面向权重可变的存算一体加速器的卷积算子调度
2021-05-28师紧想
师紧想
(上海交通大学电子信息与电气工程学院,上海200240)
0 引言
深度卷积神经网络迎来了巨大的发展,传统CPU、GPU越来越难以满足大规模神经网络对功耗和能效的需要。随着Dennard定律缩放的失效[1],存算一体加速器以低功耗、高能效的计算特点受到了广泛关注。以忆阻存储器(Resistive Random Access Memory,ReRAM)为基础的存算一体加速器是存算一体一个重要研究方向[11-12]。
存算一体加速器具有存储单元与计算单元一体的特点,因此给面向存算一体的编程和资源调度带来了困难,一些存算一体加速器[2-3]仍采用手工映射的方式部署神经网络模型。本文面向忆阻器存算一体设计了指令生成工具,并设计了算子调度策略,解决面向存算一体神经网络加速器的编程、编译问题。
1 忆阻器存算一体架构
忆阻器存算一体加速器的基本单元是忆阻器交叉阵列(crossbar),当前的存算一体加速器普遍采用多个忆阻器交叉阵列组成计算点阵,并将训练后的卷积神经网络的参数(权重)一次性映射在阵列上。例如ISAAC[2]采用了12k个crossbar组成一个从chip到tile到crossbar的层次化计算架构,每个crossbar包含128行×128列个忆阻器单元,可以映射48Mb模型参数,足以映射如ResNet-18网络的所有参数,而不需要考虑crossbar再次映射的情况(后文称再次映射为权重更新)。
而实际上受限于工艺条件,crossbar很难做到128行×128列的规模[4,5,6],并且从面积和利用率等实际情况考虑:①采用上万个crossbar占用了很大的面积,增加了功耗;②在映射部分参数规模不大的网络时,硬件资源利用率不高;③存在神经网络参数规模可达到亿级,对于这些极大规模的网络,该架构仍然无法一次性映射全部权重。考虑这些情况,本文抽象出来存算一体架构的一些共有特征,提出一个阵列规模小的权重可变的存算一体架构,通过多次映射权重来完成整个网络的计算,并且通过本文设计的软件栈完成具有多次权重更新的编译需求。
本文面向的架构如图1所示,其中左侧是该架构的tile级结构,包含一个全局共享存储器和4个core。通过高带宽的H-tree互联结构,core可以访问tile上的全局共享内存,每个core包含9个逻辑crossbar,每个crossbar由64×64个2bits忆阻器单元构成,即本文所基于的架构可同时映射144Kb权重,最小矩阵向量乘执行单元为64×64×8bits。由于架构需要多次更新crossbar上的权重,考虑到crossbar更新权重的代价较高,本文将在后文设计相关的调度策略缓解这个问题。
存算一体加速器具备软件可编程性,如图1右侧所示,本文架构的Core单元可以执行从/向tile的全局存储器上读取/写入数据的过程,并可以独立译码和执行计算过程。
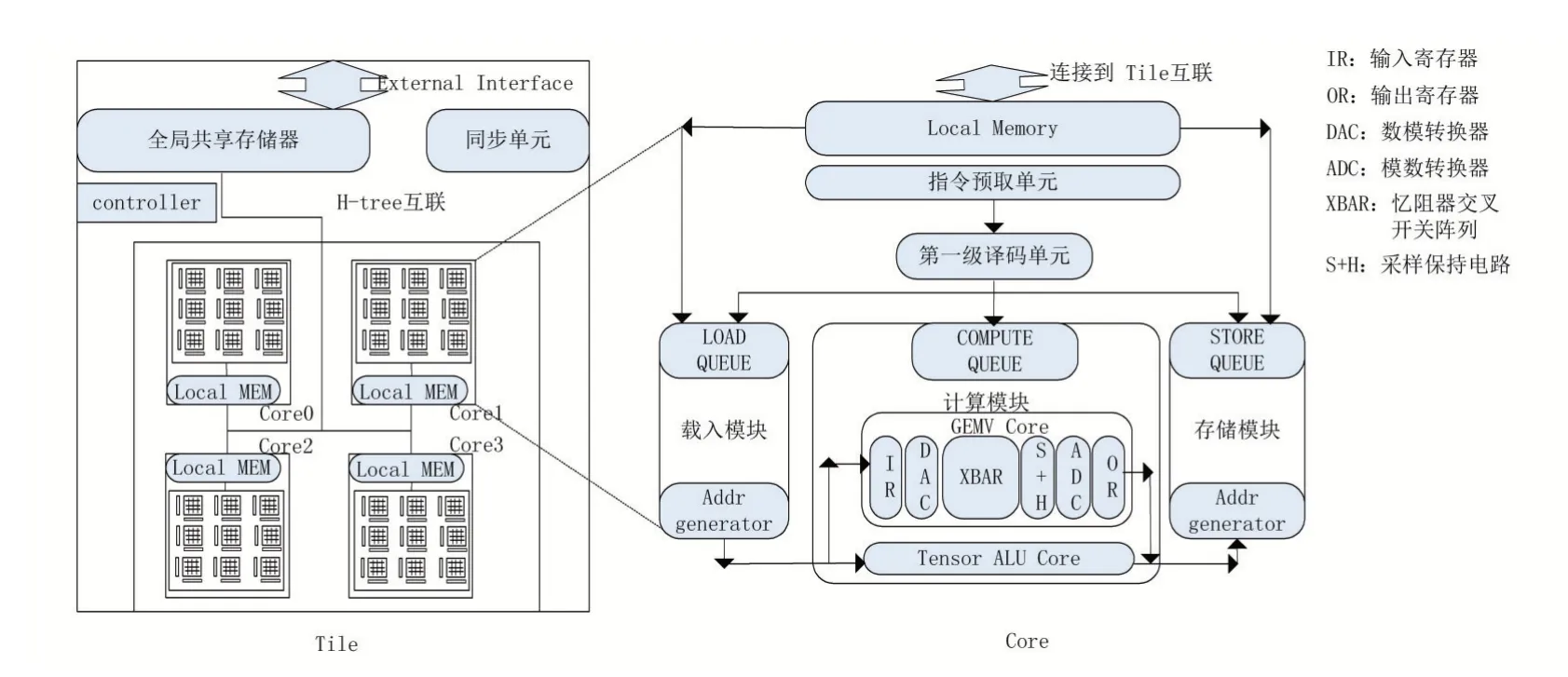
图1 存算一体层次化架构
2 指令与代码生成
2.1 流程介绍
当前存算一体加速器上部署神经网络模型时大多采用手工映射的方法,为了减少开发时间,一些工作[7][8]设计了编译软件栈,但是缺乏算子优化且没有考虑权重更新的情况。Halide[9]是一个解耦计算与调度的代码生成工具,本文的指令生成工具在算子优化方面结合Halide的思想,提供了优化算子的能力,并且考虑了crossbar的权重更新。
本文指令生成工具的代码生成流程如图2所示。

