基于KNN-GBDT的混合协同过滤推荐算法
2021-05-14王永贵李倩玉
王永贵,李倩玉
辽宁工程技术大学 软件学院,辽宁 葫芦岛125105
随着互联网技术的迅速发展和网络资源的日益丰富,随之而来的海量信息超载和信息迷航等问题使得推荐系统应运而生,成为电子商务中不可缺少的工具。推荐系统作为一种可以向用户提供个性化推荐的系统,目前已被广泛应用于电子商务中用来挖掘用户日常行为数据中的隐藏商业价值。据电子商务统计,推荐系统对网上商品销售的贡献率为20%~30%。其中,协同过滤[1]是推荐系统中研究最多、应用最广的个性化推荐技术,其主要特点在于不依赖商品的内容,而是完全依赖于一组用户表示的偏好[2]。通常,协同过滤主要分为两大类,包括基于内存[3]的协同过滤和基于模型[4]的协同过滤。前者通过计算用户和物品之间的相关性,为目标用户推荐相似的物品;后者通过研究用户的历史数据,进行优化得到统计模型后推荐,而且大多数模型是机器学习模型和语言模型,如Bayes[5]、LDA[6]等。由于最近邻关系模型使用简洁方便,推荐结果直接明了,因此大多数推荐系统都采用基于最近邻关系模型的协同过滤。其中,K-最近邻模型(KNN[7])是在最近邻关系模型中使用频率最高的一个模型。
Zhang 等人[8]提出了一种KNN 和SVM 混合的协同过滤推荐算法,但因为推荐系统中数据的极端稀疏性问题,SVM分类器的分类精度并不准确。传统的KNN算法没有考虑到数据的稀疏性问题,时间复杂度高,而且只对两个及以上用户评分的物品进行分析,容易忽略一些用户的潜在信息,导致推荐精度低。此外,采用基于单分类[9]的推荐算法预测目标用户[10]的评分时,容易陷入“单指标最优”的困境。Bellkor 使用多级集成学习技术,即通过组合多种不同的推荐算法来提升推荐准确度获得了2009 年Netflix 推荐算法大赛的冠军。Freund[11]是最早将Boosting 集成学习框架应用到信息检索领域的人,但其提出的理论只能解决小规模样本集问题[12]。方育柯等人通过大规模数据实验说明Boosting 集成学习法用于推荐系统的可行性[13]。
针对存在的问题,本文结合KNN 和Boosting 算法的功能特点,提出一种基于KNN-GBDT 的混合协同过滤推荐算法。其主要贡献可概括如下:
(1)在相似度计算公式中引入只有单个用户评价的物品权重,以发现更多目标用户和物品之间的潜在信息。在相关计算中,先使用奇异值分解(SVD[14])法来减少向量的维数,缩短计算时间。
(2)采用GBDT 算法作为基本框架,利用多分类器通过集成多组推荐结果预测评分,最后为目标用户推荐预测评分高的物品。
(3)在MovieLens 数据集上进行大量实验,证明本文算法优于其他基于单分类的推荐算法,提升了推荐精度,有效解决了数据集稀疏性问题。
