增加,但通过适当降低瓶颈的扩张系数t,可以实现对网络规模的控制。

图2 本文的瓶颈结构
在网络设计方面,本文将Dense-Net的密集连接应用于MobileNetV2+SSD的网络中。本文的特征提取网络MobileNetV2没有采用多个输出通道堆叠的方式,而是对瓶颈的输出通道数进行放大,最终实现通道的增长。结构中首先堆叠数个步长为1的瓶颈,并采用密集连接对输出通道进行拼接,以提高网络通道数量。同时,为了保证网络的复杂度与特征提取能力,使用了t=1、s=1的瓶颈和t=1、s=1的瓶颈的组合来完成输出通道数缩小。改进的MobileNetV2+SSD网络的结构如图3所示。
在MobileNet特征提取网络中,瓶颈结构的拼接在一定程度上可以代替或者部分代替扩张系数对于通道数的扩张作用。本网络在卷积层较深的位置采用了较小的扩张系数,如第13、14、17及16个bottleneck部分。
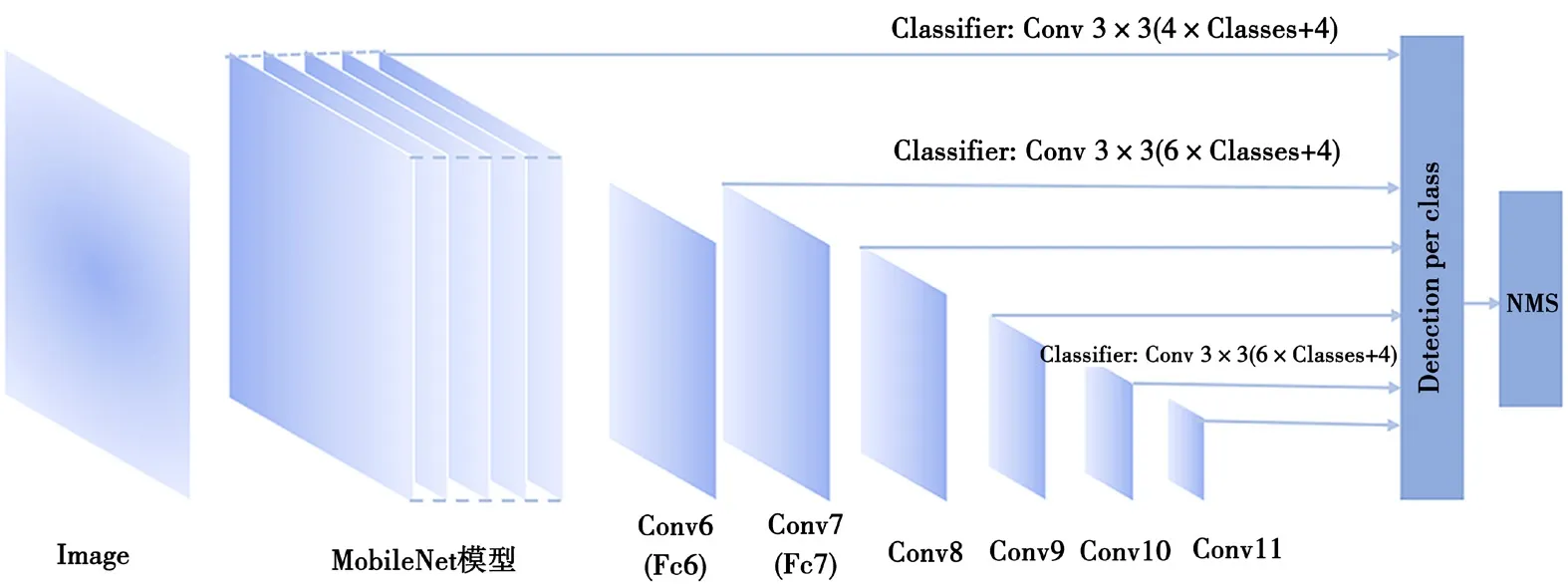
图3 改进的MobileNet+SSD网络结构
瓶颈参数的计算方法为:

式中:p为网络参数数量;t为扩张系数;Cin为图像通道数;Cout为输出通道数。
MobileNet网络结构中,关键特征提取层对应的输入输出参数和计算量如表2所示。改进网络的参数量为245 864个,较之前的网络结构参数量减少约17%,计算量减少了约13%。网络结构经过改进后,计算量与参数量都有明显的降低。参数与计算量减少的原因为:在原网络中s=2的瓶颈会对输出的通道数进行放大,这些输入经过多层传递后必然会产生更多的计算量。而拼接结构s=2的瓶颈的输出通道数较少,即这些瓶颈内的参数与计算量也较少。通过拼接的方式不会进行多余的计算。
MobileNetV2+SSD网络结构共有29层网络结构。其中,MobileNetV2特征提取网络有17层,其余12层由17层网络衍生而成,其作用是为SSD提供不同尺度的特征图。本文沿用了SSD的基础结构,未对其进行改进。
