基于改进YOLOv4的安全帽佩戴检测算法
2021-05-16王雨晨徐明昆
王雨晨 徐明昆





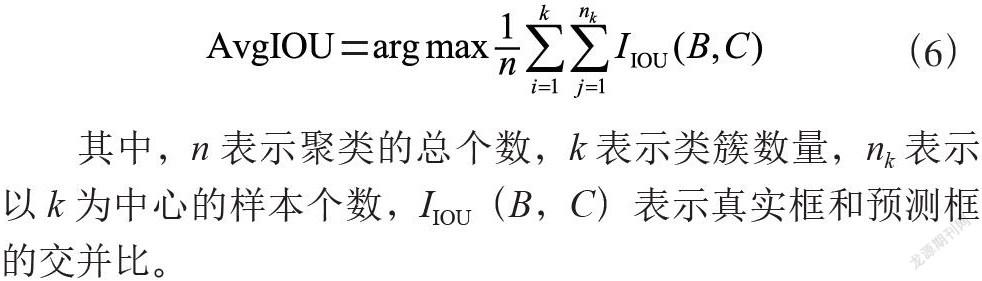







摘 要:针对目前智慧安监领域对于安全帽佩戴的检测存在尺度多样化、检测难度大、中小目标漏检率高的问题,提出了一种基于改进的YOLOv4的安全帽佩戴检测算法。首先,改进K-means算法重新选择锚框,然后在网络中引入CBAM注意力模块来增强安全帽佩戴信息的特征表达,最后对模型进行加速剪枝。实验结果表明,提出的算法在检测中mAP@0.5值提升了6.7%,检测速度提升了35%,模型参数量减少了48%,改进后的模型更适用于实际场景中对安全帽佩戴行为的识别。
关键词:安全帽佩戴检测;YOLOv4网络;改进K-means;CBAM;剪枝
中图分类号:TP391.4 文献标识码:A文章编号:2096-4706(2021)22-0156-06
Abstract: Aiming at the current problems in the detection of safety helmet wearing in the field of intelligent safety supervision of diversified scales, difficult detection and high missed detection rate of small and medium-sized targets, a safety helmet wearing detection algorithm based on improved YOLOv4 is proposed. Firstly, the improved k-means algorithm reselects the anchor box, then introduces the CBAM attention module into the network to enhance the feature expression of safety helmet wearing information, and finally speeds up the pruning of the model. The experimental results show that the proposed algorithm improves the mAP@0.5 value by 6.7%, improves the detection speed by 35%, the amount of model parameters is reduced by 48%. The improved model is more suitable for the identification of safety helmet wearing behavior in the actual scene.
Keywords: safety helmet wearing detection; YOLOv4 network; improved K-means; CBAM; pruning
0 引 言
随着当前城市化的加速发展,我国的建筑业规模日益扩大[1],但是对于施工人员的安全防护措施仍然落后,安全事故时有发生。安全帽作为有效保护头部的安全防护工具,其正确佩戴非常重要,相关企业规定相关人员进入施工场所必须正确佩戴。近年来,计算机视觉领域的迅速发展促进了图像采集设备和图像处理技术的结合使用,使得安全帽佩戴自动检测成为可能[2]。目前大多数工厂已经安装了智能监控设备,通过对于相关人员的行为分析进而检测是否正确佩戴安全帽。然而在实际监控场景中,由于监控设备安装的角度和场景复杂性,画面易出现佩戴安全帽人员所占比例小、尺度变化大等问题,容易产生漏检。因此结合实际复杂工业环境,设计一个适用于小目标安全帽佩戴检测的算法对于安全生产有着重要意义。