1 理论基础
1.1 KNN算法
KNN算法的工作原理是在计算用户(物品)相似度的基础上,来寻找相应的K 近邻集合,然后根据最近邻集合预测目标用户对物品的评分并进行推荐。
KNN协同过滤算法流程如下:
(1)相似度计算
一般而言,相似度计算分为基于用户的相似度计算和基于物品的相似度计算,常用的方法分别为Person相关性和余弦相似度。假设总共有n 个用户的集合U={U1,U2,…,Un} 和m 个物品的集合I={I1,I2,…,Im} 。根据用户-物品矩阵H ∈Rn×m,计算每个用户(物品)与另外所有用户(物品)的相似度。

其中,ru、rv分别表示用户u 和用户v 的评分向量;ru,i表示用户u 对物品i 的评分,rv,i表示用户v 对物品i的评分。
②余弦相似度(Cosine)
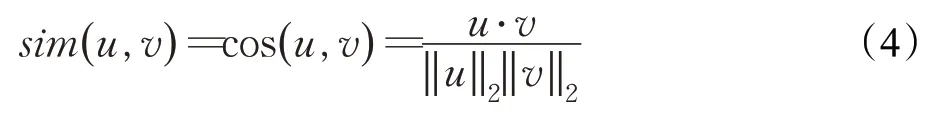
当用余弦公式计算用户(物品)之间的相似度时,将每一个用户(物品)看成一个n 维的向量,再利用上述公式进行计算。
(2)K 个最近邻的选择
在计算完基于用户(物品)之间的相似度后,选择与目标用户相似程度最高的K 个用户合并在一个集合中,这个集合就是目标用户的K 最近邻集合。
(3)预测评分
令目标用户u 的最近邻集合为N(u),然后利用目标用户的K 最近邻集合中的用户对目标用户未评分的物品进行评分,计算公式如下:
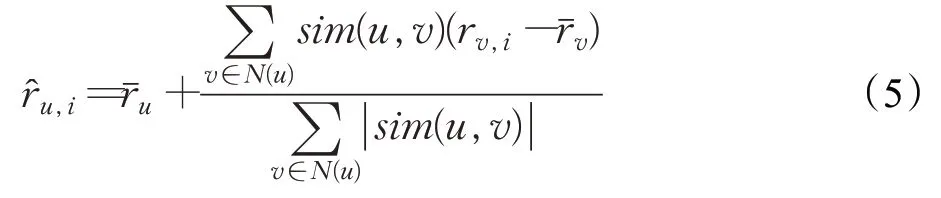
最后,筛选出评分高的物品推荐给目标用户。
1.2 Boosting集成学习技术
Booosting 算法是一种集成学习法,多级集成学习技术即通过集成多个不同的相似度计算方法来提升最终的推荐准确度。单个推荐算法容易陷入“单指标最优”的困境,而多级集成学习技术则因为这种能力,在很多领域都显示出了强大的优越性与实用性[15]。
Adaboost算法是Booosting算法的最早的一种实现版本。在算法的初始化阶段,为每个样本提供一个相等的抽样权重(一般开始时权重相等即认为均匀分布),换句话说,在开始时每个样本都是同样重要的。接下来在这些样本上训练一个分类器对样本进行分类,由此便可以得到这个分类器的误差率,根据它的误差率对这个分类器赋予一个权重,赋予权重的大小由分类器的误差率所决定,误差越大权重越小。然后针对此次分错的样本增大它的抽样权重,同时减少分对样本的抽样权重,这样训练的下一个分类器就会更加关注这些难以分离的样本,然后再根据它的误差率赋予权重,由此可见精度越高的分类器权重越大,就这样进行n 次迭代,最后得到的就是由多个弱分类器加权和的强分类器。
2 本文算法
