基于中心词和LDA的微博热点话题发现研究
2021-05-29林杰豪翟雯熠
刘 干 林杰豪 翟雯熠
(1.杭州电子科技大学经济学院 杭州 310018;2.澳大利亚国立大学商学院 堪培拉 2601)
0 引 言
随着现代技术的蓬勃发展,网络话题逐渐成为信息媒体中的核心主体,人们关注的重心也从早期的事件转移到如今的话题。话题检测与跟踪(TDT)就是由早期的面向事件检测与跟踪(EDT)所衍化的,这是一项关于因当今信息爆炸所引发的信息流处理技术,主要应用于检测和跟踪话题,判断多话题的一致性等话题信息任务[1]。
在中国,微博是当前用户最多,最综合的社交平台。由其2019年第4季度财务报表显示,微博的月平均活跃用户数已经达到了5.16亿人。微博拥有海量的用户群,又拥有以推文、评论等为主的强交互式社交功能,对话题生成、舆情传播、谣言散播、热点事件发展等都具有强烈的影响作用[2-3]。在这种环境下,针对微博的TDT就显得尤为重要。实现对微博热点话题的及时发现,能够帮助有关部门及时监控网络舆情,及时重塑、引导舆论环境向正面,积极的方向发展。
1 相关研究
1.1 LDA的相关研究近年来,国内外有关TDT技术的研究层出不穷,在文本类话题发现上以语言模型为主,其中LDA[4]使用生成模型的思维实现话题分配,在应用上取得了许多成果。李昌等[5]引入技术词语境IPC构成WI-LDA模型,在指定任务的主题生成上取得了更好的效果。谭旭等[6]融合ARMA模型和LDA,在情感分析中进行动态化呈现和细粒度划分。此外,为了能更直观地对比实验的应用效果,还需要确定一个主题数K作为控制变量。而关于LDA话题组数的确定方法亦层出不穷。Blei等[4]使用困惑度(Perplexity)指标来衡量模型对主题模型分配的不确定性,但这个方法对高主题数具有倾向性。王晰巍等[7]基于奥卡姆剃刀准则,将最小的曲线拐点作为主题数,但这种方法缺乏稳定性,难以确保所得解为最优解;Griffiths等[8]使用贝叶斯统计标准方法,用对数边际似然函数的方法代替困惑度指标;关鹏等[9]通过JS散度来计算每个主题—词分布参数围绕其均值的方差大小,和困惑度指标结合提出了Perplexity-Var指标。虽然这些方法都在原有指标的基础上作出了改进,但仍然没有脱离多次训练的范畴。Teh等[10]提出了层次狄利克雷过程HDP,将每一个样本独立的从混合分布中抽取,通过完成抽样过程生成最终的混合成分数,实验结果发现最佳的混合成分数与困惑度方法所得结果一致。
在多实验组对比下,运用奥卡姆剃刀法则来找到令每个实验组都具有最佳分组效果的主题数K是难以实现的。而LDA本质虽然是主题生成的概率分布,但是其最终实现的下游任务仍然是话题聚类和分组。因此在对聚类效果的评估上,聚类所使用的方法也可以作为LDA的度量指标。实验采用模拟退火遗传算法(SAGA)[11-12]这一启发式的混合遗传算法来确定共同的主题数K以便后续应用实验的对比。
