可靠多模态学习综述*
2021-05-23詹德川
杨 杨 ,詹德川 ,姜 远 ,熊 辉
1(南京理工大学 计算机科学与工程学院,江苏 南京 210094)
2(计算机软件新技术国家重点实验室(南京大学),江苏 南京 210023)
3(Rutgers Business School,Newark,NJ 07012,USA)
1 引 言
“一本《红楼梦》,经学家看见《易》,道学家看见淫,才子看见缠绵,革命家看见排满,流言家看见宫闱秘事.”——鲁迅.
现实世界中,复杂对象从不同角度分析拥有不同的属性特征.如图1 所示,现实应用中复杂对象通常可以通过多模态信息加以描述,多模态学习也有着广泛的应用场景,网页包含文本、图片和超链接等信息;视频可以分解为图片帧、音频和文本;文章可以通过不同语言表示;手机应用从不同传感器收集信息进行分析,等等.可见,样本可以通过不同通道的信息加以描述,每一通道的信息定义为一种特定的模态.因此,较之单模态数据,多模态数据可以提供更丰富的信息表示,且基于多模态数据表示也有着极其广泛的应用,如基于图文数据的热点推荐、基于多传感器信号的无人驾驶、基于视频语音的字幕生成等.
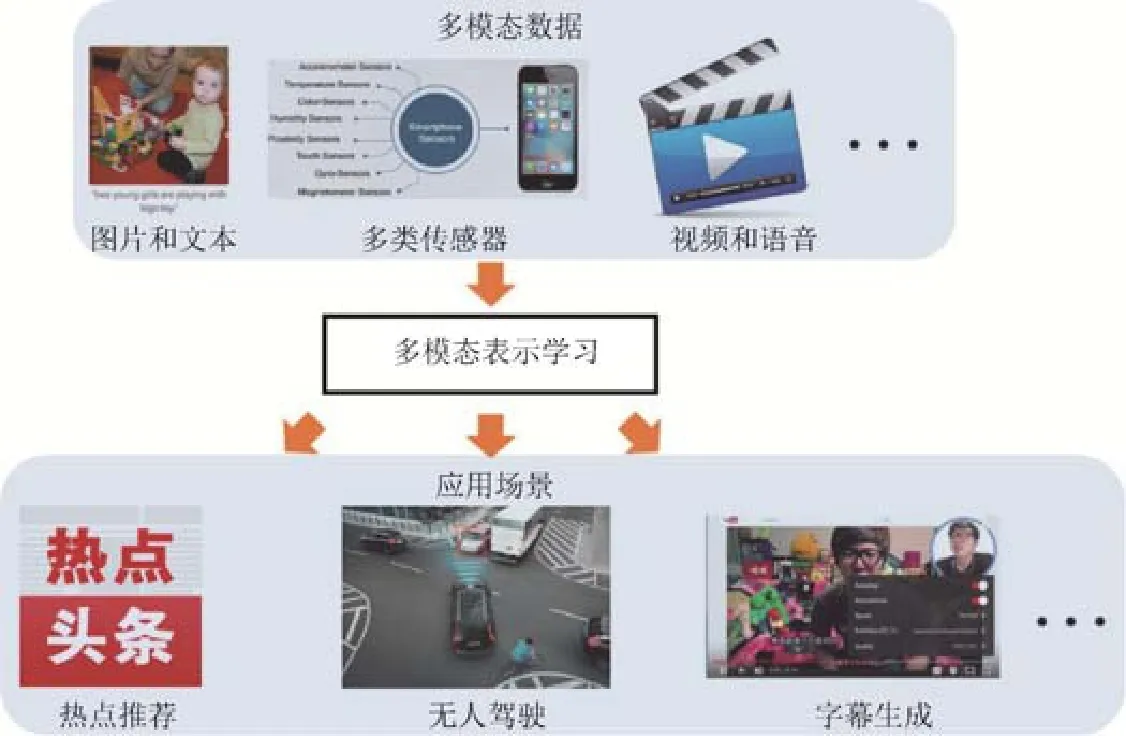
Fig.1 Multi-modal data and applications图1 多模态数据及应用
较之单模态学习,多模态学习通常考虑如下两方面的研究内容:(1) 单模态学习性能;(2) 模态间相关性度量及利用.采用的主要策略是将二者纳入统一框架中进行联合优化,进而为每个模态学习更具判别性的语义表示,构建模态间的映射关联,提升模型性能.具体地,传统多模态方法大致可分为两类:(1) 基于协同训练思想的方法;(2) 基于协同正则化思想的方法.协同训练(co-training)[1]是多模态学习早期学习方法之一,其利用模态间的互补性准则,最大化两个不同模态未标记数据的互一致性(即挑选最置信的未标记样本标记伪标记,提供给其他模态学习)提升单模态的性能.基于这一思想设计出众多衍生方法,如 Co-EM[2]、Bayesian co-training[3]、Co-Trade[4]等.作为多模态学习的另一个重要分支,协同正则化(co-regularization)[5]则是利用模态间的一致性准则,最小化两个不同模态未标记数据的预测差异性来排除不一致的假设.进一步地,研究者基于该思路提出其他模型,如SVM-2K[6]、MSE[7]等.此外,基于子空间学习方法(如CCA[8])、基于多核学习方法(如MKL[9])也可归为利用一致性准则的协同正则化方法.值得注意的是,早期基于互补性准则的协同训练类型方法通过各模态最置信的未标记样本的伪标记信息进行相互教学,其本质也可看作潜在标记的一致性,因此传统的两类方法都关注利用样本不同模态间的强相关性.相对于早期传统的多模态学习方法,近些年一些研究转而注重学习或度量模态间的互补信息表示,以此增强模态的融合性能[10],本文将在第2.2.3 节具体介绍该类方法.同时,多模态理论研究也有所建树,如协同训练的泛化界[11]、基于信息熵的多模态理论框架[12].然而,在开放环境下,考虑信息缺失、噪声干扰等问题,模态间的强相关性难以满足,传统多模态学习方法仍面临着巨大挑战.同时,多模态学习与机器学习中的其他研究领域也紧密相关,研究内容丰富,如集成学习[13]、领域适配[14]、主动学习[15],考虑到与本文主题关联较低,这里不再一一赘述.