采用Boosting 集成学习法作为本文算法的基本框架,将基于KNN 的协同过滤算法作为Boosting 算法的弱分类器进行分类。
在得到用户物品矩阵后,改进传统的基于用户相似度的计算式,引入了若只有单个用户评价的物品权重,并将改进后的相似度计算式(基于用户的皮尔逊相关性和基于物品的修正的余弦相似度)得出的多组候选最近邻居集的预测评分作为GBDT 算法的多分类器所需的预测空间进行集成。最后,筛选出评分最高的N 个物品推荐给目标用户。本文算法流程图如图1所示。
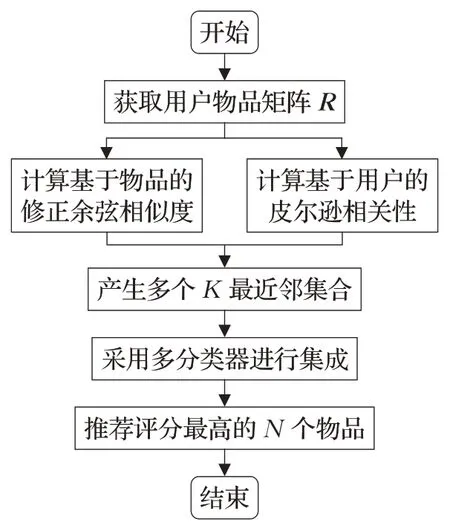
图1 算法流程图
2.1 改进的KNN相似度计算方法
针对传统相似度计算方法存在的问题,本文提出了对相似度计算改进的方法。在基于用户的皮尔逊相似度计算式中,引入了若只有单个用户评价的物品权重;在基于物品的相似度计算式中,使用了修正的余弦相关性。
2.1.1 用户相似度计算方法
使用U 代表用户,I 代表物品,假设推荐系统中有n 个用户的集合U={U1,U2,…,Un} 和m 个物品的集合I={I1,I2,…,Im} 。用户评分数据集用R 表示,Ri,j代表用户Ui对物品Ij的评分,这一评分体现了用户对物品的兴趣和偏好。
传统的KNN 相似度计算方法中,只对两个用户共同评分的物品进行分析,如果两个用户共同评分的物品数量非常少,那么计算出来的这两个用户之间的相似度会很高。但实际上,这两个用户对物品的兴趣相似度并不会很高。针对此问题,引入只有单个用户评价的物品权重。改进后的用户相似度计算式为:
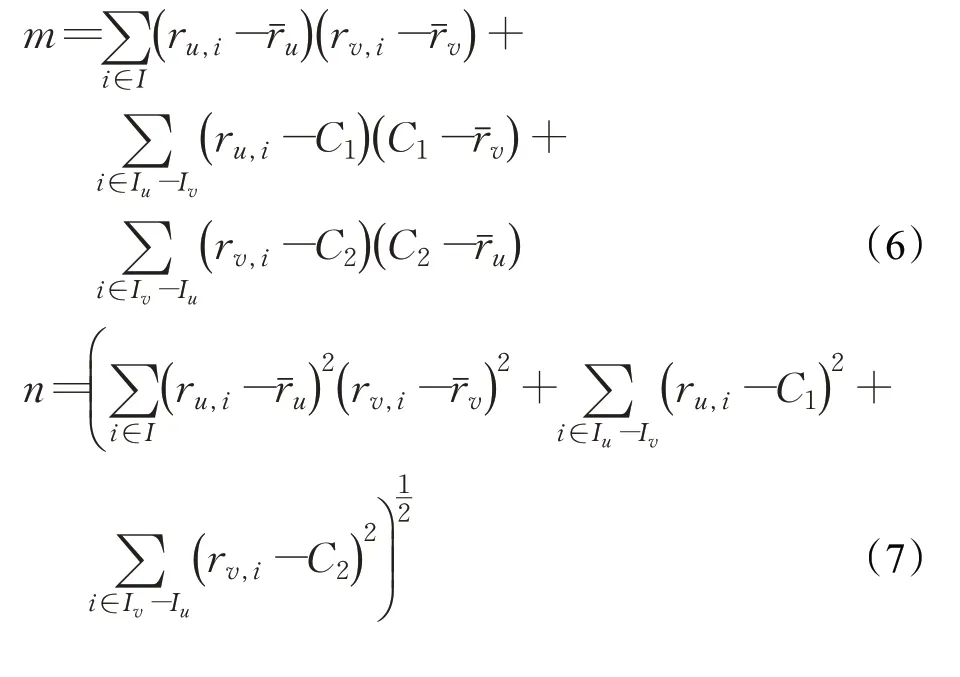

式(6)和式(7)分别在式(1)和式(2)的基础上,加入只有用户u 和只有用户v 评分的物品权重C1和C2。其中,Iu,v=Iu-Iv表示用户u 已经进行评分而用户v没有进行评分的物品。C1表示用户u 在Iu,v中对该物品的评分,C2表示用户v 在Iu,v对该物品的评分。
2.1.2 物品相似度计算方法
在余弦相似度计算式中没有考虑到不同用户的评分尺度问题,修正的余弦相关性通过减去用户对商品的平均评分来改善上述缺陷。对于物品p 和物品q,分别对应用户u 和用户v 的评分。
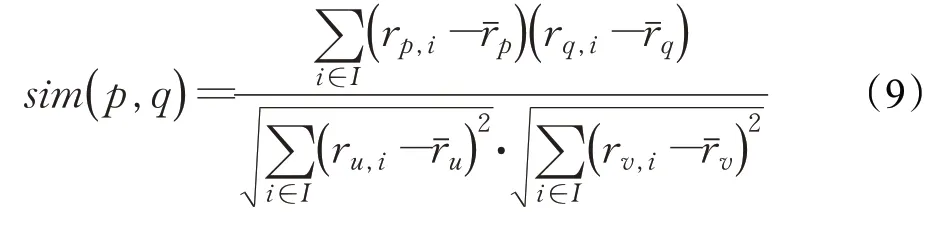
2.2 Boosting集成过程
推荐系统的Boosting 集成过程:U 代表用户集合,I 代表物品集合,Y 中1表示目标用户购买过该物品,0则表示目标用户没购买过该物品,算法最后计算的结果会将0 值变为非0 值,最后系统会筛选出得分较大的物品,并将其推荐给用户。

2.3 GBDT算法描述
