基于改进粒子群的随机森林优化算法客户流失预测研究
2021-05-16张三妞张智斌
张三妞 张智斌






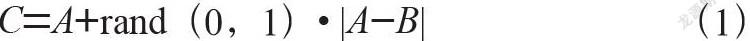



摘 要:针对客户流失在电信中检测率低的问题,文章提出了一种改进粒子群的随机森林模型。首先对数据的每个属性进行分析,选取合适的特征,再用SMOTE技术处理数据不均匀问题,然后运用决策树、随机森林、支持向量机等监督算法得出其中最优模型,其中随机森林算法最优,最后用改进PSO算法中的惯性权重和学习因子优化随机森林的参数。经实验验证该模型比随机森林和粒子群优化后的随机森林数据要高,准确率高达91%,召回率高达95%。
关键词:客户流失;随机森林;粒子群算法
中图分类号:TP18 文献标识码:A文章编号:2096-4706(2021)22-0075-04
Abstract: Aiming at the low detection rate of customer churn in telecommunications, this paper proposes a random forest model based on the improved particle swarm optimization. Firstly, each attribute of the data is analyzed, the appropriate characteristics are selected, and SMOTE technology is used to deal with the problem of uneven data. Then, the optimal model is obtained by using the supervision algorithms such as decision tree, random forest and support vector machine, in which the random forest algorithm is the best. Finally, the parameters of random forest are optimized by using the inertia weight and learning factor in the improved PSO algorithm. Experiment results show that the effect of the model is higher than random forest and random forest optimized by improved particle swarm optimization, the accuracy is up to 91%, and the recall rate reaches 95%.
Keywords: customer churn; random forest; particle swarm optimization
0 引 言