1.1 多模态学习面临的挑战
真实开放环境下,多模态数据通常会受到噪声、自身缺陷及异常点等干扰,使得上述互补性及一致性准则难以得到满足.究其原因,主要体现在学习过程中出现的未标记样本伪标记噪声、采样偏差及模态特征表示、模型性能差异等问题,进而导致模态表示强弱以及模态对齐关联的不一致.具体表示为:
1) 模态表示强弱不一致.传统多模态学习方法通常考虑模态间的一致性,即特征或预测的一致性.而在开放环境下,噪声等因素会造成单模态的信息不充分[16],进而导致单模态特征、预测的噪声和模态间的差异性,造成模态之间存在强弱之分.直接使用传统的互补性或一致性准则会造成模型优化偏差,影响模型联合训练;
2) 模态对齐关联不一致.传统多模态学习方法通常假设同一样本拥有全量的模态信息,且模态间的关联关系也是事先确定的.而开放环境中,考虑到隐私保护、数据收集缺陷等因素,多模态数据存在模态缺失问题[17],即样本可能仅获得部分模态信息,而非全量信息.同时,考虑到人工标注代价等因素,同一任务获得的不同模态间的对应关系也可能不明确[18].
综上所述,模态表示强弱不一致和模态对齐关联不一致是多模态数据在开放环境下凸显的两大新的挑战,也是造成传统多模态学习方法在真实数据集上甚至出现性能退化现象的关键因素.针对这些挑战,可靠多模态学习(也称鲁棒多模态学习)开始受到国内外研究的广泛关注.针对模态表示强弱不一致问题,文献[19,20]提出利用强模态作为软监督信息辅助弱模态,文献[21,22]考虑加权等操作排除不一致样本的干扰;针对模态关联不一致问题,文献[17]考虑缺失模态的聚类,文献[23]考虑不对齐多模态的融合.
1.2 多模态学习的主要技术与应用
目前已有一些关于多模态学习的综述发表[24-26],这些综述大多着重于总结传统多模态学习方法及其应用.例如,文献[25]总结了传统多模态子空间学习、多核学习及协同学习,并给出了当前深度多模态学习的进展;文献[24]则从多模态应用层面出发介绍相关的学习方法,包括:(1) 模态表示学习;(2) 模态映射学习;(3) 模态对齐学习;(4) 模态融合学习;(5) 模态协同学习,并给出其在视觉领域、多媒体领域的诸多应用.表1 给出了上述5 种多模态技术在不同实际场景中的具体应用.

Table 1 Main techniques and applications in multi-modal learning[24]表1 多模态学习的主要技术与应用[24]
值得注意的是,大多综述忽略了第1.1 节中所描述的多模态学习所面临的挑战,为此,本综述将具体分析针对这两个挑战的国内外相关研究现状,并介绍目前可靠多模态学习的研究进展.
1.3 论文的组织
本文首先概述传统多模态学习中基于互补性和一致性准则的方法,其次具体分析开放环境下多模态数据凸显的“模态表示强弱不一致”“模态对齐关联不一致”两大挑战,并介绍目前针对这两个问题的可靠多模态学习研究进展状况,内容安排的具体框架如图2 所示.特别地,随着深度学习的兴起,适应不同领域的深度模型均取得远超传统模型的性能,而目前先进的多模态方法也通常选择相应的神经网络,如卷积神经网络、长短记忆神经网络作为各模态(图片、文本)的基模型,并设计相应的损失函数进行联合训练,为此本文也将着重介绍目前高性能的多模态深度学习模型.
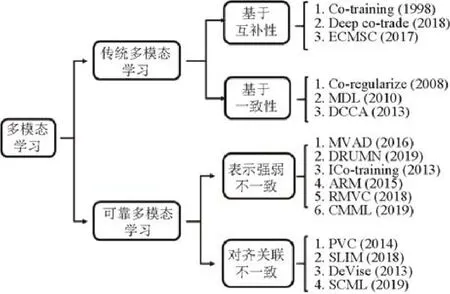
Fig.2 The framework of the survey,including traditional and reliable multi-modal learning图2 本文整体组织框架(包括传统多模态学习和可靠多模态学习)
2 传统多模态学习
本节首先介绍多模态学习的两种基本准则,然后具体介绍相应的学习方法.在无特殊说明的情况下,本文所介绍的方法一般以两模态为例,不失一般性,扩展到多模态通常采用两两遍历加和形式.
2.1 两种基本准则
传统多模态学习的精髓在于如何有效地考虑模态间的关联性,通常要求服从两个基本准则:互补性和一致性.互补性准则描述每个模态的数据可能包含其他模态所欠缺的信息,因此综合考虑多模态信息可以更全面地描述数据并提升任务性能.具体地,假设数据集X包含两个模态X1和X2,进而单样本可以表示为其中,yi是标记信息.数据满足以下3 个假设:(1) 充分性,即每个模态自身含有充分信息进行分类;(2) 兼容性,即两个模态大概率具有共现特征,能够预测相同标签;(3) 条件独立,即给定标签情况下模态条件独立.基于上述假设,文献[1]给出如下结论:如两个模态是条件独立的,那么协同训练会提升单模态性能.文献[11]则进一步给出了基于PAC 理论的协同训练的泛化误差界,证明两个模态的一致性是单模态模型性能的上界.考虑到条件独立假设过强,因此文献[27,28]等工作进一步放松该假设,并给出相应的泛化误差理论证明.
相对于互补性准则,一致性准则旨在最大化两个不同模态的一致性.假设数据集X包含两个模态X1和X2,文献[29]证明两个模态的一致性和单模态错误率之间的关联为
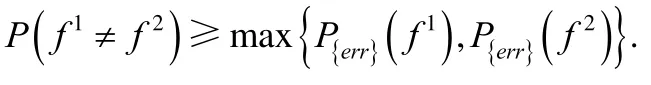
依据上式可以得出两个独立模态模型不一致的概率是单模态模型最大错误率的上界.因此,通过最小化两个模态模型的不一致,每个模态模型的错误率将被最小化.殊途同归,可以看出,互补性本质上也是一致性的一个变种.
