基于光谱与纹理特征融合的绿萝叶绿素含量检测
2021-05-24闫明壮王浩云吴媛媛曹雪莲徐焕良
闫明壮,王浩云,吴媛媛,曹雪莲,徐焕良
(南京农业大学信息科学技术学院,江苏 南京 210095)
叶绿素是植物进行光合作用不可或缺的光合色素和物质基础[1],同时叶绿素含量也是评价室内植物对苯污染的抗性能力的重要依据。研究证明,苯气体浓度越大,胁迫时间越长,植物叶片叶绿素含量下降越快[2]。近年来,以图像分析技术和高光谱成像技术为主的无损检测技术,被广泛应用到作物叶片叶绿素含量及分布的研究中。刘燕德等[3]使用遗传算法和连续投影算法对原始光谱数据进行特征波段的提取,采用偏最小二乘回归模型对脐橙叶片叶绿素含量及可视化分布进行研究。朱军伟等[4]采用纹理分析的空间灰度共生矩阵法寻找纹理各统计量与玉米叶片叶绿素含量的关系,通过建立的多元回归模型分析玉米不同生长期的叶绿素实际含量与模型预测值之间的相关性。
图像分析技术和高光谱成像技术在一定程度上提高了叶绿素无损检测的准确性,但单一使用光谱特征无法描述叶绿素整体的空间分布特征,而单一使用图像纹理特征无法准确反映植物内部叶绿素含量[5-6]。综合利用高光谱图像的光谱信息和图像信息,可以提高结果可靠性及准确性[7-8]。在高光谱成像技术应用中,开始出现将多特征融合用于作物品质的检测。于慧春等[9]将枸杞高光谱数据中的特征光谱与纹理数据组合后,建立枸杞内部多糖和总糖的预测模型,该模型在光谱特征方面,使用主成分分析方法对光谱特征进行提取,提取后的光谱特征中噪声信息过多,影响了基于融合特征模型的预测效果。
目前在叶绿素高光谱检测领域中,还未见使用多特征融合的方法进行模型构造的报道。本文以长藤绿萝为研究对象,基于融合特征建立绿萝叶片叶绿素预测模型,为快速无损检测植物叶绿素含量提供思路和方法。
1 材料与方法
1.1 试验材料
试验样本为绿叶长藤绿萝。选取生长状态一致的绿萝20盆,在相同生长环境下,每盆植株的上、中、下部位取16片叶片样本,共计320个样本,样本采摘后立刻进行叶绿素含量测定和高光谱信息采集。
1.2 试验方法
1.2.1 叶片SPAD值的测定选用便携式叶绿素仪(SPAD-502型)测量叶片叶绿素SPAD值。在叶片主叶脉左侧中部支脉与支脉间区域,标注2 cm×2 cm的矩形待测区域,测定该区域的 SPAD 值,重复3次。