随着深度学习热潮的出现,许多学者使用深度学习算法解决目标检测任务并取得了巨大突破[3]。基于深度学习的目标识别方法主要分为两类,即两步检测[4-6](two-stage)算法和单步检测[7,8](one-stage)算法。两步检测法在检测精度上更有优势,单步检测法在检测速度上更具有优势。Fang等人[9]使用改进后的Fast R-CNN对未佩戴安全帽的人员进行识别,但是由于检测过程中先选择候选框然后进行分类,检测速率较慢。Huang等[10]指出在待检目标尺度相对较小时,基于锚框的检测器的检测准度都会急剧下降,而安全帽检测任务中多以小目标为主。王兵等[11]使用改进的YOLOv3进行安全帽佩戴检测,但是由于底层缺乏语义信息容易造成小目标漏檢。施辉[12]利用改进后的YOLOv3网络,先识别人体再识别安全帽,存在两部分误差。由于智能监控的目标检测算法需要处理实时视频数据,需要较快的判断速度,因此本实验选择使用单阶段算法YOLOv4,通过对网络的改进实现对安全帽佩戴进行检测。
综上,本文提出一种基于改进YOLOv4的安全帽佩戴检测算法,进而实现对于实际监控场景的小目标、多尺度的检测,本文主要工作包含:(1)嵌入融合CBAM(Convolution Block Attention Module)注意力机制的特征增强方法;(2)改进K-means聚类算法对锚点框重新选择;(3)使用通道剪枝和层剪枝融合的剪枝策略对网络进行加速。
1 YOLOv4算法模型
YOLOv4目标检测算法是单步检测模型,能够仅通过一个CNN(Convolution Neural Network)网络直接预测目标类别概率和位置坐标,而不需要先产生候选区域的中间过程。YOLOv4网络主要由输入端、骨干网络、特征融合网络和预测头部四部分组成。其中骨干网络为CSPDarknet53,此网络借鉴了残差网络的结构,将CSPNet[13]和Darknet[14]相融合来达到快速提取网络特征的效果。CSPDarknet53由五个CSP模块组成,每个模块包含卷积层、批归一化层、Mish激活函数和X个残差模块。特征融合网络中的SPP(Spatial Pyramid Pooling)结构采用5×5、9×9、13×13三种类型的池化层来增加网络的感受野,PAN(Path Aggregation Network)结构在FPN(Feature Pyramid Netework)[15]的结构上增加了一层下采样,将深层特征和浅层特征融合,改善了浅层语义特征丢失的问题。预测头部的输出分为三个不同尺度的特征图,分别适用于大、中、小三类目标的检测。
2 改进的YOLOv4检测算法
为了提升对于小目标安全帽佩戴对象的检测,本文提出一种改进的YOLOv4算法检测模型,检测时对相关人员的“头部+安全帽”区域进行识别。为了解决小目标特征丢失问题,加入融入CBAM注意力机制进行特征增强;随后对锚点框的选择方法K-means进行改进,选择符合本文小目标数据集的锚点框;最后,对改进后的模型进行组合剪枝,在保证检测准确率的同时加快检测速度。改进后的网络具体结构如图1所示。
2.1 基于改进K-means的锚点框选择
YOLOv4网络的预测头部使用三个尺度的特征图对图像进行目标识别,每个特征图采用锚点框(Anchor Box)作为预测框,通过对其位置和大小稍微调整就能够检测出目标。因此锚点框相当于一组模板,选择合适尺寸和合适数量的锚点框有利于提高安全帽佩戴对象的检测精度。原始YOLOv4网络使用K-means对候选框进行聚类分析,得到的锚点框是基于80类不同尺度目标的COCO数据集的,然而本文的安全帽数据集多为中小目标,而且传统的K-means算法具有对初始聚类中心具有依赖性的问题[16],因此本文对K-means算法进行改进。