電信公司通常将客户流失作为一个关键的业务指标来预测离开电信服务提供商的客户数量,直接影响到服务提供商的竞争力。客户流失是指客户离开服务提供商的比例,又因为获取新客户的成本既高又难,保持已有顾客的成本远远小于赢得新顾客的成本,因此对于给定的特定参数,顾客是否会流失变得尤为重要。国内外有大量的文献研究了客户流失预测,研究领域涉及极广,主要包括电信[1]、银行[2]、超市[3]以及游戏客户的流失等。客户流失预测经过多年的研究,客户流失预测研究领域取得了诸多成果。客户流失的现有算法主要可分为四种:基于传统统计学方法、基于人工智能、基于统计学习理论以及基于集成分类器的预测算法。
电信客户流失预测包含用户属性分析、服务属性分析以及合同属性分析特征。大部分是一些高维数据集,在数据的特征选择上,主流方法主要有:肖进等提出了一种集成的模型,这种模型将Bagging集成学习、半监督学习和元代价敏感学习等技术结合,提出了代价敏感的客户流失预测模型[4];2019年王泽宇为了提升客户流失预测效果,利用粒子群优化算法分别优化贝叶斯和BP神经网络算法,构建客户流失预测模型,对电信客户进行分类预测[5]。本文重点阐述了改进粒子群算法中的惯性权重和学习因子优化随机森林中的参数,达到提高准确率和召回率的目的。
1 改进粒子群的随机森林优化算法
基于改进PSO的RF优化算法,本文选用Kaggle网站上电信客户流失的公用数据集,首先对数据集进行特征提取,接着用合成少数类过采样技术SMOTE(Synthetic Minority Oversampling Technique)处理数据不平衡,然后对处理好的数据运用逻辑回归、支持向量机、随机森林、K近邻、AdaBoost以及Bagging算法对客户流失进行初预测,选取其中最优的一个算法,接着用改进的粒子群对该算法进行优化,得到最终模型,最后对该模型进行评估。具体流程如图1所示。
1.1 数据不平衡SMOTE算法
合成少数类过采样技术SMOTE(Synthetic Minority Oversampling Technique)用于处理数据类别不平衡问题(Imbalanced class problem)[6],是传统随机过抽样计算的一种改进方法,具体如式(1):
A-B为二者间的欧式距离,rand(0,1)为随机在0~1之间取值。C为新的样本。
1.2 随机森林算法
随机森林是一种集成算法(Ensemble Learning)[7],它隶属于Bagging类,随机森林能够获得如此了不起的成就,关键是因为“随机”和“森林”,一种使其拥有抗过拟合,一种则使其变得更为准确。
随机森林算法可以对特征进行打分,为此我们可以评判特征的重要性,我们可以将特征变量重要性评分(variable importance measures)用VIM表示,用G表示Gini指数,假设有m个特征X1,X2,X3,…,Xm。需要计算每一个特征的Gini指数评分,也就是第j个特征在RF所有决策树中节点分裂后不纯度的平均改变量。Gini指数的计算公式如式(2)所示:
其中,K表示类别有K个,Pmk表示节点m中类别k所占的百分比。
直观地说,是指随便从节点m随意选取二个样本,其类型标志为不相同的概率大小。特征Xj在节点m的重要性,即节点m分支前后的Gini指数变化量为
其中,Gl和Gr分别代表了分支后的二个新节点的Gini指数。
最后,再将所求的重要性评分做个归一化处理。本文中得到的特征重要性如图2所示。
从图2可看出,tennure和MonthlyCharges的重要性最高,其他特征一次递减,由此可选取特征重要性打分高的作为选取的特征,其他特征则舍弃,以提高客户流失的准确率和召回率。
1.3 改进PSO对随机森林进行优化
