基于3D双流卷积神经网络的异常行为检测①
2021-05-21刘良鑫林勉芬钟良泉彭雯雯潘家辉
刘良鑫,林勉芬,钟良泉,彭雯雯,曲 超,潘家辉
(华南师范大学 软件学院,佛山 528225)
1 背景及现状分析
1.1 研究背景
随着人工智能和图像处理技术的快速发展,基于深度学习的智能视频监控系统研究具有重要意义.近年来,在国家政策的支持下,安防行业飞速发展,政府、企业、机关、城市、社区都在配合国家的安全工作进行相关的部署,努力打造一个智慧和安全的国家.随着科技的发展,智能监控技术也在不断地进步,而目前的监控任务主要还是依靠人工实现,需要大量的人力、物力对海量的视频内容进行观看和分析.不能有效地利用现有的资源.所以为了解决这个困难,本项目的研究内容就是实现对视频中异常行为的自动筛选和实时检测.
1.2 国内外研究现状
1.2.1 智能视频监控系统研究现状
智能视频监控系统是通过计算机视觉技术、图像视频处理技术和人工智能的识别技术对监控视频的内容进行分析,然后根据分析的结果对系统进行控制.
在国外,美国国防高级研究(DARPA)设立了一个视觉监控重大研究项目VSAM.该项目从1997年就开始设立了,由卡内基梅隆大学(CMU)、麻省理工学院(MIT)还有马里兰大学等著名高校和研究机构参与研究.VSAM 项目可以说是最早的视频监控的智能化的开端,主要研究用于战场、未来城市和普通民用场景进行监控的自动视频理解技术.
美国的Microsoft、GE、IBM 等公司也对智能监控系统进行了研究,如GE的VideoIQ 产品,可以在多种场景下进行检测.而国内在这方面发展较晚,但也有比较优秀的成果,如中科院北京自动化研究所下的模式识别国家重点实验室,主要研究模式识别、计算机视觉、图像处理与图形学、自然语言处理以及模式识别应用与系统等.其中谭铁牛研究员领衔的科研团队开发了可对突发事件进行全天候实时监控预警的“智能视频监控系统”,而且成功应用于北京奥运会安保工作.除此之外该研究所还有其他的研究成果,包括:目标异常行为的识别与报警、异常的物体滞留或丢失检测、人群流量评估及拥堵报警、监控状态下的人脸跟踪与识别等.
1.2.2 异常行为检测研究现状
在异常行为检测技术出现的早期,Datta 等提出利用人的运动和肢体定位来检测人的暴力行为[1],Kooij等使用视频和音频数据来检测监控视频中的攻击行为[2],Cao 等提出了暴力流描述符来检测人群视频中的暴力行为[3],但这几种方法都有较大的检测误差.最近,Mohammadi 等提出了一种新的基于行为启发法的方法来对暴力和非暴力视频进行分类.除了暴力和非暴力模式的区别外,还提出使用跟踪来对人们的正常运动进行建模,并将偏离正常运动的行为作为异常进行检测[4].以及Chen 等提出的利用C3D和深度排名模型进行的异常行为识别[5].
但是,上述方法只是能对某种特定的异常行为进行检测,例如Cao 等提出OpenPose 模型[3]只能识别人体异常行为,而无法对爆炸,车祸等异常行为进行识别.因此本文打算对一种可以在多种视频环境下对多种行为进行异常检测,且在检测过程中能保持较大的精确度和较好的实时性的系统进行研究.
2 系统总体设计
2.1 系统流程介绍
本系统主要实现对视频中异常行为的检测功能.本系统的功能介绍如下:打开本软件后,选择本地存储的视频,确认后即可立即检测.检测过程中,系统一边播放视频,一边显示异常概率曲线.随着视频的播放,异常概率曲线会不断的更新跳跃,其范围值从0 到1,值越大代表该时间段的发生异常概率行为的可能性越大.系统功能流程图如图1所示.

图1 系统功能流程图
为了实现异常行为识别算法,将异常行为与正常行为的进行区分是一个不可避免的环节.有效的,精准的异常识别处理能将一段原始视频对象提取出视频行为特征.能够精确分析视频行为特征并给出异常行为概率估计能够使得异常行为识别更具准确性和科学性.
2.2 系统模块功能介绍
异常行为识别系统模块主要分为5 个子模块,如图2所示.