2.2 基于互补性准则的方法
2.2.1 Co-training
Co-training[1]假设样本有两个条件独立的模态,给定L个有标记样本和U个无标记样本,Co-training 采用如下迭代训练方式.
Step 1.无放回地从无标记数据集U构造数据池U';
Step 2.分别用两个模态X1和X2的有标记数据训练两个朴素贝叶斯学习器(可替换其他弱学习器)h1和h2;
Step 3.每个模态用训练好的学习器在U'中为本模态挑选p个最置信正例和n个最置信负例的无标记样本,标上伪标记加到L中重训练.从而X1可以获得X2互补的信息,X2也可以获得X1互补的信息;
Step 4.从U中重新填充2p+2n个样本到数据池U'.
2.2.2 Deep co-trade
基于集成学习的思想,文献[4]提出Co-trade 算法.该算法首先对有标记数据进行可重复取样得到3 个训练集并训练3 个对应的学习器,且在协同训练的过程中,每个学习器获得的新数据集合都是通过其他两个学习器投票得到.同时,随着深度网络的成功应用,文献[30]基于Co-trade 的思想提出了Tri-net.如图3 所示,Tri-net 首先对训练数据用不同大小的卷积核构造3 个不同的训练集,并且采用Output smearing 技术(对训练集的真实标记加入随机噪声)来构造差异性更大的无标记数据.随后采用Tri-training[31]的思想对无标记数据预测标记并带回训练集重新训练.

Fig.3 The illustration of Tri-net,which utilizes multiple classifiers for ensemble[30]图3 Tri-net 示意图[30].采用多个学习器集成学习
而当扩展到两模态以上的场景时,Tri-net 也可以衍生出很多变种,包括:(1) 为每个模态建立学习器,再采用集成思想结合其他模态学习器为当前模态的无标记数据投票得到新标记;(2) 为每个模态基于Tri-training 思想建立多个学习器,再用两层的堆叠(stacking)技术为无标记数据投票得到新标记.
2.2.3 ECMSC
不难看出,传统协同训练方法局限于运用标记相互教学,仍属于潜在的标记一致,缺乏学习量化模态间的互补信息.因此,文献[10]提出一种新颖的多模态聚类方法ECMSC(exclusivity-consistency regularized multi-view subspace clustering),ECMSC 兼顾多模态特征表示的差异性和聚类指示矩阵的一致性,其新颖点在于使用了差异化正则凸显模态的互补信息.差异性可通过如下矩阵Hadamard 乘积来定义.
定义1.两个矩阵U∈ℝn×n和V∈ℝn×n之间的差异性定义为 H(U,V)=||U⊙V||0=∑i,j(u ij·vij≠0),其中,⊙表示Hadamard 乘积(对应位相乘),|| ·|0| 表示 ℓ0范数.
ℓ0范数可以放松到 ℓ1范数,于是两个模态聚类结果的差异性可以表示为 H(Z v,Zw)=||Z v·Zw||1.
每个模态聚类指示矩阵和潜在一致的聚类指示矩阵的关联可以延用以往常用的约束,具体为
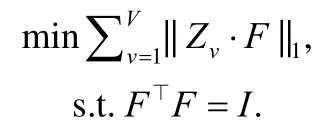
将定义1 中的差异性正则扩展到多模态谱聚类中,新模型表示为
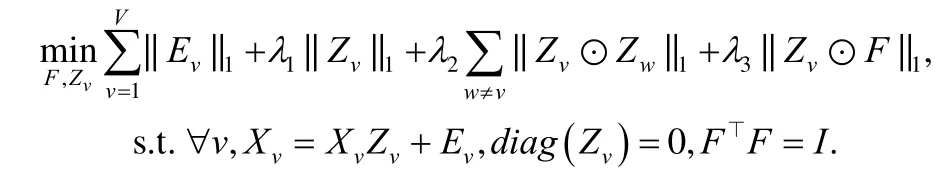
其中,||Zv||1的作用是保证稀疏性,约束项中每个模态的聚类指示矩阵则可以看成字典学习的表示形式,噪声损失项则采用 ℓ1范数来处理稀疏噪声.
该模型的本质思想也是一种对抗学习,一方面希望体现不同模态的差异性(第2 项),另一方面则希望单模态的聚类指示函数与潜在真实的聚类指示矩阵一致(第3 项).在优化方面,ECMSC 也可以采用ADMM 进行并行优化.值得注意的是,第2 项的差异正则实质上可以采用很多其他形式,如HSIC 等.
2.3 基于一致性准则的方法
基于一致性准则的方法可以分为:(1) 约束模态预测一致性;(2) 约束模态特征表示的一致性.
