基于LDA的地铁施工安全隐患排查要点挖掘与可视化研究
2021-05-31
(华中科技大学 土木与水利工程学院,武汉 430074)
引言
为缓解交通压力,我国轨道交通建设呈现快速增长趋势[1]。伴随着地铁的高速建设,地铁事故也接踵而至。隐患排查工作已在地铁施工的全生命周期中占据重要地位,隐患作为导致事故的源头,受到国家和企业的高度重视,因此很多地铁企业将遏制事故发生的关注点转向隐患的辨识、响应和消除[2]。 目前,施工安全员主要借助地铁施工隐患排查系统查询、存储和统计隐患,对于系统中积累的大量非结构化隐患排查记录,存在信息处理慢、信息不共享等问题, 导致文本中隐含的易发隐患、隐患排查要点、隐患内部联系等信息并没有被挖掘,且由于文本数量冗杂,相关工作严重依赖导则与安全员经验,需要投入大量人力成本,如何挖掘有效信息显得尤为重要[3-4]。
以上研究为地铁施工隐患管理提供了有益思路,隐患排查系统在地铁施工隐患管理过程中占有重要地位,但是隐患排查系统中积累了大量隐患排查记录分析工作严重依赖导则与地铁安全管理工作者,并且研究发现关于挖掘隐患主题和隐患排查要点的研究还相对较少[8-10]。由于系统隐患排查记录信息冗杂,难以通过人工阅读或简单统计的方式处理地铁施工隐患文本数据,需要花费很多人力和物力[11-12]。为解决上述问题,提高隐患排查工作效率和安全管理决策,同时促进排查工作实现全程自动化,本文提出了一个自动化分析隐患记录框架,框架集合中文分词技术、TF-IDF(Term Frequency-Inverse Document Frequency)算法、基于Gibbs的LDA(Latent Dirichlet Allocation-Gibbs)主题模型算法、WC(Word Cloud)技术和WCN(Word Co-occurrence Network)分析技术。基于此框架,借助了文本挖掘技术和可视化技术的优点,地铁隐患排查系统中积累的历史数据下隐含的隐患信息可以不用花费人力被发现并被进行可视化展示,这些信息为指导隐患排查工作提供数据基础,实现从海量数据中挖掘隐患排查要点,提高文本处理效率,从而节约人力和物力。
1 地铁施工安全隐患排查要点挖掘及可视化
地铁施工隐患排查记录中蕴含反映地铁施工隐患主题的知识,但由于文本数量庞大,难以通过人工阅读的方式归纳总结,需要花费很多人力和物力。为解决上述问题,本文提出了一个自动化分析隐患记录框架,具体框架如图1所示,此框架实现自动化分析隐患记录的目的,从而节约人力和物力。
1.1 隐患数据来源
本文选取的隐患数据来源是武汉地铁施工隐患排查记录,搜集时间范围从2016年到2018年在建地铁线路的3 000条施工隐患排查记录,具体在建施工地铁路线为武汉地铁5号、6号、7号、8号、21号、27号地铁线等。地铁施工隐患排查系统中积累了大量的隐患排查记录,记录中包含:隐患编码、下发时间、线路、标段、工点、隐患部位、隐患描述和隐患等级等,在本研究中,借助隐患下发时间、隐患部位和隐患描述来挖掘有价值的信息,部分记录见表1。
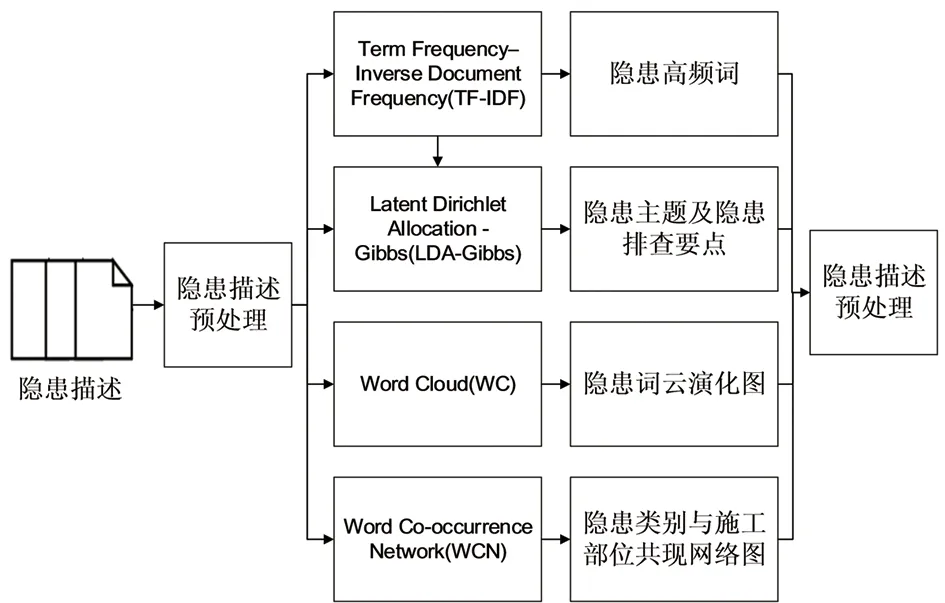
