基于OMNet++的大规模InfiniBand互连网络模拟系统*
2021-05-18钱德沛
汪 鑫,林 放,刘 轶,钱德沛
(北京航空航天大学计算机学院,北京 100191)
1 引言
高性能计算系统广泛应用于灾害预测、环境监控、基因工程和航空航天等领域。由于此类系统规模庞大、结构复杂,其实际性能受到多方面因素的影响,如处理器、内存和互连网络等。因此,在系统设计阶段,通过模拟的方法对高性能计算系统方案进行性能评价,从而对设计进行改进,将大大节省经济和时间开销。
互连网络是高性能计算机系统的重要组成部分,研发人员对并行程序运行过程中互连网络状态和性能十分关注。近年来,以InfiniBand为代表的产品化高速互连网络在高性能计算系统中应用日益广泛。统计数据[1,2]显示,2019年11月发布的TOP500名单中,TOP100中采用InfiniBand的比例高达46%,同比2018年增长5%,其中排名前3的系统全部采用InfiniBand互连网络。因此,对InfiniBand进行建模模拟是很有必要的。
在高性能互连网络模拟方面通常的做法有数学建模法和仿真模拟法。数学建模法用参数刻画网络特征,建立网络模型,模拟速度快,容易与高性能计算机模拟系统集成,但是误差较大;仿真模拟方法可使用网络模拟器(如OMNet++)完成,其优点是可以较为精确地进行网络建模和模拟,但模拟过程中通信模式相对固定,难以模拟程序运行过程中的网络状态和性能。提供一种模拟精度和效率较高,并且能够模拟MPI程序运行过程中互连网络状态的网络模拟器是一个需要解决的问题。
针对于此,本文设计了一种基于OMNet++网络仿真框架的大规模InfiniBand互连网络模拟系统,该系统通过记录的并行程序MPI消息来驱动网络仿真过程,可以较为准确地模拟InfiniBand互连网络在程序运行过程中的性能表现。系统支持对不同拓扑和速率的InfiniBand互连网络进行模拟,并可与高性能计算机模拟系统集成。
2 基于OMNet++的互连网络模拟 系统
2.1 网络仿真框架OMNet++简介
OMNet++是一个离散事件仿真框架,具备全开源、高度模块化和模块可定制化等优点。OMNet++将网络抽象成不同简单模块和复合模块的组合,提供Ned描述语言来快速定义网络拓扑,使用ini文件进行网络参数初始化,使用C++语言来定义仿真主体各个网络模块的行为。
模块之间通过门连接,通过消息通信,提供Send函数接口用于发送消息,handleMessage函数接口用于处理接收的消息。OMNet++提供CMDENV和QTENV 2种用户仿真环境,前者以命令行方式运行,多用于批处理模拟任务;后者提供交互界面模式,可直观地观察仿真过程中消息的发送与接收。OMNet++框架如图1所示。

Figure 1 Framework of OMNet++图1 OMNet++框架图
用户主要通过定义网络模块的行为来实现网络的模拟功能,比如数据包的接口转发、拥塞控制等。在网络仿真开始之前,进行模块初始化,即进行各模块参数的设置,同时确定模拟通信的形式,如点对点单消息通信或点对点消息集合通信,因为是事件驱动模拟,所以第1个事件的产生至关重要。仿真环境内部维护1个事件队列,模块间通信时,每进行一次Send都会向事件队列中添加事件,并且切换当前仿真上下文(执行操作的模块),而并非直接到达目的模块。然后依次从事件队列中取出事件,若事件的所有者和当前上下文一致,则执行事件;若队列为空,则模拟过程结束。
2.2 设计思路