1.2文本表示的相关研究相比较其他的聚类任务,文本、图像等抽样目标的聚类任务通常还要先对样本进行表示学习[13]。早期的学者们通过BOW、TF-IDF等方法来得到文本向量。刘小慧等[14]认为传统TF-IDF对热点词的研究起到反效果,提出了改进的TFK-IDFK算法,将权重分配由原先的逆向改为正向。周源等[15]将文档分为多个子集,用不同子集中IDF值的方差代替原先的IDF。但由于离散模型的高维稀疏缺陷,分布式方法应运而生。Mikolov等[16]提出了CBOW和Skip-Gram模型来实现词嵌入(Word Embedding),随后Google在2013年开源了封装这两个模型的工具Word2Vec。马思丹等[17]通过对文本关键词划分计算两部分加权相似度后,再用线性方法加权得到文本向量。Pennington等[18]提出了Glove模型,额外考虑了整体语料库。然而,直接的词嵌入方法忽略了词序、指代消解、多义词等问题。随后,基于RNNs的深度学习开始被应用于词向量的训练,它通过现在t时刻和过去t-1时刻的特征进行输出。但是RNNs存在顺序依赖问题,一方面导致其没有并行能力,另一方面则是对长期的记忆行为比较无力。于是Sutskever等[19]用Attention机制缓解了长距离依赖问题。Vaswani等[20]开创性的提出了多层Transformer结构,通过Self-Attention机制,实现了消歧、指代消解、并行计算和双向信息流,但因为是有监督学习方法导致难以学到复杂的上下文表示。为此,Peters等[21]提出了ELMo模型,运用多层双向LSTM对每个词作编码,经过加权得到词向量。Radford等[22]用Transformer代替了ELMo的RNNs,提出了更适合特定任务的GPT。Devlin等[23]提出了Bert,采用双向Transformer,实现了Word2Vec的完全上位代替。在Google对其进行开源后,其他研究者只需要通过迁移学习后,针对特定任务额外进行Bert训练微调即可适应当前任务。至此,预训练语言模型成为了NLP领域非常重要的基础技术。由于哈工大讯飞联合实验室开源的中文模型比Google所提供的模型更加出色,后续将采用其BERT-wwm预训练模型来获取词向量,应用于SAGA的距离计算以及Bert实验组吉布斯抽样(Gibbs Sampling)时的权重系数计算。
2 关键方法设计
2.1中心词LDA方法设计LDA[4]是基于贝叶斯学习的话题生成模型,认为由文本生成了话题,又由话题生成了词,它们分别服从两个不同的多项分布。因此,只要能计算得到两个多项分布的参数向量,我们就可以得到当前语料库的话题分布。然而,多项分布的参数估计是十分困难的。根据贝叶斯派的思想,多项分布的参数向量是由其先验分布Dirichlet分布所产生的。因此可以通过超参数和近似求解的方法来进行估计,通过收缩的吉布斯抽样来生成模型。由于Bert预训练所得到的词向量考虑了词间的相关性、多义词等关系,在结合了LDA模型的文本—话题、话题—词因素后,能实现LDA模型更好的分组效果。和传统的吉布斯抽样相比,改进方法引入中心词概念,打破词间等权重现象,通过计算稀疏值为文本中每个词赋予权重。首先是稀疏值的计算:

(1)
Swmi为当前文本中词Wmi的稀疏值,|Wmj|表示与其计算距离的词在当前文本所占的频数,d表示词向量维度,参数θ用于调节后续权重值的分配效果,不同的语料库有各自适合的取值,该值越大则中心词权重分配越极端。分母则是做了归一化处理,分别消除了文本长度和词向量维度的量纲。该值越大表示以该词为中心时,周围词的分布更加稀疏,说明该词对当前文本的表示力度更低。
(2)
获取稀疏值后再采用softmax函数将特征对概率的影响转化为乘性,目的是让中心词得到更有倾向性的权重分配,随后在原式基础上额外令每个指数值减1,将其最小值变为0,否则它将弱化权重的倍数关系。最终的权重公式设计为:
(3)
Weightmi表示当前词的最终权重系数,由于稀疏值是反向指标,所以需要重新对指标作概率规范化处理。令每个文本∑Weightmi=1。一个文本的词间稀疏关系可由图1所示。

图1 文本中心词与非中心词概念图
当以Wm1为中心词时,将分别计算其与周围词的频数距离并汇总为稀疏值,作为当前文本权重的分配依据,最后将这个权重值代替吉布斯抽样时的频数计数来进行满条件概率抽样:
(4)

由式(4)可知,第一个因子反映了当前词本身词种对话题分配的影响,第二个因子反映了同一文本中其他词对当前词话题分配的影响。因此在等权重吉布斯抽样下,同一文本内难以形成统一的话题,最终将导致词间分配混乱。而在引入中心词概念后,由式(4)的第二个因子可知,文本中每个词的话题分配会向低稀疏值词靠拢,形成了“近墨者黑”效应:当前文本中的词以更高的概率被分配为低稀疏值词所分配的对应话题,这便会使得文本内的话题分配更加集中。然而,根据两者间真实话题的一致与否,这种效应分别起到引导和误导作用。其中引导效果会令距离更近的一类词更容易在最终分组中被分为同一话题,进而优化最终热点话题生成效果。而即便是在误导效果下,由于高稀疏值词被分配的权重更低,所以被误导的词在第一个因子中产生的词种话题影响会更小。
下面以“篮球”为例:“我们在体育场打篮球”,“我们逛了商场,买了篮球,吃了海底捞”。其中,“篮球”在第一句以较高权重引导了“体育”或“运动”话题,而在第二句中将以较高概率被其他低稀疏值误导为“生活”话题。但第二个句子中的“篮球”被误导分配为“生活”话题时,它对应的权重值也是一个较低的值。由式(4)的第一个因子来看,其中分母固定表示当前话题下所有词的权重和,这个值的大小由整个语料库的构成决定。而分子表示当前话题下该词的权重和,在对“生活”话题进行概率计算时,高稀疏值带来的低权重值会使分子的权重降低,从而在整体计算满条件概率时降低被分配为“生活”话题的概率。
因此,那些频繁代表了一个文本中心词的词向量更容易形成自主的话题,而频繁作为非中心词的词向量很可能在多次训练下左摇右摆得到不同的分配结果。引入中心词概念后,根据式(4)可知,文本内词间的关系影响可以整理为下述两种情况,其中高低频表示该词在整个语料库的频次,是否中心词的定义仅限每个文本内部,且中心词通常不是单个词。