1.2.2 叶片高光谱信息的采集用上海五铃光电科技有限公司的推扫型高光谱成像系统采集叶片高光谱数据,采用漫反射架构,相机型号为ICL-B1620 CCD,光源为3900ER可调谐光源(美国Illumination Technologies公司)。软件由Spectral-image取像软件和HSI Analyzer分析软件组成。消除前后噪声波段后,高光谱有效波长范围设置为400~900 nm,共468个波段。
高光谱数据采集前,需要进行仪器的黑白矫正和高光谱图像的黑白标定[10-11]。在与样品采集相同的系统条件下,扫描标准白色校正板得到全白的标定图像W,关闭相机快门进行图像采集得到全黑的标定图像B,完成高光谱图像的标定,使采集得到的绝对图像I变成相对图像R,则标定后的高光谱图像的计算公式[12]:
Rλ=(Iλ-Bλ)/(Wλ-Bλ)
(1)
式中:Rλ、Iλ、Bλ和Wλ分别表示在波长λ下相对图像、绝对图像、黑板标定图像和白板标定图像。
1.3 模型性能指标与评价依据
在光谱分析过程中,选择合适的方法来建立性能稳定、结果可靠的数学模型是实现高光谱图像分析的前提和关键。因此,需要有定量的评价指标体系对不同模型的结果进行评价和比较。在本文中,所采用的定量模型评价指标有决定系数(R2)、均方根误差(root mean square error,RMSE)、相对分析误差(residual predictive deviation,RPD)。
2 绿萝叶片特征选择与提取
2.1 叶片高光谱特征的提取
对通过黑白校正后的光谱图像,选取叶片叶绿素SPAD值的实测区域,使用HSI Analyzer分析软件,从该实测区域内截取30×30像素的矩形感兴趣区域(region of interest,ROI)作为研究对象。计算所有样本ROI的全部光谱数据的各个像素点中光谱响应的平均值,估算该样本的相对反射率。320个样品共获得320条光谱平均反射值。
2.1.1 高光谱数据预处理仪器的响应、随机噪声、散光等因素会导致光谱曲线重复或产生基线漂移,为减少该类因素对试验结果的影响,需要对光谱信息进行预处理[13]。目前常用的预处理方法主要包括平滑、求导、归一化、多元散射校正[14]等。采用Savitzky-Golay卷积平滑(S-G平滑)、多元散射校正(multiplicative scatter correction,MSC)、一阶导数3种方法对ROI的高光谱数据进行预处理,采用留一交叉验证法建立模型,以交叉预测集相关系数(RCV)和交叉预测集均方根误差(RMSECV)为评判指标[15],挑选出最佳预处理方法。
