基于多层迭代的递归数据流匹配改进算法
2021-05-14蔡艳婧孔苏鹏王则林
蔡艳婧 孔苏鹏 程 实 王则林*
1(江苏商贸职业学院电子信息学院 江苏 南通 226001) 2(南通大学信息科学技术学院 江苏 南通 226019)
0 引 言
包匹配算法是对通过路由器的数据包进行识别,从而可以为互联网提供访问控制,提高网络服务质量以及针对不同客户要求提供差异式服务。包匹配算法本质上是一个多维范围匹配问题,根据预定义规则对进入网络或主机数据包的IP头部信息进行比较。IP头字段信息一般包括源IP地址、目的地IP地址、源端口、目的地端口和上层协议类型。每个规则还有一个行为字段,以便对符合匹配的数据包进行相应处理。一般每条规则还有一优先级。对于传入的数据包,如有多条规则与它匹配,数据包则匹配最高优先级的规则。包匹配的性能由内存消耗和内存访问的次数来衡量。
目前,不同的包匹配算法在算法的空间和时间性能之间采用不同的权衡策略。基于哈希表的算法有优越的空间性能,但其时间性能却无法得到保证[1-2]。基于决策树的算法使用决策树把规则库划分为多个线性搜索组[3-4],此算法的速度和存储性能会根据规则数据库的特点有所不同。EffiCuts使用多个决策树控制内存消耗,但也降低了算法的时间性能[5]。三元内容可寻址存储器(TCAM)广泛用于查找规则。然而,TCAM不能直接处理范围类型的规则匹配,因此需要把范围的规则转换成前缀的规则类型,降低空间效率[6]。RFC[6]是著名的高性能算法之一,其高性能保障是有条件的,通常适用于维数低、规则库规模不大的情形,否则会引起维度灾难,产生规模爆炸问题。
本文基于RFC提出一个新的包匹配算法,将规则库分割成几个规则子集,每个子集的规则存储在一个RFC数据结构中,子集的规则数量被限制在一个阈值范围内。本文提出的改进算法可以避免产生巨大空间的外积表,因此以递归的方式执行RFC,确定该访问何子集,何子集规则被匹配。另外本文还对RFC数据机构进行一些改进以提高存储和速度性能。数值实验表明,本文算法显著提高了RFC用于大规模多维规则库的可行性,同时保持了RFC算法优越的时间性能。
1 算法改进基本思想
本文改进算法的目标是提高RFC的空间效率,采用多个RFC实例。首先,本文把规则库分为几个子集,每个子集的规则存储在一个独立RFC数据结构中。每个子集由一个索引规则来进行描述,每个索引规则指向相应的RFC的数据结构。因此,如果将规则库分为k个子集,从而k个索引规则被创建。这些索引规则被存储在另一个RFC索引数据结构中,称为RFC索引,以它来确认进入网络或主机的数据包该进入哪个子集,进一步通过相应的RFC数据结构来确定具体的匹配规则。
下面举例说明对规则库分割的必要性。表1是由两个头字段组成的规则库,在源地址(SA)领域,有五个组合:0*(R3、R6),010*(R3、R4 R6),1*(R2,R6),1100(R1、R2、R6)和1110(R2、R5 R6)括号前的标识符是括号里规则的前缀匹配。在目的地址(DA)领域,有六个组合:*(R5),110*(R5,R6),1011(R1,R5),0*(R4,R5),010*(R2、R4、R5)和00*(R3,R5)。因此,两个头字段执行外积后有30个实体。执行外积得到的实体数量可以通过分割规则库来减少。图1通过几何的方法来说明这些规则分割的思想。这些规则被分为三个子集(R1,R5,R6)、(R2,R5)和(R3,R4)。每一个子集的外积实体的数量是9、4和4,从而外积实体总数减少到17。与原来相比,分割规则库可以有效降低外积表实体数目,从而提高存储效率。
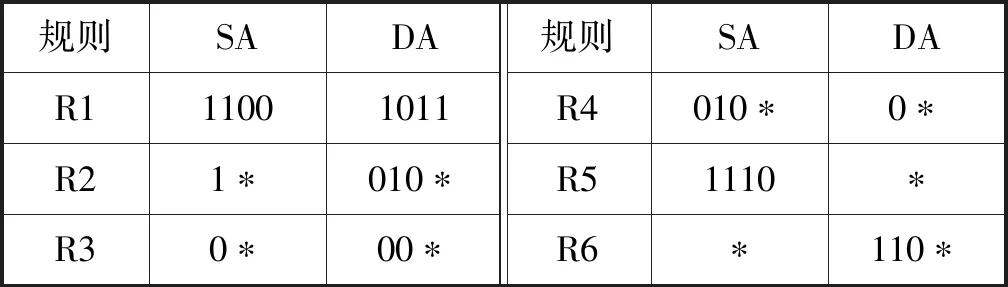
表1 简单规则库
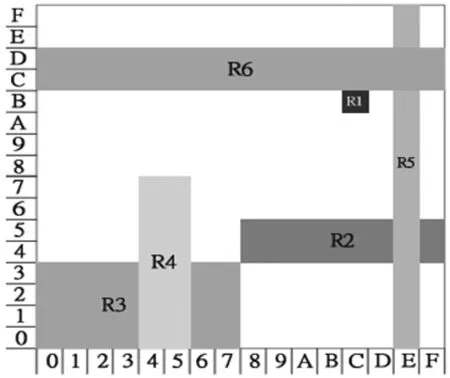
图1 对表1规则的几何描述
一个有效的分割算法应该满足以下三个要求:(1) 那些在几何描述上彼此接近的规则应该在分类上属于同一子集,以确保搜索过程能访问到所有子集;(2) 每个规则应该驻留在确切某个子集里,一个不太有效的分割算法可能导致一个规则处于不同子集;(3) 规则子集的数量应该可调节以便适应不同规则库。下面研究分析当前已有的分割规则库算法。
