航行通告中自然语言理解算法研究
2021-05-23邓益鹏罗银辉
邓益鹏 罗银辉


摘要:航行通告机器识别,对于规范化的代码处理相对简单,但对于自然语言处理起来相对困难。针对航行通告中类别多,数据分布不平衡,中英文混合等问题,提出基于word2vec文本向量化技术的文本分类方法,针对小样本数据采用smote算法对数据重采样,经过重采样后的数据选择使用XGBoost继承算法模型完成分类。由中航材导航技术公司提供的航行通告标签原始数据,经实验表明,能够有效规避样本数据分布极不平衡,分类数量过多的问题,同时模型的主要评价指标都有提高,包括模型的准确率、召回率及F1值。
关键词:航行通告;数据分布不平衡;word2vec;smote;XGBoost
中图分类号: TP31 文献标识码:A
文章编号:1009-3044(2021)11-0206-04
在运用传统机器学习文本分类的领域,文本分类的模型算法整体上已经成熟,在文本分类技术从理论研究到实际应用上面临着多方面的挑战,与实验室文档比较,互联网传播的电子文本信息则表现出分类多样,关系复杂,数据分布极为不平衡等特点,由中航材导航技术公司提供的通告标签原始数据同样标签数据分布极为不均衡,部分原始数据如表1所示。
传统的文档表示方法以词袋法BOW为主[1],词袋法将文档看作是单个词的集合,每个词被认为是相互独立的。BOW将一篇文档都表示成和训练词汇文档一样大小的向量,向量的每个位置代表该位置所代表的词出现了几次,出现新的词汇文档,则向量维度增加。这就意味着几个重大缺陷:1)维度过高;2)短文本的词汇数通常是几个到几百,词向量的维度却高达数十万,利用率不到千分之一;3)词袋法不能很好地表示短文本的语义,忽视掉其中的顺序、语义等关键的信息。
深度学习发展越来越好[2],2013年Mikolov提出了word2vec模型[3]来表示词向量。word2vec模型计算文档中词的上下文信息并将其转化为一个低维向量,越相似的句子则在向量空间种越接近。word2vec模型在自然语言处理领域应用相当成功。包括中文分词[4]、情感分类[5]等。
smote算法[6]是改善数据不平衡分布的一种重采样算法。核心是通过对少数类样本进行过采样,不是直接简单复制少数类样本,是利用欧氏距离对少数类样本进行分析合成新的样本。经实验,smote算法对数据的预处理更有效,能够有效预防模型出现过拟合。
基于树模型的XGBoost训练模型是目前在传统机器学习当中优秀的集成学习模型,主要思想是训练多个准确率较低的弱学习器,然后通过某种机制集成为一个强学习器[7]。调整参数方便,训练时长较短,结果较为优秀,代价函数加入了正则项防止模型出现过拟合。
1 方法
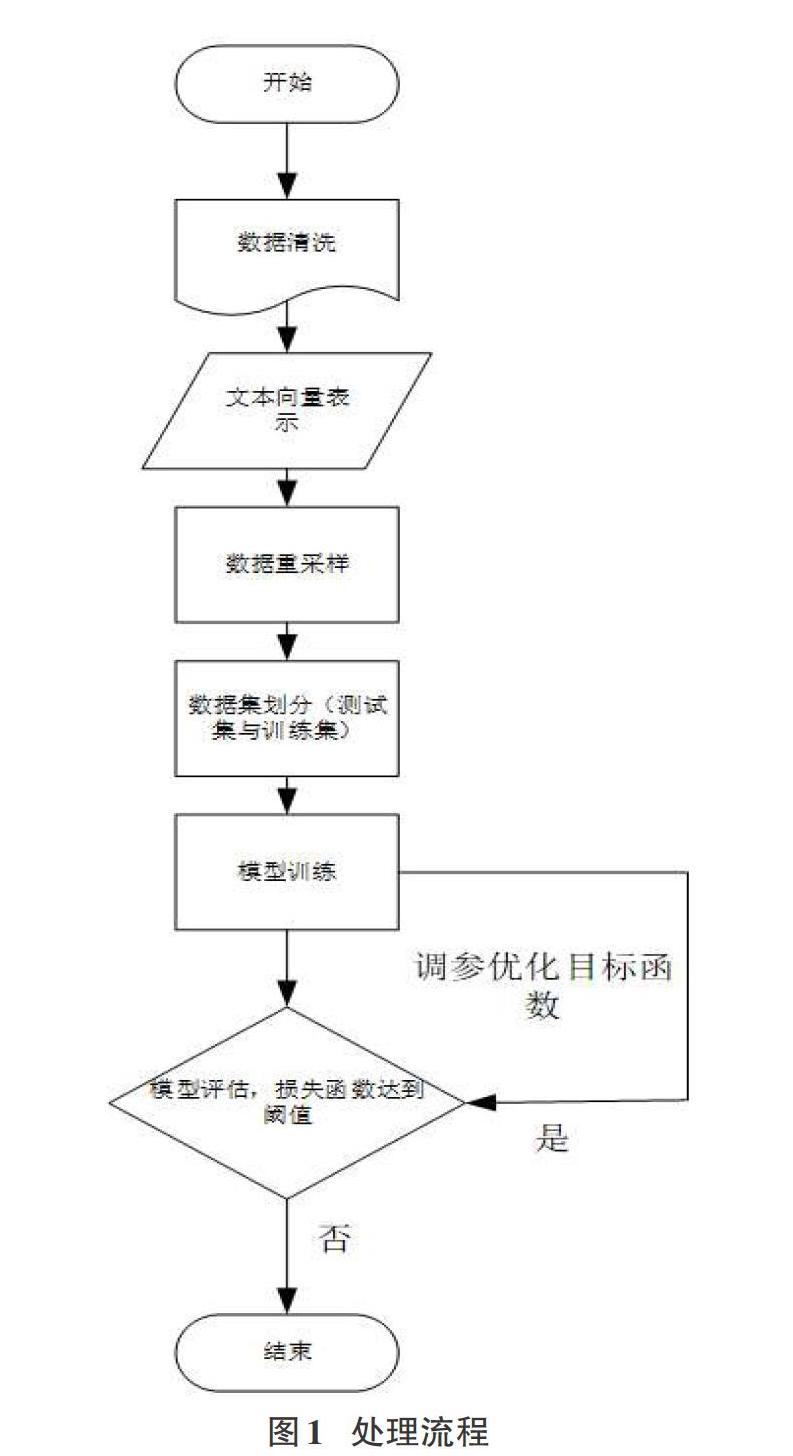
文章为了能够有效提高文本分类的精度,使用一种基于word2vec向量化和XGBoost的文本分类方法。其流程图如图1所示。
1.1 数据清洗
针对本文的中文数据采用的哈工大的jieba分词技术,停用词库来自哈工大数据源,经处理过后的如表2所示。
1.2 文本向量化
词的向量化表示是将语言中的词进行数学化表示,词的向量化表示主要有四种方式:(1)one-hot文本表示;(2)分布式表示;(3)TF-IDF权重文本表示;(4)word2vec模型神经网络模型表示。
本文主要采用第四种。word2vec表示主要是两种,包括CBOW和Skip-gram模型。图2所示,CBOW模型利用词w(t)前后n个词去预测当前词;Skip-gram模型则反之利用当前词w(t)去预测前后n个词。图3所示Skip-gram模型。
1.3 smote数据重采样
smote算法[8]是过采样中提出的新算法,分析少数类样本的特点,模拟生成新的样本,将新的样本插入到数据集中,不均衡的数据集变成均衡数据集来防止模型出现过拟合。采样原理如图4所示。
