基于多维度上下文和双聚类的个性化推荐算法
2021-05-14李彤岩蒲江岚
李彤岩 蒲江岚
(成都信息工程大学通信工程学院 四川 成都 610225)
0 引 言
随着互联网技术的迅猛发展以及万维网无障碍的持续性发展,人类产生的数字信息量呈指数增长,人们很难在大量信息中找到真正想要的东西[1]。推荐系统(Recommended System,RS)作为一种信息过滤工具应运而生。RS帮助用户从不断增加的在线信息列表中找到所需的服务,其在缓解信息过载问题方面的有效性已被证实,并被应用于互联网中的许多领域,例如电影、音乐和旅游,用于向用户推荐合适的产品[2-3]。
RS采用各种过滤方法来提取有意义的信息,如基于内容的过滤(Content-Based filtering,CB)、协同过滤(Collaborative Filtering,CF)和混合过滤(Hybrid Filtration,HF)[4]。其中协同过滤的方法取得了巨大成功,成为个性化推荐系统中的最有前途的核心技术[5]。但是当可用的协作信息(如项目的历史评分)很少时,基于CF的推荐系统表现不佳,这称为数据稀疏问题,是许多新推出的推荐系统中最常见和最具挑战性的问题之一[6]。为了有效地缓解数据稀疏问题,需要利用有限的用户信息资源,多角度、多维度地进行分析计算和推荐。
CF的缺点之一在于其通常只考虑用户和项目两个维度中的一个,其推荐结果往往因为缺乏关联度而导致精确度下降。用户和项目这两个维度是有所关联的,因此产生了同时利用用户和项目两个维度来优化推荐结果的双聚类(Bi-clustering)的推荐算法[7-9]。研究表明,使用双聚类技术不仅可以减少利用空间,还能够有效地处理冷启动问题并提高推荐质量[8]。