现有OMNet++支持的工作方式,每次模拟都是对某次通信或者某种特定场景下消息序列通信的模拟,即仿真任务都是由配置文件提前配置好的。而要模拟并行程序运行过程中的互连网络状态,要求系统能以并行程序运行过程中的消息传输作为模拟输入,这在现有框架下难以实现,需要对系统进行扩展,使其能够在模拟过程中接收并行程序MPI消息,并以此驱动互连网络的模拟。
一种简单的设计是,每一次新的通信都更新一次配置文件,然后通过命令行方式(CMDENV)启动一次全新的网络模拟,这样也能实现对实时MPI消息的接收并进行一次模拟。但是,这种设计有一个严重的问题,由于还是由配置文件确定的通信过程模拟,当连续2次通信的信息(源节点、目的节点或消息大小)不一致时,需要对文件进行修改,即需要对文件不断读写,这将是一个极大的开销。同时还有每次对同样网络拓扑进行重建带来的不必要开销。
以上问题导致了现有的基于OMNet++实现的网络仿真模型无法直接模拟并行程序执行过程中的网络状态。为了模拟并行程序执行过程中的网络状态和性能,需要解决以下2个问题:
(1)系统能接收外部的MPI通信消息,并能以此消息为驱动,模拟互连网络通信。
(2)高性能计算机模拟器的通信模拟需求可能不是连续的,存在持续一段时间多次调用I/O操作的情况。在一次通信模拟结束之后,系统需要继续等待外部消息的到来,而不是直接停止工作。
2.3 互连网络模拟系统结构
为了实现由外部MPI通信消息驱动的网络仿真系统,本文在原来的网络模型中,增加了管理节点。管理节点和每一个模拟节点相连,不参与网络模拟通信的过程,只接收消息接口转发的外部节点MPI通信模拟请求,并根据消息的起始节点分发消息。通信仿真时延通过模拟节点发送给管理节点,并由管理节点返回给消息接口。
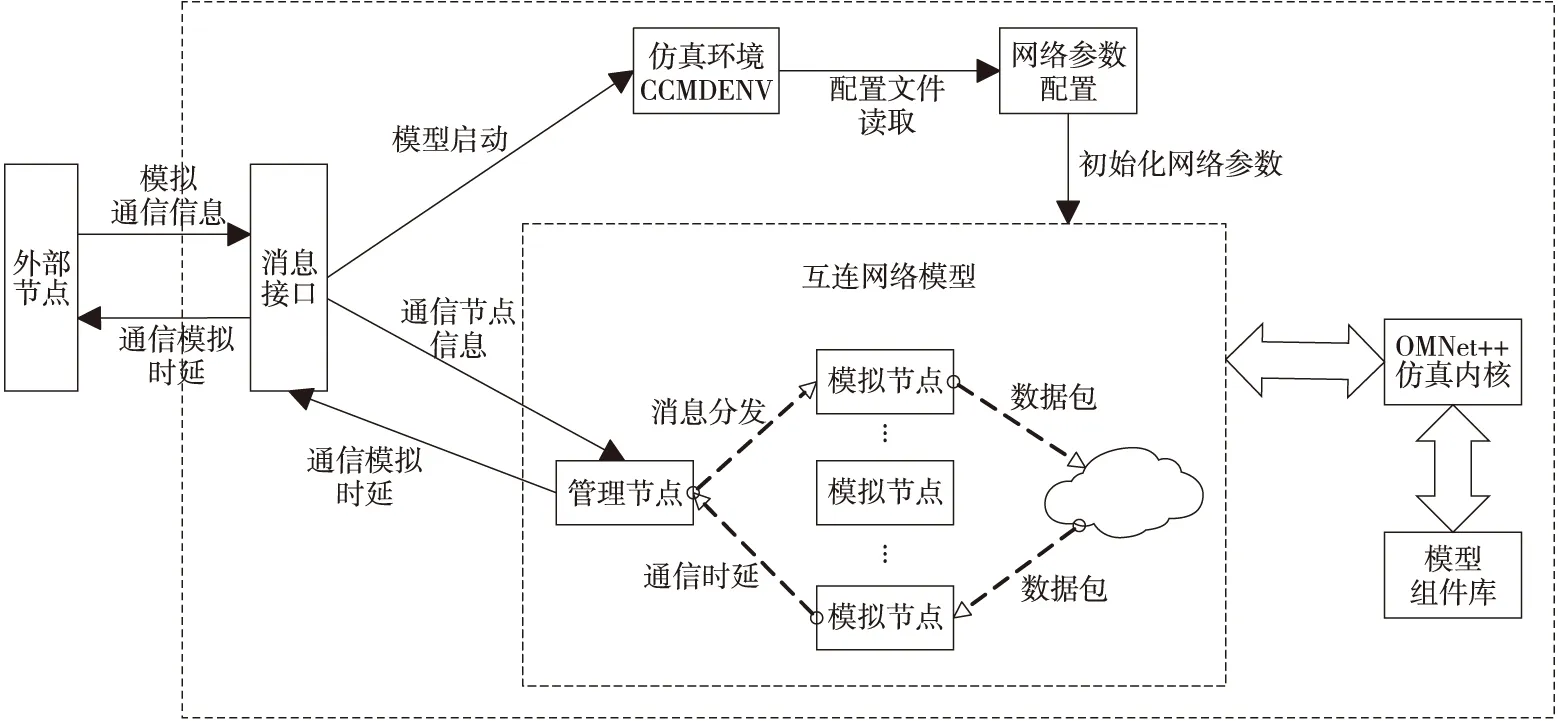
Figure 2 Structure of the interconnection network simulation system based on OMNet++图2 基于OMNet++的互连网络模拟系统总体结构
同时为了满足高性能计算机模拟系统的实时MPI通信模拟请求,本文在CMDENV仿真环境基础上实现了CCMDENV(Connectable CMDENV)仿真环境接口。区别于OMNet++的仿真环境接口,在实现上,CCMDENV设计事件队列为空时不直接停止,而是以指定的频率轮询队列,继续等待事件到来。同时对管理节点增加分发消息标识,使之不会影响当前正在进行的通信模拟。
基于OMNet++的互连网络模拟系统总体结构如图2所示。并行程序在真实的高性能计算系统中运行,使用PMPI(MPI Profiling Interface)[3]接口捕获每个通信函数,获取函数的MPI消息信封(包括源进程号、目的进程号和数据大小等)并输入至外部节点,外部节点存储这些MPI通信消息,并发起通信模拟请求。消息接口用来接收外部节点通信请求以及进行仿真请求的转发,同时接收仿真结果。网络配置包括网络拓扑和网络参数(链路带宽、网络拥塞等)的设置。系统通过Ned文件配置网络拓扑信息,通过ini文件配置网络参数信息。用户通过网络配置模块生成Ned文件和ini文件。模拟节点作为网络仿真主机节点,进行仿真消息的发送与接收。仿真内核和模型组件库用来支持OMNet++仿真。
根据图2,网络模拟系统的具体工作流程如下所示:
(1)消息接口接收外部节点通信模拟请求,如果此时模型未启动,则通过仿真环境接口启动仿真模型,配置网络参数,初始化模型组件;
(2)消息接口将通信模拟请求发送给管理节点,管理节点根据进程与节点的分布关系,以及源进程号和目的进程号,解析通信消息的起始节点,将消息分发给对应的模拟节点;
(3)模拟节点根据通信消息的目的节点、消息大小等信息,生成仿真通信消息并发送;