2.3.1 Co-regularization
半监督学习方法协同正则化(co-regularization)[5]考虑预测的一致性约束.具体地,给定少量有标记数据(xi,yi)和大量的无标记数据(xj),协同正则化为每一个模态学习一个最优学习器:
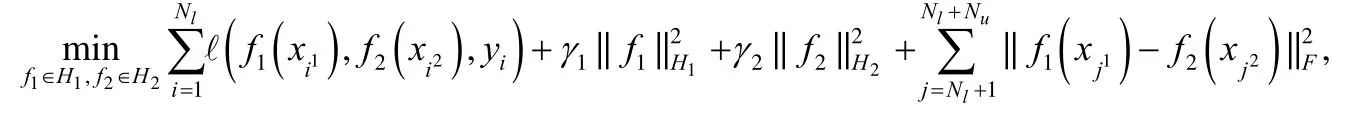
其中,f1∈H1,f2∈H2,分别是两个模态的学习器,H1和H2是两个模态的假设空间.计算两个模态预测集成结果和真实结果的损失.不失一般性,ℓ一般取平方损失,即运用RKHS 范数度量模型c的复杂度.起关键作用的最后一项则是强制不同模态在无监督数据上的一致性,Nl和Nu是有标记数据和无标记数据的大小.文献[32]证明,通过度量两个函数类的“距离”可以约束无标记数据的一致性,进而降低Rademacher 的复杂度.测试阶段,样本预测结果为
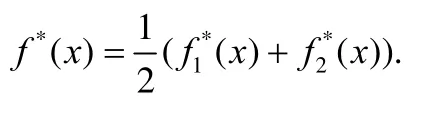
2.3.2 DCCA
典型性相关分析CCA(canonical correlation analysis)[8]则是约束模态特征表示的一致性.具体地,对于X1∈两个模态数据,每个模态学习投影向量将两个模态投影到相同维度的子空间,并最大化两者投影后特征间的相关系数:
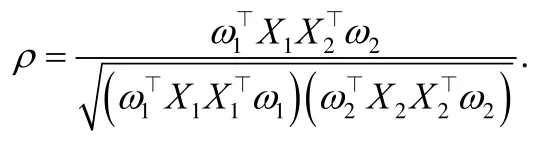
因为对ω1和ω2具有伸缩不变性,CCA 等价为
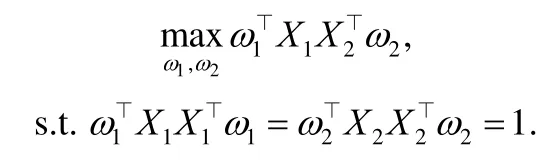
而ω1和ω2也可以通过求解广义特征值问题的最大特征值对应的特征向量而得到:
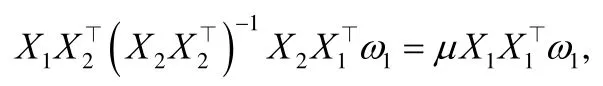
其中,μ是特征向量1ω的特征值,2ω也可以类似求得.文献[46]则将CCA 扩展面向多模态的多重集典型相关分析MCCA(multiple CCA),并利用多核稀疏保持投影有效扩展为多模态场景.值得注意的是,MCCA 采用两两模态关联加和形式.考虑到神经网络强大的非线性表示能力,文献[33]提出了DCCA(deep CCA),如图4 所示,DCCA为每个模态分别建立单独的神经网络进行特征学习,再将不同模态的特征输出线性投影到共享子空间,最大化模态间的相关性,具体表示为
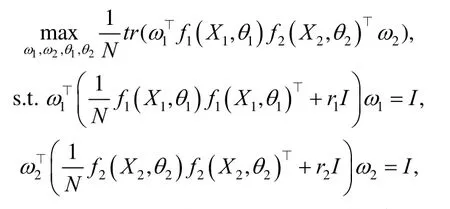
其中,f1和f2表示各模态的神经网络,θ1和θ2是其对应的网络参数.特别地,文献[33]的实验发现,全量数据的L-BFGS 二阶优化效果远好于批量数据的一阶随机优化,说明优化过程中采样数据的大小与相关性计算有着密切的联系.
Fig.4 The illustration of DCCA,which combines the CCA and deep networks[33]图4 DCCA 框架[33].该方法结合CCA 思想和深度模型框架
进一步地,DCCAE(deep auto-encoder CCA)[34]综合考虑了自编码网络和DCCA 思想,相应的模型表示如下:

2.3.3 MDL
文献[35]提出了基于模态隐空间表示一致的多模态深度网络MDL(multi-modal deep learning),如图5 所示.MDL 在训练阶段利用深度网络学习不同模态在同一子空间共享的隐含表示,再重构不同模态的原始输入.图5左图所示为单模态输入重构多模态,右图所示为多模态输入重构多模态.值得注意的是,MDL 共享隐空间表示学习可以自然地扩展为两模态以上的多模态表示学习,无需像子空间表示学习方法那样两两加和扩展为多模态场景.
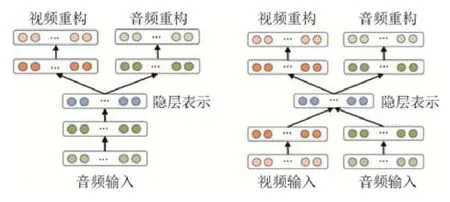
Fig.5 The illustration of MDL,which employs deep auto-encoder for representation learning[35]图5 MDL 框架[35].该方法考虑深度自动编码网路进行模态隐空间表示学习
2.4 讨 论
本节介绍了基于互补性和一致性准则的传统多模态学习方法.万变不离其宗,这两类多模态学习方法都利用了模态间的强相关性:(1) 标记预测的强相关性.协同训练类型方法利用潜在一致的伪标记进行互补教学,协同正则化方法利用各模态对齐无标记数据预测的一致性作为正则化项;(2) 特征表示的强相关性.子空间特征约束和隐空间特征约束方法均考虑了各模态数据相同维度特征表示的相关性度量,其中,隐空间特征学习方法可有效扩展为多模态场景,而其他方法则需两两度量.
针对传统的聚类、分类等任务,多模态较之单模态可提供更具判别性的特征表示,其思路可类比于单模态集成学习中的特征抽样、单模态半监督学习中的数据增广,从而在特征层面为样本提供更加丰富的表示.基于模态间强相关性有效地利用各模态无标记数据,进而可有效地提升聚类、分类的集成性能.在聚类、分类任务中,互补性和一致性体现为特征的互补性和标记的一致性,二者相辅相成.另一方面,针对多模态特有的跨模态检索、描述、问答等任务,其需要构建跨模态特征嵌入间的映射关联,这类多模态学习则更注重特征表示的强相关性应用,对互补性考虑较少.
3 可靠多模态学习
在开放环境下,各模态的信息差异性较大,呈现出不均衡性,其强相关性很难保证,致使传统的多模态学习方法面临着巨大挑战.本节首先指出不均衡多模态数据凸显的表示强弱不一致和对齐关联不一致两大挑战,之后具体介绍针对这些挑战目前有关可靠多模态学习方法的最新研究进展.