如前所述,本文采用基于KNN的协同过滤算法,将改进后的相似度计算式得出的多组候选最近邻居集的预测评分作为GBDT算法的多分类器所需的预测空间,并对多组推荐结果进行集成。
GBDT算法作为AdaBoost算法的改进,由梯度提升算法和决策树算法两部分组成,其核心为减小残差,即负梯度方向生成一棵决策树以减小上一次的残差。Boosting 思想遵循的基本原则是每一次建立模型都是建立在模型损失函数梯度下降方向。如果在建立模型的时候让损失函数迭代下降,则就说明模型在不断往优化的方向上改进,GBDT算法就是让损失函数在其梯度方向上下降。决策树算法具有时间复杂度低、预测速度快等优点,但是单个决策树算法很容易因为过度拟合影响最终的分类结果。GBDT算法使用多分类器,创建数百棵树,可以最大限度减小决策树算法过度拟合的程度,而且各分类器设计简单,训练的进度也会相应加快。
对于有着N个样本点(xi,yi),计算其在候选最近邻居集模型F(x:α,β)下的损失函数,最优的参数{α,β}就是使损失函数最小的参数。其中,α为候选最近邻居集模型里面的参数,β为每个候选最近邻居集模型的权重。优化参数的过程就是所谓的梯度优化的过程。假设目前已经得到了m-1 个候选最近邻居集模型,在求第m个候选最近邻居集模型的时候,首先对m-1 个候选最近邻居集模型求梯度,得到最快下降方向。候选最近邻居集模型的最终结果依赖于多个候选最近邻居集模型结果相加。GBDT 算法多分类器集成过程如下所示:

3 实验设计
为了验证基于KNN-GBDT的混合协同过滤推荐算法的性能,将本文所提出的算法和LDA、CMF、SVD 等经典推荐算法进行比较,并对得到的实验结果进行分析。LDA将项目视为一个单词,将用户视为一个文档,由此以计算推荐物品的可能性。CMF通过同时分解多个矩阵来合并不同信息源。SVD 是基于特征的协同过滤算法。
3.1 实验准备
实验采用的是MovieLens 数据集来评价所提出算法在TopN推荐列表中的效果,其包含100 KB、1 MB、10 MB 三个规模的数据集,专门用于研究推荐技术。MovieLens 是一家电影推荐网站,该数据集由明尼苏达大学GropLens研究小组通过此网站发布。此数据集包含943位用户对1 682部电影的100 000条1~5分的评分数据,如表1 所示,取值越高代表用户对电影的评价越高。为了便于实验,对评分值进行重新标定,将1~5 的评分值转化为0~1的评分值。
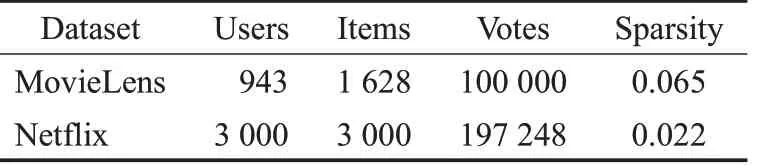
表1 实验数据集描述
3.2 评价指标
为了更加公平地评价算法性能,随机将数据集分成互不相交的两部分:训练集和测试集(比例为7∶3),进行10次划分,分别形成10组不同的训练集和测试集,然后使用用于评价TopN推荐列表的评价指标:召回率(Recall),准确率(Precision)和F1 来评估实验结果。最终的算法评价是基于这10 组训练集测试集的平均值。其中,N表示推荐列表中的物品总数,P表示目标用户在前N项中喜欢的物品数。

