基于多维度特征分析的KPI异常检测
2021-05-20曹志英张秀国
曹志英,曹 伟,张秀国
(大连海事大学 信息科学技术学院,辽宁 大连 116026)
0 引 言
KPI异常检测有着其特殊性[1]。现有的方法缺乏一定的普适性,在不同类型的KPI序列中异常检测的效果差别很大。基于统计的异常检测方法的缺点在于事先需要知晓数据分布[2];基于距离的异常检测方法的局限性是复杂度高,难以兼顾数据集的维度和可扩展性,且难以检测出数据集中存在多种分布的异常情形[3,4];基于密度的异常检测方法虽然能较好地检测出局部异常点,但是异常因子阈值等参数对模型影响很大,缺乏简单有效的参数确定方法[5]。文献[6]提出的基于核密度估计的聚类方法没有考虑数据的前后时间关联。Zhang等[7]提出一种基于BP神经网络的异常检测方法,该方法将挖掘的6个局部特征作为神经网络的输入,通过神经网络的输出来进行KPI的异常检测,但是该方法对样本数据的平衡性较敏感。文献[8,9]针对周期型KPI进行分解,然后根据指定的异常指标对分解的序列进行计算,从而判断出当前KPI是否异常;文献[10]通过“时间窗口”与平滑预测技术分析时序数据,能够消除异常数据出现的随机波动性,反映出序列的整体规律性,然而此类方法比较适用于稳定类型的时序数据;Hu等[11]提出基于元特征的方法,该方法能够较好地捕捉单元时间序列和多元时间序列的异常,然而异常检测的准确度还不够高。
对此,本文提出一种基于多维度特征分析的异常检测方法,该方法能有效地在未知数据集分布的情形下挖掘出数据的局部特征和总体特征,适应多种类型的KPI数据,具有较好的普适性。
1 基于PCA和小波分析的特征提取及修正
根据文献[12]的定义,KPI数据是(timestamp,va-lue)的时间序列集合,其具体格式见表1,设为Q={q1,q2,…,qn}。在进行KPI异常检测时,首先需要进行特征提取,良好的特征有利于异常检测模型逼近异常值检测的上限。由于KPI随时间会呈现出稳定型、波动型和周期型的变化,不同类型的序列隐含的特征类型与特征数目也不同,因此特征提取的方法不能单一。对于特征提取,本文首先对Q归一化得到数据V,然后为保证提取的特征能够涵盖序列局部与整体变化的细节,再对V进行多维度的特征提取生成特征集A;进而使用主成分分析对A降维得到特征集B,以避免一些无关项的干扰;最后基于小波能很好地处理B中的非线性数据,本文使用小波对B进行特征修正,最终得到特征集C。