2.1.2 高光谱特征波段的提取高光谱数据存在大量的噪声和冗余信息,直接对高光谱原始图像进行处理分析,不仅数据量大、有效信息少,而且处理时间长、准确率低。为提高叶绿素预测的准确性,减少处理的复杂性,通过算法对高光谱原始图像进行特征波段的选择,从所有波段范围内挑选出对绿萝叶片SPAD值影响最大的几个波段。
目前常用的高光谱特征波段选择的方法主要包括:无信息变量消除法、竞争性自适应重加权法、随机蛙跳算法、连续投影算法等。
无信息变量消除法(uninformative variables elimination,UVE)是基于分析偏最小二乘法回归(partial least squares regression,PLSR)系数的算法,能有效去除无关波长变量。对PLSR模型中添加1组与原始变量数量相同的白噪声变量,然后基于PLSR模型交叉验证并剔除无关变量,得到回归系数矩阵,利用回归系数向量的平均值与其对应的标准差相除,进而确定筛选变量阈值,大于阈值的筛选变量即为优选特征变量[16]。
连续投影算法(successive projections algorithm,SPA)能从光谱信息中充分寻找含有最低限度冗余信息的变量组,有效消除变量之间的共线性影响,使变量之间的共线性达到最小,降低模型的复杂度[17]。
2.2 叶片图像特征的提取
将感兴趣区域的RGB图像通过灰度变换和滤波等手段进行预处理,去除叶片表面的亮光和阴影噪声。
本文采用灰度共生矩阵(gray-level co-occurrence matrix,GLCM)进行纹理特征提取,该纹理提取方法描述了具有空间位置关系的2个像素灰度的联合分布。灰度共生矩阵就是从图像f(x,y)灰度为i的像素出发,统计其距离为δ、灰度为j的像素(x+Δx,y+Δy)同时出现的概率P(i,j,δ,θ)。
(2)
式中:i,j=0,1,…,L-1,L为图像的灰度级数;Nx和Ny分别为图像的行数和列数。
采用GLCM对感兴趣区域图像共提取4个纹理特征的描述值,分别为能量、对比度、相关度和熵。这4个特征值具有描述图像不同特点的功能,能量描述图像灰度分布的均匀程度和纹理的粗细程度;对比度反映纹理性质之间的差异性,描述纹理局部的变化量;相关度指图像的灰度矩阵元素在行或列方向上的相似度;熵表明纹理的复杂情况。由于叶片表面的纹理较细,设置像素间距r为1,扫描角度分别设置为0°水平扫描、45°扫描、90°扫描和135°扫描。如图1所示,以像素点S为例,像素间距r=1,纹理扫描角度依次为0°、45°、90°和135°,对不同角度方向进行各纹理属性值的提取,为了降低计算量,对不同方向的4种GLCM属性值求取平均值[18]。
