基于ABC-BP模型的煤层含气量预测
2021-05-23臧子婧吴海波张平松董守华
臧子婧,吴海波,张平松,董守华
(1.安徽理工大学 地球与环境学院,安徽 淮南 232001;2.中国矿业大学 资源与地球科学学院,江苏徐州 221116)
我国煤层气资源丰富,开发利用价值大,煤层含气量是煤层气资源开发的重要资料,准确地预测煤层含气量,不仅能大大降低煤层气资源开发的风险性,还能节约开采成本,提高煤层气开采效率[1-3]。充分挖掘地震资料所蕴含的信息,利用地震多属性优选融合技术提高煤层含气量的预测精度是目前煤层气储层预测研究的热点之一[4-6]。现有的研究多基于BP(Back Propagation,简称BP)神经网络预测模型,该模型非线性问题处理能力强,在数据拟合和函数逼近方面都具有明显的优势,计算精度更是高于传统的线性预测算法[7-8],但BP神经网络对初始值敏感,当网络层次较多时,容易导致计算量大、收敛慢、局部极小等问题[9-10]。
近年来,国内外学者们将神经网络算法作为研究对象,在煤层气储层预测建模和优化算法方面不断进行尝试,如施式亮等[11]提出了一种基于神经网络和遗传算法(Genetic Algorithm,简称GA)的煤与瓦斯突出区域预测模型;刘景艳等[12]提出了一种基于粒子群算法(Particle Swarm Optimization,简称PSO)优化神经网络的煤层瓦斯含量预测模型;杨桢等[13]提出了一种基于蚁群算法(Ant Colony Optimization,简称ACO)优化神经网络的瓦斯预测模型。上述预测模型均取得了较好的效果,但在训练过程中仍存在不足,如GA算法易早熟收敛、局部搜索能力较差;PSO算法在迭代后期易陷入局部最优解,且搜索精度不高;ACO算法寻优较盲目,收敛慢,容易发生停滞现象[14]。
相比较传统的优化算法,人工蜂群算法(Artificial Bee Colony,简称ABC)的控制参数更少,全局搜索能力更强,尤其适用于复杂问题的优化[15-16]。因此,笔者提出一种人工蜂群寻优算法改进的BP神经网络预测模型——ABC-BP预测模型,通过设计合理的蜂群和适应度函数,对神经网络的输入层与隐含层的连接权值和隐含层的阈值进行优化,从而增强BP神经网络预测模型的鲁棒性,提高预测精度和效率。
1 研究区概况