表1 KPI数据示例
1.1 特征定义
归一化使不同量级的数据转化为同一种量级,保证数据间的可比性。本文采用的归一化方式为z-score标准化。若Q的均值为μ,标准差为σ,则z-score标准化公式具体如下
(1)
数据预处理完,然后进一步挖掘出KPI数据不同类别的特征,本文主要挖掘KPI数据的原始特征、统计特征和拟合特征。原始特征为归一化后的数据。统计特征主要描述数据间的离散程度和变化趋势,有别于文献[7]定义的6个统计特征,本文使用一阶差分、占据比和凹凸性3个统计特征。拟合特征基于“滑动窗口”,考虑到序列整体间的前后关联,弥补了对单个数据点考虑的缺陷。根据文献[12],拟合特征主要有变异系数、峰态系数、移动平均线、差分移动平均线和指数加权移动平均线。
根据文献[12]的定义,归一化后的数据集设为V={v1,v2,…,vi,…,vm},从V中获取滑动窗口为w的数据如式(2)所示
Vw(i)=[vi,vi+1,…,vi+w-1],i=1,2,…,m-w+1
(2)
根据文献[12],原始特征、一阶差分、占据比等特征的具体定义如下
原始特征:fi=vi,i=1,2,…,m
(3)
一阶差分:di=vi+1-vi,i=1,…,m-1
(4)
其中,di为相邻value值之差,描述了相邻数据间的单调性

(5)
其中,ri表示当前的value值与整体序列中最小value值之差占整体最大最小值之差的比例
凹凸性:Si=vi+2-2vi+1+vi,i=1,2,…,m-2
(6)
其中,Si表示连续相邻value值间凹凸性的变化情况
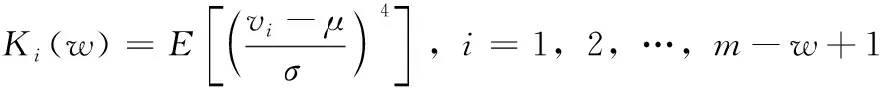
(7)
其中,Ki(w)为时间序列相对于正态分布是重尾还是轻尾,用于检测突然的尖峰或骤降。w表示时间窗,μ为长度为w的滑动窗中的均值
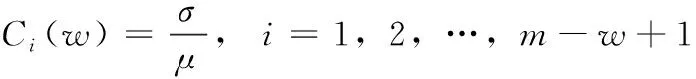
(8)