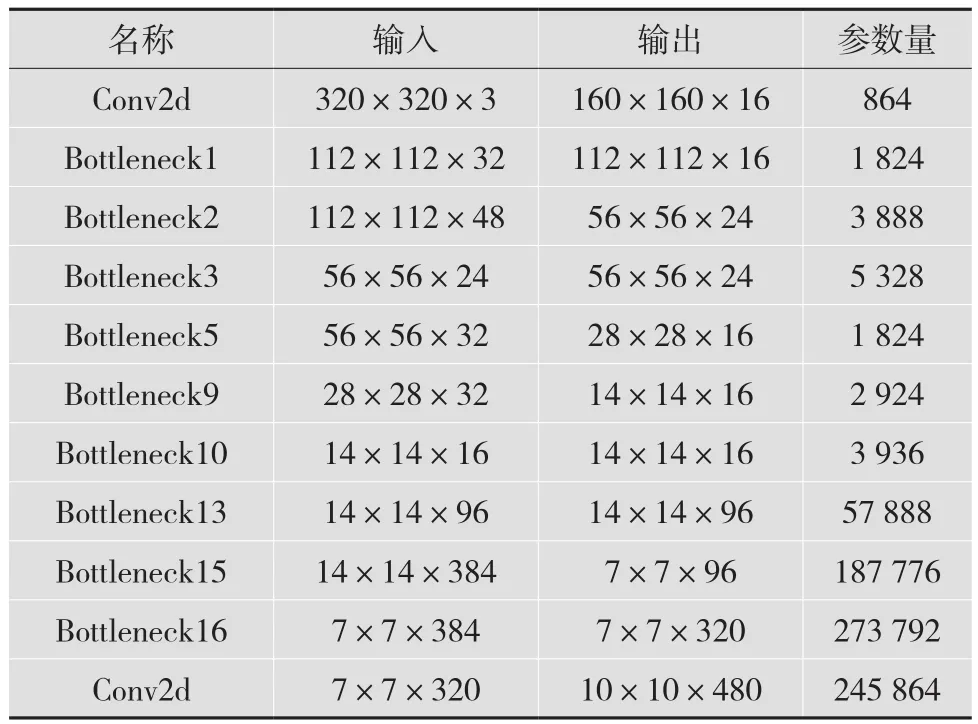
表2 MobileNet网络部分计算参数以及计算量
1.2 基于伺服信息的目标分类方法
基于伺服信息的目标组分类是通过光学仓伺服控制系统的陀螺和GPS提供的转台的方位角度、俯仰角度、相应的角速度以及位置信息来判断目标的大致类型。由伺服提供的信息和图像信息,虽然不需要伺服信息和图像在时间上进行融合,但是需要传感器和伺服系统在时间上的同步输出数据。根据伺服系统陀螺仪工作手册,其采样频率为1 000 Hz,图像传感器的采样频率为25 Hz。以采样速率慢的传感器为基准向下兼容,在第40 ms、80 ms、120 ms等时间节点,在伺服和相机报文刷新时,进行信息采集和融合工作。其时间同步如图4所示。
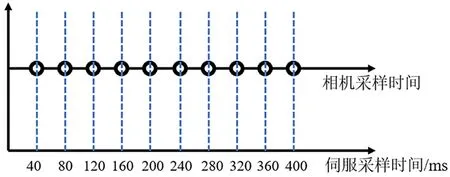
图4 伺服和相机时间同步示意图
基于伺服信息的目标识别流程如图5所示。首先,根据伺服的GPS信息判断系统的安装位置和安装高度;其次,通过俯仰信息判断得到观测物体的大致俯仰陀螺的方位信息(光轴的指向),判断其为地面物体还是空中物体;最后,通过方位陀螺的角速度信息近似判断物体的速度。最终形成地面低速、地面高速、空中低速以及空中高速4大类物体特征。
2 多源信息融合的目标识别技术
多源信息目标智能判决技术主要通过对图像识别结果和伺服转台信息进行融合判决的形式对目标进行判别,筛选那些判别概率最大的结果。由于低、慢、小目标辐射噪声的多源信息是在光电探测器和伺服信息在不同机制下获取的,多源信息之间配准困难,因此,本文采用D-S证据理论的目标融合验证方法,如图6所示。