用户的决策也可能会受到场景或语境的影响,例如:当人们旅行时,某些活动项目在很大程度上取决于当地的天气,而现有的CF系统通常无法模拟这种复杂的关系,也很难挖掘和利用其中的关联,所以无论是下雨还是晴天,系统都会将山地路线推荐给喜欢徒步旅行的人,从而产生推荐信息与用户决策之间的偏差。解决该问题的主要途径是在CF系统中对场景或语境建模,将用户的选择或偏好需要与用户做出该选择的上下文相关联。这意味着系统需要捕获用户点击或购买项目的当前上下文,例如用户做出选择的时间、地点等。因为推荐的质量常常随推荐调用的时间和位置不同而变化,所以时间感知CF[10]和位置感知CF[11]被提出,以提高推荐的准确性。然而,上述方法只能为对象提供客观的推荐服务,没有考虑用户的主观偏好。针对这一不足,本文研究并提出了一种基于多维度上下文和双聚类的个性化推荐算法(MCB),以满足不同用户对个性化推荐服务的需求。
1 MCB推荐算法
推荐算法的目标是根据目标用户兴趣相似的其他用户的信息,做出关于该用户所偏好的个性化预测。为了向一组用户提出有成效和高效率的建议,需要解决两个关键问题:(1) 应以非正式和准确的方式表达一个群体的偏好,所提取的偏好表示用户“兴趣”,并且确定哪些项目具有群体成员所接受的高概率。(2) 如何集成多个中间推荐列表以生成的最终结果。中间的推荐列表是针对不同的源生成的,例如不同群体的用户和上下文信息[3]。
1.1 MCB推荐框架
MCB算法的主要流程如图1所示,包括四个阶段。
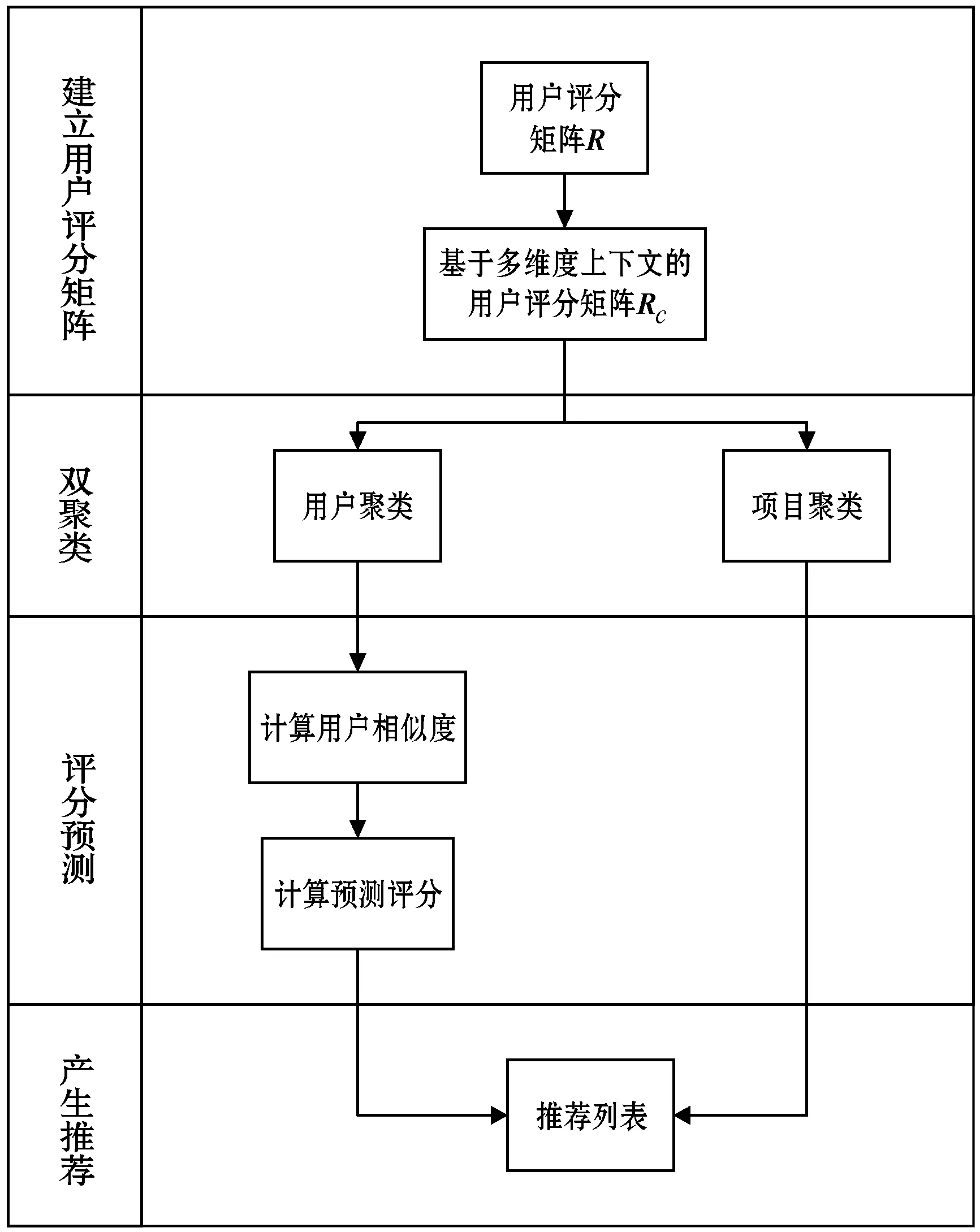
图1 MCB算法流程
1) 建立用户评分矩阵。与传统的评分矩阵建立方法不同,MCB算法不仅需要收集用户评分信息,还要收集其行为的上下文背景,以不同的上下文背景修正历史评分,建立一个基于多维度上下文的用户评分矩阵。