a.无中心词,权重分布均匀。此时等同于等权重吉布斯抽样效果。当话题偏向一致时,文本中的词在最终分组中会有更大概率被分为同一组。当话题偏向多样时,最终分组会更加混乱。
b.中心词和非中心词。当话题偏向一致时,两者在最终分组中会有更大概率被分为同一组。此时无论各个词权重如何,对最终分组结果而言都是有利的。当话题偏向多样时,前者将会误导后者。此时若两者均为高频词,或前者为低频词,后者为高频词,则后者由于高稀疏值将弱化误导现象,使后者在其他文本中的概率计算时受到的影响降低。若两者均为低频词,或前者为高频词,后者为低频词,则将根据后者和前者的共现频次,决定后者的话题分布情况,所以后者的话题分布可能更加集中,也可能更加混乱,而前者由于高权重值将会更加集中。
总的来说,在引入中心词概念后,改进LDA模型提高了高频词的话题分配准确率,同时降低了错分话题时带来的后续干扰影响,从而使最终模型中高频中心词的话题分布更加集中,这在微博热点话题发现中会取得更好的效果。
2.2实验组评价指标设计将基于Bert和Word2Vec的模型设为实验组,基于TF-IDF和BOW的模型设为对照组。考虑到微博文本低频词种数较多的性质,Word2Vec组采用CBOW模型完成训练。实验效果通过困惑度[4]指标反映,该指标虽然在确定主题数方面有不少缺陷,但作为评价LDA模型优劣的指标仍然是合适的。
(5)
式中p(w)表示每一个词在各个话题下概率的乘积,|W|表示所有词种数。该指标的变量集中在指数部分,反映了话题分配的混乱程度,词的话题分布越集中,p(w)值越小,即熵越小,则说明模型越好,该部分值也越小。考虑到指数的爆炸性增长性质,实验环节仅取用指数括弧内的部分用作展示。
3 文本模型处理
3.1 文本预处理
3.1.1 数据获取与清洗 为了更细化的提炼源自于微博的热点话题,本次研究根据微博热搜榜9月热点事件,分别在每日11时、23时爬取热点信息,并保留每次热搜榜前10热点,去重后共计586个榜单热点,构成用于后续分析的语料库。并在数据清洗环节剔除极端的高频词、低频词,以及发文时间不在9月的博文,这里设置高频阈值为80%,低频阈值为5。
3.1.2 中文分词与去停用词 本文采用交互式分词方法HanLP进行分词。相比较其它分词工具,HanLP在分词速度、内存消耗上有明显优势。且对于难以辨识的句子更倾向于字级别的细粒度切割,误分概率更低,更适合作为微博文本的分词方法。完成分词后,用字典法思路构造去停用词典对如“的,了”等无意义词进行过滤。考虑到热点话题词的性质,额外再剔除分词结果中的单个字。
