改进YOLO V2的6D目标姿态估计算法
2021-05-14包志强吕少卿黄琼丹
包志强,邢 瑜,吕少卿,黄琼丹
西安邮电大学 通信与信息工程学院,西安710121
6D目标姿态估计不仅需要对单幅RGB图像中的目标进行定位,还需要检测目标在三维空间中的旋转自由度。这种技术目前主要的应用有无人驾驶、机器人自动抓取、增强现实和虚拟现实等[1]。但在实际应用中,姿态估计技术遇到了很多挑战,比如有复杂背景干扰、多个目标互相遮挡以及相机成像条件不一(低光照、曝光过度以及镜面反射等)。
就目前大部分研究者的工作来看,姿态估计方法主要分为三个类别:基于关键点和模版匹配的方法、基于RGB-D的方法和基于CNN的方法。基于关键点的方法主要在局部特征上建立2D-3D 对应关系[2],然后采用PnP 算法计算6D 姿态估计参数。尽管精度很高,但不足以解决无纹理的目标姿态估计问题[3]。基于RGB-D的姿态估计方法随着商用深度相机的出现也有了很大的发展。Hinterstoisser 等人[4]提出了3D 点云的表面模版匹配,之后还提出了点对特征及其几种变体[5],以提高对复杂背景和噪声的鲁棒性。然而,这些基于RGB-D的姿态估计方法在计算上是昂贵的。
近年来,基于CNN 的姿态估计方法能得到具有高度代表性的目标检测模型。基于CNN姿态估计的方法一般有两个策略,分别是回归和映射。第一种策略利用CNN 直接产生连续的姿态参数或离散的视点。比如,deep-6Dpose[3]用来检测和分割输入图像中的目标,同时用目标的卷积特征回归6D姿态参数。SSD-6D[6]在单个阶段利用SSD 结构预测目标的2D 边界框和方向,然后根据2D 边界框的大小估计目标的深度,将输出信息从2D提升到6D。这些方法遵循基于外观的方法规则,并且通常依靠后期优化来提高姿态估计精度。第二种策略利用关键点学习和预测RGB 图像与3D 模型之间的2D-3D 对应关系。比如,由一个卷积神经网络组成的BB8[7]算法分割目标后预测目标的3D边界框映射的2D位置,然后用PnP方法计算6D姿态。该算法效果显著,但受限于方法本身多阶段的特性,导致其速度很慢。另外,在文献[8]中,CNN 会预测输入图像中3D 边界框的2D 投影位置,以减少遮挡的影响。受此启发,基于YOLO V2[9]框架,设计了一种深度卷积神经网络完成目标的6D姿态估计任务。
在这篇论文中,基于YOLO V2 框架,提出了一种单阶段、端到端的深度卷积神经网络结构,它以图像作为输入,直接检测3D 边界框顶点的2D 映射。同时,不需要细化等后处理步骤,只需训练目标的3D 边界框映射模型。在LineMod[4]和Occlusion LineMod[10]数据集上进行了测试,结果表明当处理单个目标时,本文方法的计算速度比其他方法快10 倍多,精度优于经典的姿态估计算法。