2) 双聚类。采用K-means聚类算法,分别对用户和项目进行聚类。
3) 评分预测。利用用户聚类找到邻居后,选择在目标用户的K个最近邻中搜索该用户可能感兴趣的项目,然后根据用户间的相似度计算项目的预测评分,再对项目的预测评分进行排序,选择Top-N个项目作为预推荐项目。
4) 产生推荐。最后将项目聚类集合与预推荐项目集合综合,生成最终的推荐列表为用户进行推荐。
1.2 评分矩阵
用户的评分数据是基于CF的推荐系统的基础资源,这意味着用户的参与对于推荐的成功至关重要。但实际上,可供推荐的总项目数比用户所经历的项目数要大得多,因此评分矩阵是稀疏的。针对这一问题,本文采用多维度上下文的算法[12]对原始评分进行修饰。
假设系统有d个上下文维度C={C1,C2,…,Cd},上下文维度之间的相似度计算式为:
(1)
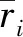
由于上下文的影响,用户的评分记录源自不同的上下文环境,可能和目标用户当前的背景存在差异,所以不同上下文背景下的评分记录与当前上下文下的用户相关程度不同。为了更好地表达用户在当前上下文下对项目的喜好,可以利用上下文维度之间的相似度来修正原始的评分数据,得到在上下文c下用户u对项目i的评分:
(2)
式中:c是目标用户所处的上下文;x是某评分记录所处的上下文;simt(c,x,i)表示项目i上下文c和x在t维度下相似度;ru,i,x是用户u在上下文条件x下对项目i的评分;k是归一化权重因子。
通过上下文的修饰计算后,建立评分矩阵:
(3)
式中:m是推荐系统中的用户总数;n是系统中的项目总数;ru,i,c是用户u在上下文c下对项目i的评分。