3.3 参数设置
在算法中,对实验结果有影响的参数有两个,第一个是在KNN 推荐算法中,计算完相似度之后选择的最佳参数K个候选最近邻居集。第二个是TopN算法的推荐列表长度,因为考虑到推荐问题的实用性,推荐列表不适宜太长,因此推荐列表的长度设置为5、10、15、20、25。
3.4 实验结果与分析
实验从最佳参数K对准确率和召回率的影响,在不同数据集上的召回率和F1,以及运行时间的长短对算法进行对比评估。
(1)最佳参数K的影响
最佳参数K控制着模型复杂度,若K值过小,即模型会过于简单;若K值过大,会产生数据拟合,导致算法在性能上受到较大影响。实验利用召回率和准确率作为评判标准来测试最佳参数K的值。本文算法将K控制在0~400来测试TopN协同过滤推荐算法,并且重复实验三次,取这三次实验得到的平均值作为最终结果,不同K值下的准确率和召回率如图2所示。通过图2 表明,K值在100~300 时性能比较稳定;当K=200时,经典的TopN协同过滤推荐算法的召回率和准确率达到最高;当K>300 后性能略微下滑。因此,基于KNN-GBDT 的混合协同过滤推荐算法取K值为200,即在协同过滤推荐算法中每一个物品的候选最近邻居集合数目为200。
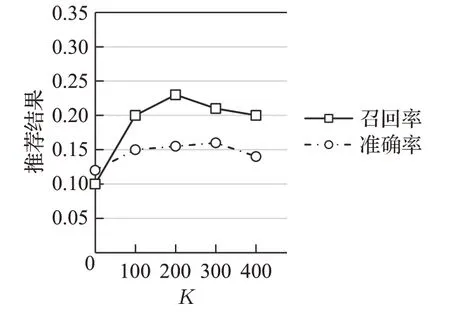
图2 在不同K 值下推荐结果的召回率和准确率
(2)不同数据集下的召回率
图3和图4表示的是四种推荐算法在数据量不同的数据集上的召回率,其中横坐标表示的是推荐列表的长度,纵坐标表示的是推荐结果的召回率,四种算法在召回率上的性能优劣如下所示:KNN+GBDT>LDA>SVD>CMF。从图3 可以看出,当推荐列表长度小于10 时,LDA 算法的召回率是高于本文所提出算法的召回率的,但随着推荐列表长度的增加,GBDT迅速上升,此时能明显看出,本文算法的召回率高于其他传统推荐算法的召回率,这说明LDA算法性能并不稳定,不太适合复杂的推荐系统。如图4所示,由于MovieLens1M中的数据量大于MovieLens100k,所以MovieLens1M 中的数据稀疏性远低于MovieLens100k,这使得模型更容易训练,因此MovieLens1M中算法的召回率低于MovieLens100k中算法的召回率。
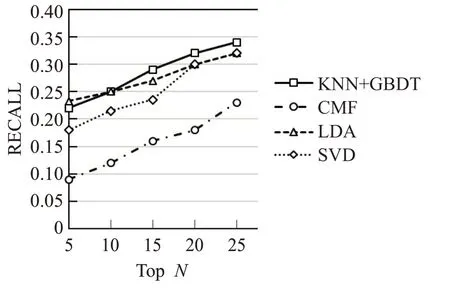
图3 数据集MovieLens100k的召回率

图4 数据集MovieLens1M的召回率
(3)不同数据集下的F1