图2 系统模块
(1)预处理模块
通过本地视频库或者视频流获取待检测视频,将每个视频的大小调整为240×320 像素,并把视频的帧数率降低并固定到30 帧/s.
(2)特征提取模块
视频经过预处理后,我们通过Two-Stream-I3D 网络提取视频特征,输出为fc6-1的文件类型.首先我们将对处理过的视频进行截取,每16 帧作为视频片段.接着,我们从Two-Stream-I3D 网络对视频片段进行提取,然后进行归一化处理.
(3)特征处理模块
这一模块,运用Python,处理上一步输出的fc6-1 文件,处理为深度网络所能学习的二维矩阵txt 文件.
(4)特征概率回归模块
这一模块,将上一步所生成的经过处理的视觉特征txt 文件,送入训练好的深度网络模型(GRNN),搭配上已经训练好的模型权重,通过模型处理对视觉特征文件进行回归处理,得到异常概率分数,范围从0 到1(值越大代表发生异常概率的可能性越高).
(5)视频播放及概率曲线显示模块
通过GUI 文件,将视频片段的异常概率得分通过红色曲线显示出来,同时播放视频.随着视频的播放,曲线不断的跳跃更新,不断向前滑动,最左端的曲线值代表此时的视频的异常概率值,最终达到异常行为识别的效果.
3 异常行为识别算法实现
3.1 I3D 模型的原理与实现
I3D 模型[6-8]是由Inception-V1(2D)模型改良而来,其基础模型结构为InflatedInception-V1.
Inception-V1(2D)是一种目前较为成熟的图片检测模型,其初代模型Inception的核心就是把GoogLeNet的一部分较大的卷积层替换成小卷积,以达到减小权值参数数量的目的,而Inception-V1(2D)又对Inception模型的子程序模块Inc.层进行改良,添加了3 个1×1的卷积层从而降低原模块的卷积维度.
I3D 模型对Inception-V1(2D)模型改良方法如下:I3D 网络将原模型的2D 基础卷积扩展为3D 基础卷积,并且在卷积核中增加时间维度,具体扩展方式为:沿着时间维度重复2D 滤波器与其的权重相同的次数,再通过除以该次数进行归一化处理.
InflatedInception-V1的主要的组成成分为卷积层、池化层和Inc 层.
在卷积层中,3D 卷积相比于2D 卷积能够更好的捕捉视频中的空间和时间信息,如果3D 卷积的时间维度为N,在检测过程中,3D Conv 会对视频的连续N帧图像进行卷积操作,每一帧的特征地图都会与相邻的连续几帧相连,以此获取运动信息.
在池化层中,3D 池化层类似于3D 卷积,只不过不做卷积操作,只获取当前窗口最大值或者平均值作为新的图像的像素值.然后在深度上以步长进行滑动,得到多个特征地图.
在Inc 层中,Inc 层为Inflated Inception-V1 模型的一个子程序模块,在Inc 中,同时使用了1×1×1,3×3×3的卷积,增加了网络对尺度的适应性.其次,1×1×1 卷积有着特殊的作用,它可以用于减小权重的大小和特征地图的维度,同时由于1×1×1 卷积只有一个参数,相当于对原始特征值做了一个scale,这无疑会对识别精度有所提升,如图3.

图3 Inc 层模型
在模型的最后还含有一个Softmax 层对输出进行分类.整个模型的架构图如图4.

图4 I3D 模型
在异常行为识别方面,基于深度学习的网络模型无论在识别速度,识别精度还是系统的鲁棒性都要远远优于传统方法.而在深度学习方法的选择上,过去人们大多使用C3D 及其改进的方法来对视频进行处理,但是由于C3D 其较为简单的网络模型,往往不能对视频中的时空特征进深度处理,当遇到较复杂的情况时,传统的3 维卷积神经网络就容易遗漏部分运动特征,从而对检测结果造成影响.因此,我们采用双流的I3D网络作为我们系统的特征提取模型,从而应变各种较为复杂的情况.
3.2 GRNN 回归神经网络模型原理
广义回归神经网络(GRNN)[9,10]是径向基神经网络的一种,相较于传统的回归神经网络,GRNN 多添加了一层求和层,并去掉了隐含层与输出层的权值连接(对高斯权值的最小二乘叠加),具有更高的精确度,同时GRNN 作为一个前向传播神经网络,不需要反向传播求模型参数,收敛速度快.GRNN 具有很强的非线性学习能力和学习速度,网络最后普收敛于样本量聚集较多的优化回归,当样本数据较少时或数据精确度较差时,GRNN 能发挥出很大的优势.
GRNN是一个相对简单的4 层网络结构,分别为输入层、模式层、求和层和输出层.如图5.