1.3 双聚类
寻找最为相似的邻居是CF的关键,有几种相似度量方法(余弦相似度、Pearson相关系数等)成功地解决了这一问题,但大多数相似性度量方法在寻找相似用户时往往没有考虑到用户偏好的变化结果,计算出的邻居集合在任何给定时间点不能总是反映最优邻域。无监督学习的聚类方法给寻找最优邻域带来了希望。本文采用K-means聚类算法,分别对用户和项目进行双聚类,如图2所示。双聚类算法如算法1所示。
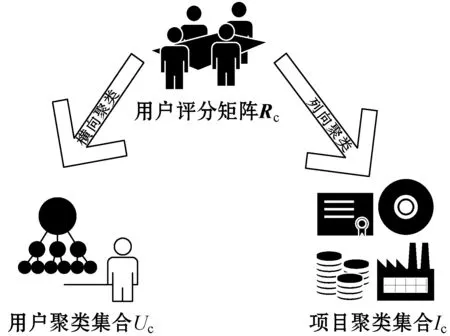
图2 双聚类示意图
算法1双聚类算法
输入:用户评分样本集U={x1,x2,…,xm};项目评分样本集I={y1,y2,…,ym};簇数k。
输出:用户聚类集合Uc={Uc1,Uc2,…,Uck},项目聚类集合Ic={Ic1,Ic2,…,Ick}。
1. 随机初始化U的k个质心向量{u1,u2,…,uk},I的k个质心向量{i1,i2,…,ik};
//用户聚类
2. Repeat
3. For eachxi∈U
4. 计算xi与各个质心uj(j=1,2,…,k)的欧氏距离,将xi划分到距离最近的质心un中,更新对应的簇Ucn;
5. End for
6. For eachUcj∈Uc

8. End for
9. Until聚类簇中元素不再分离或者达到设定的迭代次数
//项目聚类
10. Repeat
11. For eachyi∈I
12. 计算yi与各个质心ij(j=1,2,…,k)的欧氏距离,将yi划分到距离最近的质心in中,更新对应的簇Icn;
13. End for
14. For eachIcj∈Ic
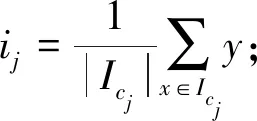