Ci(w)描述一个时间窗中序列的离散度。w表示时间窗口的大小σ表示滑动窗口的标准差,μ表示滑动窗口的均值

(9)
Gi(w)描述了滑动窗所经过序列的平均值。移动平均线通过削弱时间序列的不规则变化来揭示序列的变化趋势。
差分移动平均线
(10)
Ji(w)从单调性上揭示了数据的变化趋势。它主要通过计算相邻value之间的差分值,然后再求固定时间窗口的移动平均值。
指数加权移动平均线
Ti(w)=λvi-1+(1-λ)Ti-1,i=2,3,…,m-w+1
(11)
Ti(w)反映序列近期变化的趋势,其根据加权下降系数呈指数型迭代,λ表示加权下降的速率。
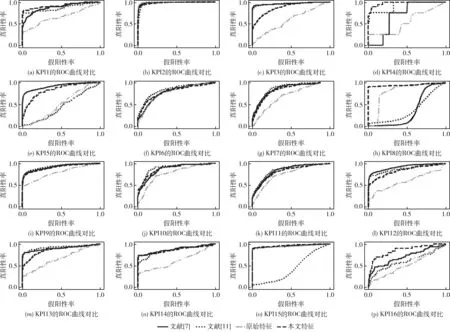
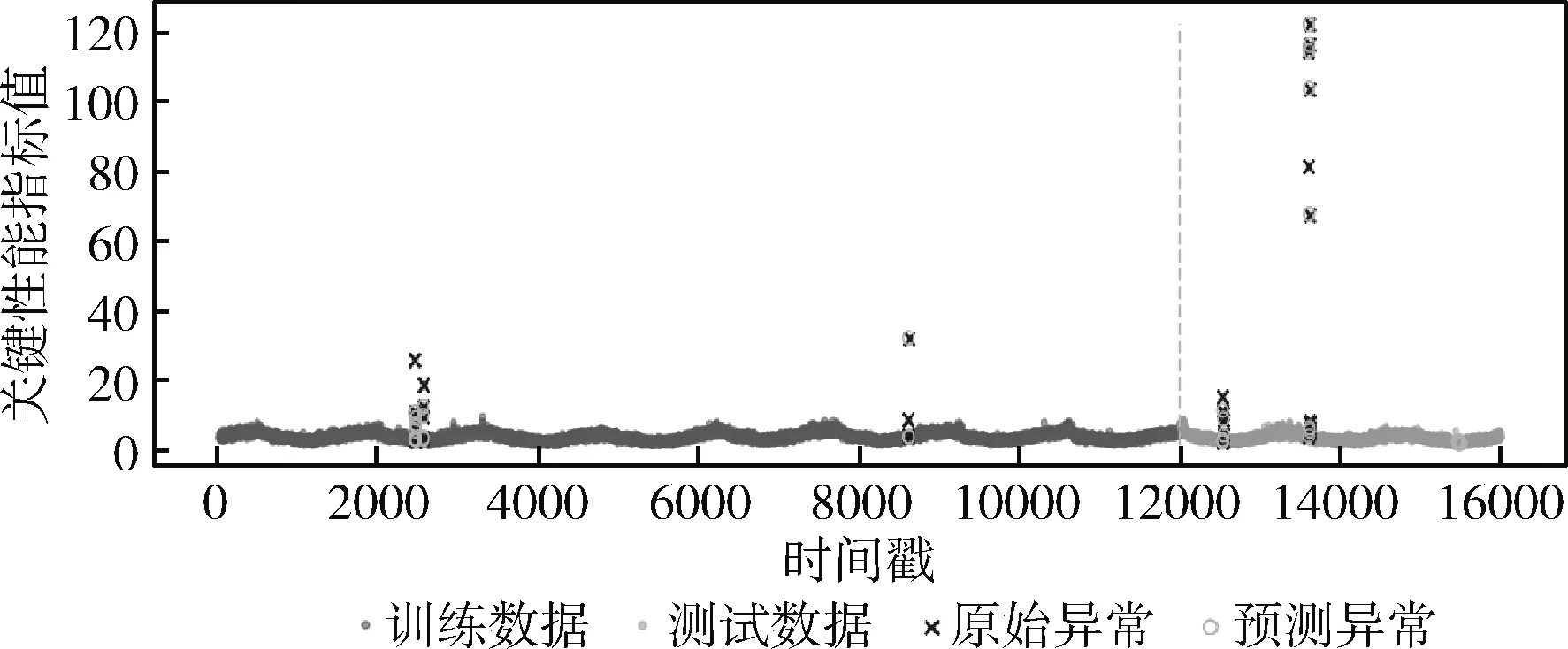
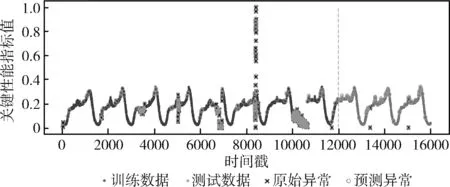
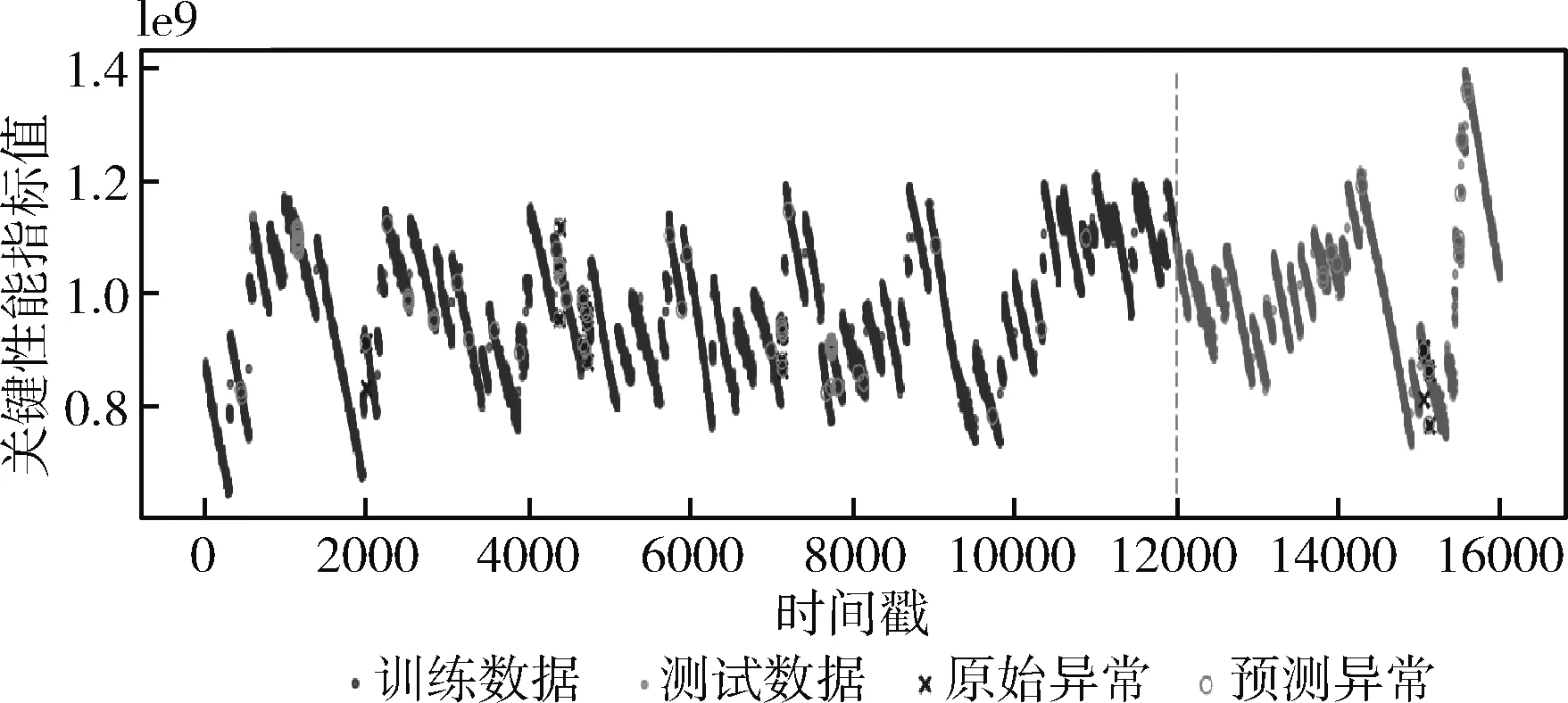
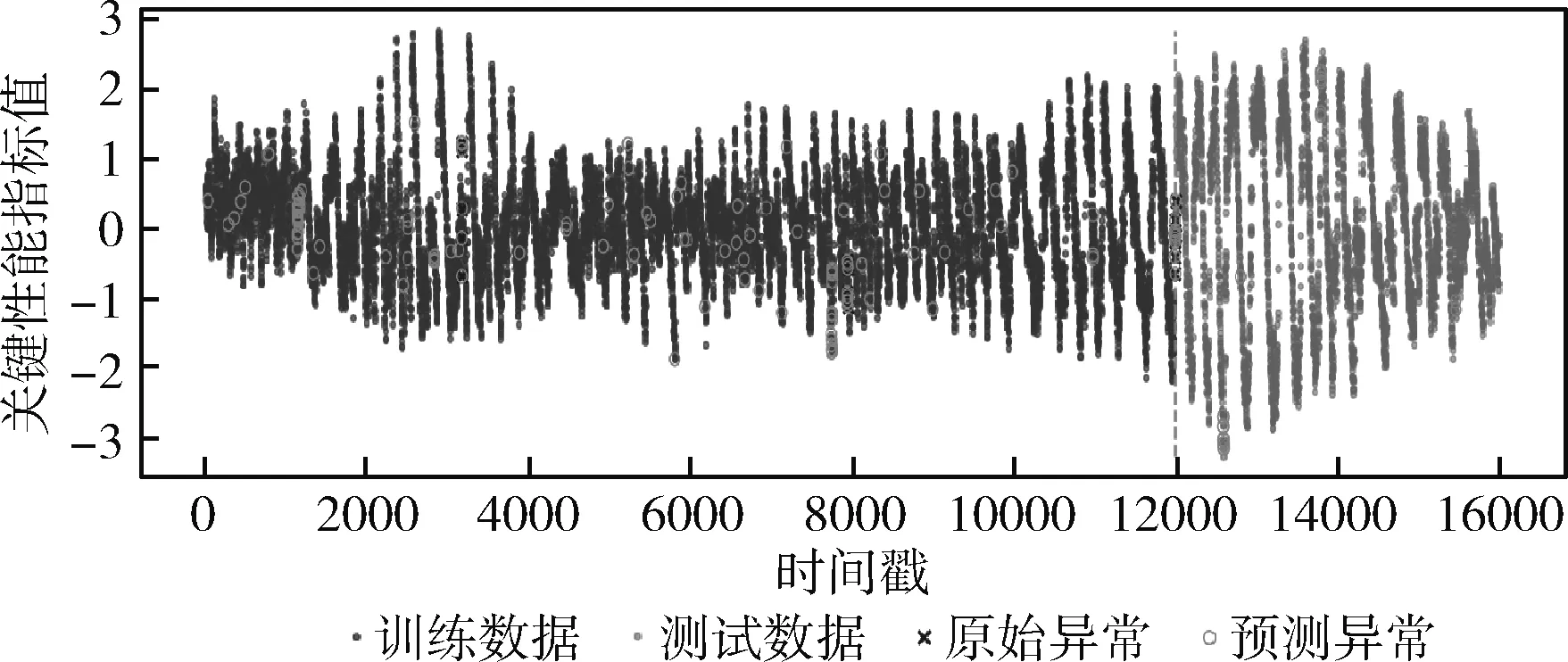
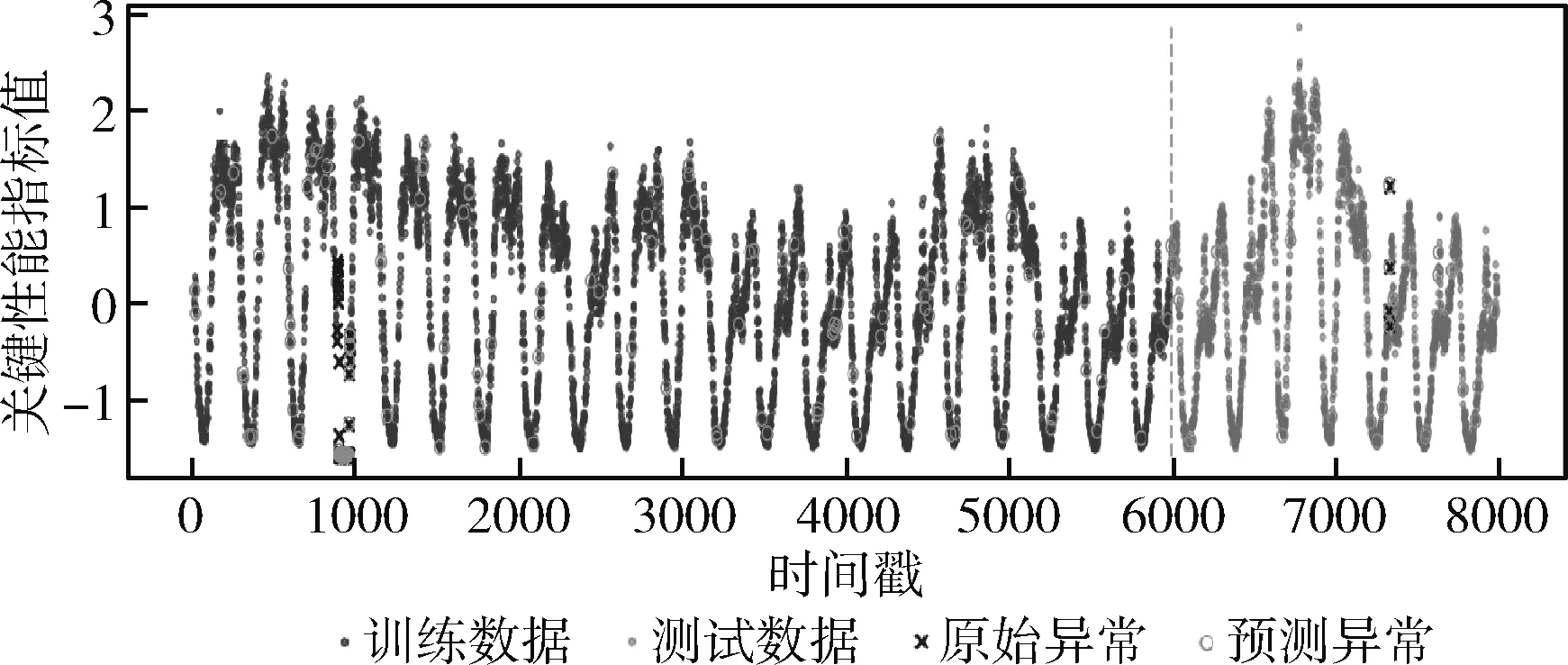
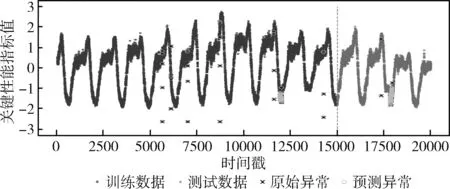
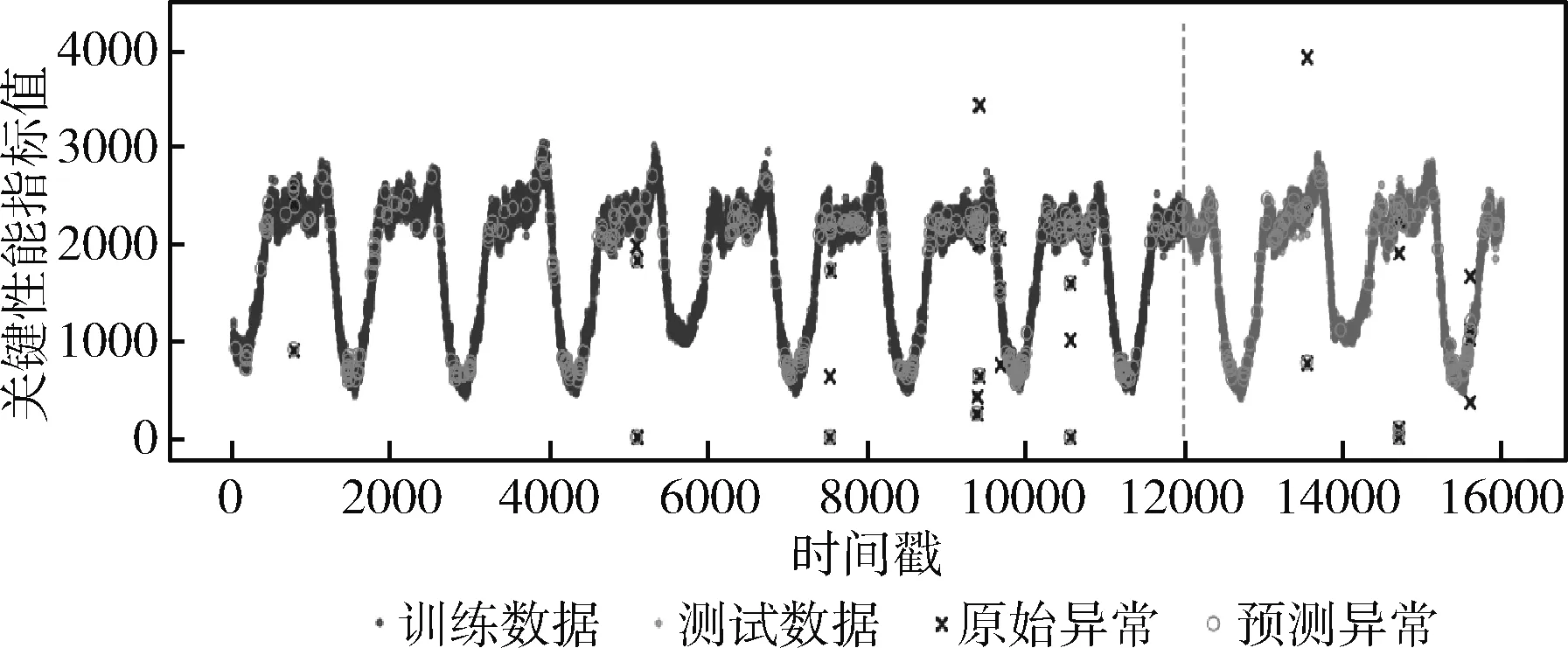
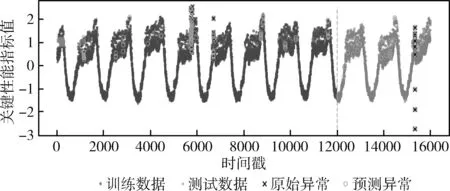
由文献[12]可知,原始特征和统计特征,可根据式(3)~式(6)从数据集中直接计算得到。对于拟合特征,由于窗口的大小会影响提取特征的精度,因此本文通过对滑动窗口的值进行多次设定,计算得到不同大小滑动窗口下的拟合特征。设有n个窗口的取值,滑动窗口的大小w1 得到上述特征后,将上述特征中的特征项组合成A。因为滑动窗口有一定的长度,所以拟合特征中特征项的长度会比原始特征和统计特征中特征项长度小,为保证A纵列长度的一致性,本文将原始特征和统计特征在进行特征项组合时舍去了部分数据。A的具体形式如下 其中,wn为滑动窗口所取的最大尺度,特征集A的大小为(m-wn-1)*(4+5n)。 由于特征集A的维度较高,这可能会影响后续模型异常检测的正确率;同时高维度的数据集消耗的资源较大,不利于模型的训练。