3.1 不均衡多模态数据
开放环境下,噪音、自身缺陷等因素会导致模态的不充分,进而产生模态间的差异性.如图6 所示,图文对出现不同程度的不匹配现象.

Fig.6 The inconsistent multi-modal data,in which the image-text pairs have inconsistency problem图6 表示强弱不一致的数据.图文对呈现不同程度的不匹配问题
可见,数据的各模态所有拥有的信息呈现差异性,具有强弱之分.又如身份识别中指纹信息更丰富,而受遮挡的人脸信息较难区分;病理检测中核磁共振图像能够提供更有效的病理结构,而X 光检测提供信息较为局限.因此,针对表示强弱不一致的多模态数据,目前研究主要分为3 类:(1) 模态表示不一致的异常点检测.较之单模态异常点检测,多模态异常点检测更为复杂,拥有额外的模态不一致属性的异常点,需设计更鲁棒的多模态不一致度量.为此,第3.2.1 节和第3.2.2 节将给出具体介绍;(2) 模态表示不一致的辅助学习.模态信息差异导致强弱之分,而强模态的收集代价通常比弱模态更加昂贵,为了有效减少数据收集开销,需利用强模态在训练阶段辅助弱模态建模,进而在测试阶段仅需弱模态即可预测.为此,第3.2.3 节和第3.2.4 节将具体加以介绍;(3) 模态表示不一致的加权融合.更一般的场景是不同样本的模态强弱也不尽相同,模态强弱存在自适应性,需自主地学习各样本不同模态的权重,进行加权融合.为此,第3.2.5 节和第3.2.6 节将具体给出介绍.
此外,传统多模态学习中模态的对齐关联是事先给定的,样本拥有全量的多模态数据.然而,考虑到深度学习通常需要大量的数据进行训练,而拥有大规模标注对齐的多模态数据十分困难.现实应用中多模态数据出现对齐关系不一致现象,如图7 所示:(1) 样本模态出现缺失问题,即仅少量样本拥有全量模态;(2) 样本仅拥有非平行模态信息,即对齐关联缺失.

Fig.7 The non-parallel multi-modal data,in which the data exists modality or alignment missing图7 对齐关联不一致的数据.数据出现模态缺失或对齐关系缺失
针对对齐关系不一致的多模态数据,目前的研究方法主要分为两类:(1) 缺失多模态学习.此类方法主要考虑如何利用现有的多模态数据进行跨模态补齐,并进行后续聚类、分类操作.第3.3.1 节和第3.3.2 节将具体加以介绍;(2) 非平行多模态学习.此类方法主要考虑如何利用潜在一致的标记信息建立模态间隐含关联,进行辅助学习、跨模态映射.第3.3.3 节和第3.3.4 节将具体给出介绍.
3.2 针对表示强弱不一致的方法
3.2.1 MVAD
文献[21]提出概率隐变量模型MVAD(multi-view anomaly detection)来检测模态不一致的异常点.MVAD 假设所有一致的样本是由单个隐向量生成,而异常点则由不同隐向量生成.通过狄利克雷过程先验(Dirichlet process priors)可以推断每个样本隐向量的个数,进而获得每个样本异常的概率.如图8 所示,对于多模态样本X的生成过程如下所示.
Step 1.刻画参数α~Gamma(a,b);
Step 2.对每个样本n=1,2,...,N
(a) 刻画混合权重θn~Stick(γ);
(b) 对每个隐向量:j=1,2,...,∞:刻画一个隐向量znj~N(0,(αr)-1I)
(c) 对每个视图:d=1,2,...,D
刻画一个隐向量分配snd~Discrete(θn)
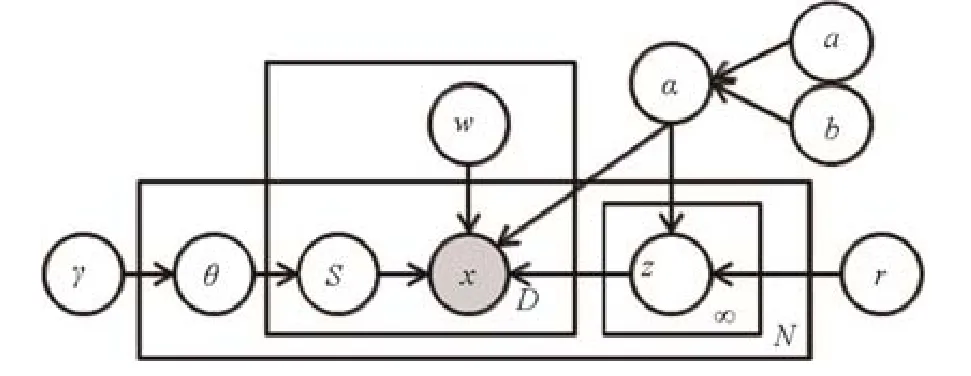
Fig.8 The illustration of MVAD,which aims to detect inconsistent outliers[21]图8 MVAD 框架[21].该方法利用概率隐变量模型检测模态不一致异常点
其中,Stick()γ是折棍子过程(stick-breaking)[36],可以利用参数γ为狄利克雷过程生成混合权重,r是对隐向量表示的关联预测.α共享于观测值和隐向量预测.图8 阴影部分和非阴影部分分别表示观测值和隐变量.整体框架可以看成鲁棒概率典型性相关分析对模态不一致异常点检测的扩展,可运用随机EM 算法进行贝叶斯推断.