3.2文本表示学习通过哈工大讯飞联合实验室发布的Bert中文预训练模型获取到字向量并经过少量训练调整后,将其以均值的方式计算分词后的每个词词向量。但由于Bert考虑了位置关系,所以对同一句子的重复词也将同样采用均值方法来得到最终词向量。实验中BOW组和TF-IDF组能直接构成文本向量,Bert组和Word2Vec组将会先得到词向量,再用于计算文本向量。无论是通过Bert亦或Word2Vec训练得到的词向量,都是考虑了词间相关性所得到的量化数值,两两词向量间具有计算关系,只是后者更加简单直接且仅考虑了其窗口范围的词。因此直接采用归一化,根据每个文本所属词向量和的均值作为对应的文本向量表示。
4 实验阶段
4.1确定主题数K为控制变量经过预处理环节后,本次研究真实应用的文本量为128 430。设置GA参数种群规模P为500,交叉概率Pcross为0.5,变异概率Pvariation服从均值为0.2,标准差为0.02的高斯分布,适应度函数选择DBI[24],设置SA参数初始温度T0为0.5,退火速率λ为0.999,以符合初期低概率,后期高概率的需求。如图2所示,当迭代次数为75时,DBI值连续10次没有发生变化使得迭代收敛,确定主题数为11。

图2 SAGA迭代过程图
4.2实验结果对比参数设置方面,当α采用较大的值时,由式(4)的第二个因子可知,中心词对其他词的影响力度将会被弱化,话题分配趋向于均匀,将不利于实验效果,因此设置超参数α和β均为0.01,θ设置为5。令BOW和TF-IDF两组通过传统方法得到LDA模型,而通过Word2Vec和Bert得到的词向量先经过式(3)计算得到权重,再展开收缩的吉布斯抽样得到最终LDA模型。下面只提取式(5)指数中的分子部分来观察各个实验组在主题数变化下的对比和趋势(见图3)。
通过观察图3可知,传统LDA模型指标下降缓慢,相较改进LDA模型而言几乎保持不变。在整体效果上,显然有Bert>Word2Vec>TF-IDF>BOW。由式(5)可知,生成模型中词的分布越均匀,则熵值越大,分组效果越差,当给定主题数增加时,吉布斯抽样方法能够更好的认识模型,从而有了困惑度指标对高主题数的倾向性这一现象。在改进LDA模型中,高频词分布有了更强的集中效果,因而在整体困惑度水平上显著优于传统方法。各实验组多次实现的度量指标如表1所示。
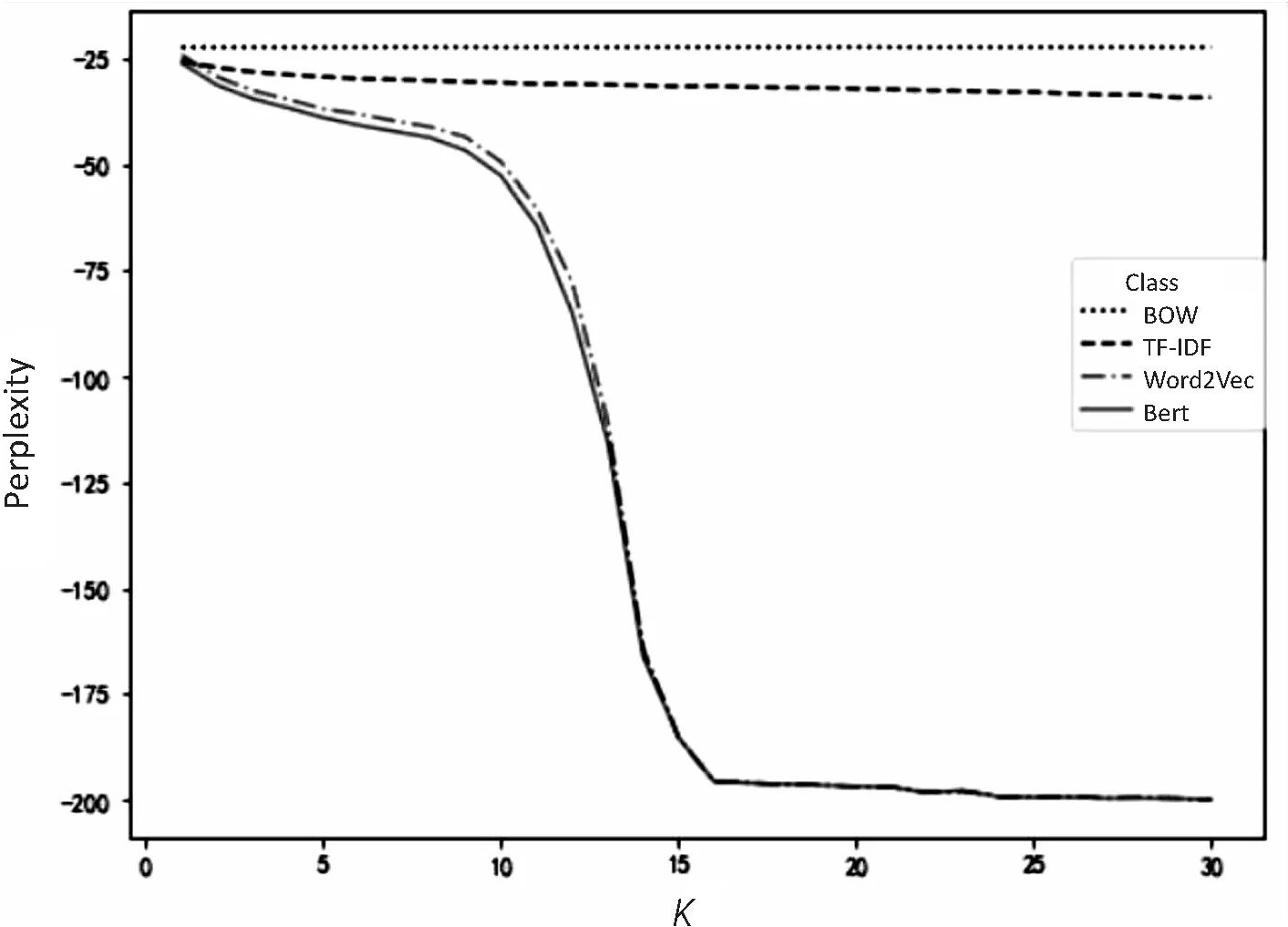
图3 实验组、对照组对比曲线图
但当主题数过小时,话题分配的满条件概率更依赖于语料库的词频构成,改进方法将不适用。如当给定主题数为1时,忽略超参数下式(5)中第一个因子将变为词频占比,第二个因子则恒为1。在改进方法中,每个文本的权重和为1,在比较语料库的权重占比中,长文本内频数较高的词在权重累计上会变得不利,此时改进方法的优劣主要取决于语料库构成。

表1 主题数为11下多组实验结果
4.3改进方法在微博热点话题发现上的应用确定LDA主题数为11,训练生成四组LDA模型。在将相似话题尽可能匹配后。展示每个话题中权重排名前6的词,对比情况如表2所示。

表2 微博热点话题生成LDA模型部分对比情况