1.4 XGBoost算法
XGBoost【9】是陈天奇在基于GBDT的基础提出集成算法,与之相比,XGBoost对损失函数利用二阶泰勒展开式增加正则项寻求最优解避免过拟合,有效构建增强树,能在cpu上进行并行运算。树的集成模型如下:
[yi=k=1Kfkxi fk∈F] [1]
K是树的数量,F是树的集合空间,[yi]是模型的预测值,[xi]是第i个数据点的特征向量,[fk]是第k棵树,与叶子节点的权重w有关。
XGBoost模型由三部分组成,包括学习模型,参数调整和优化目标函数。目标函数优化程度决定模型的准确率,提高模型的泛化能力。故要通过损失函数最小化,增加模型复杂度的惩罚项实现对目标函数的优化。XGBoost模型目标损失函数由下两部分组成:
[L=i=1nlyi,yi+k=1KΩfk] (2)
第一部分由真实值[yi]和预测值[yi]之间的误差组成,第二部分[k=1KΩfk]是树的复杂度函数,用于控制模型复杂度正则项。[Ωfk]可表示為:
[Ωf=γT+0.5λw2] (3)
[γ]和[λ]为惩罚因子;T为树上的叶子数。式3在最小化序列的过程当中,每一轮训练增加增量函数[fi(xi)]。因此目标函数可以改为:
[Lt=i=1Nlyi,yit-1+fixi+Ωft] (4)
t表示训练第t轮,对于式(4),使用二阶泰勒级数展开式将第j棵树的每片叶子中的样本集合定义为[Ij=i|q(xi=j)]。目标损失函数的一阶导数是:
[gi=?yit-1lyi,yit-1] [5]
二阶导数是:
[hi=?2yit-1lyi,yit-1] (6)
由此可得:
[Lt?i=1ngiftxi+0.5hif2txi+Ωft?j=1Ti∈ Ijgiwj+0.5i∈ Ijhiλw2j+γT#]
(7)
定义公式[Gj=i∈ Ijgi]、[Hj=i∈Ijhi],式7简化为:
[Lt?j=1TGjwj+0.5Hj+λw2j+γT] (8)
[wj]的偏导数为:
[w`j=-GjHj+λ] (9)
权重向量w带入到目标损失函数得:
[Lt?-0.5j=1TG2jHj+λ+γT] (10)
由式10可得目标函数损失越小,模型的分类效果就越好,泛化能力越强。
2 实验
本文实验基于GPU图形工作站搭建实验环境:操作系统是windows7,内存48GB,显卡为GTX1080Ti,编程语言为Python3.7。
2.1文本分类模型主要指标
评估模型的指标主要包括准确率Precision、召回率Recall、F1指标。准确率是指文本分类正确的样本数与所有分类样本数的比例:
[Precision=aa+b] [11]
[Recall=aa+c] (12)
a代表被正確分类的样本数,b代表被错误分类的样本数,c代表属于该类却没有被分类出来的样本数。准确率和召回率是两个矛盾的指标,为能够真正反映模型的好坏,引入F1召回率指标,是文章主要考虑的指标。
[F1=2Precision*RecallPrecision+Recall] (13)
2.2 实验结果与实验分析
实验选择的数据集来自中航材导航技术公司提供的航行通告数据集,有883093条数据,类别高达1434种,类别最多的样本数有87081个,最少的仅有1个,为保证模型质量,筛选出样本数大于5的类别样本,剩下871010条数据,992个类别。word2vec的计算采用的gensim开源软件实现。主要超参数选择为sg=1,选择Skip-gram算法,特征向量维度为50,窗口为5,min_count为10。训练次数为30,最后训练出来的维度是50维稠密实数向量。经过word2vec词向量化后的数据进行smote算法重采样,对类别样本数小于5000大于5的数据使用smote重采样,将小样本数据构造成每种类别在10000条,保证数据集的相对均衡。XGBoost选择基于树的模型,分类器基分类器数量为100,最大深度为5,实验采用了5折交叉验证,评估准确性是交叉验证的平均值处理后的数据经模型处理其模型结果指标如图5-图7所示。