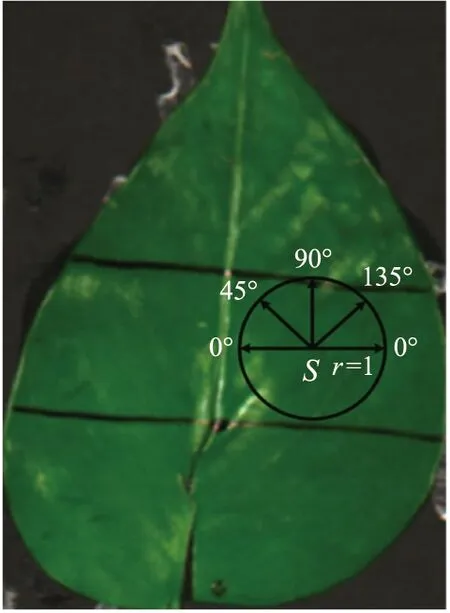
图1 绿萝叶片扫描角度图Fig.1 Scanned picture of Epipremnum aureum leaf
图2为该4个特征值分别与叶绿素SPAD值的皮尔森相关性系数r。从图中可以看出,各特征值与SPAD值的相关性系数绝对值均大于0.80,呈高度相关,其中特征值熵的相关性系数绝对值为0.90,呈强相关性。
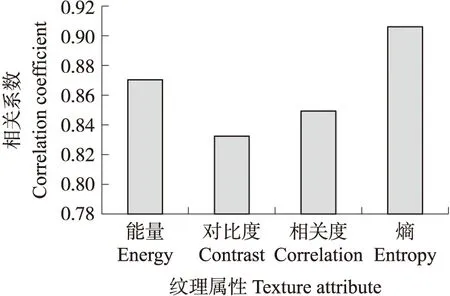
图2 绿萝叶片纹理属性与叶绿素 SPAD值的相关系数Fig.2 Correlation coefficient between E.aureum leaf texture attributes and chlorophyll SPAD value
2.3 光谱特征与图像特征的融合
将每个样本经过SPA提取的10个光谱特征、相应的4个纹理特征串联融合到1个数据集中,得到320*14的融合特征数据集。高光谱特征通过光谱的反射值映射绿萝叶片内部叶绿素的含量特征,图像的纹理特征从叶片外部描述叶绿素的空间分布信息,将2种特征融合后,得到包含叶片叶绿素含量与空间分布的综合信息,与于慧春等[9]报道的融合特征相比,该高光谱特征是样本的原始光谱经过S-G平滑预处理和SPA特征波段的选取得到的,该特征不仅具备与叶绿素含量的高相关性,而且具备轻量化的特点,再加上纹理特征的补充,使该融合特征更加高效和丰富。
2.4 模型的建立
从本文提取的光谱特征数据和图像纹理数据以及2种特征融合后的数据可以发现,各特征变量与叶绿素含量之间具有显著的非线性关系,因此传统的线性回归方法得不到理想的回归模型。为得到准确的预测效果,选用支持向量回归(support vector machine regression,SVR)和人工神经网络(back propagation artificial neural network,BPANN)建立绿萝叶片SPAD值的预测模型。
由于模型的初始参数是随机产生的,导致模型每次预测结果具有不确定性,为了更好评价模型准确性和稳定性,本试验采用30次随机仿真,模型评价的最终结果为30次仿真试验的平均值。模型的建立在Matlab R2014a软件中完成。
3 结果与分析
3.1 绿萝叶片SPAD值的实测