PSO算法不仅具有规则简单、容易快速实现、参数小且用户无须直接获得离散梯度优化信息的三大特点[8],在用于进行连续离散梯度优化和进行连续性离散优化的各种问题分析中都同样可以同时取得良好的优化效果,PSO算法容易陷入早熟和局部最优的问题[9]。为避免陷入这些问题,本文从以下两个方面改进PSO:
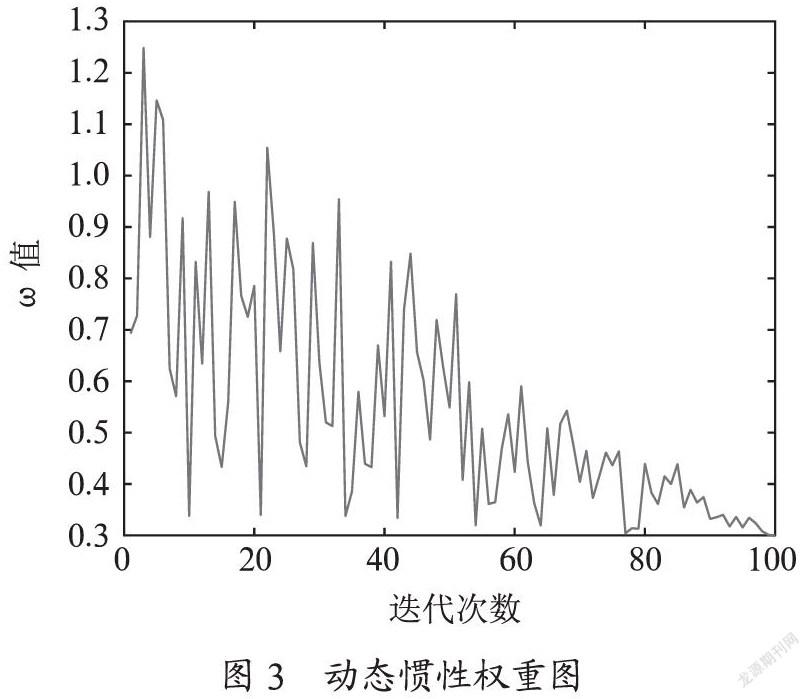
(1)引入动态惯性权重,定义为如式。
式中k代表当前的迭代数,D代表较大的迭代数,rand(0,2)代表区间[0,2]均匀分布的随机数。取ω1为0.3,ω2为1.1,迭代100次得到了如图3所示的动态惯性权重。
由图3可发现,在整体搜寻的前期,ω取大值的概率大,说明全局搜寻能力增强,而后期ω取较小值的概率大,局部开发的能力受到了加强。提高了种群的多样性,提高了局部搜索的能力。
(2)更改因子。c1、c2为提升前期全局搜寻能力,从而使搜寻后期粒子收敛为全局最优解。对因子做如下更改如式(5)所示:
式中c1i、c1j、c2i、c2j均为常数。
2 实验验证
本文使用的电信流失客户数据集来自Kaggle平台,一共提供了7 043条用户样本,每条样本包含21列属性,由多个维度的客户信息以及用户是否最终流失的标签组成,其中未流失客户有5 174人,流失客户有1 869人,客户信息具体如下:
(1)基本信息:性别、年龄、经济情况、入网时间等。
(2)开通业务信息:是否开通电话业务、互联网业务、网络电视业务、技术支持业务等。
(3)签署的合约信息:合同年限、付款方式、每月费用、总费用。
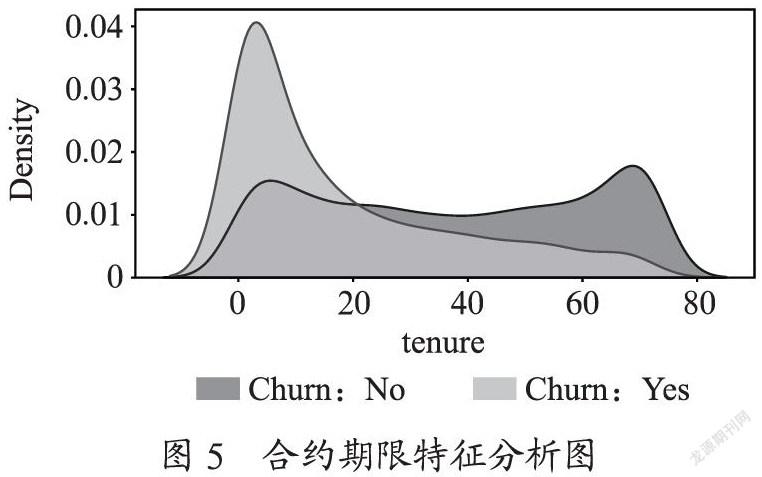
由于属性繁多,其中包括了无用的特征,需要对这些特征逐个进行分析,分析示例如图4、图5所示。
根据每一个特征的分析图分析,可以得出高流失率用户的特征为:
(1)用户特征属性:老龄使用者、未婚使用者、无亲属使用者更易丧失。
(2)服务特征属性:在网时间不足半年、有电话业务、光纤使用者、光纤使用者附加流媒体电视和电影等业务,无网络增值业务。
(3)合同特征属性:双方签订的合同期较短,使用电子支票付款,电子票据,月租费大约为70 ~ 110元的客户较易流失。
(4)其他属性对用户流失影响较小,在本文做删除处理,与以上特征保持相对独立。
对保留下来的数值型特征采用皮尔逊相关系数矩阵计算特征之间的相关性,如图6所示。
由图6可知TotalCharges与tenure、MonthlyCharges相关性较大,容易引起预测结果降低,所以对TotalCharges做删除处理。
对于电信用户流失预测问题,通常更关心真正流失的用户,因此需要寻找一个能够较好地衡量这一现象的评价指标,为此我们用精确率、召回率等来评价预测结果。
结合本文,精确率代表的意义是:在所有预测为流失的样本中,真正流失的样本数;召回率代表的意义是:在真正流失的样本中,预测到多少样本。显而易见,召回率是我们关心的指标,即宁可把未流失的用户预测为流失用户而进行多余的留客行为,也不漏掉任何一名真正流失的客户。在此依旧采取准确率、召回率以及综合两者的F1值,但关注的中重点仍然放在召回率上。
對处理好的数据用决策树(LR)、支持向量机(SVM)随机森林(RF)、K近邻(KNN)、Bagging以及AdaBoost进行分类,分类结果如表1所示。
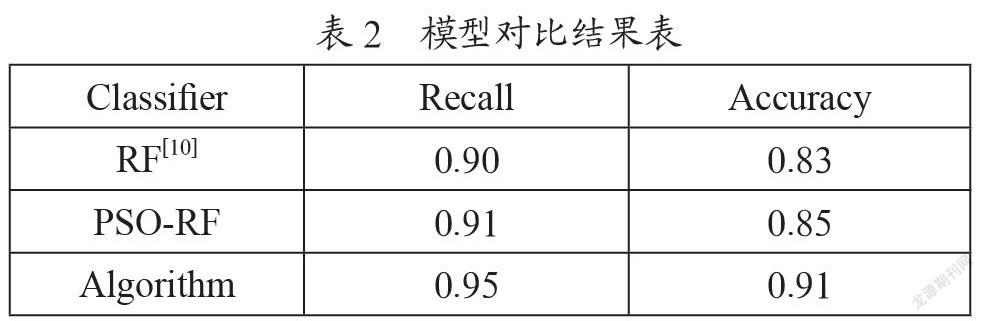