研究区块位于沁水盆地南缘,区内无大中型断层发育,中部发育一个向斜和一个背斜;预测的目标储层为3号煤层,位于下二叠统山西组下部,煤层厚5.04~7.16 m,平均6.11 m;煤质为低–中灰、高机械强度无烟煤;煤层原始的含气量高达16.6 m3/t以上。
研究区的勘探孔(井)布置如图1a所示,纵测线号(Inline)19~343,横测线号(Crossline)100~1 300,CDP网格尺寸为5 m×5 m;采用8线10炮制束状观测系统,单边激发、线距40 m、点距10 m、炮线距50 m、满覆盖次数32,炮检位置关系如图1b所示。本次所用三维地震数据体为经过常规处理和叠前偏移后的数据体,处理后的典型地震剖面如图2所示。
研究区内共有10个钻孔提供了煤层含气量解吸实验数据,但其中6口位于研究区边缘(图1a),地震记录覆盖次数为24,考虑到工区内煤层含气量数据较少,且覆盖次数相差不大,因此,边缘处的6口井数据仍作为本次的研究数据。本次预测将Q1201、Q1202、Q1204、Q1206、Q1208、Q1501、Q1502以及Q1503这8口井的数据作为训练样本,取中心处Q1203和边缘处的Q1205作为待预测对象,验证分析预测模型的准确性。

图1 研究区勘探情况Fig.1 Exploration in the study area
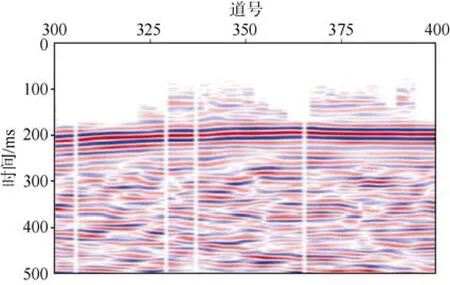
图2 处理的典型地震剖面Fig.2 Typical seismic profile after process
2 地震属性提取与优选
煤层含气量一般受地质构造、煤的变质程度、煤岩组分和煤层埋藏深度的影响,研究区煤层气赋存条件较好,但受褶曲构造的影响,造成了煤层气赋存非常不平衡。本文依据勘探区叠后三维地震数据体,沿3号煤层分别提取了9种不同类型的地震属性,分别是最大曲率、倾角属性、薄层属性、甜点属性、声阻抗、瞬时频率、瞬时加速度、瞬时振幅以及瞬时Q值,各属性均能在一定程度上反映含气性特征,其中,前3种地震属性能反映不同的沉积、构造特征,后5种地震属性主要用于识别岩性或储层特性,甜点属性多用于指示含气异常。各属性的提取涉及到大量数学公式,这里不再一一赘述。
本文采用R型聚类分析对9种地震属性进行了分类优选,目的是为了确保所选地震属性对煤层含气量变化最为敏感且相互独立,具体步骤如下。
