基于MHA-Lattice LSTM的中文命名实体识别
2021-05-19于敏
于 敏
(北方工业大学,北京 100144)
0 引言
命名实体识别(Named Entity Recognition,NER)任务是指从非结构化自然语言中识别出特定的重要信息即命名实体,该任务作为自然语言处理的基础任务,在问答系统、机器翻译和信息抽取等自然语言处理下游任务中占据重要作用。命名实体的概念最初是在第六届MUC会议(the Sixth Message Understanding Conferences,MUC-6)中被首次提出[1],用于识别文本中组织机构、地理位置和人名等信息单元,以及时间和百分比等数字表达式。早期命名实体识别工作以基于规则和词典构建的方法为主,该方法的性能直接由规则和词典决定,可移植性较差而且建设周期长。基于统计机器学习的方法则是依赖于标注完备的大量训练语料,主要使用最大熵模型、隐马尔可夫模型、支持向量机以及条件随机场等相关模型,实现了较好的识别效果;然而,识别效果依赖于大量的标注语料的条件限制了该方法在实际生产中的广泛应用。随着深度学习的发展,各种神经网络渐渐被应用于命名实体识别,神经网络可以找到命名实体更多非线性的内在联系,并能从由有限的标注数据中学习有用的数据表示,从而达到好的识别效果。
传统的中文命名实体识别大多是基于中文分词任务,进而在目标语句上进行词级别的序列标注任务,从而达到确定命名实体边界和类型的目的。然而,分词任务不可避免地会出现错误,错误传播会一直延续到标注任务,最终影响到实体识别的性能。Zhang等[2]1554-1558提出了基于长短期记忆网络-条件随机场(Long Short-Term Memory- Conditional Random Field,LSTM-CRF)的网格长短期记忆网络(Lattice LSTM)模型,在基于字符的序列模型上,引入词典达到将词信息集成到基于字的模型的目的。该模型获得了比以往模型更加优秀的效果。然而,模型难以处理潜在匹配词对的冲突问题,同时由于LSTM链式结构的存在,不能充分利用语句序列的全局信息,而且对于远距离文本信息的特征提取性能会随着距离的增加而弱化。因此,中文命名实体识别的研究还有很多问题亟待解决。
1 中文命名实体识别相关研究
目前命名实体识别算法可以根据它们在语句序列中所使用的不同信息特征和模型分为不同的类别。其中包含字符级模型、词级模型和字符与词级混合模型。字符级模型将语句序列中的每个字符的嵌入表示作为模型输入,学习语句序列中字符与字符之间的内在关联以获取命名实体;很多研究工作者探讨了基于字符的中文命名实体识别算法,Dong等[3]在基于字符的模型基础上,通过字根特征获取字符的嵌入信息以优化模型的字符嵌入,JIA等[4]在基于字符的模型基础上,同时利用BERT与训练进行实体增强,将文本中的特定实体集成到模型中。词级模型中,语句序列中的每个词由其词嵌入表示,词信息的使用在英文语言文本中更加便利,英文自然语言本身具有明显的区分标志,文献[5-7]在基于词的模型基础上,引入了不同信息特征以提升识别效果,如语句序列中潜藏的时间信息等特征或实现了基于词嵌入的无监督命名实体识别。基于字符的中文实体识别被证明效果要优于基于词的中文命名实体识别[8]。因此,很多研究都尝试将词信息集成到基于字符的模型中,Wu等[9]提出了多向图结构,通过融合文本中的地名索引信息学习字的单词表示,实现了较好的识别效果。GUI等[10]通过卷积神经网络获取上下文多维信息表示,整合了通过预训练的词嵌入所包含的词信息以及字信息,通过反思机制加强信息特征表示,有效地进行了相关命名实体的识别。将字信息和词信息融合到模型中是实现命名实体识别效果的有效方法。