3.2.2 DRUMN
文献[37]基于迭代训练错误率提出一种鲁棒无监督多模态深度网络DRUMN(deep robust unsupervised multi-modal network).传统的基于模态权重检测多模态异常点的方法存在两个弊端:(1) 检测阈值需预先设定且固定不变,不能随学习过程自适应调节;(2) 考虑模态两两配对检测,阈值随模态个数的增多而呈指数增长.为了解决上述问题,DRUMN 考虑自适应地为各模态样本及模态对加权.其首先采用能量模型RBM(restricted Boltzmann machine)[38]作为特征学习网络.具体表示为
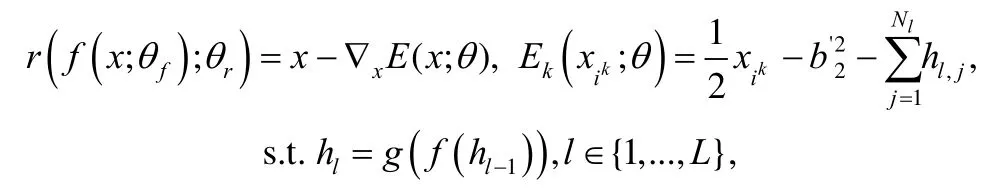
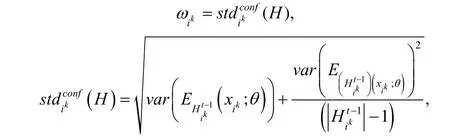
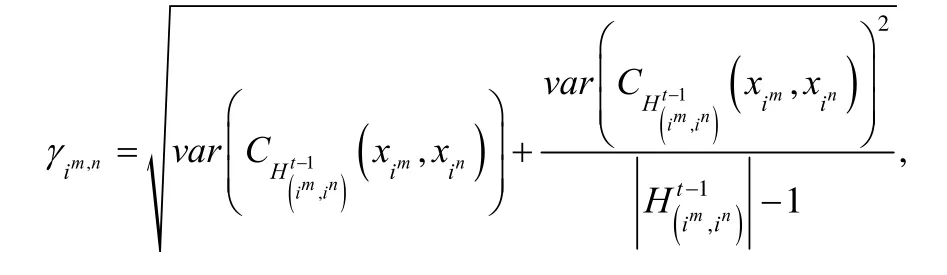
其中,C()· 表示互信息函数,且模态不一致样本较大.最终的优化函数表示为
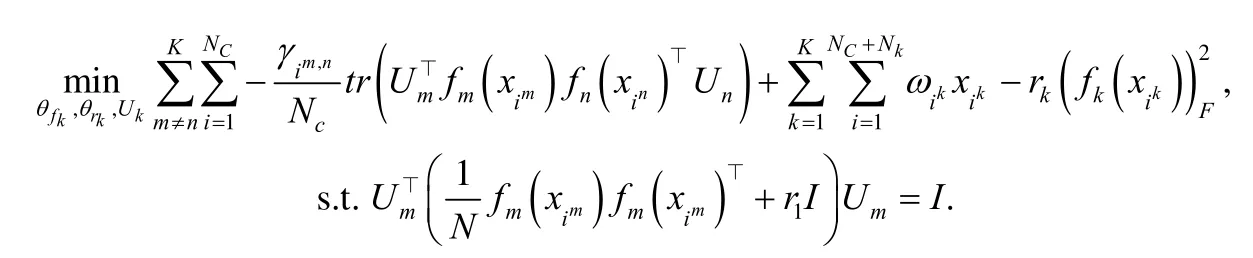
总体上,DRUMN 利用各模态的自编码(auto-encoder)网络结构处理模态缺失样本,同时用能量模型自适应地估计样本权重处理模态不一致的样本,进而减小多模态异常点对训练带来的干扰.
3.2.3 ICo-training
针对强弱模态辅助学习,文献[16]证明,模态不充分条件下,Co-training 适用的理论分析:两个模态预测置信度的差异性较大,Co-training 在模态信息不充分的条件下仍然能够通过利用无标记数据提升学习器性能,并提出一种基于大间隔算法ICo-training.
Step 1.无放回地从无标记数据U构造大小为u的数据池U';
Step 2.分别运用两个模态X1和X2的有标记数据训练两个学习器h1和h2;
Step 3.每个模态用训练好的学习器在U'中本模态无标记样本中挑选p个最置信的正例和n个最置信的负例,挑选最置信的样本需要预测概率大于设定的阈值;
Step 4.标上伪标记加到L中重训练.
不难发现,随着学习器性能的变化,设定的阈值也应发生变化.为此,文献[16]进一步提出了基于迭代间隔的ICo-training 算法,迭代的阈值表示为
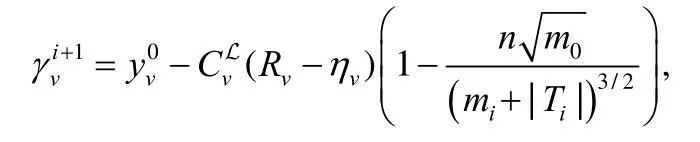
3.2.4 ARM
但上述方法仍需手动设定阈值参数来挑选样本.为此,文献[20]提出了ARM(auxiliary regularized machine)方法,旨在训练阶段利用强模态学习器辅助弱模态进行有效的特征抽取.ARM 利用先验知识,将模态分为强模态和弱模态两个模态,并分别建立学习器,同时利用强模态的预测和弱模态的邻接矩阵构造流形正则项,起到强模态辅助弱模态的作用.ARM 模型表示如下:
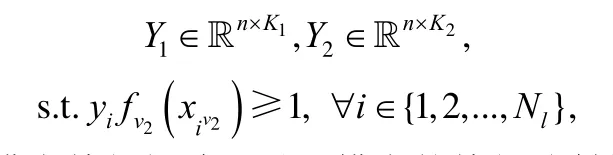
3.2.5 RMVC
在模态不充分场景下,传统多模态聚类会产生性能退化现象.为此,文献[40]提出了可靠多模态聚类方法RMVC(reliable multi-view clustering),自适应地为不同候选聚类结果学习相应的权重,并最大化最优单模态在最坏聚类设定下的信息增益,以此提高多模态集成聚类的性能.该方法先提出χ2距离,度量不同聚类指示矩阵(K1和K2可不相等)的差异:
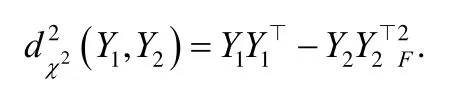
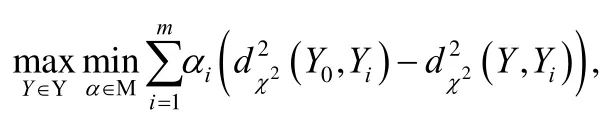
其中,α服从单纯型,为待优化的潜在聚类结果.是预先获得的单模态聚类结果,Yi是运行m个多模态聚类算法获得的m个聚类结果.Y0等价于所有单模态聚类结果中最优的聚类结果.分开看,这一项可确定每种多模态聚类效果的权重αi.而最大化-相当于对m个多模态聚类的集成学习,可以看出,最终的聚类结果与Yi密切相关,文献[40]证明了如下结论:若最优聚类结果属于Yi,那么优化得到的聚类结果肯定优于单模态的聚类结果.