(4)目的节点接收到仿真通信消息,将本次通信时延等信息发回管理节点,管理节点再将其发回消息接口,由消息接口传回外部节点。
3 InfiniBand网络的建模与模拟
3.1 HCA和Switch模型
针对InfiniBand网络的分析,本文将网络简化成由主机通道适配器HCA(Host Channel Adapter)、交换机(Switch)和链路构成,并做以下假设:
(1)交换机工作为流水线模型;
(2)假设交换机转发采取虚切通的工作方式,在虚切通模式下,交换机接收到包头之后即可进行接口转发,无需等待完整数据包接收完毕;
(3)每个交换机含有M个输入输出端口,每个端口有N个虚拟链路VL(Virtual Link),并对每个输入输出端口建立FCFS队列;
(4)交换机对不同数据包进行路由、仲裁等处理的时延为固定时延。
主机(HCA)和交换机(Switch)模型如图3所示,模型中各模块的含义如表1所示。

Figure 3 Model of HCA and Switch图3 HAC和Switch模型

Table 1 Illustration and function of each module
在HCA模型中,每个HCA包含消息产生模块(app)、包生成模块(gen)、输入输出缓冲模块、消息接收模块(sink)和仲裁模块。app产生消息,消息包含消息大小以及通信的源节点、目的节点,产生的消息进入gen模块。gen将消息进行分包和分片,然后进入vlarb模块。vlarb根据消息的目的节点分配VL,进入obuf排队或者直接输出;同时vlarb接收ibuf与远程目的节点协商的可接收的消息缓冲大小进行链路控制。obuf根据vlarb的仲裁消息,决定队列消息的发送;ibuf则接收外部节点信息,以及接收目的节点的流量控制信息。
交换机模型由交换机端口模块、交换机端口转发表和交换机开关组成。交换机端口转发表在网络拓扑初始化过程中建立,存储交换机到所有计算节点(HCA)的转发端口列表,因为网络拓扑的原因,交换机到计算节点可能存在多个不同的转发端口。交换机端口模型包含ibuf、obuf和vlarb模块,obuf为输出缓冲,进行消息排队和输出;ibuf接收节点数据消息和链路控制信息;vlarb则进行obuf队列输出和链路控制。
3.2 消息建模
为了实现消息的接收、发送与链路控制,需要针对不同类型的消息进行建模。主要消息类型及其作用说明如表2所示。

Table 2 Illustration and function of messages表2 消息类型及其作用说明
3.3 路由算法实现
对互连网络模拟的很重要的一部分包括路由算法的实现。当前主流的互连网络路由算法主要有OpenSM[4]中提供的7种:Min Hop、UPDN(UP/Down)、 DNUP(Down/UP)、 胖树(Fat Tree)、LASH(LAyered SHortest path routing)、 DOR(Dimension Order Routing)和Torus-2Qos。InfiniBand是当前高性能计算使用最多的高性能互连网络,而胖树拓扑则是InfiniBand互连网络的主要拓扑结构。本文针对胖树拓扑,实现了针对该拓扑的路由算法Fat-Tree。该算法利用胖树的分层结构特性,避免了环路路由的问题。胖树结构中,层级越小则表示靠近根部节点。路由表在模块初始化、仿真开始之前建立,算法如算法1所示。
算法1路由表建立
1forleavlinL→0:
2forswinswitchList[level]:
3sw.upSwitch←send(hcaList,port);
4forlevelin 0→L:
5forswinswitchList[level]:
6sw.downSwitch←Syn(pktForwardList)
4 实验与结果分析
4.1 实验环境与测试方法
为了验证模拟的精度,本文从高性能集群中采集真实的通信时延,将系统模拟时延结果与实际集群节点通信时延作对比。集群配置和仿真主机配置如表3所示。

Table 3 Parameters of cluster and simulation host表3 集群和仿真主机配置
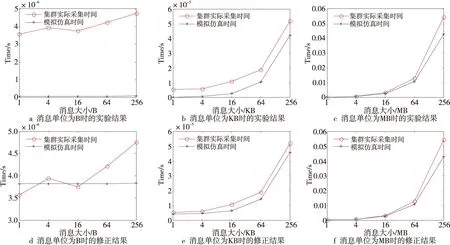
Figure 4 Communication latany of kinds of messages图4 不同消息长度的通信时延
由于集群限制,大多高性能集群的设计都是通过一台InfiniBand交换机作为根部节点,计算节点与InfiniBand交换机直接相连。实验数据采集于此种集群结构;为了减少通信误差,实验以2个节点之间50次通信时延的算术平均值作为通信时延。通信消息在B、KB和MB 3个单位下分别选取1,4,16,64和256共5种长度。
4.2 实验结果分析
实验结果如图4所示。其中图4a~图4c分别给出了当通信消息单位分别为B、KB和MB时,从实际集群采集的通信时延和互连网络模拟系统模拟时延。从图4a可以看出,当消息较小时(1 B,4 B和16 B),集群通信时延相差不大。这主要是因为采集时延为MPI通信时延,MPI环境通信本身需要额外的开销,而小消息通信时延相对来说可忽略不计。模拟系统因为采用了最小消息长度(1 024 B),不足则按最小长度计算,所以在测量区间内模拟结果不变。当消息长度增大时,集群通信时延和模拟系统模拟时延结果相差不大,当消息大小上升为MB级别时,如图4c所示,模拟结果和实际集群采集时延较为吻合,只有在特大通信消息时(256 MB),出现了一定的差距。这主要是因为网络通信的复杂性,网络并不会长时间保持相同的拥塞情况。当通信过程持续时间较长时,通信过程受到网络干扰的可能也随之增加。
由于集群通信采集时延是MPI通信时延,MPI通信本身有通信开销,当通信消息很小时,网络通信时延相比MPI通信接口初始化开销占比较小,故本文把实际集群小消息通信时延作为MPI本身开销。把MPI开销作为修正因子加入模拟系统中,图4d~图4f表示加入修正因子之后的模拟结果。
4.3 性能分析
为了分析互连网络模拟系统的性能,实验分别记录不同长度消息的通信仿真所需实际时间。过小的通信消息,仿真所需时间短,故而受外部不稳定因素影响波动较大,所以不做讨论。本实验主要采集单位为KB的消息,长度分别取64 KB,128 KB,256 KB, 512 KB,1 024 KB和2 048 KB,仿真所需时间均取多次实验的算数平均值,以降低实验误差。实验结果如图5所示。

Figure 5 Time required for simulation图5 仿真实际所需时间
图5结果显示,仿真所需时间与仿真消息大小基本成正比关系。这是因为系统是以消息驱动的模拟仿真,当通信消息成倍增长时,产生的仿真消息也是成倍增长,因而仿真所需时间也是成倍增加。在消息大小为64 KB,128 KB和256 KB时,仿真所需时间本身也很小,因而测量时间波动较大,所以和消息大小在1 MB和2 MB时的时间比率有稍微偏差。总体来看,仿真所需时间较短,效率较高。
从趋势看,当消息长度为256 MB时,仿真时间将达到分钟级别。但是,实际通信过程中,这类大消息不经常出现,同时仿真所需时间本身也与进行仿真的主机配置相关,所以不影响本模拟系统的正常使用。
5 相关工作
互连网络模拟方法通常分为2种:一是通过抽象互连网络特征,用参数模型来刻画互连网络,进行数学参数建模;二是通过离散事件来模拟网络行为,进行仿真模拟。