对于最优的随机森林模型,采用未改进的粒子群算法和改进的粒子群算法分别对随机森林模型优化参数,结果如表2所示。
从表2可看出本文改进过的粒子群优化随机森林的模型效果较好,相比未改进的粒子群优化随机森林准确率提高6%,召回率提高4%。相比单个随机森林模型准确率提高8%,召回率提高5%。
3 结 论
在电信客户流失中,对粒子群优化随机森林结构进行改进、优化随机森林参数等有助于提高精度。本文提出一种改进的PSO优化随机森林参数的分类算法。对电信客户流失的数据进行预测分析,与PSO-RF分类器进行对比,结果表明本文算法能提高电信客户流失的分类准确率。
参考文献:
[1] 周荣鑫,赵娟娟,靳梦华.基于贝叶斯网络的电信客户流失预测分析 [J].软件,2019,40(2):187-190.
[2] 时丹蕾,杜宝军.基于BP神经网络的银行客户流失预测 [J].科学技术创新,2021(27):104-106.
[3] HU X,YANG Y F,CHEN L H,et al. Research on a Customer Churn Combination Prediction Model Based on Decision Tree and Neural Network [C]//2020 IEEE 5th International Conference on Cloud Computing and Big Data Analytics(ICCCBDA).Chengdu:IEEE,2020:129-132.
[4] 肖进,李思涵,贺小舟,等.代价敏感的客户流失预测半监督集成模型研究 [J].系统工程理论与实践,2021,41(1):188-199.
[5] 王泽宇.基于粒子群优化算法的电信客户流失预测模型的设计与实现 [D].北京:中国科学院大学,2019.
[6] 王文博,曾小梅,赵引川,等.基于SMOTE-XGBoost的变压器缺陷预测 [J].华北电力大学学报(自然科学版),2021,48(5):54-60+71.
[7] 丁敬国,郭锦华.基于主成分分析协同随机森林算法的热连轧带钢宽度预测 [J].东北大学学报(自然科学版),2021,42(9):1268-1274+1289.
[8] 杨泽民.基于PSO的电信业数据关联规则挖掘 [J].软件,2013,34(6):44-46.
[9] XUE Z H,DU P J,SU H J. Harmonic Analysis for Hyperspectral Image Classification Integrated With PSO Optimized SVM [J].IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2014,7(6):2131-2146.
[10] BHUSE P, GANDHI A, MESWANI P, et al. Machine Learning Based Telecom-Customer Churn Prediction [C]// 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi:IEEE,2020,1297-1301.
作者简介:张三妞(1997—),女,汉族,河南周口人,硕士在读生,主要研究方向:大數据;张智斌(1965—),男,汉族,四川会理人,副教授,学士,主要研究方向:基于网络的计算机软件技术、工业控制技术。