对比表2各组LDA模型生成结果可以发现,话题1、话题2为疫情主题,话题3为双节主题。在话题1中,各组均有较好的分布表现。在话题2中,Bert组仍然有较好的分布表现;TF-IDF组和BOW组内词间差异较大,主题模糊;Word2Vec组则存在如“央视”等相关性较低的词,存在主题干扰。在话题3中,Bert组反映了新冠疫情和双节的关联;BOW组则反映了双节和文娱活动的关联;TF-IDF组和Word2Vec组内则仍有词间差异较大的现象。在其他话题中,也同样存在与上述类似的结果。由此来看,Bert组表现最佳,而Word2Vec组和TF-IDF组的表现较差。其原因在于Word2Vec虽然使用了改进方法,在总体词的话题分布上更加集中,使得总体熵值更小,但由于其仅能和窗口范围内的词直接计算距离,对其他词的关系计算不够准确,因此出现了错误的集中效果。而TF-IDF的IDF部分对高频词权重有削弱作用,同样由满条件概率公式中的第一个因子可知,高频词将更不易于被分配为同一话题,即分布更加分散;低频词则由于其高权重值影响,反而使得分布更加集中[14]。因此,Word2Vec组和TF-IDF组在最终话题生成模型上的表现并没有优于BOW组。
总体来看,LDA的热点话题发现能力非常强。这是由满条件概率公式中的第一个因子导致的,一个词的整体词频数越大,无论是否等权重,话题是否集中,在进行吉布斯抽样后将更容易作为话题高权重词出现。对比整体实验结果可以看出,在传统方法下的LDA模型中,词的分布更加均匀,它以更大的概率出现在多个话题中,故而在多次训练下,部分高频词时而出现时而消失,甚至会有部分低频词在某一组中占据较高的权重,这对微博热点话题的发现是不利的。而在引入中心词概念后,高频词的话题分布更加集中,进而帮助高频词在最终模型的各组中取得更高的权重。将BOW和Bert两组的“中国”一词作比较可以发现,Bert组的分布更加集中(见图4、图5)。

图4 BOW模型“中国”词—话题分布图

图5 Bert模型“中国”词—话题分布图
然而吉布斯抽样属于一种马尔科夫链蒙特卡洛方法(MCMC),由于其初始化分布的随机性,改进方法下的吉布斯抽样所生成的LDA模型仍会产生高频中心词分错组、左摇右摆的现象,这是由于多个高频中心词出现在同一文本下,却被随机分配了不同话题时相互误导所引起的。但此类现象相对较少,故而改进LDA模型在组间区分效果上仍会优于传统方法。
5 结 语
本研究提出了一种改进LDA模型,通过对每个文本引入中心词概念,计算每个词的稀疏值作为权重来代替传统吉布斯抽样中的频数值。实验表明,在模型生成质量方面有Bert>Word2Vec>TF-IDF>BOW,在应用中Bert也有最好的表现。此外,改进LDA模型在微博的热点话题发现中对高频中心词具有更好的提炼效果,通过这种方法,能够更好地抓住高频的“关键少数”词,从而更好地对微博舆情进行引导,能对后续的按话题展开的情感分析等任务提供基础。但此次研究仍然无法解决高频词在多次训练下分组多变的问题,因此,如何进一步改进LDA来解决此类问题是下一步工作的重点。