图2 编译流程图示
首先利用Halide描述运算,再将运算描述转换成Halide算子中间表示,并将循环嵌套表示的算子进行任务划分、分割成与硬件原语绑定的执行单元,以方便后续代码生成。最后将算子级中间转换成LLVM IR,将LLVM IR翻译成可执行文件后,运行可执行文件,可以生成存算一体指令,最后借助驱动工具将指令加载到Core单元并执行。
2.2 算子任务划分与并行
考虑到加速器执行的最小运算粒度是矩阵向量乘操作,因此需要将以循环嵌套描述的卷积等运算拆分成硬件可执行的矩阵向量乘操作单元。另外为了让算子在多个Core上并行执行,采取将以循环嵌套描述的算子的一些计算轴与计算核进行绑定的方法。考虑减少计算依赖等因此,本文将卷积的输出通道与Core进行绑定。
如图3所示,本文首先在卷积算子的7层循环中将输出通道C表示的循环轴分割成两个子循环轴C_o与C_i,分割的因子为64,以便匹配硬件最小执行单元,进一步以因子4分割C_o通道,以绑定4个计算核心。最终形成从外到内为C_o_outer、C_o_inner、C_i的循环顺序,并在算子IR上的C_o_inner轴上利用语法标记为并行,以便在代码生成时将该变量与计算核心绑定。
3 算子优化与调度空间探索
考虑到存算一体的输入数据访问以及crossbar权重更新代价,本文主要研究了两个算子优化的技术:①连续内存访问优化:在片上输入缓冲区资源足够的情况下,读取输入数据时,应尽量选择读取连续内存排列的数据,以提高DMA访问的效率;②权重更新次数优化:在中间结果缓冲区足够的情况下,尽量复用当前权重,减少权重更新次数。