图1 地铁施工安全隐患排查要点挖掘与可视化流程图
1.2 隐患数据分析方法
借助Python软件,首先对隐患描述进行数据预处理(中文 jieba 分词、去停用词处理、自定义词典),随后借助文本挖掘技术和可视化技术的结合,主要进行了4项步骤:
(1)利用Term Frequency-Inverse Document Frequency(TF-IDF)算法估计一个词语对一个文档集的重要程度,从而对隐患描述下的关键词有一个整体的概括[13-14];
(2)基于TF-IDF筛出特征值较高的关键词,在挖掘文本主题之前,需要估计最佳主题个数,从而使聚类结果达到最优,本文采用经典指标困惑度(Perplexity)确定最佳主题个数K[15], 然后吉布斯(Gibbs)抽样的Latent Dirichlet Allocation(LDA)模型识别出大规模隐患描述语料库中潜藏的主题信息和隐患排查要点[16, 17];
(3)结合时间维度,通过Word Cloud(WC)技术[18]对隐患描述进行可视化分析,绘制隐患词云演化图;
(4)基于LDA-Gibbs聚类主题,推断隐患描述标签,定义隐患描述类别。结合隐患描述类别和隐患,借助可视化软件Gephi[19],绘制隐患Word Co-occurrence Network(WCN)[20],挖掘隐患内部相关关系。

表1 原始语料集合简单样本
2 结果分析
2.1 隐患高词频分析
为了提高管理者和地铁一线施工工人对隐患的快速认知,本文借助文本挖掘技术有效自动挖掘隐患排查信息。根据TF-IDF中TOP20的规制,抽取2016-2018年隐患描述关键词,初步概括隐患高频关注点。如表2,TF-IDF值代表所对应的关键词对于整个语料库中的重要程度,前五TF-IDF值对应的“基坑”、“临边防护”、“一闸多机”、“配电箱”、“钢筋”关键词经常出现在隐患描述中,这提醒管理者在地铁施工过程中,应时刻注意基坑的状态,加强临边防护措施,严禁一闸多机行为,时刻检查配电箱状态,规范钢筋施工工序等。

表2 隐患高频词分布
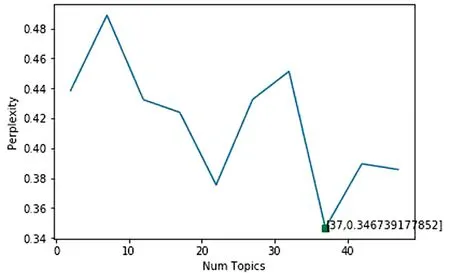
图2 LDA-Gibbs主题模型困惑度
2.2 地铁施工隐患排查要点
基于LDA-Gibbs算法,参数α经验值为1/K,β为0.01,关键词为10。困惑度变化图像如图2所示,最小困惑度对应的主题个数K=37,通过进一步专家筛选,最终得到主题个数为34个,见表3。
根据LDA模型文本聚类的特征词,经专家判断并结合数据源描述,进而发现每个隐患主题下包含的隐患排查要点,从而推断所对应的隐患主题。如表3中序号1所对应的关键词(“吊装”、“吊车”、“汽车吊”、“支腿未打开”、“资料”、“吊钩”、“限位器”、“小钩”、“未报备”、“保险装置”),进而归纳总结得到表4序号1对应的起吊设备隐患排查要点(“吊车支腿未打开”、“吊车资料未报备”、“吊车小勾未设置限位器”、“吊钩保险装置损坏”),最后推断隐患主题为“起吊设备隐患”,从中可以表明施工工人在布置起吊设备时,需要注意前期吊车资料是否报备,吊车支腿是否打开,吊车小勾是否有设置限位器和吊钩保险装置是否损坏等要点。基于LDA模型分析武汉地铁2016-2018年施工安全隐患排查记录数据过程中发现的隐患排查要点问题,表4中归纳总结出每个隐患类别下的排查要点对于指导隐患排查可以起到借鉴和指导作用。