图5 GRNN 模型
输入层的输入为测试样本,节点取决于样本的特征维度;模式层计算每一个样本中的Gauss 函数取值,其节点个数为训练样本的个数求和层中使用两种计算方式,第一个节点将对模式层的输出进行算术求和,其他节点将对模式层的神经元进行加权求和,其节点数为输出样本的维度加1;输出层的节点数等于样本中输出向量的维度,输出为对应求和与求和层第一个节点的输出相除.
求和层第一类求和公式:

求和层第二类求和公式:

3.3 基于I3D-GRNN的异常行为识别算法实现
从总体上看:本文提出的算法主要有两部分组成:I3D 特征提取器+GRNN 分类器.
首先,视频信息可以分为空间信息和时间信息.空间信息指的是帧画面的表面信息;时间信息指的是帧与帧的之间的联系.对于I3D 来说,时间维度需要设定一个适中的缩减速度,过快则可能把不同物体的边缘信息混杂在一起,反之将无法捕捉到动态场景.因此:Two-Stream-I3D是由两个I3D 网络组成的.第一个子网络是提取视频的RGB的特征.第二个子网络是提取光流的特征.虽然单个I3D 模型已经具备从RGB 流中提取运动特征的功能,但单个模型只包含前馈计算算法,因此我们将两个I3D 网络分开训练,一个对RGB 流进行训练,输入为间隔16 帧提取的RGB 视频帧信息;另一个对光流进行训练,我们分别提取视频中水平和垂直方向的光流帧,将多幅光流图构成一个光流组,然后将携带优化的光流信息的光流组作为输入,同时我们在第二个I3D 模型中采用TV-L1 算法对光流进行计算,该算法作为一个递归型算法,其对视频中运动特征的提取效率优于单个模型.
在经过几层卷积和汇集后,将训练RGB 流子网所提取的特征和与训练光流子网所得的特征进行融合,具体的融合方法为:对两个子网的输出进行加权平均.融合后将得到进一步的视觉特征.为了避免过度拟合,我们在每个卷积层上添加L2 正则化.如图6.
其次,我们将 Two-Stream-I3D 模型的Softmax 分类层用GRNN 分类器代替(如图7),将Two-Stream-I3D 网络提取出的特征作为GRNN 分类器的输入,最终达到对视觉特征进行一个概率回归的作用.
最后,关于优化函数,训练模型采用AdaGrad[11,12]随机梯度下降函数作为模型优化函数.AdaGrad 相较于其他优化函数,它可以自适应学习率,自适应地为各个参数分配不同学习率.如果这次梯度大,那么学习速率衰减的就快一些;如果这次梯度小,那么学习速率衰减的就慢一些.

图6 Two-Stream-I3D 模型

图7 I3D-GRNN 模型结构
4 实验和结果
4.1 实验数据
本项目训练采用的数据集为UCF-Crime-dataset[13].该数据集是由佛罗里达大学开发的,是一个总时长为128 个小时且由1900 个时长相等未经剪辑的真实世界监控录像组成的视频集合,其中包含13 个现实世界中的反常现象,如:打斗、交通事故、盗窃、爆炸、抢劫等,同时还包含正常的活动,视频集大致可分为包含异常行为的视频和不包含异常行为的视频两大类.其中视频平均的帧数为7274 帧.
4.2 实验步骤
本次实验环境为Ubuntu18.04和Python3,编译环境为PyCharm,硬件环境的测试机型是戴尔G3 系列.CPU是英特尔酷睿i7 8 代系列;内存是8 GB;硬盘是2 TB.
测试实验分别以包含异常行为的视频,无异常行为的视频,隐蔽异常行为的视频,失真度较高的视频等不同类别的视频为样本,每类视频对应不同的情况和不同的视频质量,每个视频都包含不同的场景,共50例进行了测试
点击运行程序进入主界面如图8(b),界面中央有一个选择视频的按钮,点击按钮弹出一个视频文件选择的对话框,选择一个需要进行检测的视频.左方就会出现一个视频窗口演示所选择的视频如图8(a).在播放视频的过程中,控制台会实时提示所显示的帧数.在左方出现视频窗口的同时,系统会对视频中每一帧的画面进行训练学习,提取出特征,然后在PyCharm的SciView 里将计算出来的数据在坐标轴上描绘出一条连续的曲线如图8(c).横坐标是帧数,纵坐标是训练出来的特征数据,范围是0 到1.当视频中没有异常行为出现的时候,曲线的纵坐标接近于0;当视频中出现异常行为的时候,曲线将会有很大的浮动.