1 基于YOLO V2姿态估计算法
YOLO V2[8]算法对目标进行检测,用基于回归的方法来提取特征,是一种端到端的训练方法,它直接在特征层上回归出类别和边框,节省了大量提取边框的时间。BB8 则在目标的周围找到一个2D 分割掩模,然后将裁剪后的图像送到下一个网络,该网络预测图像中目标的8 个2D 角点。在这两个网络的基础上,本文设计了基于YOLO V2的姿态估计深度网络,用来预测目标3D边界框顶点的2D投影,然后利用PnP算法计算目标的6D姿态。
1.1 模型搭建
在预测目标的6D 姿态之前,首先需要预测目标的3D 模型在二维图像上的坐标映射[11]。9 个控制点可描述一个目标的3D 模型,包括3D 边界框的8 个角点和1个中心点。这9 个控制点保证了3D 模型在2D 图像上规则的可视化。
模型输入为单幅RGB 图像,用全卷积结构提取目标特征信息。首先把图像分成包含S×S个单元的规则网格。每一个网格都与一个多维向量关联,包括9个控制点、目标的类别概率以及总的置信度。
另外,为了保证在有目标的区域预测的置信度高,在没有目标的区域预测低的置信度,该算法还计算了预测的3D边界框与真实框的交并比得分。
本文提出的算法调整了YOLOV2 的网络结构,将原始的23 个卷积层和5 个最大池化层改成了6 个卷积块,如图1所示。第一块和第二块都是由一个卷积层和一个池化层组成,第三块、第四块和第五块都是由三个卷积层和一个池化层组成,第六块由三个卷积层组成,最后一层输出线性卷积结果,每一个块都表示一种级别的特征。该网络将提取的目标特征分成了6个级别,低层输出低级别特征,高层输出高级别特征,如图1(a)~(g)所示。所有的卷积层卷积核尺寸是3×3,步长为3;池化层采用最大池化,滤波器尺寸是2×2,步长设置为2。整个HCNN 特征提取网络只有14 个卷积层,5 个最大池化层,激活函数全部是LeakyReLU,最后一个卷积层用的是线性激活函数。
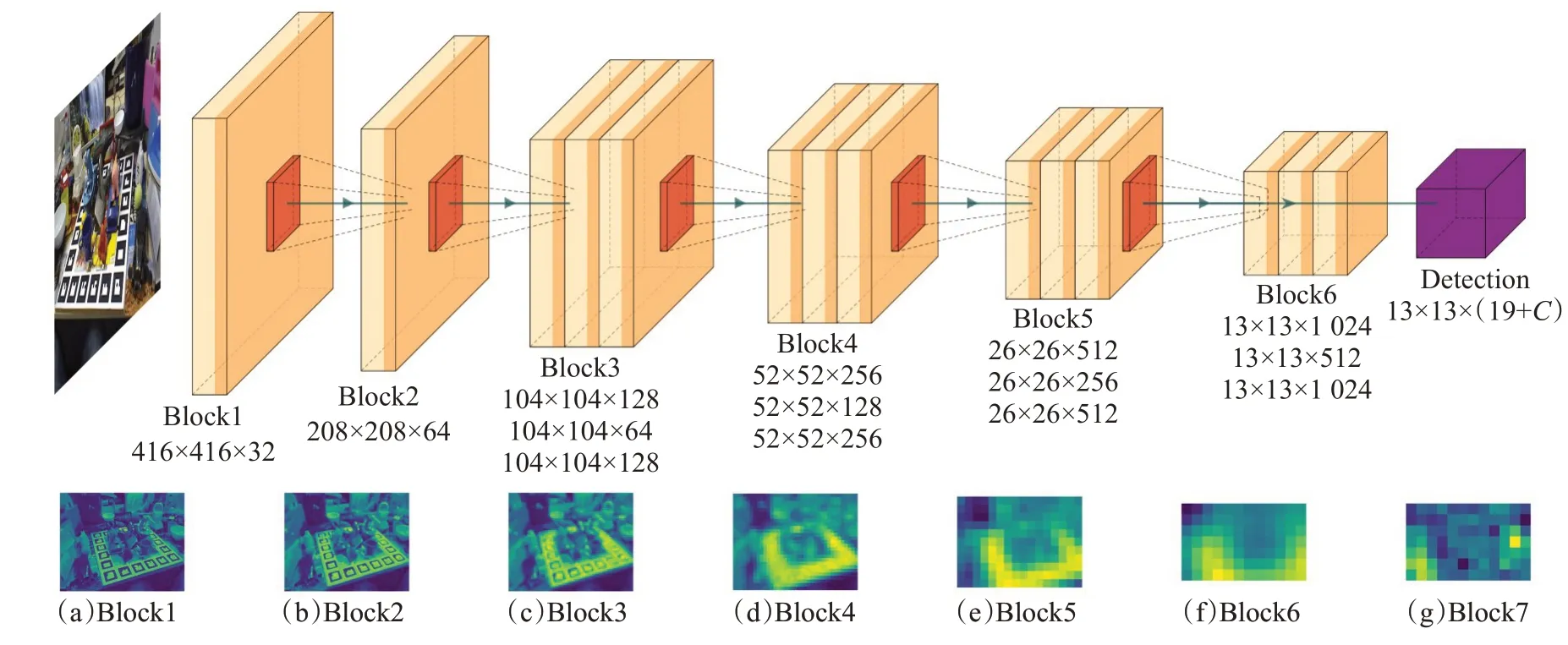
图1 特征提取网络结构
卷积层通过卷积核和非线性激活函数计算多个特征图,每个特征图表示目标可能出现的位置视觉特征。图2 中第一行至第五行表示第一个至第五个卷积块的特征图的部分输出表示,浅层卷积块提取图像的纹理和局部细节特征,深层卷积块提取图像的轮廓和抽象的全局特征。最大池化层在一个小的特征图上计算最大特征表示,最后一个卷积层的卷积核个数为19+C:9 对角点坐标,1 个置信度值,再加上C个类别。该网络的特征提取过程可以学习包含复杂背景的目标特征(高级特征表示)。
另外,在训练期间用批量归一化调整了输入图像的大小。当网络的图像下采样因子是32 时,将输入分辨率的大小改为32 的倍数{320,352,…,608},以提高对不同尺寸目标检测的鲁棒性。