表3 地铁施工隐患主题挖掘结果
同时,基于 LDA挖掘的地铁施工安全隐患主题:起吊设备隐患、模板隐患、消防设备隐患、上下通道隐患和现场用电隐患等34主题(具体可见文中表格4),对隐患安全分类标准具有一定的参考价值。将隐患主题分门别类,对应隐患34个类别,使其成为一个有序的组合,并将其应用于隐患信息系统下隐患分类的下拉列表,辅助未来的隐患排查工作,为组织开展轨道交通安全质量隐患排查治理工作提供借鉴,并弥补隐患分类还没有一个统一的及普遍认可的分类标准的空白,基于LDA模型实现将抽象的非结构化数据到知识的转化,提高了文本处理效率,极大地节约了人力物力,同时识别出的隐患主题/类别为系统工程分类标准规范提供理论依据。
2.3 隐患词云演化分析
为了帮助管理者及一线工人快速捕捉地铁隐患信息,借助词云图技术为地铁安全管理工作者提供一种全新的可视化视角,更加直观地提示管理者着重控制关键隐患部位以及预防致因。
如图3所示,2016-2018隐患词云演化图表明,各年份地铁施工关键词如下:2016年为“基坑”、“临边防护”、“一闸多机”; 2017年为“基坑”、“出入口”、“架设不及时”; 2018年为“基坑”、“钢筋”、“临边防护”。从各个阶段隐患关键词的热点分布图中由此可以分析:
(1)“基坑”是地铁施工中存在隐患的主要施工部位,随着城市建设的飞速发展、人口密集越来越大,基坑的开挖深度已经从原来的4-6m发展到现如今最深的已达20多m,在地铁工程施工过程中,基坑作为隐患高发部位,对基坑工程的质量进行控制尤为重要[21];
(2)“钢筋”工程在建筑施工质量管理中的重要性也逐渐凸显。现代化地铁工程施工要求日新月异,地铁钢筋施工质量管理工作的难度和重要性也随之提高,现场施工管理人员在隐患排查工作中需要更加便捷和有效的手段来严格监督管理钢筋工程的施工进度和施工质量[22]。
此外,根据词云图关键词之间的相对位置,在一定程度上描述和揭示隐患关键词之间的相互关系—关键词相对位置距离相近,表明这两个关键词经常出现在同一种隐患事故中。比如在词云图(a)中,“一闸多机”与“不规范”相对位置较近,表明施工工人在设置配电箱时经常出现操作不规范的行为。这就为施工管理人员的隐患排查工作指引了方向,可以针对这一问题着重规范现场施工人员在安装配电箱时严禁“一闸多机”的行为。在词云图(b)中,“架设不及时”与“钢支撑”、“安全隐患”相对位置较近,说明地铁施工过程中,“钢支撑架设不及时”会带来严重的“安全隐患”问题。例如:“钢支撑架设不及时”会导致围护结构水平变形及地表沉降急剧增大,从而对周边环境产生不利影响。那么施工人员在隐患排查工作中就应该提高对钢支撑架设时间节点的关注。在词云图(c)中,“出入口”与“堆放”、“安全隐患”联系紧密,表明在地铁施工过程中,“出入口”地点由于材料“堆放”常常会带来严重的“安全隐患”,如:工人在出入口被物体绊倒而受伤或者出入口因材料堆积而引发坍塌事故等。这表明施工管理人员应当着重加强施工现场建筑材料堆放的规范管理,特别是出入口必须保持通畅,不得堆放任何材料和杂物,预防因材料堆放不合理导致的安全事故发生。