召回率并不是唯一的评估指标,也可以使用F1 来评估四种算法的性能。其中横坐标表示的是推荐列表的长度,纵坐标表示的是推荐结果的F1,四种推荐算法在F1 上的性能优劣如下所示:KNN+GBDT>SVD>LDA>CMF。从图5 可以看出,当推荐列表长度小于10时,SVD 算法和本文所提出算法的F1 相差不大,但随着推荐列表长度的增加,准确度会增加,相应F1 也会增加,此时基于多分类器的协同过滤算法明显优于其他传统推荐算法,这说明了GBDT不仅能够在推荐列表顶端具有较高的准确率,同时在推荐列表的中间部分同样具有较大的优势。如图6所示,由于MovieLens1M中的数据稀疏性远低于MovieLens100k,因此MovieLens1M 中算法的F1 稍高于MovieLens100k中算法的F1。
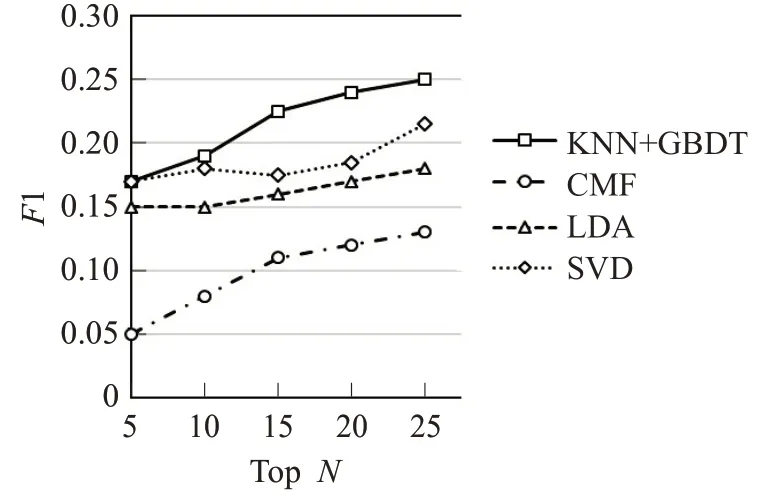
图5 数据集MovieLens100k的F1
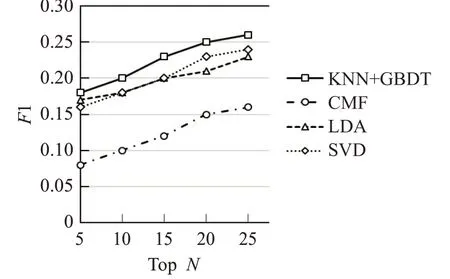
图6 数据集MovieLens1M的F1
(4)算法运行时间
实验测试了两种模型在不同模型复杂度下的运行时间,其中横坐标表示的是K值,纵坐标表示的是运行时间。在不同的K值下每个模型运行五次后取平均值,实验结果如图7 所示。从图7 可知,当K>300 时,KNN+GBDT算法具有明显的优势,运行时间较CMF算法减少很多;当K=700 时,两种算法运行时间相差了2 000 s之多,可以得出KNN+GBDT算法更适合复杂的推荐系统,同时也说明了多分类器的时间效率比单分类器的时间效率高;当K>700 时由于实验性能较差,且运行时间较长,故不做考虑。
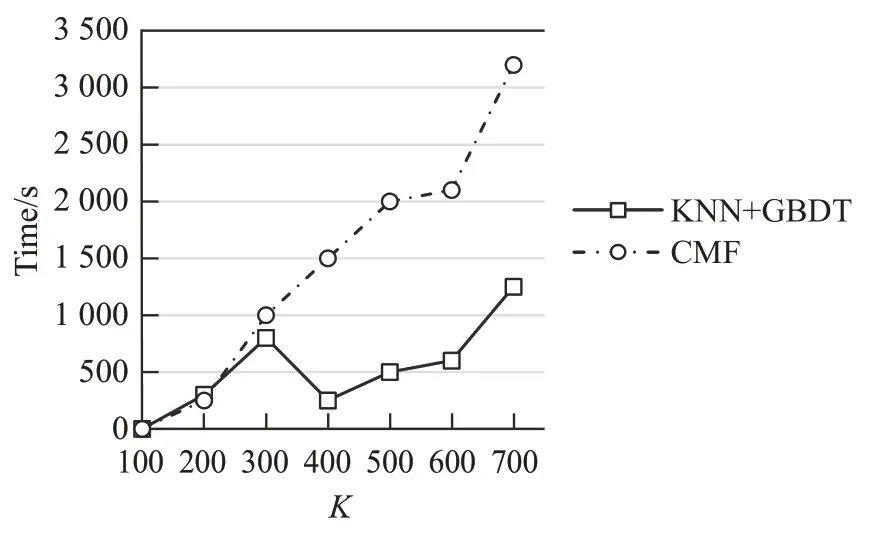
图7 不同K 值下的运行时间
4 结束语
本文旨在分析如何利用多分类器提高推荐精度,提出了一种基于KNN-GBDT 的混合协同过滤推荐算法。在传统KNN相似度计算公式中考虑了只有单个用户评价的物品的权重,得到了目标用户更多的潜在相关信息。采用GBDT算法预测目标用户对物品的评分,利用多分类器对KNN算法的多组预测结果进行集成。
在实验部分与其他传统推荐算法进行了比较。推荐结果采用的是TopN形式,即分别统计目标用户对未曾购买或者评价过的物品的兴趣度,取排在前N位的物品形成推荐集。实验结果表明,KNN-GBDT 算法其准确率和召回率不仅明显优于基于单分类器的协同过滤算法,还优于其他传统推荐算法。本文算法增加了数据预处理部分,这对于推荐算法的应用来说是一个不利因素,因此本文下一步的工作就是优化模型,改进GBDT算法,在预测目标用户对物品的评分时考虑更多用户和物品的特性,对分类器进行优化,提高训练速度。