PCA因为能够去除数据之间的相关性,所以被广泛用于降维。其主要思想是将高维度空间中的数据投影到低维度空间从而形成主元特征分量达到降维的效果。 根据文献[12]定义,首先对A的每行进行零均值化处理,然后计算A的协方差矩阵,根据协方差矩阵求得A的特征值λi(i=1,2,…,q) 及其对应的单位正交向量pi(i=1,2,…,q),则A的第i个主成分向量为yi=Api(i=1,2,…,q)。将A的特征值由大到小进行排序并定义第i个特征值与各特征值之和的比值为第i个特征值的特征贡献率,选取前r(1≤r≤q)个特征值计算其累加特征贡献率g(λr)。g(λr)定义如下 (12) 上式中,若存在r=R使得g(λR)>ζ,0<ζ<1,则这R个特征向量为A降维后的特征向量。 将这R个特征向量组合成特征集B,如下所示 其中,yR(m-wn-1)表示特征向量yR的第m-wn-1个分量值。 由于降维后的特征属于非平稳特征,具有突变性、随机性的特点,这些特点不易被获取。而小波可以利用其分辨率的特性,通过伸缩与平移,可以对非平稳特征的序列在时域和频域上进行分析。本文通过小波分析将B中的分量yi分解到不同的频率通道上,从而变为频率单一的信号。原始分量yi通过高频滤波器和低频滤波器后被分解成两组系数:细节系数和近似系数。细节系数保留yi中的高频成分,高频成分反应了突变、骤降等随机抖动因素对主体趋势的影响,是yi中的随机性部分;近似系数保留yi中的低频成分,低频成分保留了原始特征的大部分特征,是yi中的主体趋势部分。考虑到细节系数中随机性特征的提取易受到分解尺度的影响,因而三层是小波分解的最佳尺度。此外,本文选用的基小波函数是Haar小波函数。 为表示方便,把yi记作f(t),f(t)表示yi在时间戳t上对应的值。根据文献[12]定义,小波变换对f(t)分解的公式如下 (13) 其中 Ai=HAi-1,Di=GAi-1,i=1,2,…,j (14) 式中:H表示低通滤波器;G表示高通滤波器;j表示分解的尺度;Aj为第j层的低频信息,表达序列的大致趋势;Di为第j层的高频信息,表达序列细节上的差异。经过处理,原始特征序列从原先的一维特性转变成低频和高频的二维特性。 