①将9种地震属性数据进行归一化,按照式(1)计算两两之间的相关系数,组成系数矩阵;将系数矩阵进行数据变换,把相关系数转化为距离,按最长距离法进行聚类,聚类分析结果如图3所示。由图3分析可知,9种属性可大致分为相互独立的A、B、C、D这4种类型。

其中,xi、xj为归一化后各个属性。
②提取井位处的9种地震属性值及相应的煤层含气量,在归一化处理的基础上,按照式(2)计算出各属性和煤层含气量的相关系数(表1)。
③分别在上述四类属性中优选出对地质目标反应最敏感的1种组成本次预测用的地震属性集(表1)。优选的地震属性分别是倾角属性、薄层属性、最大曲率以及瞬时Q值,各优选地震属性切片如图4所示。

式中:xi为井位置处归一化后各个属性;y1为归一化后的煤层含气量数据;cov为协方差函数。
其中,倾角属性的分布可直观地展示目的层构造特征;薄层属性用于指示煤层厚度特性;曲率属性常用来识别断层、褶皱;瞬时Q值与地震波衰减吸收系数成反比,各属性均能在一定程度上反映煤层气藏的变化。
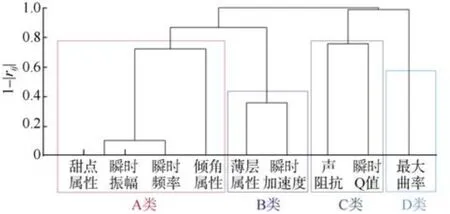
图3 地震属性聚类分析Fig.3 Clustering analysis of seismic attributes
3 煤层含气量预测模型构建
3.1 BP神经网络算法
BP网络又称误差反向传播神经网络,由输入层、隐含层和输出层构成,每一层都由若干个神经元组成。其结构如图5所示。BP神经网络除了具有非常强大的非线性映射能力、自主学习和自适应能力,还具有不俗的泛化能力和容错能力[17]。
BP神经网络按有监督学习方式进行训练,当学习样本输入网络后,其神经元的激活值将从输入层经各隐含层传到输出层,并输出网络响应结果。然后,遵循期望输出与实际输出误差最小的原则,将误差信号沿原来的连接通路返回并逐层修正连接权值和阈值,直到误差信号满足精度要求为止。

表1 井位置的各属性与煤层含气量相关系数Table 1 Correlation coefficient between each property of well location and gas content of coal seam
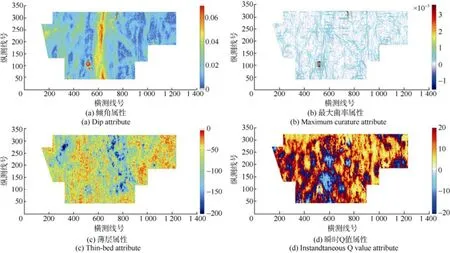
图4 通过聚类分析优选出的4种研究区3号煤层地震属性切片Fig.4 Four kinds of seismic attribute slices of No.3 coal seam in the study area were selected by cluster analysis