基于LSTM-CRF的Lattice LSTM模型在字符级模型基础上引入词典,以达到将词信息集成到字符级模型的效果。与基于字的模型相比较而言,该模型显性利用了词信息和词序信息,与基于词的模型相比较而言,该模型有效避免了分词任务所引起的错误传播。
Lattice LSTM的门控循环单元用于控制相邻字符路径和潜在匹配词路径之间的贡献值。然而,门控机制有时不能选择正确的路径。模型难以处理纳入词典中的潜在匹配词之间的冲突:1个字符可能对应于词典中的多个潜在词对,错误的选择可能会导致网格模型退化为部分基于词的模型,导致标记错误,如图1所示。
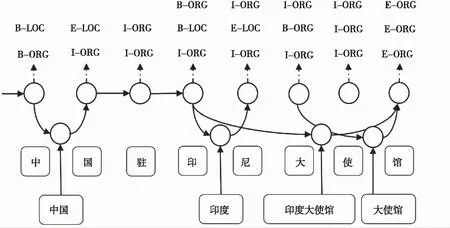
图1 退化的Lattice LSTM模型
图1中,“中国驻印尼大使馆”“印尼大使馆”和“大使馆”3个词语共享词边界“馆”,3个词所占权重是模型无法判断的,故匹配词冲突问题会导致标记错误进而影响模型整体性能;同时,基于LSTM的模型是对语句进行顺序编码,嵌套实体会存在严重的歧义问题,并且字符优先分配给左边的词语。例如,“中国驻印尼大使馆”语句序列中,模型可能会优先分配“中国”,然后再是“印尼”等标签,即当前字符并未关注到其后面剩余的字符,缺乏对整个语句序列的语义信息的感知。
为有效减小潜在匹配词对的冲突问题,充分利用字符之间的内在关联性和全局语义信息,笔者通过多头注意力机制(Multi-Head Attention,MHA),结合优化的Lattice LSTM模型,提出MHA-Lattice LSTM模型,在获取字信息之间内在关联的同时,捕获语句序列的全局信息,提高模型处理远距离语义信息的能力;注意力机制通过控制不同路径词信息到字符的权重,有效提升模型处理潜在词对的冲突问题,同时将全局语义信息纳入考虑,弥补了模型链式顺序结构的全局语义的缺失问题。
2 MHA-Lattice LSTM模型的提出
为有效利用语句序列中的字信息和潜在隐藏词汇所包含的词信息,笔者提出基于注意力机制和Lattice LSTM的命名实体识别模型。模型使用预训练词典信息,避免了由于分词错误所引起的错误传播;模型通过注意力机制可使远距离有效信息捕获的可能性变大,有效利用远距离依赖特征和全局信息,同时,通过控制不同路径潜在词汇信息到字符的权重,有效提升了模型处理潜在词对的冲突问题。MHA-Lattice LSTM模型框架如图2所示。

图2 MHA-Lattice LSTM模型框架
2.1 Lattice LSTM的优化
基于字的LSTM模型本身并未有效利用语句序列中的词信息,为此,笔者使用Lattice LSTM模型,同时学习和提取语句序列中的字信息和词信息。Lattice LSTM可以看作是基于字的模型的扩展,集成了基于潜在词汇信息的单元和附加门来控制信息流,Lattice LSTM网络结构如图3所示。

图3 Lattice LSTM网络结构
Lattice模型和基于字符的模型有所区别,它是通过词嵌入词典引入外部词汇信息,对输入字符序列以及与字符匹配的潜在词汇进行编码,从而有效挖掘语句序列中潜藏的词信息的。模型单元状态的计算公式如下:
(1)
(2)