距离公式是对目标进行聚类的衡量标准,然而在目标检测领域,坐标代表锚点框的长度和宽度,传统的欧式距离、切比雪夫距离等不能恰当地表示对象的距离,两个对象的距离应该由锚点框和真实框(Ground Truth Box)的IOU来表示,因此自定义的距离公式见公式(1)。
其中d(box,centroid)表示锚点框到聚类中心的距离,IIOU(box,centroid)表示锚点框与真实框的交并比。
另外对于初始点的选择方法本文也进行了改进,首先任选一个锚点框作为聚类的中心,然后计算每个锚点框和当前聚类中心的距离,用D(x)表示,每个锚点框被选为下一个聚类中心的概率为D(x)2/∑D(x)2,每轮计算结束后按照轮盘概率法选择下一个聚类中心,直到选出指定数量的聚类中心,然后进行聚类计算。
2.2 CBAM注意力机制
注意力机制是通过对神经网络层分配不同的权重,来减弱无关信息的干扰,进而实现对于重要特征信息的提取。由于实际工厂环境中冗余信息过多,小目标语义信息在下采样过程中逐渐减弱,容易造成漏检,因此本文引入注意力机制对小目标特征进行提取。单独的通道注意力机制[17]对于特征的筛选加权仅限制于单维度,对于检测准确度的提高具有一定的局限性,而由Woo等人提出的CBAM(Convolution Block Attention Module)[18]注意力机制融合了通道注意力和空间注意力,更加关注目标位置特征,能够较好得保留图像中的有效信息。
通道注意力模块(Channel Attention Module, CAM)主要关注通道特征,模块输入为h×w×c的特征图,其中h、w、c分别表示特征图的长度、宽度和通道数。对于输入的特征图,首先进行最大池化和平均池化操作,得到两个1×1×c的特征。然后将两个特征图输入拥有共享权重的多层感知机(Multi-Layer Perception, MLP)中,多层感知机包含两层全连接层,第一层输出的神经元个数为c/ratio,其中ratio表示衰减因子,第二层输出神经元个数为c,经过多层感知机得到的两个特征图求和后与Sigmoid函数做运算,得到通道注意力权重值。空间注意力模块(Spartial Attention Module, SAM)主要关注空间位置信息,通道注意力权重值和原始特征图做乘法作为模块的输入,然后经过最大池化和平均池化操作,对得到的特征进行拼接得到h×w×2的特征。特征图随后使用大小为7×7的卷积层进行卷积运算,并与Sigmoid函数做运算得到空间注意力权重值。最终通道注意力和空间注意力权重相乘得到特征增强图,整体流程图如图2所示。
本文根据YOLOv4的结构,设计实验对CBAM模块嵌入的位置进行研究。注意力机制能够嵌入骨干网络、特征融合网络和预测头部三部分的特征融合区域中,第一种方式是嵌入到骨干网络Backbone中,在模型的初始阶段,模块主要提取通用特征,如果在前面部分加入CBAM模块会徒增计算量,因此选择在后面语义丰富的特征图中加入CBAM模块。综上,考虑在第四、五块CSPX结构中的shortcut层和route层后融入CBAM注意力机制。第二种方式是在特征融合网络Neck的每一个route层后加入,第三种方式是在每一个预测头部YOLO Head的CBL模塊前加入,嵌入方式如图3所示。
2.3 模型裁剪
施工场景的安全问题越早发现越能够减少事故的发生,因此在通过特征加强保证检测精度的同时,检测速度的提升也是重要的。本文选用组合剪枝方式对模型体量进行压缩,主要采用通道剪枝和层剪枝,通道剪枝策略是通过稀疏化训练将卷积层中不重要的通道进行裁剪,层剪枝是裁剪shortcut层相关结构来完成更大程度的参数量缩减。剪枝流程主要分为三步,首先进行稀疏化训练,然后进行组合剪枝,最后对剪枝后的网络进行微调,整体剪枝流程如图4所示。