根据D-S判决理论[10],将判决的光电伺服跟踪目标种类的所有可能结果通过识别框架Θ进行表示,且Θ中的元素是互不相融的,Θ中所有子集为2Θ。定义Θ上的函数m:2Θ→[0,1]满足:

式中:m(A)为A的基本概率赋值,表示对识别结果A的信任度。空集的信任度为0,识别结果信任度之和为1。
在识别结果中存在子集A满足m(A)>0,则称A为识别结果的一个焦元。定义识别框架Θ上的置信函数为B,函数可以表示为:
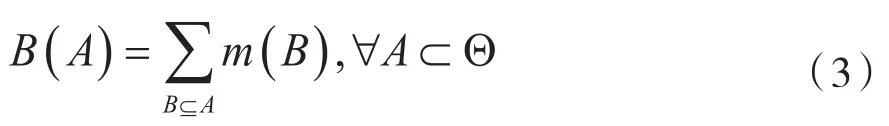
识别结果的合成规则为:将多个组识别结果转化为一个融合的识别结论,从而实现多识别结果的融合。即可以通过求解同一焦元的子集基本概率赋值的正交和,求得该焦元的合成概率指派:
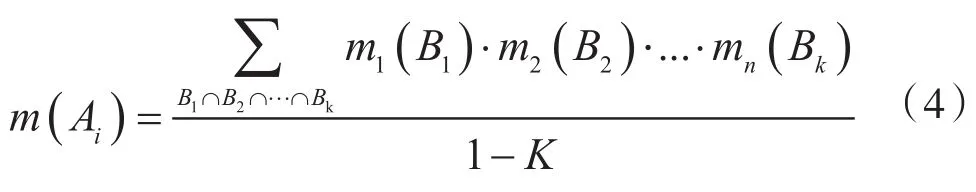

图5 基于伺服信息的目标识别流程
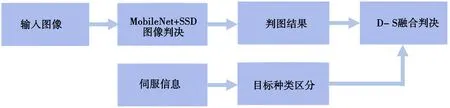
图6 D-S目标信息判决理论智能判决技术
融合判决对基于伺服信息的判断设定为:当判定地面低速目标时,该焦元的基本概率赋值设定为0.7,地面高速目标的概率赋值设定为0.3,其他焦元设定为0,其他情况同理。
3 实验结果和分析
本文的实验环境为Linux Ubuntu 18.04系统,核心处理器为Intel i7 9700,内存为16 GB,图形计算单元为 GTX 1080 Ti,采用 PyTorch1.2,Cuda10.0,Cudnn7.5,用的数据集为COCO 2012数据集中人、车、船、飞机部分数据以及自主采集数据,网络训练选择人、车、船及飞机的图像各2 000张,测试图像各200张。
测试的loss曲线如图7所示。从图7可以看出,loss曲线在训练最初下降速度较快,而后loss值变化趋于平缓。改进后,loss平稳后的值与原始网络相近,说明在对原始网络的规模进行缩减时并没有使网络的训练变得困难。