16. End for
17. Until聚类簇中元素不再分离或者达到设定的迭代次数
1.4 多维度的个性化评分预测(MPRP)
传统的项目评分预测算法以目标用户的平均项目历史评分为参考中心,再利用与相似邻居间的相似度和相似邻居的评分计算得出项目评分预测。当用户数据稀疏的情况下,如用户对许多项目都未做出评分,传统的项目评分预测算法的预测结果误差增大,精确率降低。本文以多维度上下文为基础,增加考虑用户评分的权重问题,并引入基于统计学习的系统误差因子,提出了一种多维度的个性化评分预测算法(MPRP)。
MPRP算法用式(4)来计算用户u对项目i预测的评分pu,i,引入用户评分的权重因子a,并为项目的评分分配(1-a)的权重。
(4)
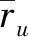
(5)
式中:ru,i表示用户u对项目i的实际评分;pu,i表示系统产生的用户u对项目i的预测评分;NI(u)表示目标用户u采纳推荐结果的项目集合I(u)的项目个数。
系统针对目标用户生成一个用户可能感兴趣的项目评分预测列表,在对目标用户推荐时对得到的项目评分预测列表中的项目评分进行排序,选取N个预测评分最高的项目为目标用户u进行推荐。
2 实 验
2.1 实验数据集及环境
CARSKit(https://github.com/irecsys/CARSKit/),是一个基于Java的开源上下文感知推荐引擎。实验采用其中的DePaulMovie数据集,该数据集包含了97位用户对79部电影的5 043条评分数据,评分等级为1到5,数据集的稀疏度约为1×5 043/(97×79)=34.2%。