图5 BP神经网络结构Fig.5 BP neural network structure
由于BP算法本质为梯度下降法,因此,当目标函数非常复杂,或样本数量不足时,该方法容易陷入局部极值,导致计算量大、收敛慢等问题[18]。
3.2 ABC-BP预测模型与参数设置
人工蜂群算法是一种通过模拟蜂群采蜜行为而解决优化问题的群智能算法。它是由雇佣蜂、跟随蜂、侦察蜂以及蜜源组成,蜜蜂根据各自的分工进行不同的活动,通过蜂群间不断地交流、转换与协作,从而找到问题的最优解[19-21]。
本文利用ABC智能寻优算法对BP神经网络各层神经元的权值和阈值进行了优化,具体优化步骤如下。
①设置BP神经网络的基本结构、参数,如InDim、OutDim、HiddenNum等,输入学习样本以及待预测数据,进行归一化处理。
②设置ABC参数,各蜂群总数SN=100,SN也表示蜜源个数,蜜源被采集次数即最大迭代次数Maxicircles=150及控制参数Limit=50,确定问题搜索范围,并且在搜索范围内随机产生初始解xi(i=1,2,…,SN),每个解xi是一个D维的向量。
③按照式(3)计算并评估每个初始解的适应度,设定循环条件并开始循环。

式中:RMSEi为第i个解的BP网络均方误差。
④雇佣蜂对解xi按照式(4)进行邻域搜索产生新解(蜜源)vi,并计算其适应度值。

式中:φij为[–1,1]之间的随机数;k∈{1,2,…,SN},j∈{1,2,…,D},且k≠i。
⑤按照式(5)进行贪婪选择,如果vi的适应度值优于xi,则用vi替换xi,将vi作为当前最好的解,否则保留xi不变,失败次数加一。
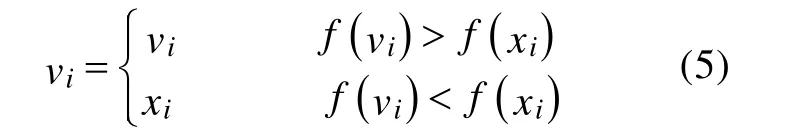
⑥根据式(6)计算蜜源的概率pi,跟随蜂依照概率pi选择解或食物源,按照式(4)搜索产生新解(蜜源)vi,并计算其适应度,并重复步骤⑤。
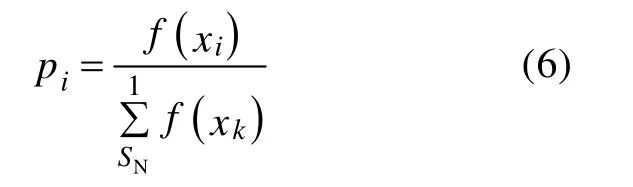
⑦判断是否有要放弃的解,若有,则侦查蜂按式(7)随机产生新解替换,记录到目前为止的最优解。

⑧判断是否满足循环终止条件,若满足,循环结束,输出最优解,否则返回步骤④继续搜索。