稀疏化训练是对YOLOv4模型中的BN层进行操作,网络中的每个BN层对应一个放缩因子γ(Gamma),本文采用放缩因子作为衡量通道重要程度的标准,放缩因子γ越大,代表该通道越重要。首先,需要在原始损失函数中引入L1正则化项来对γ进行稀疏化训练,改进后的损失函数公式如式(2):
其中,第一项Tloss表示YOLOv4中的损失函数,第二项表示L1正则化项,α表示两者的平衡因子。稀疏化后的部分放缩因子的值趋近于零,这说明通道的贡献率较小,因此可以加入待剪枝队列。
第二步需要对稀疏化后的模型进行剪枝,受文献[19]的启发,本文的通道剪枝策略对其进行优化。首先将稀疏化后的放缩因子按照从大到小的顺序进行排序,然后根据剪枝率设置全局剪枝阈值u,为了防止过分剪枝,还设置了一个局部保留阈值v。当放缩因子γ小于全局阈值和局部保留阈值的最小值时,该通道可以被裁剪。如果全层的放缩因子都小于最小值时,需要保留这一层较大的几个通道。通道剪枝后进行层剪枝,主要对shortcut层前面的CBM卷积模块进行评估,评估后对各层的γ均值进行排序,然后对贡献率小的层模块进行裁剪。裁剪的参数和大小需要根据实验确定。
裁剪后的模型在精度上会有一定程度的损失,因此需要通过微调来恢复网络的检测性能。本实验中设置的warm up学习率预热策略默认对前十个Epoch进行预热训练,有利于YOLOv4网络的性能恢复。
3 实验结果与分析
3.1 实验环境和数据
本实验训练使用Linux16.04系统,采用深度学习框架Pytorch,实验环境为Intel(R) Core(TM)i5-10210U CPU @ 2.11 GHz处理器,16 GB内存,NVIDIA GeForce RTX 3090 24 G GPU。
由于目前没有公开的开源安全帽佩戴检测数据集,因此本实验通过网络收集图片以及截取实际监控视频等方式,整理了一个安全帽数据集(Helmet Dataset),并通过LabelImg工具对图片进行标注。本数据集共包含5 886张图片,共包含两类目标:正确佩戴安全帽和未正确佩戴安全帽,图片覆盖不同光照、天气和尺度的情况,较贴近地拟合实际施工场景。在实验中,Helmet数据集按照8∶2的比例划分训练集和测试集,其中训练集图片4 708张,测试集图片1 178张。
实验设置图片的输入大小为608×608,初始学习率为0.002 6,权重衰减为0.000 5,动量为0.9,batchsize为16,训练200个Epoch,共73 600次迭代。
3.2 评估指标
本实验的网络性能评估主要采用召回率(Recall,R)、准确率(Precision,P)和mAP(Mean Average Precision)三项指标[20]。其计算公式如式(3)~(5):
其中,TP表示被正确识别的正类目标个数,TN表示被正确识别的负类个数,FP表示被错误识别的负类目标个数,AP为目标检测的平均精度。本文使用IOU阈值为0.5时的mAP值进行评估,即mAP@0.5。
对于锚点框的选择,合适的数量对于计算速度和准确度至关重要。YOLOv4算法采用平均重叠度AvgIOU作为聚类类簇个数的评估标准,公式如式(6):
其中,n表示聚类的总个数,k表示类簇数量,nk表示以k为中心的样本个数,IIOU(B,C)表示真实框和预测框的交并比。
3.3 实验结果分析
3.3.1 锚点框的选择实验结果
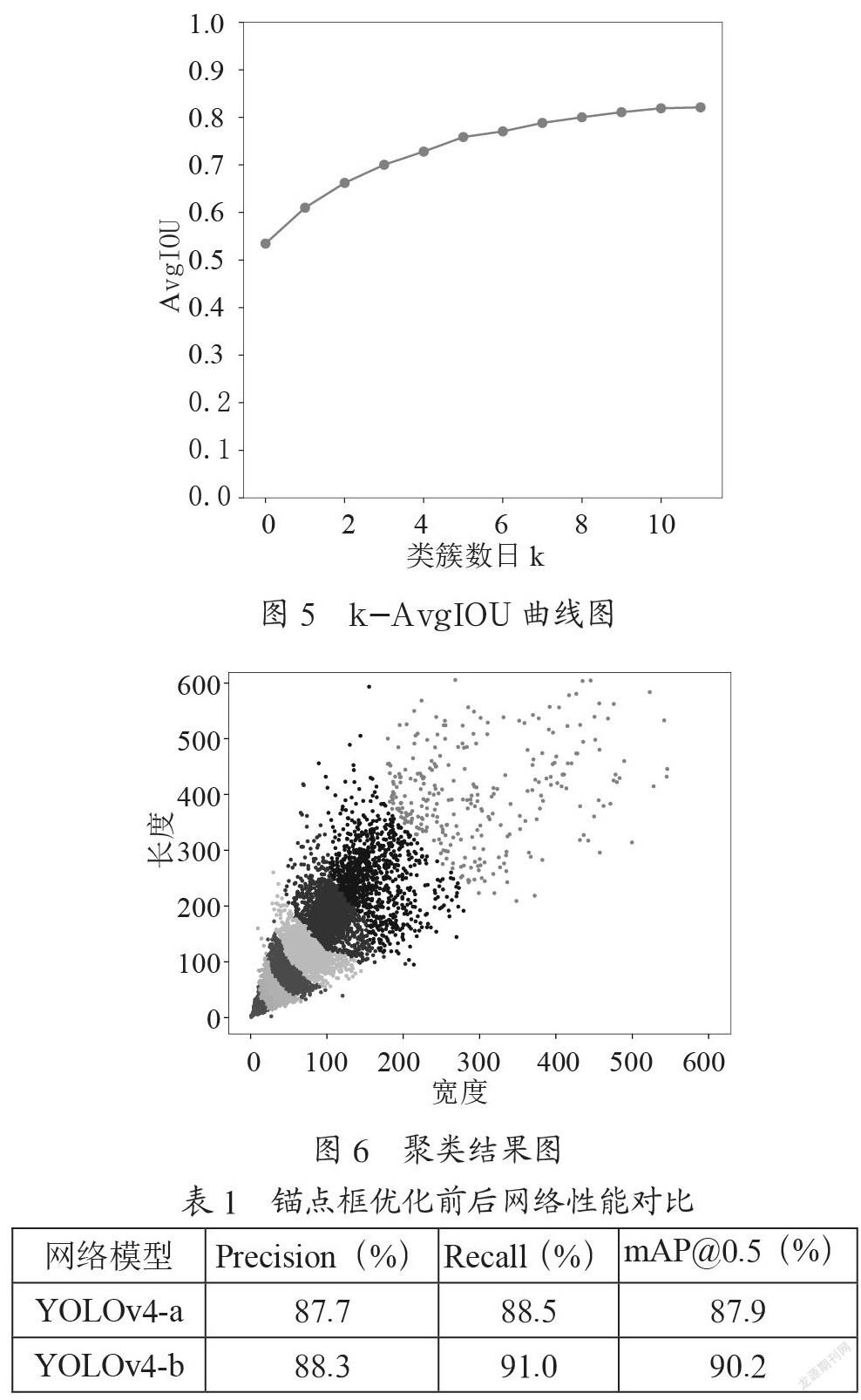
对锚点框的选择,类簇数量选取1~11,得到的k-AvgIOU曲线的结果图如图5所示。从图中可以得出结论,在k值为9之后,曲线趋于平稳,因此k值选取9,即选择9个聚类类簇中心。对锚点框进行聚类,得到的聚类结果如图6所示。图中标星的位置为聚类中心即为锚点框的大小,其宽度和长度分别为(8,17),(12,25),(19,35),(30,51),(45,76),(68,115),(99,178),(158,254),(293,398)。