将数据集随机分为训练集和测试集两个部分,其中:70%的评分数据作为用户的历史评分数据,即作为训练集;另外30%的评分数据作为用户在后期的评分数据,即作为测试集。该数据集共涉及如下三个上下文维度:① 时间:Weekday、Weekend;② 位置:Cinema、Home;③ 同伴:Alone、Family、Partner。
实验采用的计算机为Windows 10 64位操作系统,内存8.00 GB,Intel®CoreTMi5-4200U CPU @1.60 GHz 2.30 GHz,集成开发环境为JetBrains PyCharm Professional 2018.2.5,开发语言主要是Python。
2.2 评价指标
1) 预测准确度。推荐的预测准确度用平均绝对误差(MAE)和均方根误差(RMSE)来衡量,计算方式如下:
(6)
(7)
式中:pi是系统对项目i的预测评分;ri是项目i的真实评分;m是观测次数。
MAE和RMSE值越小,说明算法的推荐准确度越高。
2) 覆盖率。覆盖率(Coverage)描述一个推荐系统对物品长尾的发掘能力,计算方式如下:
(8)
式中:n是系统所有的项目数目;U是所有接受系统推荐的用户;R(u)表示所有被推荐给用户的商品。
覆盖率越高,说明系统对物品长尾的发掘能力越强。
3) 新颖性。评估新颖性最简单的方法是计算推荐列表中物品的平均流行度(Popularity):
(9)
式中:I是产生的推荐列表;p(i)是项目i获得评分的数目;log[1+p(i)]则表示项目i的流行度;N是系统推荐的总项目数。
平均流行度越小,说明系统的推荐结果越新颖。
2.3 算法参数实验
为了研究MCB算法中参数对推荐性能的影响,设置两组预处理实验,分别测试用户评分权重因子a和K-means聚类的簇的数目k对推荐性能的影响。