图3 卷积运算在多核之间的任务划分
3.1 优化连续内存访问
考虑图4所示的两种读取输入的方式,当读取的输入张量是张量A表示的张量窗口时,由于第一行数据和后行的数据在内存的存放存在间隔,因此需要使用至少三次内存访问操作(或者启动三次DMA操作)才能将完整输入读入到数据缓冲区。
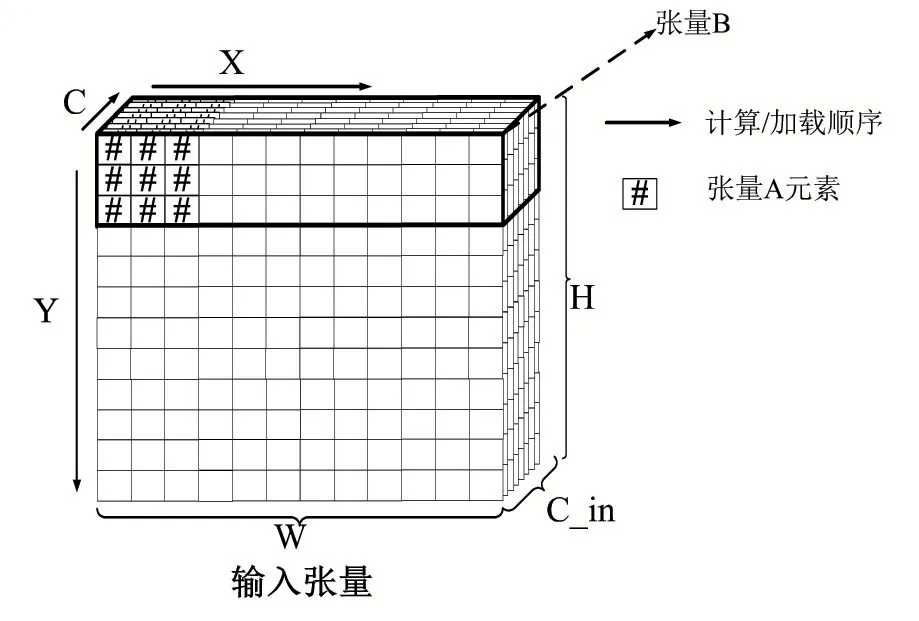
图4 从内存中读取输入张量数据的两种访问形式
当输入缓冲区还存在余量时,考虑张量B表示的读取方式,由于第一行数据和第二行数据在内存中是连续存放的,因此只需要一次内存访问指令。显然第二种读取方式减少读取次数,提高了访问效率。本文通过在编译时检测读取的目标张量数据是否连续存放,如公式1所示。