⑨迭代停止后,输出当前全局最优解,提取BP神经网络的最优权值和阈值,代入到BP神经网络中进行训练学习,完成预测后,将输出数据反归一化即为最终预测结果。
在ABC-BP预测模型中,SN参数对算法性能的影响具有不确定性,多次试验后取值为100;Maxicircles参数取值越大,优化效果越好,但不宜超过200;Limit参数只要不设置过小,对算法性能影响很小。
此次,隐含层中的神经元均采用Log-sigmoid型传递函数,输出层的神经元则采用ReLU型传递函数。学习样本为第2章节中优选出的4种地震属性及第1章节中8口井数据:输入为井位置处的优选地震属性值,输出为与之对应的煤层含气量值,整个预测流程如图6所示。
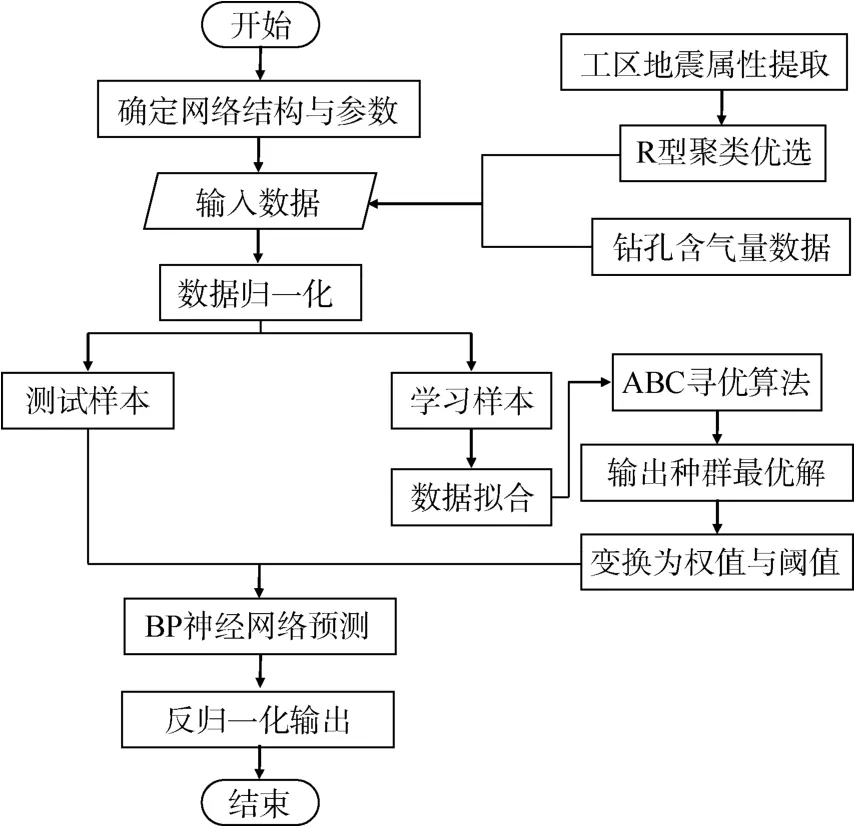
图6 预测流程Fig.6 Prediction workflow
4 煤层含气量预测结果与分析
本次研究按照图6所示的预测流程,基于学习样本训练好的ABC-BP模型,以整个工区目标储层的优选地震属性为输入,进行研究区的煤层含气量预测,并与传统BP神经网络模型预测结果进行了对比,如图7所示。两模型预测值与实测值误差分析对比见表2。其中,井Q1203与Q1205为验证井,未参与模型训练。
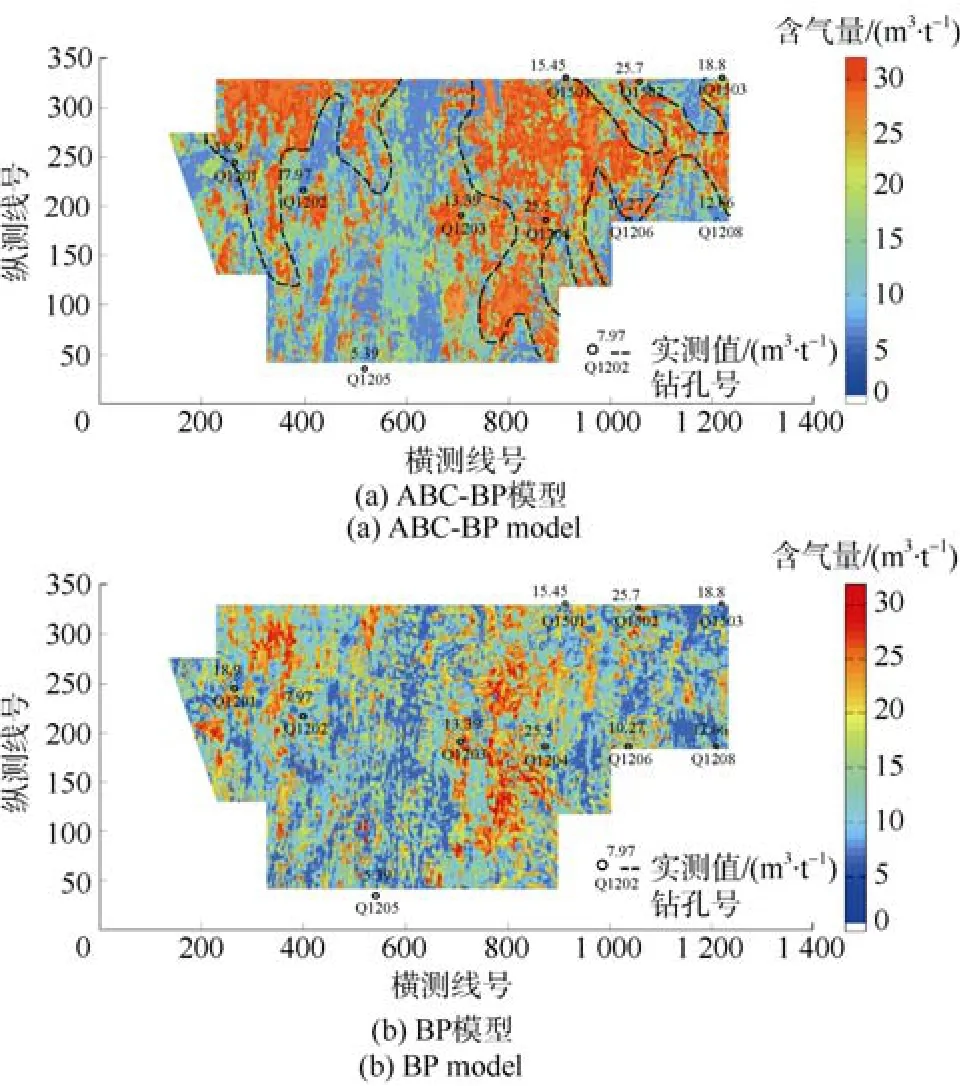
图7 目标煤储层含气量预测结果Fig.7 Gas content prediction results of target coal reservoir
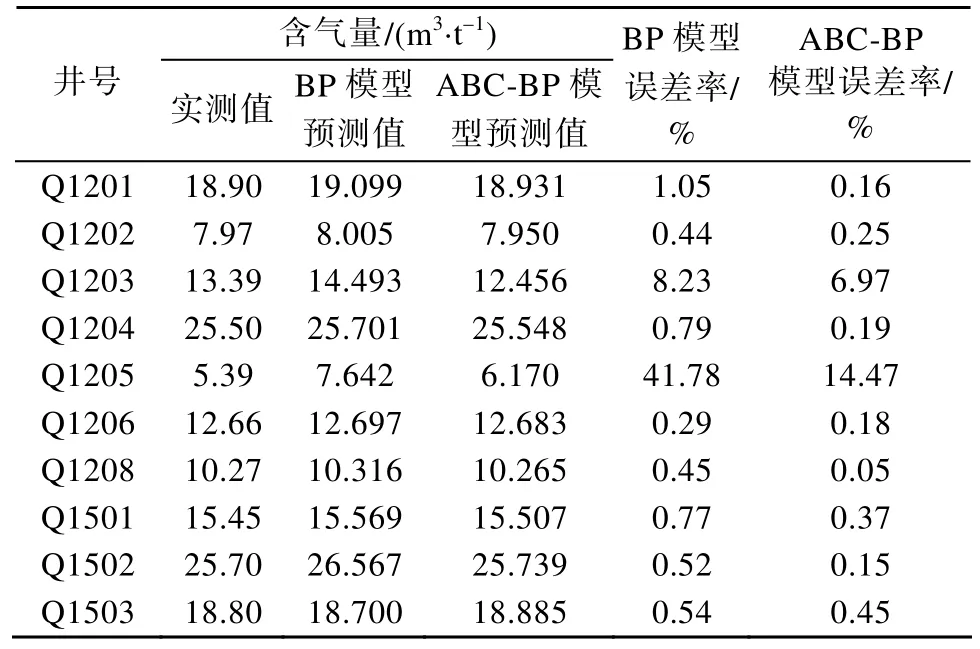
表2 井位置煤层含气量预测值与实测值误差分析Table 2 Error analysis of predicted and measured gas content of coal seam in well location
各井煤层含气量实测数据表明:由于井Q1501、Q1502、Q1503以及Q1204的煤层含气量实测值均大于15 m3/t且位置相对集中,其附近井Q1203、Q1206、Q1208的煤层含气量实测值则处于10~15 m3/t,初步判断煤层含气量高值区应集中于Q1501、Q1502、Q1503、Q1204附近,研究区其余煤层气井附近,煤层含气量则有下降的趋势;位于横测线400~600区域的井Q1202、Q1205的煤层含气量实测值为5~8 m3/t,而位于横测线244的井Q1201的煤层含气量实测值却高达18.9 m3/t,初步判断井Q1202、Q1205附近存在低含气区,仅在井Q1201处有局部增高现象。