本文通过使用Haar小波函数分别对f(t)的低频系数和高频系数进行单支重构,将低频系数和高频系数重构为与原始序列相同长度的单支序列,记为低频分量L(t)和高频分量H(t)。小波低频系数重构的曲线可以实现原始特征分量yi的还原,而且更加光滑,易反映其趋势特征[13]。小波重构的公式如下 Ai=H*Ai+1+G*Di+1,i=j-1,j-2,…,0 (15) 式中:H*和G*分别为H和G的对偶算子。 本文通过使用小波将B中各列向量的低频特征和高频特征提取出来,然后将它们组合成C,C如下所示 其中,LR(m-wn-1)表示对f(m-wn-1)重构得到的低频分量值,HR(m-wn-1)表示对f(m-wn-1)重构得到的高频分量值。 KPI异常检测的另一个关键是基于提取出的特征集,选择合适的模型进行异常检测。XGBoost是基于树或线性分类器的集成算法,它整合若干个弱分类器,形成一个具有更好分类效果或回归效果的强分类器,在各大数据竞赛中有着广泛的应用。本文选用XGBoost进行异常检测,首先对提取的特征集进行样本标记,然后分割训练样本和测试样本,接着对训练样本均衡化处理得到平衡样本,使用平衡的样本集训练XGBoost得到最优模型,最后使用最优模型对测试样本进行异常检测。 由于数据集中正常样本与异常样本的比例极度不平衡,为提升模型的检测性能、使模型异常检测能够达到预期的效果,本文采用SMOTE和随机欠采样相结合的算法对训练样本进行均衡化处理[14]。根据文献[12]设C的每行特征xi对应的样本标记为zi(zi∈R),由于C的列数为2R,行数为m-wn-1。为简便起见,令d=2R,g=m-wn-1,因此带标签的数据集D={(xi,zi)}(|D|=g,xi∈Rd,zi∈R),其中Rd表示d个特征的集合空间,R表示对应的标签集合。均衡化的具体流程是取D中的前β(0<β<1)作为训练集,使用SMOTE算法对训练集中的异常样本进行过采样,再用随机欠采样方法对训练集中的正常样本进行冗余样本去除,最终得到的主要样本信息作为新的数据集Dnew={(ai,zi)}(|Dnew|=θ,ai∈Rd,zi∈R,θ=β*g)。 (16) 其中,Γ表示所有决策树集合,φk表示第k次从Γ中取出的决策树。