共采集320个绿萝叶片样本的SPAD参考值。本文采用SPXY法进行数据集划分,80%(256个)的样本作为训练集,20%(64个)的样本作为预测集。训练集用来训练模型,预测集用于最终模型性能的评价。训练集中叶绿素SPAD值最小为2.5,最大值为57.4,平均值为36.5;预测集中叶绿素SPAD值最小为3.1,最大值为57.8,平均值为37.8。
3.2 高光谱数据处理
3.2.1 高光谱数据预处理为了对每种预处理方法效果进行定量分析,利用偏最小二乘回归算法(PLSR)对预处理的结果进行建模分析,训练集采用留一交叉验证的方式对不同数量主成分建立的模型进行分析,随着主成分个数的增加,均方根误差呈现先增大再减小的趋势,这是因为刚开始随着主成分的增加,所包含的有效信息也随之增加,但达到某一数量后,增加主成分的个数反而增大了无效信息和冗余信息,因此均方根误差也随之增大。本文中以RMSECV达到最小时的6个主成分为最佳主成分个数。从表1可见:S-G平滑预处理对400~900 nm波段的高光谱信息处理效果最好,PLSR模型的RCV为0.89,RMSECV为0.42。

表1 预处理方法的偏最小二乘回归算法(PLSR)模型效果对比Table 1 Comparison of partial least squares regression(PLSR)model effects of pretreatment methods
图3-A为在400~900 nm波段的高光谱原始图像,数据噪声较大;图3-B为经过S-G平滑预处理后的高光谱图像。可以看出,该方法有效去除数据存在的噪声,但并未压缩删除原始数据,保证数据的完整性,为特征波段的提取提供完整的原始数据支持。
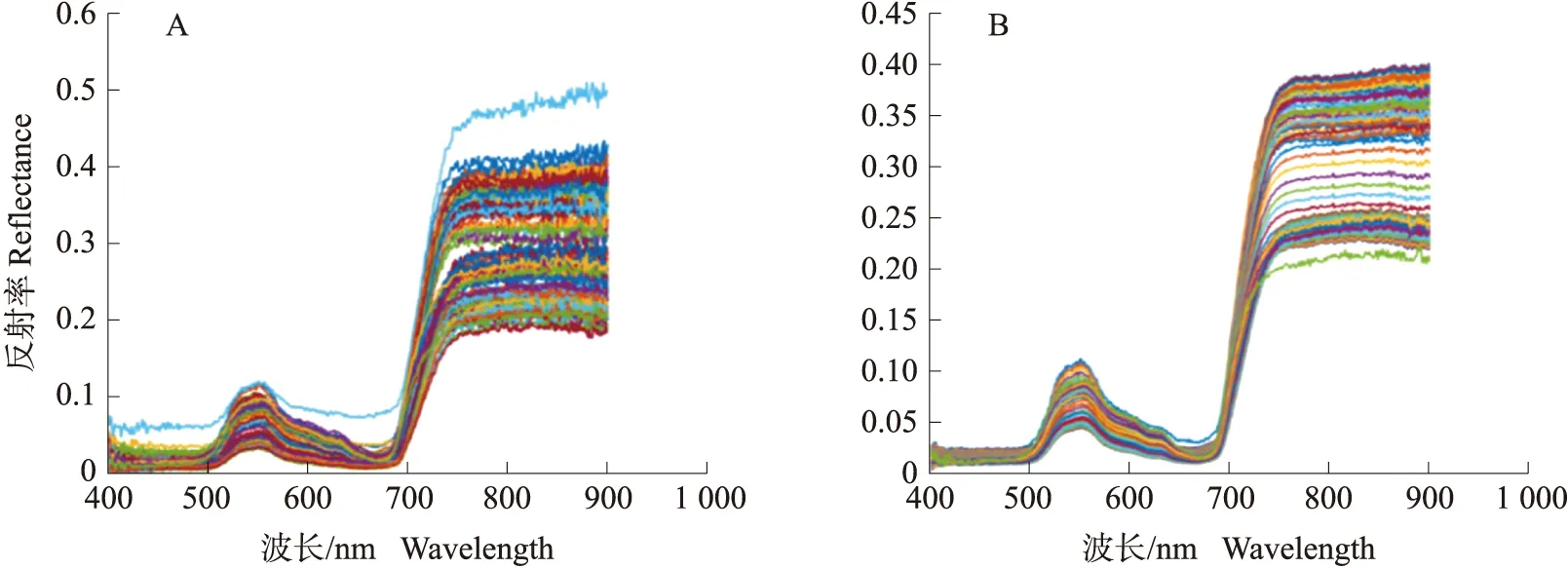
图3 原始光谱(A)和S-G平滑预处理(B)的光谱图像Fig.3 Spectral image of original spectrum(A)and S-G smoothing preprocessing(B)
3.2.2 特征波段选择从图4-A可见:UVE在400~900 nm波段所选出的30个特征波段分布集中,包含的信息具有局部性与重复性。图4-B是经过SPA算法筛选出的10个特征波段,分别是497、501、554、562、669、673、697、715、779和822 nm。直观看SPA所提取的10个特征波段均分布在与叶绿素相关性较强的区域,如500~600 nm绿色反射峰、650~680 nm红色波段吸收谷、680~760 nm红边区域。红边区域蕴含丰富的植被生长信息,与植物生理生化参数关系密切[19]。因此相比无信息变量消除法,连续投影算法不仅筛选能力强,而且具有较强的可解释性。