图8 异常行为检测系统
4.3 实验结果
经过上一步的实验测试,我们选取了具有代表性的视频样例进行分析,具体试验情况如下:
(1)对包含异常行为的视频检测:如图9所示,上方播放的是一个爆炸视频,下方则是系统对该视频的检测结果.实验结果分析,横坐标是帧数,纵坐标是训练出来的特征数据,范围是0 到1.如图所示,当没有发生异常行为时,预测曲线纵坐标无限趋近于零且几乎没有变化,当异常行为发生时,曲线则会发生大幅度的向上变化,纵坐标上升至0.7 上下,甚至在最高峰可以达到1.
(2)对无异常行为的视频检测:图10为对无异常行为的视频的检测结果.实验分析,由于此次视频画面无异常行为的发生,预测曲线纵坐标一直处于10-9上下.将纵坐标放大演示后,曲线也发生了上下变动,实际在原坐标中曲线只是出现了小幅度的波动.

图9 对包含异常行为的视频检测

图10 对无异常行为的视频检测
(3)对隐蔽异常行为的视频检测:图11为视频中演示的是一名女性在超市中盗窃水杯的场景,作案动作幅度较小,画面没有发生大幅变化.实验结果分析,即便此异常行为较为隐蔽,系统仍然检测出了该异常行为.当异常行为发生时,预测曲线出现了大幅跳跃,纵坐标一度达到了0.8 以上.

图11 对隐蔽异常行为的视频检测
(4)对失真度较高的视频检测:图12为系统检测失真度较高且包含异常行为的视频的结果.视频中演示的是较远处发生爆炸的画面,视频没有发生较大幅度的画面变化,只在画面左上方出现了爆炸的浓烟.实验结果分析,当视频失真度较高时,系统依旧能检测出异常行为的发生,即使纵坐标只能达到0.4 便出现了下降的趋势.
实通过上述实验结果可以看出经过近50 例的测试集视频的测试,发现系统能较为正常高效运行.异常行为发生时的预测值与无异常行为时相差最高可为0.9 以上,最低也能达到0.3 以上,远远大于无异常行为时的数值波动,可以明确的检测出异常行为的发生.

图12 对失真度较高的视频检测
由表1数据可得出,通过4 种类型的视频进行测试,对无异常行为类型视频识别准确率最高达到80%.对包含隐蔽异常行为的视频类型识别率最低,只有55.6%.在实际测试发现,系统常常把含隐蔽异常行为的视频当作无异常行为进行识别.最后系统测试的平均准确率达74%,具有较精准的识别功能.
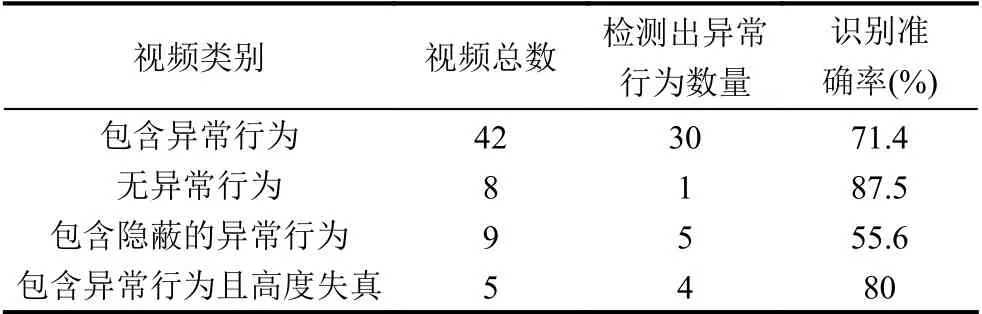
表1 视频类别数据量与识别准确率
为了验证本文算法验证本文算法的优越性,选用支持向量机[14]、随机森林[15],C3D-GRNN[16]、KNN 以及普通 C3D 模型这5 种方法对异常行为视频进行分类识别,识别所耗时间分别如表2所示.由表2的结果可知,与普通 C3D 模型、C3D-GRNN 模型等典型方法相比,本文算法识别单个样本帧效率具有较大的提高,同时也十分接近目前较优的算法(SVM、KNN)的检测时间.
5 结束语
本文利用目前火热的深度学习网络技术和Two-Stream-I3D 技术,开发出一款智能识别视频异常行为的系统,能够有效帮助监控机构智能化监控,减少人工资源的浪费.
本文利用Two-Stream-I3D 特征提取技术提取出视频特征,经过Python 处理视觉特征后,进行GRNN回归网络训练,最终达到根据视觉特征能进行概率估计回归的一个效果.最后,经过一定数量测试集视频测试,证明本文所述方法编写的系统具备了对视频监控中异常行为的检测能力,可以满足多种异常行为的检测,可以在多种视频环境下进行异常行为检测,且在检测过程中能保持较大的精确度和较好的实时性,对于监控机构进行智能化监控具有重要的现实意义.

表2 视频类别数据量与识别准确率