实验对比了重新选择的锚点框和原始锚点框对于安全帽检测的性能变化,在数据集Helmet上,YOLOv4-a表示基于原始锚点框的检测效果,YOLOv4-b表示锚点框优化后的检测效果,主要对比准确率Precision,召回率Recall和mAP@0.5三个指标,实验结果如表1。通过结果可以看出,使用优化后的K-means算法选择适合数据集的锚点框,网络检测准确率有所提升,其中mAP@0.5提高了2.9%。
3.3.2 融合CBAM模块的模型实验结果
对于输入的图像首先使用Mosaic数据增强对数据集进行丰富。Mosaic方法是对四张图像进行旋转、裁剪、拼接等操作后拼接起来形成新的图像,目的是促进模型对于小目标特征的学习。在数据增强后,采用改进后的YOLOv4网络对目标进检测。根据2.2节的设计嵌入方式,实验测试了CBAM模块融入网络不同位置的表现性能,主要嵌入网络的Backbone层、Neck层和YOLO Head层,在Backbone层中,设计CBAM嵌入到第四个残差模块中、第五个残差模块中和第四、五个残差模块中三种情况,分别用YOLOv4-Backbone-a、YOLOv4-Backbone-b和YOLOv4-Backbone-c表示,实验结果如表2所示。
通过表可以看出,在骨干网络Backbone中融入CBAM注意力机制能够提升网络的检测性能,其中在第四个残差模块中加入CBAM模块比另两种嵌入方式检测效果好,mAP@0.5值相对于YOLOv4网络提高4.9%。将CBAM模块融入特征融合Neck模块和预测头部YOLO Head模块中后,网络的检测精度有所下降,mAP@0.5值分别下降了1.1%和0.6%。实验结果表明,在网络的浅层模块中,部分小目标特征在网络学习过程中丢失,而CBAM注意力机制能够对这些丢失特征进行信息增强,因此提升了网络的检测精度;而在网络的深层中,特征提取的语义信息比较丰富,此时再加入注意力模块会造成网络学习偏移。因此,本文最终选取在骨干网络的第四个残差块的shortcut层和route层后融入CBAM注意力模塊。
3.3.3 模型剪枝的实验结果
经过上述正常训练实验后,对BN 层的放缩因子进行稀疏训练,然后设置裁剪比例和层数,实验设置裁剪率为40%、45%和50%,设置剪枝层数为12,实验结果如表3所示。通过实验可见,随着裁剪率的升高,模型的参数量逐渐减小,检测速度逐渐提升,然后随之带来的是精度的降低。从40%的裁剪率到45%,参数减少的多一些,精度有所下降,当剪枝率达到50%时,虽然FPS有所提升,但是mAP@0.5值下降的过多。因此本文选取45%的裁剪率,通过裁剪,网络减少了48%的参数量,模型识别速度加快了35%。通过微调,最终的mAP@0.5值为94.6%。
3.3.4 实验对比分析
实验将本文提出的算法和传统YOLOv3检测算法,以及文献[21]进行对比,实验结果如表4所示。通过实验可以看出,本文提出的算法行之有效,其检测精度比传统的YOLOv3网络高3.2%,比以mobileNet为框架的网络高0.8%。网络改进前后的检测效果如图7所示,可以看出,改进后的网络能够识别出远方的小目标对象,效果较好。
4 结 论
为了提升实际场景中小目标、多尺度安全帽佩戴目标的检测精度,本文提出基于改进YOLOv4的小目标安全帽佩戴检测算法,通过重新选择锚框,选择适合实际监控场景数据集的检测框。另外通过融入CBAM注意力机制模块目标信息特征进行增强,获得更为充分的语义;同时,为了得到更紧凑的网络,对整体网络进行剪枝。通过实验研究,本文提出的算法有效,相对于改进前的YOLOv4网络,算法的检测精度有所提升,同时网络参数体积缩减了,检测速度也更快了。
对于佩戴安全帽行为的检测已实现,在接下来的工作中会针对检测的结果进行目标跟踪的研究,以实现对人员的安全预警,更好地实现智慧安监。
参考文献:
[1] 郝忠,魏延晓.448例建筑施工工伤事故的标准统计特征分析 [J].中国标准化,2017(2):245-247+249.