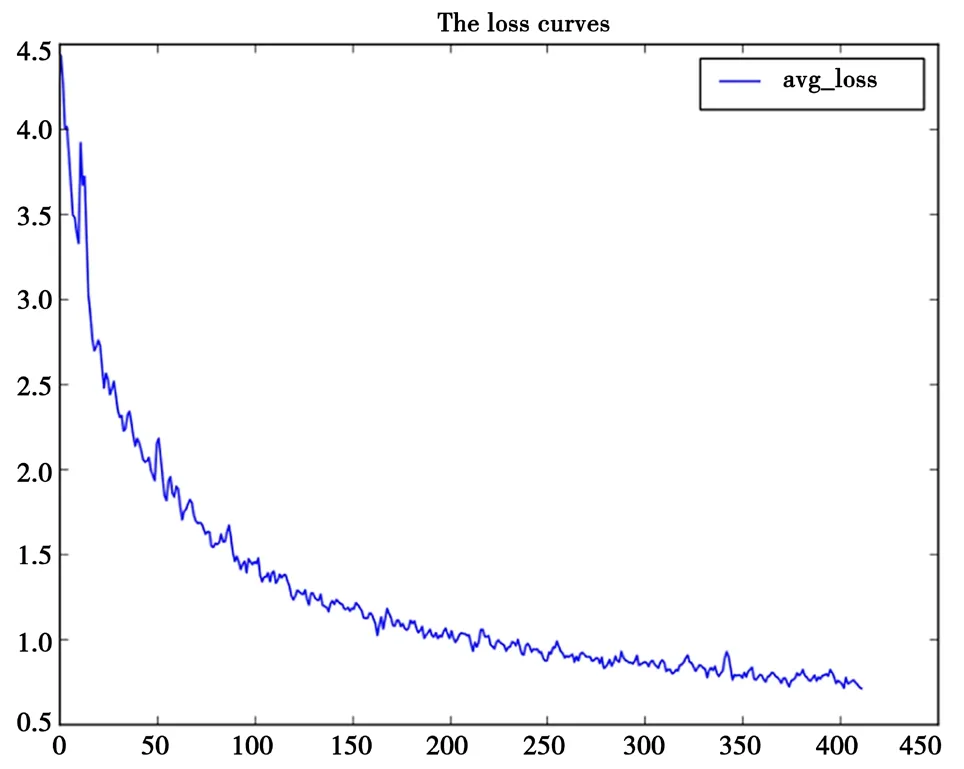
图7 loss曲线
网络在测试集上的准确率变化如图8所示。从图8以看出,在测试集上,改进网络和原始MobileNetV2网络在典型图像场景检测任务方面都有着较高的准确率。其总体趋势为:交并比(IoU)越高,召回越低,并且在整个训练测试中,改进网络的表现优于原始的MobileNetv2网络。例如,在召回率为0.8时,改进网络的IoU提高了约5%。
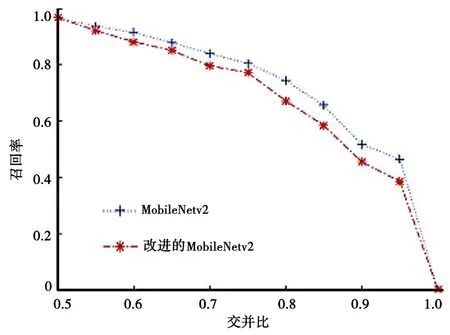
图8 网络在测试集的准确率变化曲线
根据D-S证据理论对外场试验采集的图像进行检测并和伺服参数进行融合判决。仅取图像检测时4个结果的可能性作为4个焦元,并将图像检测和根据伺服参数估计的结果作为证据信息融合图像检测结果,如图9所示。其中,对图像9(a)的判决结果如表3所示。针对图9(b)基于D-S信息融合的伺服空间和图像信息融合结果如表3所示。可以看到,仅仅依靠图像信息,汽车的检测的置信度仅为38%,而飞机的置信度为44%,出现了明显的判读误差。但是根据转台提供的空间信息对汽车判别,根据式(4)进行融合判决时,可以看到检测目标的识别种类为汽车,检测置信度上升到81%,极大地提高了检测的准确率。

图9 图像融合检测结果

表3 基于D-S信息融合的伺服空间和图像信息融合结果
4 结 语
本文提出了一种基于图像识别信息与伺服系统提供的空间信息相融合的目标检测和识别算法。该技术的图像识别算法采用了改进的MobileNetV2+SSD图像检测算法,图像检测较原MobileNet+SSD网络计算量降低12%左右,检测精度最高能达到81%。信息融合采用D-S信息融合方法,对弱小目标的判别准确率可以达到70%,较之前提高21.5%,尤其针对图像网络难以识别的小目标,检测准确率提高明显。