图2 卷积特征图示例(从上到下依次为卷积块1~5的特征图输出结果)
1.2 损失函数
姿态估计网络的最后一层使用的是softmax 函数,输出目标类别概率,以及角点在平面上的坐标,还有整个置信度得分。训练期间,通过1.3 节构造的置信度函数计算置信度分数。最小化下面的损失函数训练网络:

其中,损失函数分别包含坐标损失lco、置信度损失lconf、分类损失lcl,用均方误差函数MSE表示坐标和置信度损失,用交叉熵表示分类损失。损失函数求和权重设计中,设置不包含目标的网格单元置信度函数的权重为0.1,包含目标的权重为5,坐标损失和分类损失函数的权重均设置为1。训练过程中,置信度损失一般从10开始下降,随着迭代次数的增加最终会下降到0.5以内。
1.3 姿态估计
通过调用一次网络进行6D 姿态估计,保证了网络的快速运行。得益于YOLOV2[8]的框架,每个网格单元可以预测该单元格内的目标姿态,如图3所示。用一个置信度阈值过滤掉低置信度的预测,对于大目标或者两个单元交叉点的目标来说,多个单元很可能都会预测高置信度的检测。因此,为了得到更稳定的姿态估计,检测有最大置信度得分的3×3邻域的单元,通过计算各个检测的加权平均来合并这些相邻单元的各个角点预测,其中加权的权重是相邻单元格的置信度分数。
图3描述了目标从平面到空间的映射关系(空间坐标轴起点为(0,0,0))。图3(1)中红色的点表示提出的方法预测的目标可能出现的质心,该点坐标所在的单元格负责预测该目标的类别概率。图3(1)是目标在三维空间的真实姿态(绿色框表示),图3(3)、(4)是网络预测结果。为了保证预测的准确度,本文基于欧氏距离设计了置信度函数c(x) ,该函数用来评估预测姿态与真实姿态之间的偏差程度。c(x) 定义如下:


图3 目标姿态映射图
其中,α表示c(x)函数的锐利程度,DT(x)表示欧氏距离,dth表示置信度函数的像素阈值。
为了预测目标3D 边界框角点的投影位置,本文提出的方法首先检测目标在图像中可能出现的位置坐标。该坐标在整幅图像的一个单元格中,负责预测目标的类别概率,紧接着根据目标的3D 模型(目标已知参数)预测对应的投影点。
网络模型输出目标的质心、3D 边界框角点的投影以及目标类别。为了进一步确定目标的6D 姿态,利用RANSAC 非确定性迭代的特性,根据网络输出结果估计6D 姿态数学模型的参数,随着迭代次数的增加产生近似真实姿态的结果。此过程不需要随机地初始化参数,只需从对应的3D 坐标集合中随机选取小的子集生成假设,对于每个假设,利用PnP算法恢复相机位姿,并将其用于计算投影误差,根据误差参数判断哪些点是内点(预测的角点中与真实姿态足够接近的点)。本文投影误差阈值为22个像素。迭代次数k计算如下:

其中,w是内点与所有点数量之间的比率,k是迭代次数,它随着子集的增加而增大,p表示要确保随机选择中至少有一个是n个无差错集合数据点的概率。本文取p=0.95。
为了得到最佳迭代次数,比较了迭代次数的期望和标准差:
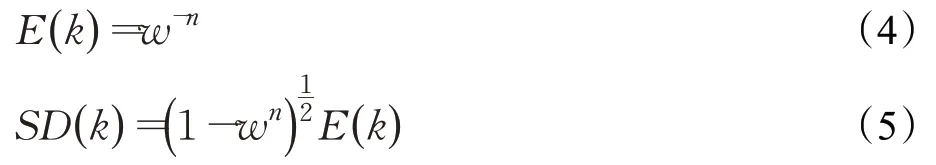
在实验中,为了保证所有预测的投影点中至少有一半的内点,设定w=9/18(18表示18个顶点),同时希望无差错的n个数据点越多越好。根据计算可得,当n=4,w=0.5 时,E(k)=16,SD(k)=15.5,它们近似相等。
2 实现细节
为了避免过拟合,在LineMod数据集中加入了其他训练图像,同时还使用了一些抖动操作,比如用1.5倍的因子随机改变图像的亮度、饱和度,用0.2的因子随机改变图像旋转角度、尺寸。用随机梯度下降方法进行优化,同时置信度函数的距离阈值dth设置为30 个像素,欧式距离指数形式中指数常数α设置为2。初始学习率为0.001,学习率分别在迭代40 000、60 000 次时分别衰减0.1 倍。为了使模型在训练过程中更快收敛,还在LineMod数据集上进行一次预训练,该预训练过程中将置信度估计设置为0。
3 实验
3.1 数据集
LineMod:这是6D 目标姿态估计的标准数据集,这个数据集包含多个姿态估计场景,比如复杂背景、无纹理目标、光照条件变化的场景。每一幅图像的中心都有一个标记了平移、旋转和类别的不同旋转角度的的目标。同时该数据集还提供了每个目标的3D 模型表示。在LineMod 数据集中一共有15 783 张图像,13 类目标,每个目标特征大约有1 200个实例。
Occlusion LineMod:这个数据集是对LineMod数据集的一个扩展,每一幅图像包含多个被标记的目标,大部分目标被部分遮挡。在实验中,Occlusion LineMod数据集仅用来测试,只用LineMod数据集进行训练。
3.2 评估指标
2D 投影指标[12]:这个指标计算的是预测的角点与真实标注角点之间的投影的平均距离。实验中,如果该距离小于5个像素,预测就是正确的。2D重投影指标定义如下:

其中,C是相机矩阵,H是需要估计的目标姿态,pi是像素i的位置,μ是像素分布的混合权重最大的平均值。
ADD 指标[4]:ADD 指标计算的是模型顶点之间3D平均距离。如果3D模型顶点的坐标与估计的坐标之间的平均距离小于目标直径的10%,预测就是正确的。该指标计算公式如下:

其中,M表示3D模型的顶点集合,p和p′分别表示估计和真实的目标姿态。
5cm5°[13]:这个指标用来估计6D 姿态估计的精度。如果平移和旋转误差分别低于5 cm 和5°,则估计是正确的。平移误差和旋转误差表示如下:
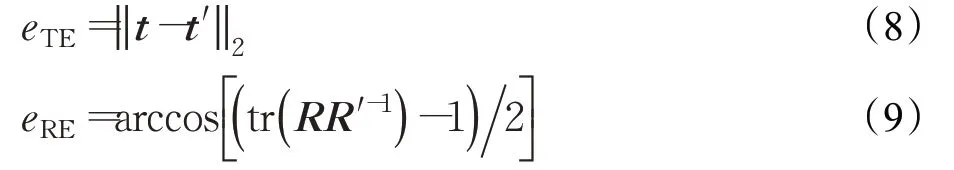
其中,t和t′分别是估计和真实的平移矩阵,R和R′分别是估计和真实的旋转矩阵。误差eRE由旋转的轴角表示的角度给出。
3.3 单目标姿态估计
本文在LineMod 数据集上进行了单目标姿态估计测试,部分结果如图4 中的第1 列和第2 列所示。最终的姿态估计结果和真实标注姿态非常接近,尤其是当数据集中包含复杂的背景和不同程度的光照时,检测性能仍然很出色。