模型使用不同的优化算法会影响模型效果,笔者针对同一模型进行了随机梯度下降(Stochastic Gradient Descent ,SGD)和Ranger优化算法[11-12]2个不同优化算法的损失函数曲线对比实验,如图4所示。

图4 不同优化算法损失函数曲线
通过图4可以发现,Ranger优化算法下降更为平滑,且具有较强的鲁棒性,而且Ranger优化器结合了RAdam和LookAhead 2个优化器的优点,需要手动调整的参数较少,故笔者采用Ranger优化算法。
2.2 多头注意力机制
LSTM的链式结构在学习过程中会抛弃部分信息,而且随着语句序列长度的增加,字符之间的关联性越来越弱,这就导致模型不能有效利用语句序列的远距离语义信息。自注意力机制在计算过程中会将语句序列中任意2个字符直接联系起来,极大地缩短了远距离依赖特征之间的距离,使得远距离有效信息的捕获可能性变大,有利于有效利用这些特征[13]。注意力机制通过允许模型直接使用来自所有时间步长的信息来克服远距语义依赖问题,通过获取语句序列中字符之间的关联程度,调整权重系数矩阵以获取词的表征。自注意力机制计算方式如下:
(3)
式(3)中,Q,K,V分别为查询、键和值,三者维度相同;dk为三者维度。通过Q,K,V三者的权重操作获取语句序列中字符之间的依赖关系,捕捉其内在关联性。
多头注意机制被广泛应用于神经网络的融合过程中,通过给相邻节点或关联节点分配不同的权值来聚合信息,捕获语句序列中的全局依赖关系。多头注意力机制是执行n次Q,K,V向量的线性变化,并计算放缩点积注意力,进而拼接n次放缩点积注意力计算的结果,每一次称为1个head。多头注意机制计算方式见式(4)和式(5):
MH(Q,K,V)=concat(head1,...,headn)WO
(4)
(5)
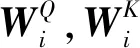
多头注意力机制相对自注意力机制就是多次对Q,K,V三者进行权重操作,最后将结果合并的过程。其中,每个仅计算最终输出序列的其中1个子空间,占比为头数之一,而且子空间之间学习和训练过程相互独立。多头注意力机制如图5所示。

图5 多头注意力机制
头数量为初始确定参数之一,Transformer中头数量常设为8头,笔者使用不同头数量进行试验,最终以8头获取到实验最佳效果。图6为Resume数据集在不同头数量下的实验对比结果,实验结果显示Resume数据集在头数为8时取得最佳效果。

图6 不同头数实验对比结果
条件随机场常被应用于序列标注模型中,学习语句序列中的约束条件,以避免某些不合法标签的出现。例如,命名实体的开头标签应为“B-”“O”或者“S-”,而不是“M-”和“E-”等约束条件。为提高预测结果的可靠性,笔者通过条件随机场(CRF)来界定标签之间的依赖关系;CRF输入为隐藏状态序列h1,h2,...,hn。对于语句的标签序列y1,y2,...,yn有:
(6)
式(6)中,y'表示任意标签序列;Wli和b(li-1,li)为模型参数,分别表示权重矩阵和偏置量。
3 实验与分析
笔者对不同领域多个数据集进行了实验与分析,以下将详细介绍数据集、模型参数设置,对相关实验结果展开讨论与分析。
3.1 实验数据与评价标准