3 结论
本文研究了经word2vec神经网络向量化后的原始数据在smote算法重采样以及XGBoost集成算法处理后的模型。与没有经历过smote算法重采样的原模型相比较,F1等关键指标有了明显的提升。证明word2vec神经网络向量化算法在结合smote算法,能够很好能够对少数类数据进行一个良好的识别处理。
但研究本身存在一定的局限,首先模型运行时长相当缓慢,仅训练word2vec词向量时间就达数小时,使用XGBoost算法完成分类训练评估时间也接近半小时,模型的参数优化有着进一步优化的可能。其次本次模型没有使用朴素贝叶斯、SVM等机器学习常见的十分成熟的模型,仅仅考虑XGBoost算法,没有考虑全面。最后分类模型没有使用深度学习来做,如若未来能够使用深度学习等方法,无论是模型评价指标还是模型运行时间应该有进一步提高的空间。
参考文献:
[1] Baeza-Yates R,Ribeiro-Neto B.Modern Information Retrieval [M].New York:ACM press,1999.
[2] Gullo F,Ponti G,Tagarelli A.Clustering uncertain data via K-medoids[M]//Lecture Notes in Computer Science.Berlin,Heidelberg:Springer Berlin Heidelberg,2008:229-242.
[3] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[EB/OL].2013.
[4] Reynolds A P,Richards G,Rayward-Smith V J.The application of K-medoids and PAM to the clustering of rules[M]//Lecture Notes in Computer Science.Berlin,Heidelberg:Springer Berlin Heidelberg,2004:173-178.
[5] 周世兵,徐振源,唐旭清.新的K-均值算法最佳聚类数确定方法[J].计算机工程与应用,2010,46(16):27-31.
[6] Fernandez A,Garcia S,Herrera F,et al.SMOTE for learning from imbalanced data:progress and challenges,marking the 15-year anniversary[J].Journal of Artificial Intelligence Research,2018,61:863-905.
[7] 苏兵杰,周亦鹏,梁勋鸽.基于XGBoost算法的电商评论文本情感识别模型[J].物联网技术,2018,8(1):54-57.
[8] Chawla N V,Bowyer K W,Hall L O,et al.SMOTE:synthetic minority over-sampling technique[J].Journal of Artificial Intelligence Research,2002,16:321-357.
[9] Chen T Q,Guestrin C.XGBoost:a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.San Francisco California USA.New York,NY,USA:ACM,2016:785-794.
【通聯编辑:梁书】