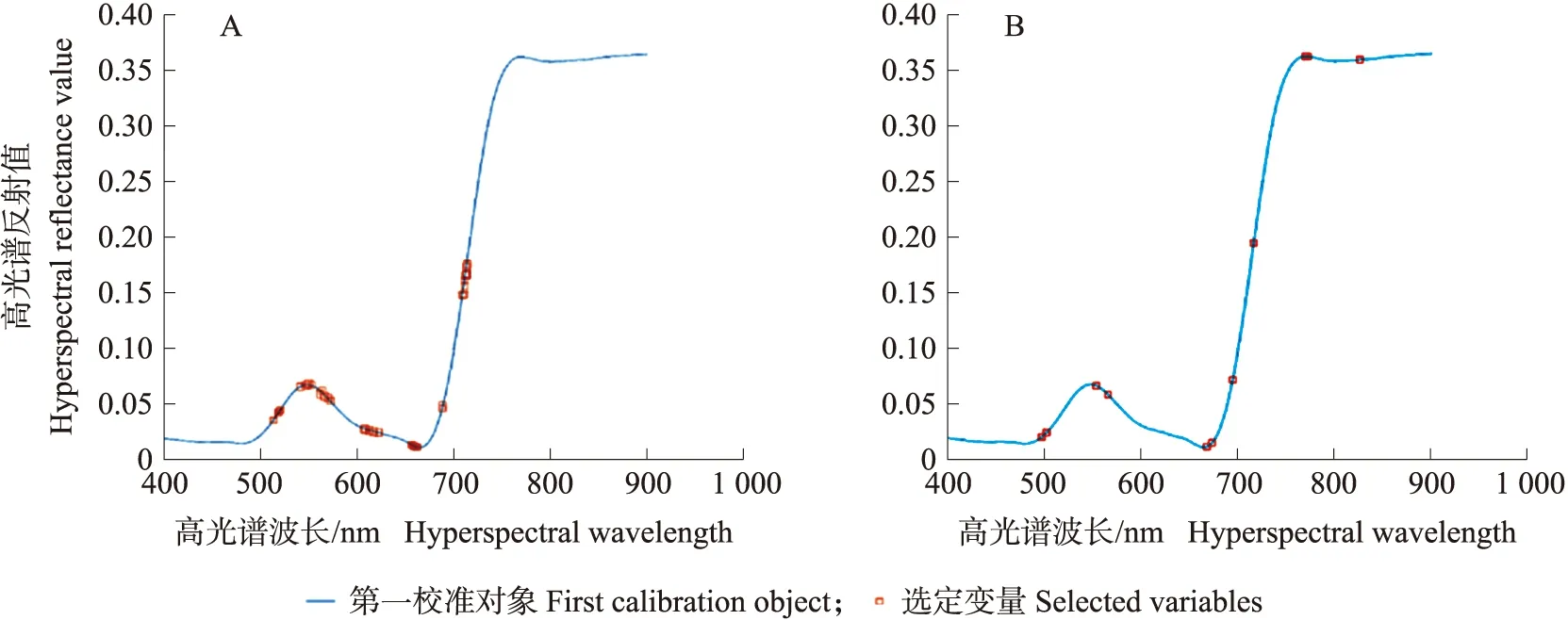
图4 UVE算法所选出的特征波段(A)和SPA算法所选出的特征波段(B)Fig.4 Characteristic bands selected by UVE algorithm(A)and selected by SPA algorithm(B)
3.3 基于高光谱特征的回归模型的建立
基于高光谱的全波段数据、SPA特征数据和UVE特征数据分别建立绿萝叶绿素的误差反向传输BPANN和SVR预测模型。
选用320个样本的SPA特征数据和UVE特征数据建立BPANN模型时,输入层单元数目分别设置为10和30,每个单元选择由SPA算法和UVE算法得出的特征波段,输出层为1个单元,设置为叶片的叶绿素SPAD值,经数据集训练后确定隐含层节点数目分别为10和19。
将S-G平滑预处理后的400~900 nm波段的高光谱信息,采用全波段光谱反射值和通过SPA、UVE分别筛选后的特征波段作为输入数据,选用高斯径向基(radial basis function,RBF)作为核函数建立支持向量机回归模型。利用RBF核函数将输入的数据映射到高维空间,选择出最优的分类面,实现非线性映射,得到关于叶绿素SPAD值的预测模型(表2),对每个模型分别运行30次,取30次的平均值为最终结果。
由表2可知:基于SPA特征波段建立的SVR模型预测集的R2最高,基于UVE特征波段建立的SVR和BPANN模型预测集的R2均低于全波段模型的预测集R2,证明模型在稳定性不变的基础上,利用SPA算法降低数据冗余和模型处理的复杂度,去除大量无用信息对关联特征的干扰性,小幅度提高预测模型的准确性,因此可以确定针对绿萝叶绿素SPAD值的高光谱特征波段选择中,SPA算法筛选效果较好。
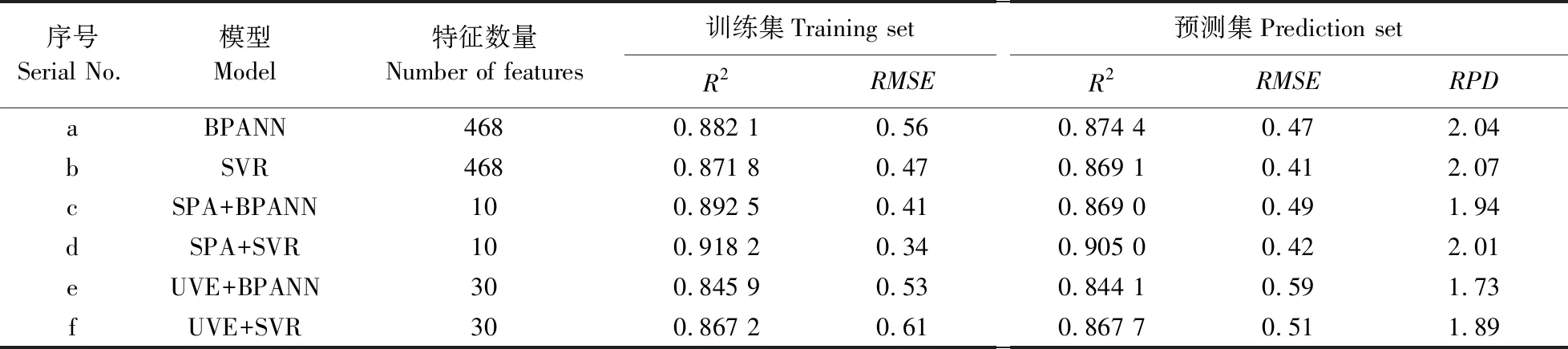
表2 基于全波段和不同特征的各种模型训练结果Table 2 Training results of each model based on full band and characteristic band