3.2.6 CMML
针对分类任务,文献[41]提出了半监督多模态学习方法CMML(comprehensive multi-modal learning),其利用注意力机制自适应地为每个样本的不同模态学习相应的权重,并提出差异性度量和鲁棒一致性度量来体现模态间的互补性,并进行自适应加权融合.充分性度量表示为
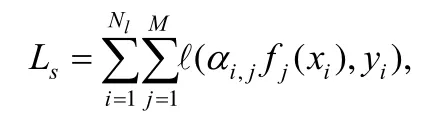
其中,fj(·)是每个模态的学习器,这里表示为深度网络,表示第i个样本的第j个模态的权重,h(·)是额外的注意力神经网络,如两层浅层全连接网络.
差异性度量可表示为
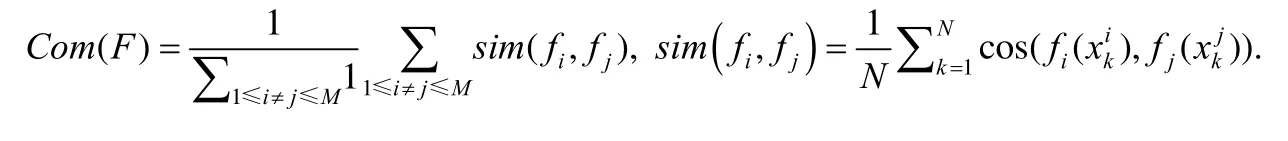
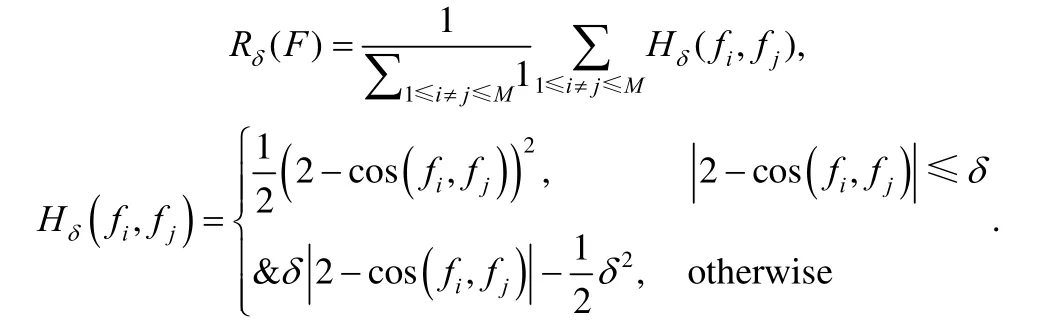
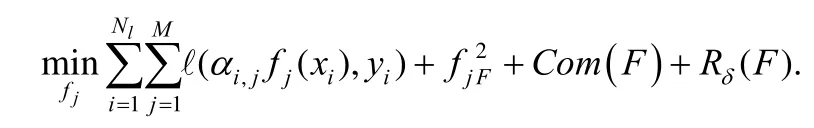
该方法借用图像、文本领域常用的注意力机制,自适应地为每个模态学习相应的权重进行加权融合,从而有效缓解模态不均衡带来的弱相关问题.
3.3 针对对齐关联不一致的方法
3.3.1 PVC
在模态缺失情况下,若直接应用现有的多模态方法,则必须丢弃模态缺失的样本或先补全缺失模态特征,这会丢失有效信息或引入额外噪声.为此,文献[17]提出了PVC(partial view clustering)方法对模态缺失样本进行聚类.不同于传统多模态方法优化投影矩阵将不同模态投影到同维度子空间表示,PVC 基于字典学习将子空间表示也作为优化变量投影回各模态的原始表示空间,再利用优化得到的子空间表示进行聚类:
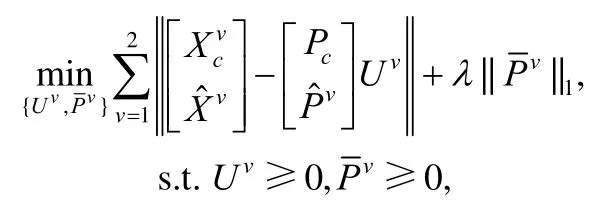
3.3.2 SLIM
考虑利用对齐的无缺失模态样本信息辅助缺失模态进行学习,文献[43]提出半监督多模态学习方法SLIM(semi-supervised learning with incomplete modalities).SLIM 有效地利用数据预测的潜在一致性,利用预测概率补全各模态的相似性矩阵,从而在统一的框架中为每个模态学习单独的学习器和所有未标记样本的聚类学习器,进而可以同时进行分类和聚类任务:
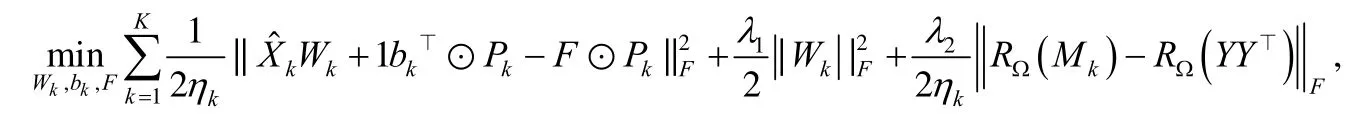
kb∈R是当前预测的偏差,1 是一个全1 向量,⊙表示对应元素的点乘算子,是指示矩阵,其中,表示第i个示例的第k个模态上完整,否则,在多类情况下,xi的标签yi扩展为一个C维的向量,其中,表示第i个示例为第j个标签,否则,类似地,F∈RN×C表示所有示例的预测标记,ηk是第k个模态的完整样本的个数.Mk∈RN×N是第k个模态的相似度矩阵.表示第i个样本和第j个样本的第k个模态完整,否则为0.其中,第3 项进一步采用平方根损失函数代替方程中的最小二乘函数,减少了噪音数据的影响.亦即,此项等价于一个加权正则化的最小二乘形式,其中,每个模态的权重为进而可以通过考虑所有模态的不同噪声水平来校准每个模态.最终,SLIM 利用模态的一致性来补全各模态缺失的相似性矩阵,从而获得潜在一致的预测矩阵F.