2.4 地铁施工隐患共现分析
为了发现各类隐患在不同施工部位发生的情况,建立隐患部位—隐患类别共现网络图。图中的节点分别代表34种隐患类别和其所对应的若干施工部位,如图4所示。
从图4中网络节点的大小可以发现易发隐患前5名是临边防护隐患、现场用电隐患、工人安全防护用品隐患、杆件搭设隐患、钢筋隐患,并且从点与点连线的粗细可以发现共现关系,例如:隐患发生部位“基坑”与这三大隐患类别(“现场用电隐患”、“工人安全防护隐患”和“临边防护隐患”)存在密切的共现关系,表明在地铁基坑施工过程中, 施工安全员应该密切关注“现场用电隐患”、“工人安全防护隐患”和“临边防护隐患”主题所对应的相关隐患排查要点。图4可视化地描述和部分揭示隐患主题与隐患部位间关系,且促进施工管理人员对关键节点信息的快速信息化访问。

图4 隐患部位—隐患主题/类别网络图
3 结论
本文提出了一个基于文本挖掘和可视化技术的自动化分析隐患文本框架,并以武汉地铁施工隐患排查记录为数据源验证框架的有效性,此框架是一次数据驱动安全隐患排查管理的有效尝试,同时以一种全新的可视化视角为安全隐患排查管理开辟了一种新思路。总结而言,本论文的研究成果与结论主要有:
(1)本文提出了一种基于文本挖掘与可视化技术的自动化分析隐患排查文本框架,该框架可实现自动化分析大量安全隐患记录,有效发挥隐患管理系统积累的历史数据的最大价值,提高隐患信息的数据驱动进程和隐患排查工作效率,同时提高安全管理决策和促进排查工作实现全程自动化。
(2)本文将LDA-Gibbs模型应用于从大量的非结构化地铁施工安全隐患描述文本中,识别出了34个隐患类别和相对应的隐患排查要点且将34个隐患类别与丁树奎分类标准比较验证了LDA-Gibbs模型的有效性。此无监督学习方法不需要人工标注,适用于处理大数据文本,识别出的隐患是基于数据的真实反映,弥补了基于文本的地铁施工隐患自动化识别隐患类别和排查要点研究的空白。
(3)本文将地铁施工安全隐患类别分为起吊设备隐患、模板隐患、消防设备隐患、上下通道隐患等34类别,34个类别随对应的重点隐患排查要点,具体可见文中表格4。基于每一条地铁施工安全隐患类别重点所对应的隐患要点,对有效指导地铁施工人员开展安全隐患排查治理工作和促进我国地铁施工安全隐患排查要点规范标准编制具有重要意义。
(4)本文提供了一种数据驱动下隐患信息可视化展示的手段,通过词云图(Word Cloud)技术可视化表达隐患关键词分布,实现从大量非结构化隐患记录中挖掘各个阶段的对隐患关键词的热点分布,并基于时序分析得到关键词的演化路径。为进一步描述和部分揭示隐患地点与类别关系,借助词共现网络分析(Word Co-occurrence Network)为地铁安全管理工作者提供了一种可视化视角,有利于地铁安全管理工作者对地铁隐患信息的快速捕捉,从而指导安全管理决策和隐患排查工作。