在数学建模方面,最典型的是以LogP[5]为基础的一系列简易参数模型。LogP模型使用4个参数:互连网络单次通信时延的上限(L)、处理器处理消息开销(o)、连续消息传输之间的间隔(g)和处理器数量(P),来刻画互连网络的整体通信时延。与LogP相比,Alexandrov等人[6]提出的LogGP模型添加了一个附加参数G,即长消息中2个连续字节之间的间隙。该模型模拟了大多数网络相对快速地传输大型消息的能力,使得每个字节的成本度量(G)比在LogP建模中多个小消息建模方式(受G限制)更精确。LoPC[7]在LogP模型的基础上考虑了在多处理器或工作站网络上并行算法对消息处理资源的争夺,LoPC直接从LogP模型中获取L、o和P参数,并使用它们来预测争用成本C。LoGPC[8]扩展了LogP和LogGP,以考虑网络争用和网络接口DMA行为对消息传递程序性能的影响。LogGPS[9]模型将发送方同步添加到模型中,大消息的传递通常是通过向接收方发送小的控制消息来检查是否有足够的缓冲来执行的。会合协议使发送方与接收方同步,在接收方准备好接收消息之前,不能发送消息。S为消息长度的阈值,超过该阈值则采用同步协议,以分析同步对通信成本的影响。Hoefler等人[10]在LogfP模型中针对基于InfiniBand的小消息建模,增加参数f表示可同时发送的最大消息数量。
除了LogP系列模型外,还有对互连网络进行整体数学建模的方法。文献[11]运用排队论针对交换端口建立排队模型,进而建立了虚切通方式下的链路延时模型,最后分别针对不同拓扑建立不同的路由模型,得到最终网络排队延时模型。高性能计算机系统模拟器SimHPC[12]集成了文献[11]的方法,作为其互连网络模拟系统。
数学建模方法的参数少则模型过于简单,会导致误差太大;参数多则模型复杂,求解时间长。与之相对的仿真模拟方法,精度更高且适用性更广,但模拟时间比数学建模方法长。近年来,随着计算机性能的提升,采用仿真模拟的方法所需时间不再是不可接受,较之仿真精度高,使用仿真法模拟互连网络的比例逐步上升。
文献[13]针对InfiniBand互连网络,使用OMNet++建立网络仿真模型,然而却没有对路由建模,使用固定端口转发进行数据转发模拟。Liu等人[14]提出了一个针对Fat-Tree互连网络建模的模拟器FatTreeSim,分别从胖树拓扑、胖树流量和胖树路由等方面对网络进行建模,采用离散事件驱动的仿真方法,但是该方法是基于PDES工具包实现的,不利于与高性能计算机模拟器集成。OMNet++实现的片级InfiniBand模拟器[15],同样没有对路由算法建模,而且不支持最近主流的EDR网络,仅能支持FDR的模拟。
6 结束语
高性能计算系统模拟器对高性能计算机的研发与调优有着至关重要的作用,对其中互连网络的模拟也是不可或缺的一部分。本文设计了一种基于OMNet++网络仿真框架的大规模InfiniBand互连网络模拟系统,该系统通过记录的并行程序MPI消息来驱动网络仿真过程,使OMNet++支持以外部消息为驱动的网络仿真。系统可做为高性能计算模拟器的网络部分模拟,而不必每次都进行新配置文件读写、网络配置等操作。同时OMNet++网络模型不必是InfiniBand互连网络,其他使用OMNet++仿真框架的网络模型,同样可以使用本文设计的互连网络模拟系统实现由外部消息驱动的网络仿真。
后续改进将针对模拟器的模拟效率展开,系统在针对大消息通信模拟时所需时间还有待改进。同时,需要增加路由算法的其他实现,因为网络拓扑的多样性,选择的路由算法应有不同,OpenSM中提供的路由算法亦是如此。