相比全波段高光谱数据和UVE算法的模型预测效果,基于SPA算法的SVR模型预测准确度虽然有一定提升,但提升幅度不大,模型的稳定性也呈现下降趋势。初步分析这是由于通过SPA算法在筛选特征波段时去除了大量的原始光谱信息,少量的特征波段虽能较好表达主要的相关信息,但不可避免地存在关键信息的遗漏,数据特征不足,导致训练得到的模型复杂度较低,影响了模型的鲁棒性和泛化能力。因此基于SPA算法的基础上,需要丰富特征参数的多样性,进一步提高模型的综合能力。
3.4 基于图像纹理特征的回归模型
对320幅绿萝图像进行处理,每幅图像提取4个特征参数,以同样的方法基于绿萝叶片纹理特征分别建立BPANN与SVR回归模型。从表3可见:SVR回归模型预测集的R2为0.803 1,RPD值为1.91;BPANN模型预测集的R2为0.732 8,RPD值为1.72。因此基于图像纹理特征所建立的预测模型准确性接近以特征光谱为参数建立的预测模型,模型也较为稳定。说明绿萝叶片表面的纹理特征能够较好描述叶片的叶绿素含量,因此,将其与光谱特征有效融合后,可增加对叶片叶绿素含量的描述性,并进一步提高回归模型的预测能力。

表3 基于图像纹理特征的模型结果Table 3 Model results based on image texture features
3.5 基于光谱特征与图像纹理特征融合的回归模型
将SPA筛选的光谱特征与纹理特征融合后作为模型的输入数据,建立关于绿萝叶绿素SPAD值的预测模型,模型反复运行后,得到最终结果。从表4可见:SVR回归模型预测集的R2为0.957 1,RPD值为2.21;BPANN预测集的R2为0.923 3,RPD值为1.97。2个模型在保持稳定性的基础上,预测集的R2都得到了明显的提升,尤其是基于融合特征建立的SVR回归模型相比单一的高光谱特征模型,预测集R2提高了0.052 1;相比单一的纹理特征模型,预测集R2提高了0.154 0。

表4 基于融合特征的模型结果Table 4 Model results based on fusion features
从图5可见:基于融合特征建立的绿萝叶绿素预测模型的R2与RPD值均高于其他单一特征模型,SVR模型的各项参数均优于BPANN模型。
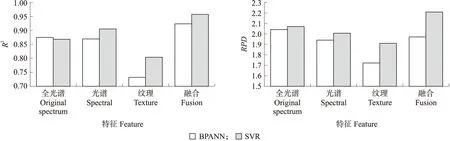
图5 各特征模型的预测集决定系数(R2,A)和剩余预测偏差(RPD,B)Fig.5 The coefficients of the prediction set(R2,A)and the remaining prediction deviation(RPD,B)of each feature model