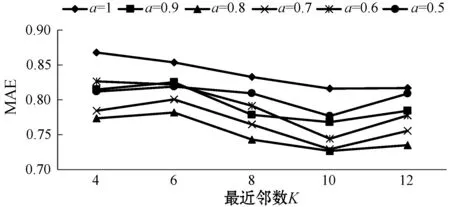
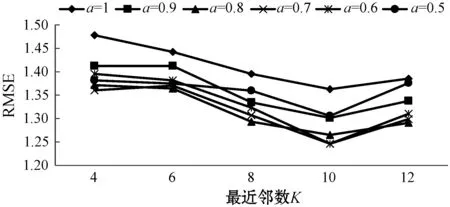
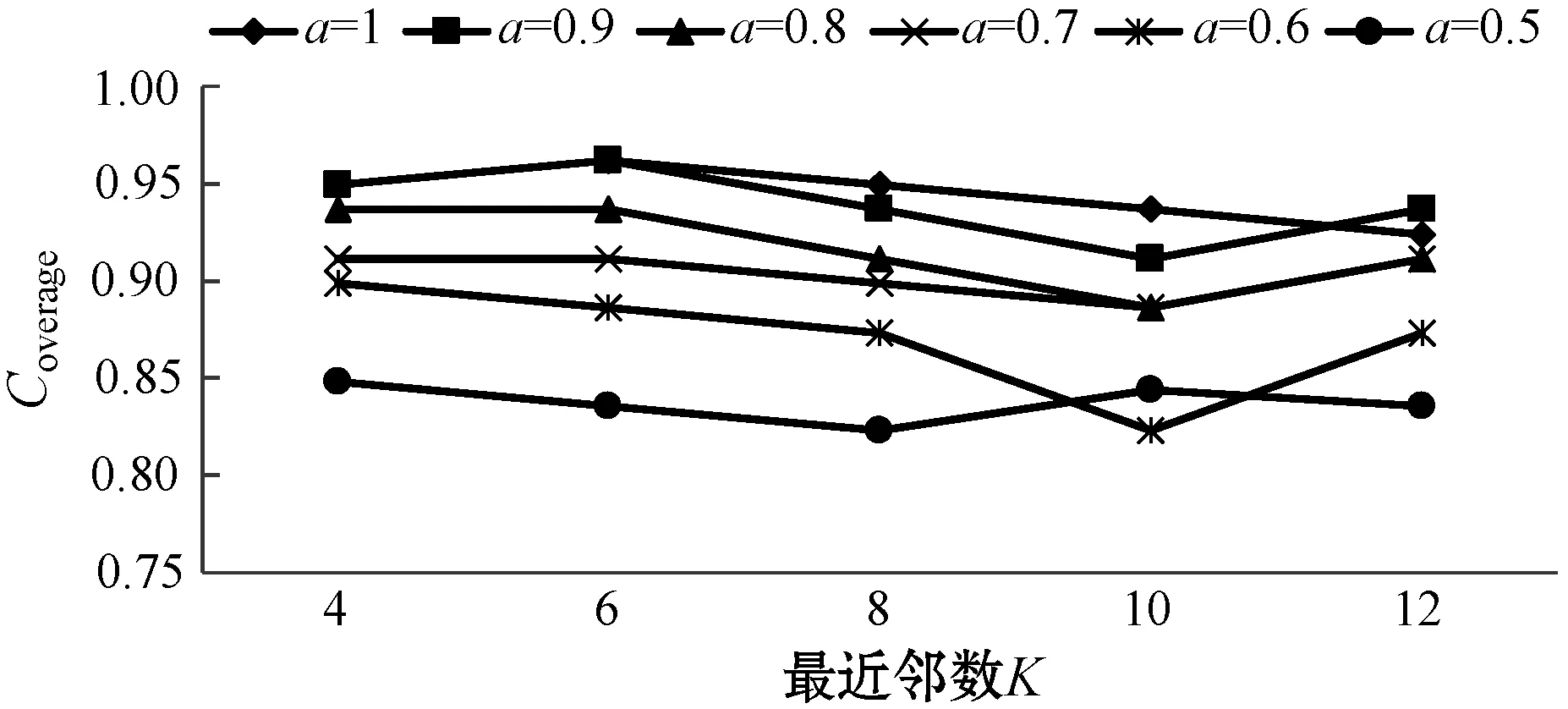
参数a的性能测试结果如图3所示。当a取0.7和0.8时,MAE和RMSE较小,推荐结果较为准确;当a取1和0.9时,Coverage较大,系统挖掘长尾物的能力更强;当a取1和0.9时,Popularity较小,推荐的新颖度更高。
(a)
(b)
(c)
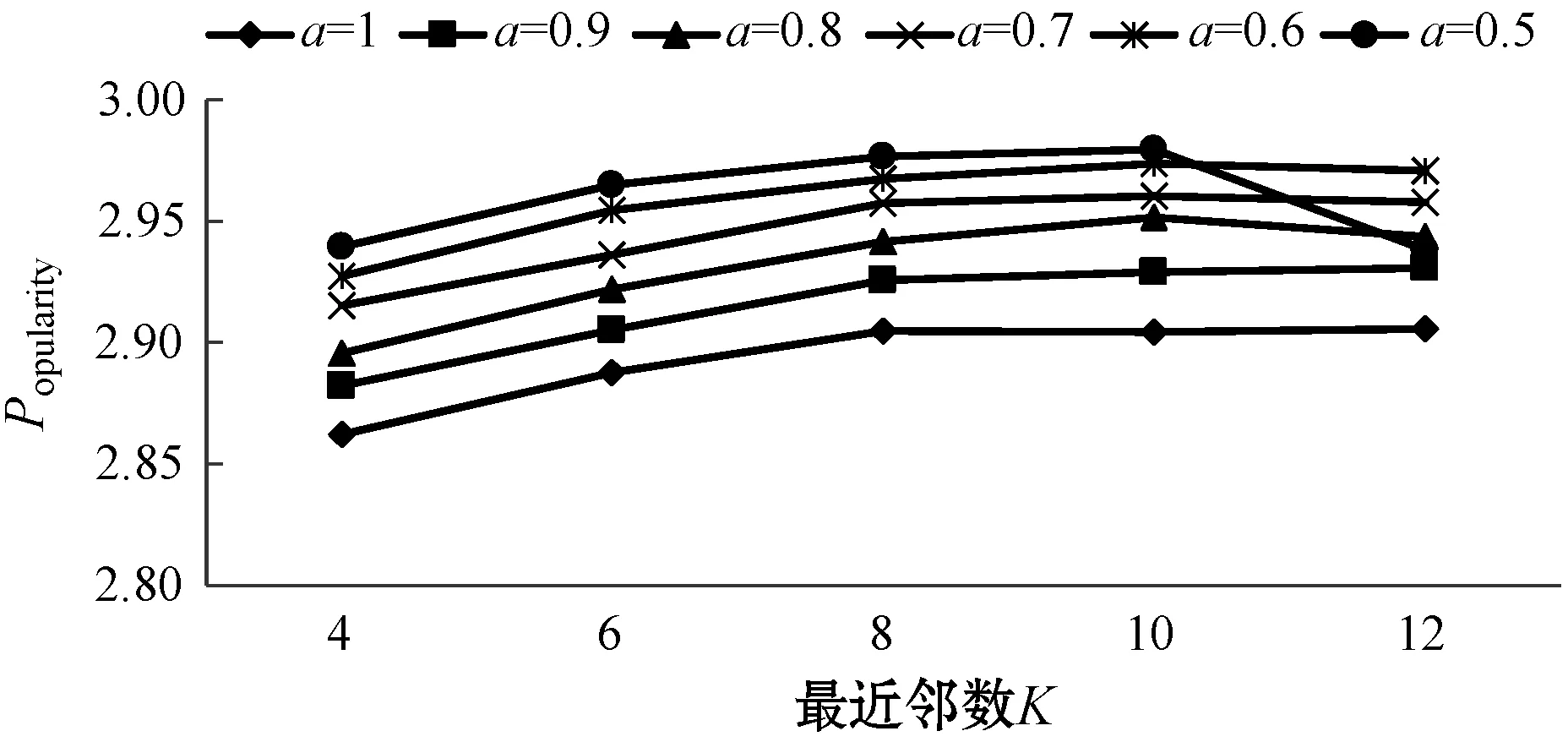
(d)图3 不同a值下的推荐性能比较
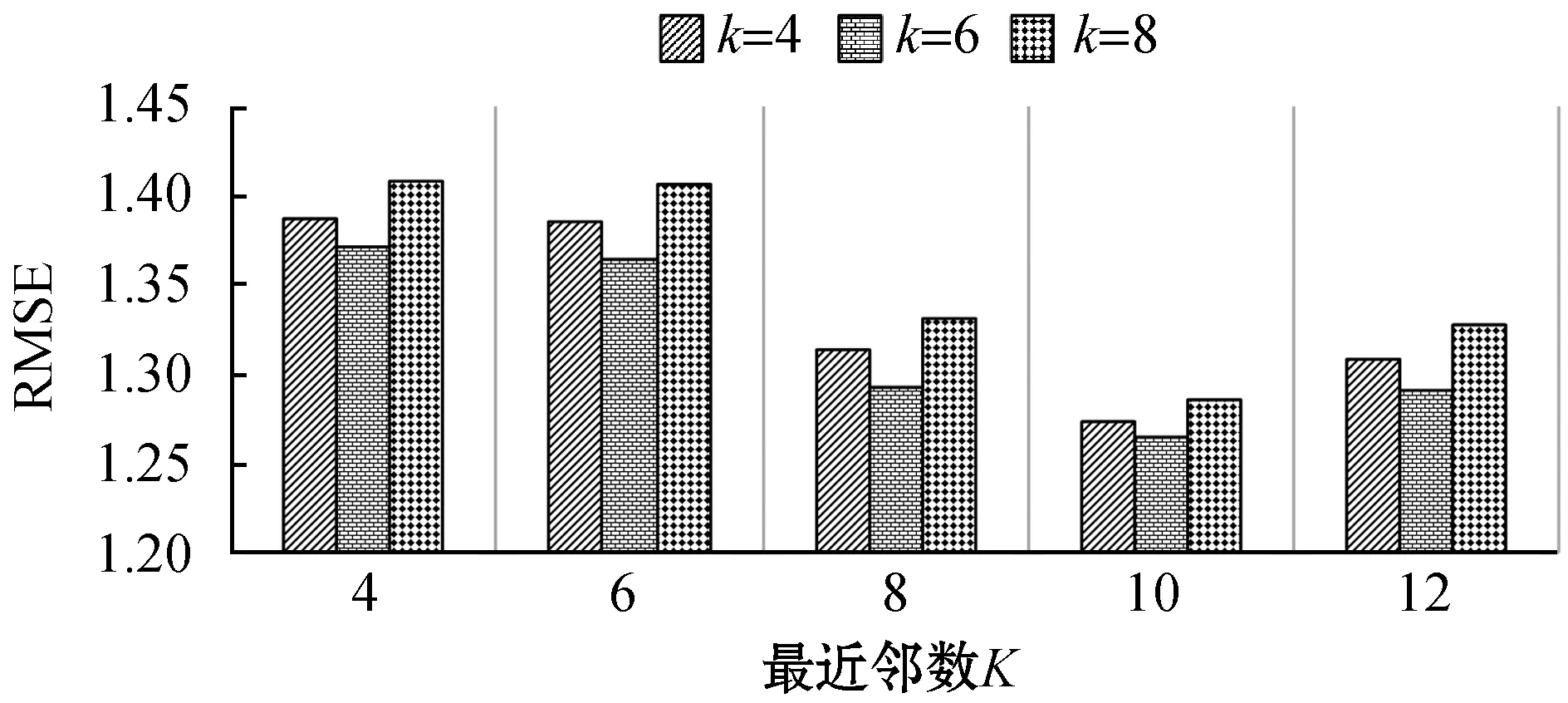
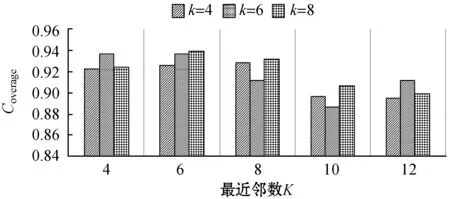
参数k的性能测试结果如图4所示。当k取6时,MAE和RMSE较小;而k在不同的最近邻数K下呈现出了不同的推荐覆盖效果,当K为4和12时,k取6的Coverage较高,当K为6、8、10时,k取8的Coverage较高;对于Popularity而言,k的取值对其并无显著影响。
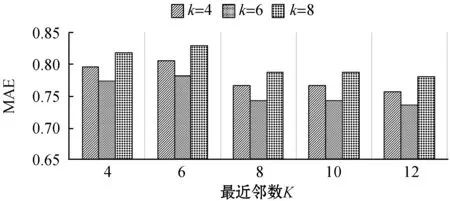
(a)
(b)
(c)

(d)图4 不同k值下的推荐性能比较
2.4 对比实验
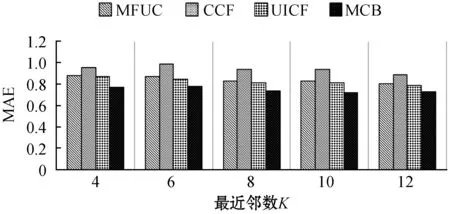
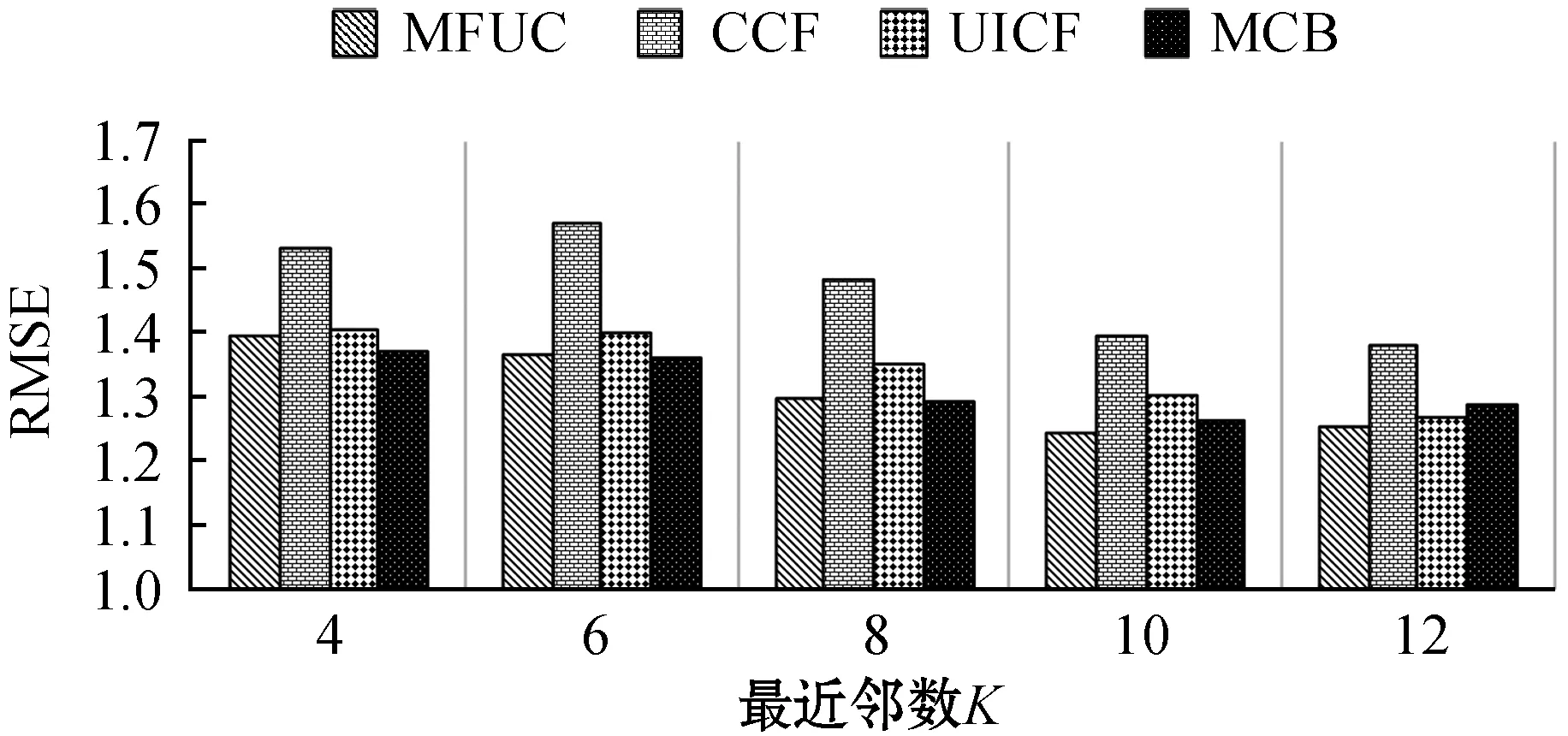
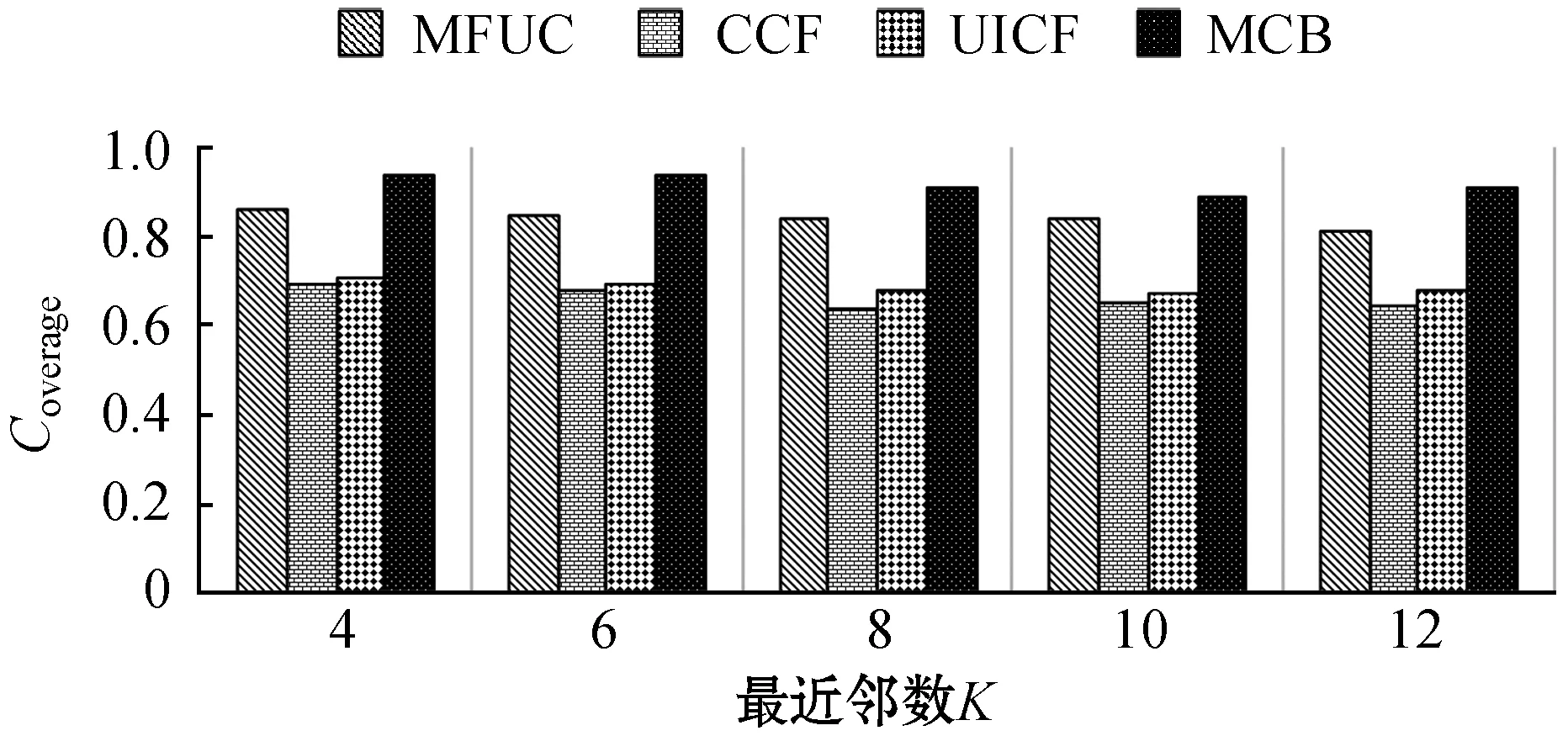