[2] CHEN S B,TANG W H,JI T Y,et al. Detection of Safety Helmet Wearing Based on Improved Faster R-CNN [C]//2020 International Joint Conference on Neural Networks (IJCNN).Glasgow:IEEE,2020:1-7.
[3] FANG Q,LI H,LUO X C,et al. Detecting non-hardhat-use by a deep learning method from far-field surveillance videos [J].Automation in Construction,2018,85:1-9.
[4] GIRSHICK R,DONAHUE J,DARRELL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[5] GIRSHICK R. Fast R-CNN [J/OL].arXiv:1504.08083 [cs.CV].[2021-09-25].https://arxiv.org/abs/1504.08083.
[6] RENS Q,HEK M,GIRSHICK R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[7] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).LasVegas:IEEE,2016:779-788.
[8] LIU W,ANGUELOV D,ERHAN D,et al. SSD:Single Shot MultiBox Detector [C]//Computer Vision–ECCV 2016.Amsterdam:Springer,Cham,2016:21-37.
[9] FANG Q,LI H,LUO X,et al. Detecting non-hardhat-use by a deep learning method from far-field urveillance videos [J].Automation in Construction,2018,85:1-9.
[10] HUANG J,RATHOD V,SUN C,et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:3296-3297.
[11] 王兵,李文璟,唐欢.改进YOLO v3算法及其在安全帽检测中的应用 [J].计算机工程与應用,2020,56(9):33-40.
[12] 施辉,陈先桥,杨英.改进YOLOv3的安全帽佩戴检测方法 [J].计算机工程与应用,2019,55(11):213-220.
[13] WANG C Y,LIAO H Y M,WU Y H,et al. CSPNet:A new backbone that can enhance learning capability of CNN [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops(CVPRW).Seattle:IEEE,2020:1571-1580.
[14] REDMON J,FARHADI A. Yolov3:YOLOv3:An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].[2021-10-25].https://arxiv.org/abs/1804.02767.
[15] LIN T Y,DOLLÁR P,GIRSHICK R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:936-944.
[16] 蔡畅.基于改进K-means的K近邻算法在电影推荐系统中的应用 [J].电子技术与软件工程,2020(18):182-183.
[17] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-Excitation Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011-2023.
[18] WOO S,PARK J,LEE J Y,et al. CBAM:Convolutional Block Attention Module [C]//Computer Vision–ECCV 2018.Munich:Springer,Cham.2018:3-19.
[19] ZHANG P Y,ZHONG Y X,LI X Q. SlimYOLOv3:Narrower,Faster and Better for Real-Time UAV Applications [C]//2019 IEEE/CVF International Conference on Computer Vision Workshop(ICCVW).Seoul:IEEE,2019:37-45.
[20] 周志華,机器学习 [M],北京:清华大学出版社,2016:23-28.
[21] KAMBOJ A,POWAR N. SAFETY HELMET DETECTION IN INDUSTRIAL ENVIRONMENT USING DEEP LEARNING [EB/OL].[2021-09-25].https://aircconline.com/csit/papers/vol10/csit100518.pdf.
作者简介:王雨晨(1997—),女,汉族,河南洛阳人,硕士研究生在读,研究方向:大数据技术及智能信息处理;徐明昆(1963—),男,汉族,北京人,硕士研究生导师,高级工程师,硕士研究生,研究方向:软件理论与技术。