图6-A为30次随机仿真试验中融合特征BPANN模型某一次的预测效果,图6-B为30次随机仿真试验中融合特征SVR模型某一次的预测效果,这2种模型在一定程度上提高了准确性,但仍然存在个别偏离预测值的数据点。可以看出BPANN模型存在数个偏离预测程度较大的数据点,影响了模型的综合能力。BP算法在拟合非线性函数的收敛过程中,所得到的收敛结果可能是局部最小点,这是源于BP算法的搜索是串行的,而非并行性搜索,因此在少量特征波段所建立的BPANN拟合回归模型中,最终所得到的拟合结果具有一定的局限性和片面性,导致基于BPANN所建立的叶绿素SPAD值预测模型稳定性较差,产生的偏离数据值较多,且偏离程度较大,模型的整体效果不如SVR模型。
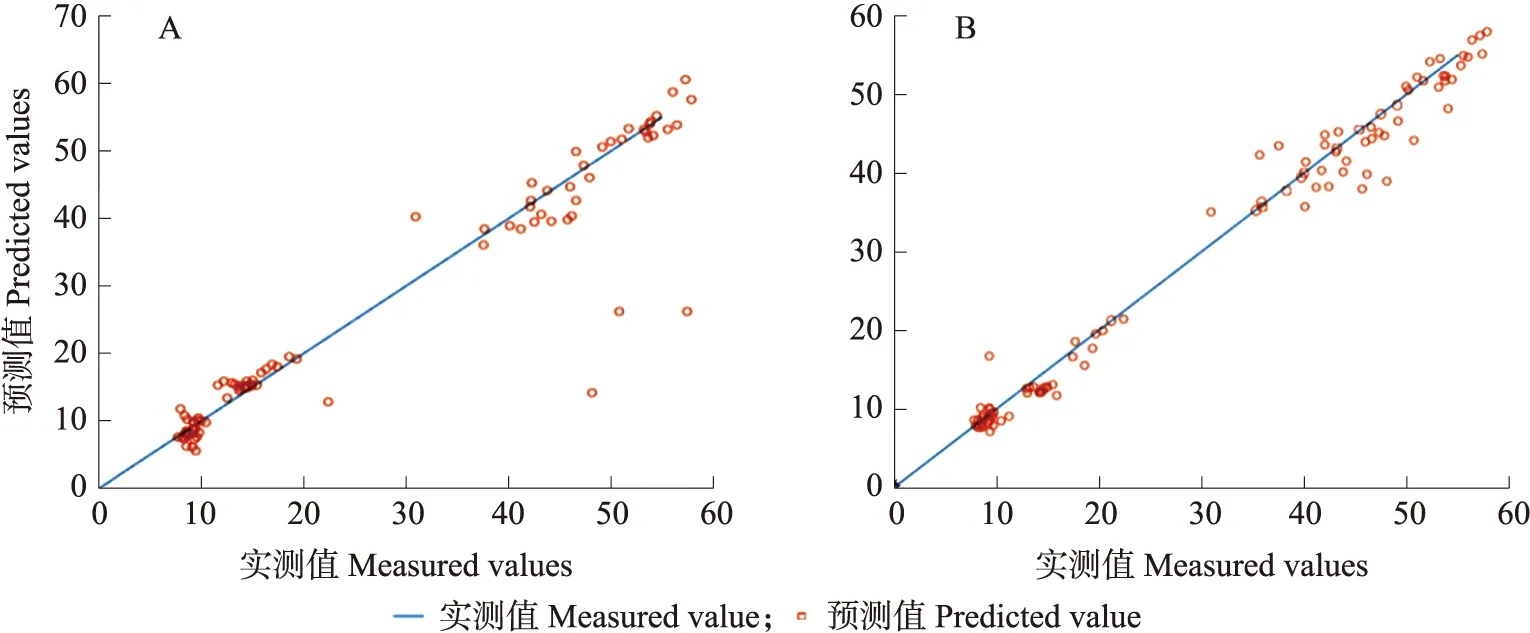
图6 基于融合特征建立的模型BPANN(A)和SVR(B)预测的绿萝叶绿素SPAD值Fig.6 Chlorophyll SPAD value of E.aureum predicted by the model BPANN(A)and SVR(B) based on the fusion features
4 结论
本文以长藤绿萝为研究对象,分别以光谱特征、纹理特征及融合特征进行建模分析,研究表明:
(1)基于400~900 nm范围内的光谱信息所建立的模型中,以经SPA算法筛选出的特征光谱所建立的SVR模型效果最好,其模型平均预测误差(RMSE)为0.38,平均剩余预测偏差(RPD)为2.21,为后续建立特征融合的叶绿素SPAD预测模型提供高光谱特征参数参考;基于SPA算法的SVR模型预测集R2提升幅度较小,为提高特征丰富度提出了需求。
(2)基于绿萝叶片RGB图像提取的灰度纹理特征所建立的BPANN和SVR模型的效果均接近于基于光谱特征建立的模型效果,证明了纹理特征的有效性。
(3)基于光谱特征与纹理特征串联融合建立的对绿萝叶绿素SPAD值的预测模型中,基于融合特征的SVR模型的预测效果最好,预测集决定系数R2为0.957 1;因此,利用高光谱成像技术,基于光谱信息与纹理信息的融合特征建立的预测模型,对绿萝叶绿素含量无损检测的性能优于各单一特征预测模型,为今后实现植物叶绿素快速无损检测提供思路和方法。
本文对绿萝叶片的高光谱特征进行了提取,融合图像纹理特征后,模型的预测效果明显提升。但该研究方法还存在一定的不足,一方面是图像的纹理特征还具有进一步优化的空间;另一方面,需要选择合适的融合方法将多个特征进行更加有效的融合,进一步提高模型预测的准确度。