图4 姿态估计结果图
就2D 重投影误差而言,将实验结果与当前常见的几种姿态估计方法进行了比较,如表1 所示,本文的算法表现最好,2D重投影精度达到89.27%,并且在端到端训练过程中本文算法没有细化操作,表中方法标记(R)的表示有细化过程。
就ADD指标而言,本文提出的算法仍然与BB8[7]和Brachmann 等[10]提出的方法比较,如表2 所示。即使提出的方法没有细化和预处理分割过程,但算法结果仍优于Brachmann等提出的包含后处操作的方法,其结果提高了1.32个百分点。
就5cm5°指标而言,提出的方法与Brachmann 等提出的方法相比有较大的优势,其结果提高了23.44 个百分点,精度超过64%,如表3。对于目前姿态估计的研究任务来说,这是相当不错的一个进步。
表4给出了本文方法和其他方法[1,6-8,10,14-16]的运行时间。本文提出的网络结构简单,在训练和推理的过程中大大减少了运算量。本文算法运行速度可达37 frame/s,完全可以实时运行,超过BB8算法速度10倍多,较之目前姿态估计任务有明显的速度优势。

表1 2D重投影误差%

表2 ADD测试结果%

表3 5cm5°测试结果%

表4 算法运行速度

图5 Occlusion LineMod数据集上2D投影误差随阈值变化的准确率
3.4 遮挡目标姿态估计
在图5中,本文提出的方法与其他常用的姿态估计方法[7-8,17]相比,在6个目标类别(总类别个数为13)的检测上整体性能优于Tekin 等人的方法,在10%阈值下单个类别最大的准确率高出其他算法9.14%,充分验证了本文算法在LineMod和Occlusion LineMod两个数据集上检测的稳定性。
本文还在Occlusion LineMod数据集上进行了遮挡目标的姿态估计测试,测试结果如图4第3、4列所示,其结果验证了本文算法的有效性,能够较好地估计目标的姿态。图6 给出了Occlusion LineMod 数据集中6 个类别的2D 重投影误差随着距离阈值的增加的变化趋势。从图中各类的变化曲线得出结论:大多数类别在阈值为50 个像素时,其检测精度在80%左右。值得一提的是,虽然本文的方法没有细化过程,但可以在有遮挡的数据集中取得较好的检测结果。另外,训练集中并没有包含遮挡目标的图像,说明提出的方法有较强的环境适应性。
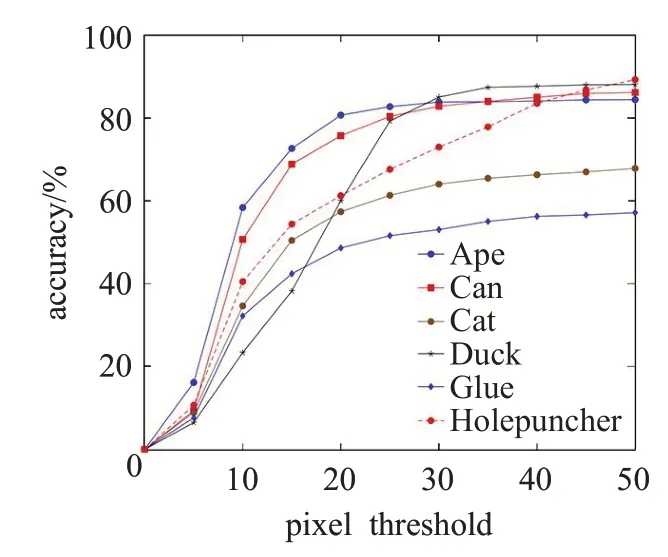
图6 在Occlusion LineMod数据集上检测精度随阈值变化结果
4 结论
本文针对三维空间中的目标6D 姿态估计问题,基于YOLO V2 深度学习框架提出了一种简单快速的姿态估计算法。该算法首先依靠卷积神经网络提取目标高维空间特征信息,然后利用目标的3D 空间模型顶点坐标得到二维平面的映射坐标,获得目标在平面上的立体表示,最后经过PnP 算法计算目标的空间姿态,确定目标姿态的粗略估计。相较于经典的姿态估计算法,本文提出的方法在精度和速度上都有较大优势,未来的研究将主要针对多目标姿态估计遮挡问题继续完善网络结构和计算过程。