对于给定数据集,将其用决策树中的决策规则分类为叶子,通过相应叶子中的得分求和来计算最终预测。 为了防止模型过拟合,将L2正则化引入到XGBoost中,最终模型的目标函数为 (17) 其中 (18) 综合以上分析,基于小波分析和XGBoost的KPI异常检测算法的具体步骤描述见表2。 表2 基于小波分析和XGBoost的KPI异常检测算法步骤 为验证本文特征提取对异常检测效果的有效性,分别选取数据的原始特征、文献[7]提取的特征和文献[11]提取的特征进行对比。本文共选取16种类型的KPI数据,数据集来自http://iops.ai/dataset_list。实验中滑动窗口选取的值为分别为5、10、15和20,训练集与测试集的比例为7∶3。首先对训练集均衡采样,然后对平衡样本进行10折交叉验证选取XGBoost的最优模型参数,最后使用调参好的模型进行异常检测。XGBoost的主要参数设置见表3。 表3 XGBoost参数设置 本文实验使用的机器内存为8 GB,处理器为Intel i5-6200U,机器学习框架为Scikit-Learn。 为评估本文模型异常检测的效果,采用查全率、查准率和准确度3个评价指标,公式具体如下: (1)查全率(Recall),记作Rc (19) (2)查准率(Precision),记作Pc (20) (3)准确度(Accuracy),记作Ac (21) 上式中,真正例(TP)表示正确诊断为异常的异常点数量,真反例(TN)表示正确诊断为正常的正常点数量,假正例(FP)表示错误诊断为异常的正常点数量,假反例(FN)表示错误诊断为正常的异常点数量。Rc表示模型正确检测到的异常数量占真实异常数量的比重,Pc表示模型正确检测到的异常数量占模型检测到的异常数量的比重,Ac表示模型整体分类的正确度[12]。 由于测试集的正负样本比例不平衡,根据上述3种评价指标无法表明学习器的泛化能力,因此引入AUC[17]来研究学习器的泛化性能,进而验证本文方法的有效性。 本节分别从查全率、查准率、准确度和AUC四方面对比基于原始特征、本文方法提取的特征、文献[7]方法提取的特征和文献[11]方法提取的特征,采用XGBoost模型检测在16个KPI序列上的异常检测效果,具体见表4~表7。