笔者对新闻、社交媒体和金融3个领域的数据集进行了实验与分析。(1)OntoNotes-4.0[14]:新闻领域数据集,包含地名(LOC)、组织名(ORG)、行政区名(GPE)和人名(PER)4种命名实体。(2)Weibo[15]:社交媒体领域,包含地名(LOC)、组织名(ORG)、行政区名(GPE)和人名(PER)4种命名实体。(3)Resume[2]1559:金融领域,包含地名(LOC)、组织名(ORG)和人名(PER)等多种命名实体。
对于3种数据集的标注方式,使用5位序列标记法BMEOS。数据集的统计信息如表1所示。
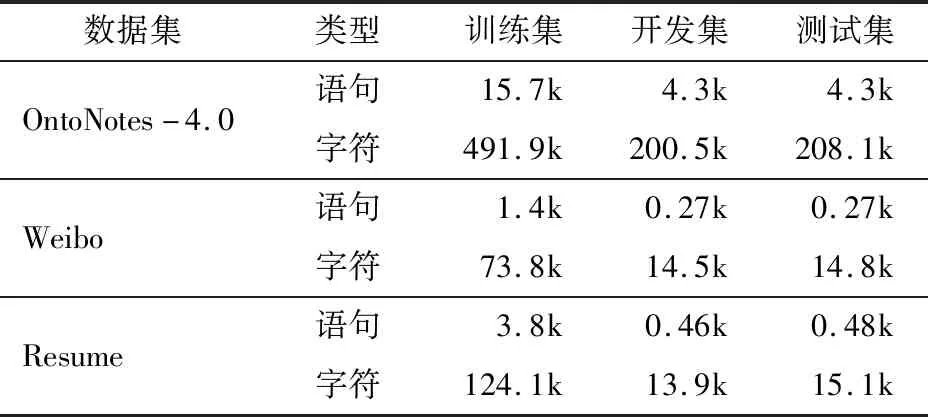
表1 数据集统计信息
笔者以准确率(Precision,P)、召回率(Recall,R)和F1-measure(F1)作为评价指标来评价模型的性能。其中,P表示模型正确识别的命名实体个数占模型识别的所有命名实体个数之比;R表示模型正确识别的实体个数占总体命名实体个数;F1值为综合评价指标,权衡P值和R值,获取模型最佳效果。评价标准的计算方式如下:
(7)
(8)
(9)
式(7)~式(9)中,TP(True-Positive)和FP(False-Positive)表示真正例和假正例,FN(False-Negative)表示假反例。
3.2 实验结果分析
为了验证笔者提出的算法有效性,以Lattice LSTM结果为基线进行对比试验。针对相应数据集作为训练样本,使用PyTorch框架对Lattice LSTM模型进行训练。具体参数设置如下:字嵌入和lattice LSTM词嵌入维度大小为50,LSTM隐层大小为200,学习率更新逐步降低,衰减率为0.005,Dropout为0.5。
MHA-Lattice的实验及相关对比结果详见表2~表4,其中对照算法为Lattice以及基线模型。
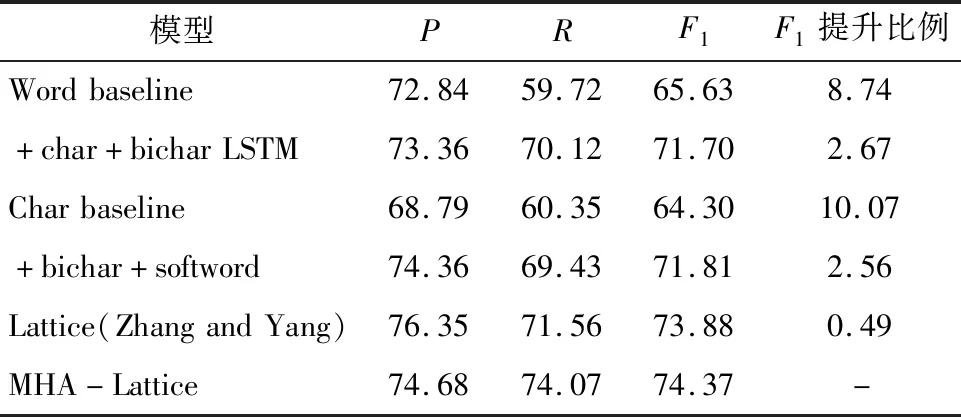
表2 OntoNotes-4.0实验结果 单位:%
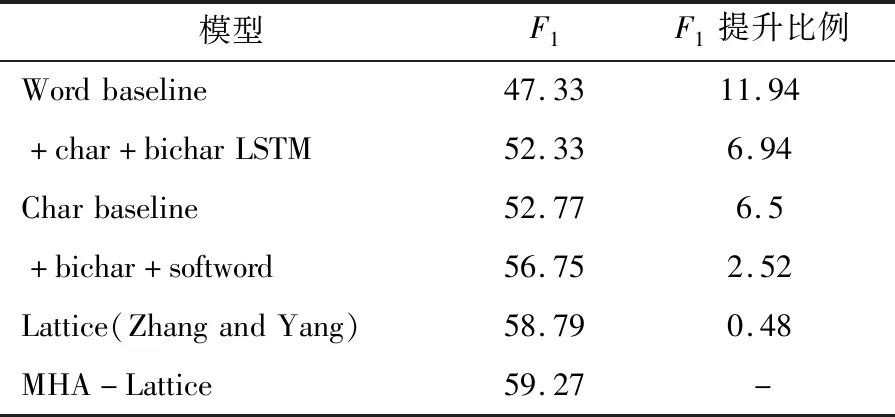
表3 Weibo实验结果 单位:%
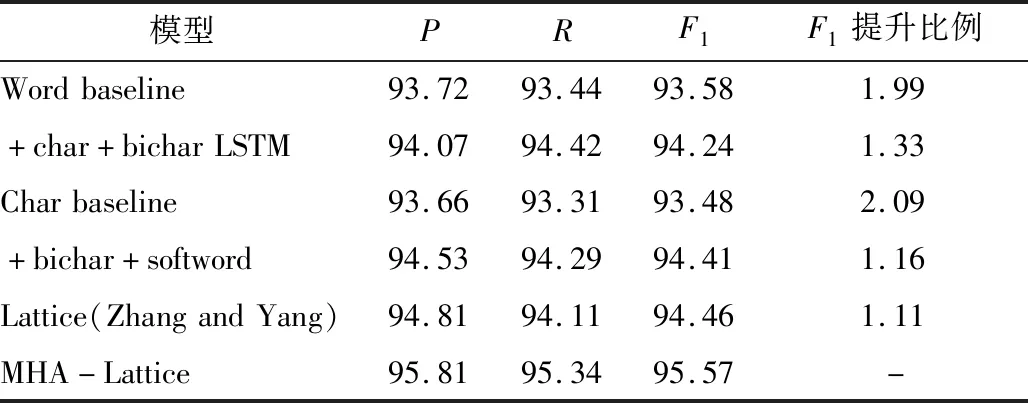
表4 Resume实验结果 单位:%
从表2~表4中可以看出,MHA-Lattice LSTM算法在不同领域不同数据集上整体性能均有所提升;表2中,Ontonote-4.0数据集数据规模较大,召回率提升2.51%,整体F1值相对基线模型提升0.49%;表3中,Weibo数据集由于包含较多表情及网络用语,识别效果相对其他数据集较差,整体F1值相对基线模型提升0.48%;表4中,Resume数据集标注完备,数据规范,识别效果相对较好,精确率和召回率均有提升,整体F1值相对于基线模型提升1.11%。实验结果充分说明了算法的有效性。模型通过注意力机制,可以更加有效地利用字符特征来克服远距语义依赖问题,有效提升命名实体识别性能。
4 结论
针对潜在匹配词对冲突问题,笔者通过多头注意力机制结合并优化Lattice LSTM模型,捕获字符之间的内在关联信息,同时获取到语句序列中的远距离有效信息,将语句中任意2个字符直接联系起来,极大地缩短了远距离依赖特征之间的距离,有利于有效地利用这些特征来克服远距语义依赖问题。模型在新闻、社交媒体和金融等不同领域的多个数据集上性能均有提高。
笔者分析研究了命名实体识别的关于匹配词对的冲突问题,提升了模型性能,针对特定领域不同数据集性能效果差别较大,后续工作将考虑针对特定领域进行模型优化。