3.3.3 DeVise
针对模态对齐关联缺失问题,文献[18]提出一种启发式辅助学习方法 DeVise(deep visual-semantic embedding model).具体地,DeVise 在训练图片模型时随机抽样文本模态的异类样本构造三元组损失函数以辅助图片深度网络训练,利用文本基模型获得的特征嵌入辅助图片缩小类内距离,扩大类间距离.最终可以利用文本模态样本增广训练数据,从而减少图片训练样本的数量.具体公式如下:
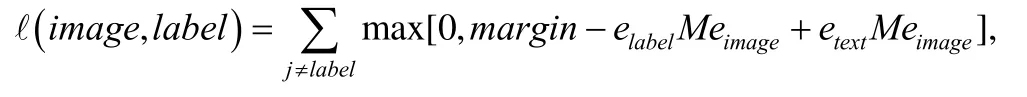
其中,margin是人为定义的距离参数,elabel是标记的语义表示,eimage是图片的特征嵌入表示,M是映射矩阵,etext是文本模态的特征表示.值得注意的是,该方法无需模态间的对齐关联,仅利用标记一致性进行样本挑选,适用于分类等任务,而针对面向模态样本对齐的跨模态检索等任务则效果甚微.
3.3.4 SCML
针对模态对齐关联缺失下的跨模态检索问题,文献[44]提出SCML(sequential cross-modal learning),该方法基于共享预测模型的序列化训练方式进行多模态模型联合训练,进而利用共享模型挖掘跨模态潜在一致的特征表示.
如图9 所示,该方法基于共享预测模型进行序列化训练,通过保证共享模型性能不下降而获得模态间潜在一致的特征嵌入.SCML 首先训练单模态模型P1(S)和共享模型S,再固定共享模型S 训练单模态模型P2,此步固定S 旨在防止S 对P1 学到知识的遗忘.而后,仅利用少量的P1 和P2 数据训练元学习器M,这一步是为了利用元学习器更新共享S,进一步获得潜在一致的语义表示.值得注意的是,SCML 训练共享模型使得各模态预测性能不下降这一思路,以此获得跨模态潜在一致的映射关联,但这并不是样本级别的映射关联,因此该方法在NDCG 指标中性能较好,而在Rank 指标中性能较差.
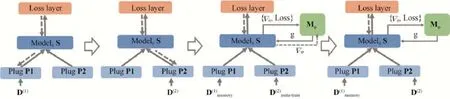
Fig.9 The illustration of SCML[44]图9 SCML 框架[44]
3.4 讨 论
本节主要介绍了针对不均衡多模态数据所提出的可靠多模态学习方法.考虑模态表示强弱不一致的方法主要思考如何有效度量模态的不一致性,并考虑利用性能优异的模态进行辅助学习.而考虑模态对齐关联不一致的方法主要考虑如何缓解模态缺失的影响,补齐模态缺失数据.而面向关联缺失的方法主要思考如何学习并利用模态间潜在一致的关联性,如标记关联.但目前仍有诸多挑战有待解决:(1) 模态不充分性度量[45].目前,强弱模态是靠训练数据的性能或者先验知识来确定,且绝大多数方法局限于两模态.如何更有效地界定模态的不充分性,并度量更细粒度的样本级别的模态不充分性还有待研究;(2) 模态缺失数据处理.目前,对于模态缺失问题的处理实质上是对样本缺失模态仅作为单模态来处理,如何利用样本无缺失的模态对缺失的模态进行有效操作还有待研究;(3) 非平行多模态学习.目前,针对模态关联缺失的方法大多为启发式方法,如何有效地扩展为仅利用少量对齐数据进行对齐标签传播还有待研究.
4 结束语
多模态学习近些年受到广泛关注并拥有诸多实际应用.传统多模态学习方法面向真实不均衡多模态数据会出现性能退化甚至低于单模态性能,这通常归结于模态表示强弱的不一致和模态对齐关联的不一致问题.为此,可靠多模态学习被提了出来,针对上述两个挑战的可靠多模态学习体现较之传统多模态学习具有更优异的性能.未来,我们认为还存在如下几方面的挑战:(1) 针对表示不一致的可解释性研究.目前的方法大多局限于基于各模态最终的特征嵌入进行不一致的度量及后续处理,缺乏考虑导致模态间不一致的因素,如局部区域信息的不一致性.如何利用多示例学习细粒度刻画各模态样本,并结合诸如图模型解释模态不一致具有巨大的研究前景和广阔的应用价值;(2) 针对关联不一致的隐关联学习.目前的方法大多还是启发式方法,在模态对齐映射学习过程中可能引入额外的噪声,如何利用少量的对齐模态数据初始化模态间的映射函数,并利用非平行数据结合对偶学习或循环生成网络进一步加以训练值得研究;(3) 动态环境下的多模态学习.当前多模态学习大多是静态的,即给定训练集训练模型并在测试集中加以验证,而现实环境是动态变化的,流式数据具有分布变化、特征增广、新类检测等问题,如何将现有的多模态学习扩展到动态环境下值得研究.