并利用存储感知输入缓冲区的余量决定读取张量的大小,最后决定每次读取张量块的大小。
3.2 优化权重更新次数与调度空间探索
前文叙述了本文架构在映射神经网络模型时权重无法一次性映射到crossbar上,因此在计算中需要多次更新权重。因此在编译阶段本文需要解决两个问题,一是在算子循环嵌套的何处进行权重更新,二是如何调度算子使得权重更新次数减少。对于第一个问题,结合上文中的算子任务划分策略,对于输入layout为[N,K,H,W](batch_size、输入通道数、长、宽),卷积核layout为[C,K,m,m](输出通道数、输入通道数、卷积核大小)的卷积运算,可以得到,在卷积运算循环嵌套的输出通道C_o与输入通道K_o所表示的循环变量改变时,权重需要进行更新。因此本文在C_o和K_o轴设置了一个语法标记,如图5所示,这个标记通过调用一个接口函数将Invalid标记传送到代码生成模块,代码生成模块根据Invalid标记来判断是否将接下来的LoadWeight指令插入到指令流中。对于第二个问题,结合图5所示描述,通过Halide提供的循环重排方法,尽量将h_o、w_o轴排到c_o_outer与k_outer之后,减少了权重更新的次数。
本文在算子优化上借鉴了Halide解耦计算描述与计算调度的思想。首先对算子如卷积运算设置一个默认的调度模板,然后在此模板的基础上利用reorder、split、tiling等方法对默认的循环嵌套进行循环重排、分块等操作,以探索在指定硬件资源上的最佳计算方案。
为了探索最佳调度方案,本文首先基于调度模板和输入负载的大小生成调度空间,在调度空间中通过遍历并评估各个点以找到最佳调度方案,并将最佳调度生成到记录文件,在遇到相同计算负载时可以直接从记录文件中提取相应的调度方案,减少不必要的调度空间探索时间。
如图5所示,本文首先将卷积的循环轴如C轴、K轴进行第一步拆分,如公式(2)、(3)所示,其中C_i与K_i用以匹配硬件最小执行单元,再进一步对C_o、K_o以及H,W,N轴采取类似的分割策略,可以生成一个由C_o_outer,C_o_inner,H_o,H_i,W_o,W_i,N_o,N_i组成的一个与变量顺序和幅度有关的调度空间。

图5 卷积循环分块与调度(分块因子由调度空间中所选的调度方案决定)

由于不同的排列组合下的申请buffer空间、中间结果所占的空间、内存访问次数以及权重更新次数都有所不同,因此可以寻优一个最佳调度。
4 实验结果与分析
4.1 实验方法
为了验证本文指令生成工具编译流程的正确性和调度策略的有效性,本文基于PUMA[10]仿真器进行修改以支持本文所提出的存算一体指令,并对生成的指令块进行仿真验证,结合生成的各级中间表示进行分析以验证编译流程的正确性。最后通过与默认调度方案对比,验证本文优化方案的有效性。
4.2 实验结果
以batch_size=1,height=28,width=28,in_filter=128,out_filter=256,wkernel=3,padding=[1,1],stride=[1,1]的卷积运算为例,本文指令生成工具生成的含有硬件信息的算子级中间表示如图6所示,本文在基于PUMA[10]的仿真器上对生成的指令流进行了仿真,验证了生成结果的正确性。图7显示在本文的减少权重更新策略调度下,部分神经网络的权重更新次数相比与默认模板减少了90%以上。

图6 生成的Conv2d-ReLU算子描述

图7 算子优化前后的映射权重的次数对比
4.3 结果分析
图6中间表示表明了本文指令生成工具生成代码的正确性,另外之所以本文的调度方案相比与没有调度的方案有很大提升,是因为默认计算方案趋向于产生完成计算结果,因此产生大量权重更新,在调度之后,趋向于在中间结果缓冲区有余量的情况下优先产生中间结果,因此产生大量权重复用的情景,从而减少了权重更新次数。
5 结语
针对忆阻器存算一体加速器的代码生成与优化问题,本文设计了一套自动指令生成的流程,在算子级中间表示上利用Halide解耦计算与调度,在生成的调度空间上探索映射卷积运算的最佳调度方案,最后相比于默认计算规则,本文减少了85%~96%的权重更新次数,大大减少了权重更新的开销。