由图7a可知:煤层含气量高值区大致分布在黑色虚线区域(H区)内,少数煤层含气量高值区在工区内零散分布;煤层含气量低值区分布在横测线号600左右;其余位置煤层含气量中等,较周围高值区或低值区有渐变趋势。这一预测结果与各井含气量的变化趋势基本吻合,这表明ABC-BP模型的煤层含气量预测结果具有一定可靠性。
由图7b可知:煤层含气量高值区主要分布在横测线号800附近位置,部分分布于横测线号大于300的区域;煤层含气量低值区分布在横测线号为600和1 000的附近;其余位置煤层含气量中等,较周围高值区或低值区有渐变趋势。根据上述煤层含气量实测值分析,可明显发现BP模型预测结果对煤层气高值区识别不明显,且无论是高值区还是低值区均较分散,难以识别,预测效果欠佳。
根据表2的仿真结果可知:对比同一井处的煤层含气量实测值和预测值,BP模型和ABC-BP模型均有较好的吻合,ABC-BP模型训练样本的平均误差率为0.23%,BP模型训练样本的平均误差率为0.61%,ABC-BP模型的误差明显低于BP模型;对于验证井Q1203和Q1205,ABC-BP模型的预测结果误差不超过1 m3/t,误差率分别是6.97%和14.47%,而BP模型的误差率则为8.23%和41.78%,预测精度较差。相较于传统的BP神经网络,改进后的ABC-BP预测模型预测精度更高,误差范围更稳定,预测效果更加理想。
5 结论
a.本文利用人工蜂群算法(ABC)有效优化了BP神经网络的连接权值和阈值,构建了ABC-BP模型,解决了BP神经网络计算量大,收敛慢,容易陷入局部极小等问题。相比较传统的改进方法,ABC算法的快速全局寻优能力更强,进一步提高了BP神经网络的预测性能。
b.本次研究以井位置的优选地震属性和含气量数据为样本训练了ABC-BP模型,通过整个工区优选地震属性的输入,实现了目标煤储层含气量的定量预测,其中,训练井处的平均误差率为0.23%,验证井处的误差率低于15%。因此,基于优选地震属性和ABC-BP的预测模型可有效用于煤层含气量的预测。
c.本次煤储层含气量预测结果精度受优选地震属性质量、样本位置以及样本数量的影响,这些因素的影响还需要进一步的研究。