为了验证多维度上下文、用户评分权重等因素对推荐结果的影响,验证本文提出的MCB算法的推荐效果,与MFUC[5]、UICF[7]、CCF[12]三种算法进行对比实验。为了保证实验的客观可比性,项目推荐数目N定为20,即为每位目标用户推荐20个项目。为每位目标用户选择的最为相似的邻居数目K为变量,K∈{4,6,8,10,12}。为了让MCB算法性能最优,结合算法参数实验,将用户评分权重因子a设置为0.8,K-means聚类算法簇的数目k定为6。实验结果如图5所示。
(a)
(b)
(c)
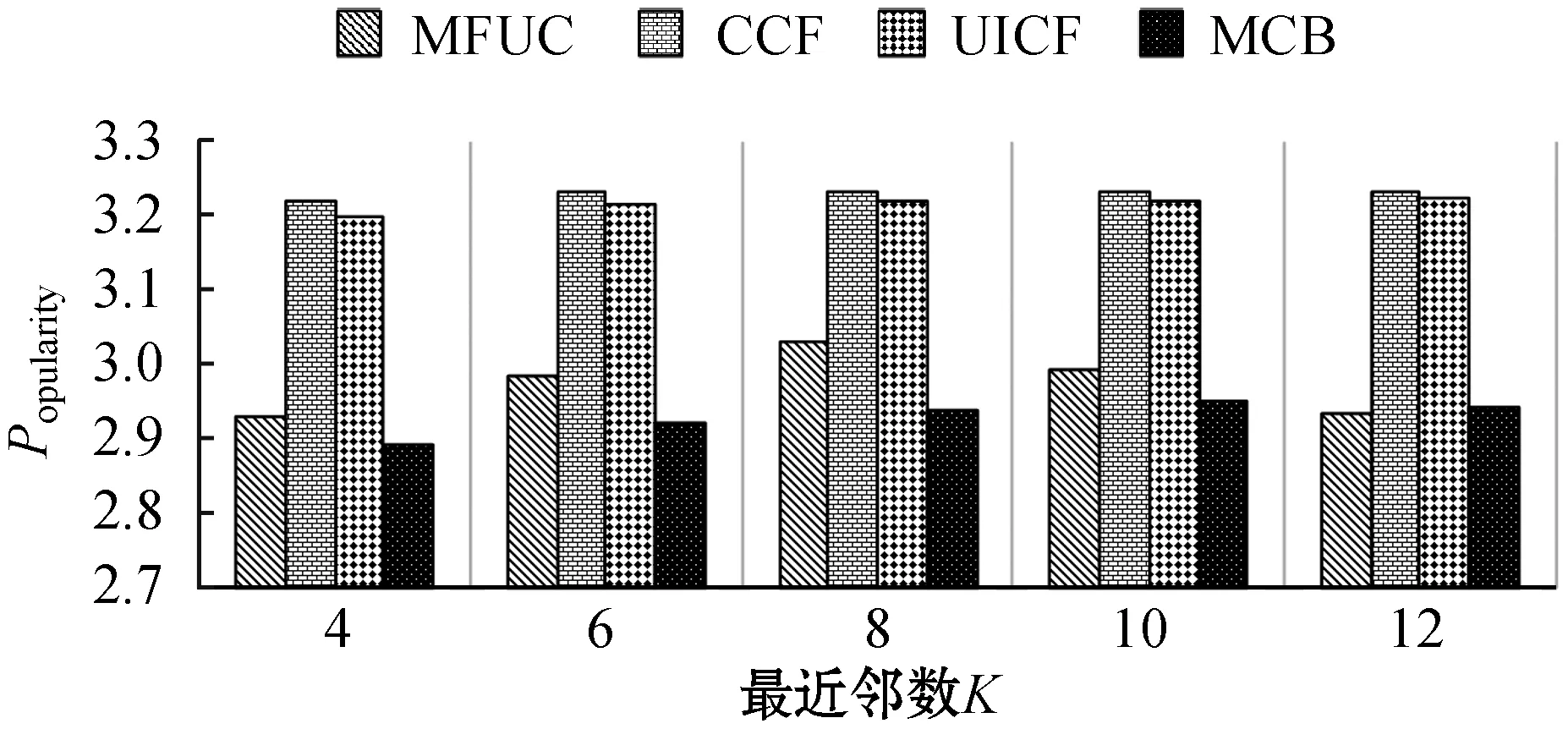
(d)图5 不同K值下四种算法推荐性能比较
可以看出,随着K值的增大,推荐算法产生的误差会降低,推荐准确性提高,但同时推荐结果的覆盖率也会有所降低。而K的取值对推荐的新颖性影响很小,这说明如果要求更加新颖的推荐服务,则需要选择推荐流行度较低的推荐算法,如MCB和MFUC[5]。从总体性能上来说,MCB优于另外三种算法,CCF[12]则最差。
此外,结合参数实验,可以看出选择正确的参数也是提高推荐准确性的关键。对于目标用户的邻居数目K、用户评分权重因子a等参数,在实际应用时,需要推荐系统在测试阶段进行对比选择合适的值。
3 结 语
本文探索了协同过滤、双聚类、多维度上下文等有关推荐系统的一些算法,研究并提出了一种基于多维度上下文和双聚类的个性化推荐算法(MCB)。MCB利用评分和上下文信息来提取用户的偏好,采用双聚类算法表达群体的偏好,有效地解决了数据稀疏问题,最后用一种多维度的个性化评分预测(MPRP)算法来生成推荐列表,提高了推荐的准确性。与传统的算法相比,MCB不仅预测更加准确,而且挖掘长尾物品的能力更强,推荐结果更加新颖。