由表4~表7可见,本文方法的查全率和准确度普遍高于其它3种方法,在KPI2上查全率甚至接近1,这表明模型具有较好的普适性。此外,查准率在KPI2、KPI3和KPI9-KPI12也略高于其它方法,这表明模型的异常检测的精度比较高。最后,本文方法的AUC也均达到0.8,这进一步表明模型的泛化性能较好,能适应类别不平衡的数据集。 表4 4种方法的查全率对比 表5 4种方法的查准率对比 表6 4种方法的准确度对比 表7 4种方法的AUC对比 由图1可知,本文方法在KPI1、KPI4、KPI8和KPI16数据集上的ROC曲线明显优于其它方法,在其余KPI数据集上与文献 [7]和文献 [11]方法的ROC大致相同,但波动幅度是最小的。总体来说,对比16张子图的ROC曲线,本文方法的异常检测效果更加稳定、更具有普适性。 图1 16种KPI数据集上的4种方法ROC曲线对比 异常点检测图形象地展示了异常检测的结果。图2~图17中分割线左边为采样前的训练数据,分割线右边为测试数据。黑色的叉表示一个原始异常点,而空心圆圈表示一个预测的异常点,若圆圈与叉重合,表示本文方法正确地检测出该异常。 图2 KPI1异常检测 图2和图3可以看出,KPI1、KPI2波动的范围比较小,序列整体上比较有规律,属于稳定型序列。两张图中的异常点以离群点为主,极少数分散在序列的抖动处。本文的方法能较好地检测出稳定型序列中的异常点,且误判的数量较少,有一定的适用性。 图3 KPI2异常检测 图6~图8看出,KPI5、KPI6和KPI7与其它KPI序列明显不同,其值的分布极不均匀,波动幅度较大,无稳定趋势,异常点所在的位置也没有规律,属于典型的非平稳波动型序列,通过多维度的特征分析所获得的特征能够在波动型序列中取得比较好的异常检测效果。图7与图8由于训练集中的异常点数量较少,导致采样后的样本缺乏一定的平衡性,因此模型检测出的效果相比图6存在较多的误判。然而从整体的异常检测效果看,本文的方法大多能检测出波动型序列中所出现的异常点,对波动型序列也有一定的适用性。 图4、图5和图9~图17可知,KPI3、KPI4和KPI8-KPI16相比其它的序列具有明显的周期性特征,因此归属于周期型序列。图4、图5、图10、图11和图13序列中的噪声点较少,曲线比较光滑,异常点大多分散在序列上下侧,差异大不;而图9、图12和图14~图17序列中的噪声点比较多,曲线比较粗糙,异常点除了以离群点呈现之外,还有一些分布在正常序列之中。观察检测效果,本文的方法能有效识别噪声并检测出序列中的异常点,但在噪声点较多的周期型序列中,其异常检测效果会差一些,原因可能是分布在正常序列中的异常点加大了模型识别的难度。 图4 KPI3异常检测 图5 KPI4异常检测 图6 KPI5异常检测 图7 KPI6异常检测 图8 KPI7异常检测 图9 KPI8异常检测 图10 KPI9异常检测 图12 KPI11异常检测 图13 KPI12异常检测 图14 KPI13异常检测 图15 KPI14异常检测 图16 KPI15异常检测 图17 KPI16异常检测 通过上述分析可知,本文的方法适用于稳定型序列和平滑的周期型序列,而在波动型序列与噪声数较多的周期型序列上存在一些漏判和误判,但是总体检测效果上是优于其它两种算法的。因此,本文的方法对稳定型、波动型和周期型序列的异常检测具有一定的普适性。 针对KPI异常值检测较难且大多数方法只针对某种特定类型的数据,缺乏一种普适性的异常检测方法。本文提出一种基于小波分析和XGBoost的异常检测方法,该方法兼顾KPI周期型、稳定型和波动型的变化特性,多维度地提取特征,并利用小波分析加以修正。实验结果表明,本文的方法在16种KPI数据集上,其查全率、准确度和AUC整体优于其它3种方法,有较好的普适性。研究中我们发现数据集中正负样本的平衡程度对异常值的检测有一定的影响,在今后的工作中,我们将研究KPI均衡采样的方式以获得更平衡的样本,进一步提高异常检测的普适性。
1.2 基于PCA的特征降维
1.3 基于小波分析的特征修正
2 基于XGBoost的异常检测
2.1 样本均衡处理
2.2 基于XGBoost的异常检测模型
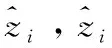
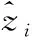
2.3 异常检测算法步骤

3 实验分析

3.1 实验评价指标
3.2 实验结果及分析











4 结束语