元组空间的思想是基于每个字段中前缀的位数把规则库分为元组。每个元组对应于一个前缀,检查所有字段的组合,以及由此产生的元组称为元组空间[6]。以一个三维元组(5,6,7)为例,属于这个三维元组的规则第一个字段是5位的前缀,第二个字段是6位前缀以及第三个字段为7位的前缀。因为每个规则只有一个前缀组合,元组空间不会违背分割的第二个要求。但这并不意味着任意前缀组合存在几何关联,所以元组空间分割的思想不能满足分割的第一个要求。由于高成本的前缀扩张也很难调整元组的数量。采用一个类似元组的思想提出了空间利用嵌套层元组,每个字段的长度定义为嵌套的数量水平相应的前缀。尽管这个算法的元组数量显著低于元组空间元组的数量,但第一个分割的要求仍不满足。贪婪算法运用外积法减少使用嵌套级别的元组数目,但是不符合分割的第二个要求,嵌套元组也不支持更新,因为插入一个规则时,新的前缀可能改变所有规则的嵌套层数。
决策树算法使用规则的字段属性将规则库分成一个个子集,当用于分割规则库的属性是字段值时,决策树提供的相同子集的规则在几何描述上相互接近,从而决策树在执行数据包匹配时只有一个子集被访问到。通过调整在一个叶节点上的规则数来控制子集的数量。然而,规则决策树算法也不符合分割的第二个要求。因通配符规范在规则库的规则描述中很常见,从而对规则库分割的几何方法只能减少规则的重复,而不能避免规则重复。一些方法被提出以减少重复规则[8],一些算法使用多个决策树来提高规则库的分割效率[9],另一些分割算法利用不同的属性划分规则集。上述方法在合理的消耗下没有一个能完全避免规则的重复问题。
与基于元组分割算法相比,使用决策树对规则库规则分割的算法只有一个规则重复问题需要克服。本文提出使用一个随需应变的方法来避免规则的重复问题,步骤如下:
(1) 生成一棵平衡二叉树,每个内部节点的关联规则被分为两个子集。在构造决策树的过程,删除任何重复规则,所有从第一个决策树删除的规则都被存储在第二个决策树。
(2) 基于第一步过程构造第二个决策树,在第二个决策树构造过程中的任何重复规则被搬到第三个决策树,如此迭代。
(3) 生成所有决策树。决策树的任一叶节点的规则被插入一个RFC的数据结构,因此,RFC数据结构的数量等于所有决策树的叶节点总数。
规则划分的详细步骤描述如下:
(1) 定义一个阈值去限制存储在一个RFC数据结构中的规则的数量,所有规则都与第一个决策树的根节点相关联。如果规则的数量大于阈值,那么把规则分为两个子集。为了对规则库进行分割,选择一个有效区分这些规则的字段。
(2) 计算规则库每个字段不同的前缀的数量,选择前缀数目最多的字段来分割。
(3) 对选定的字段,进一步确定可以将规则平衡划分成两个部分的一个点。
(4) 针对选择的字段,统计小于或等于选择点的端点规则数量,对每个端点分别统计大于选择点的起始点的规则数量。和选择点相比,数字最接近被选中。
(5) 根据选择的点,可以将规则集划分为三个子集:规则的范围低于所选点、规则的范围高于所选点和范围在选定的点的未分类的规则。
重复上述步骤,对前两个规则集做进一步划分,直到每个子集生成的规则数量小于阈值。将决策树中所有未分类的规则插入到下一个决策树的根节点进行进一步的划分。
用一个例子说明上述过程,表2所示为五个字段的17条规则组成的规则库。设置阈值为4。在分割的第一次迭代过程中,源地址字段前缀的不同数目最大,因此选择它把规则分库分成三个子集,每个子集对应于树的一个节点。如图2所示,根节点的左子节点存储规则的源地址字段低于所选点,根节点的右子结点存储较大的规则源地址字段,中间的根节点存储未分类的规则。因为左、右子节点的规则数超过4位,应该进一步分割以便生成更小的子集。决策树中所有未分类的规则(包括R15、R16、R12和R13)形成第二个决策树的根节点。由于子集的大小对应于根节点不超过阈值,第二个决策树只有一个节点。
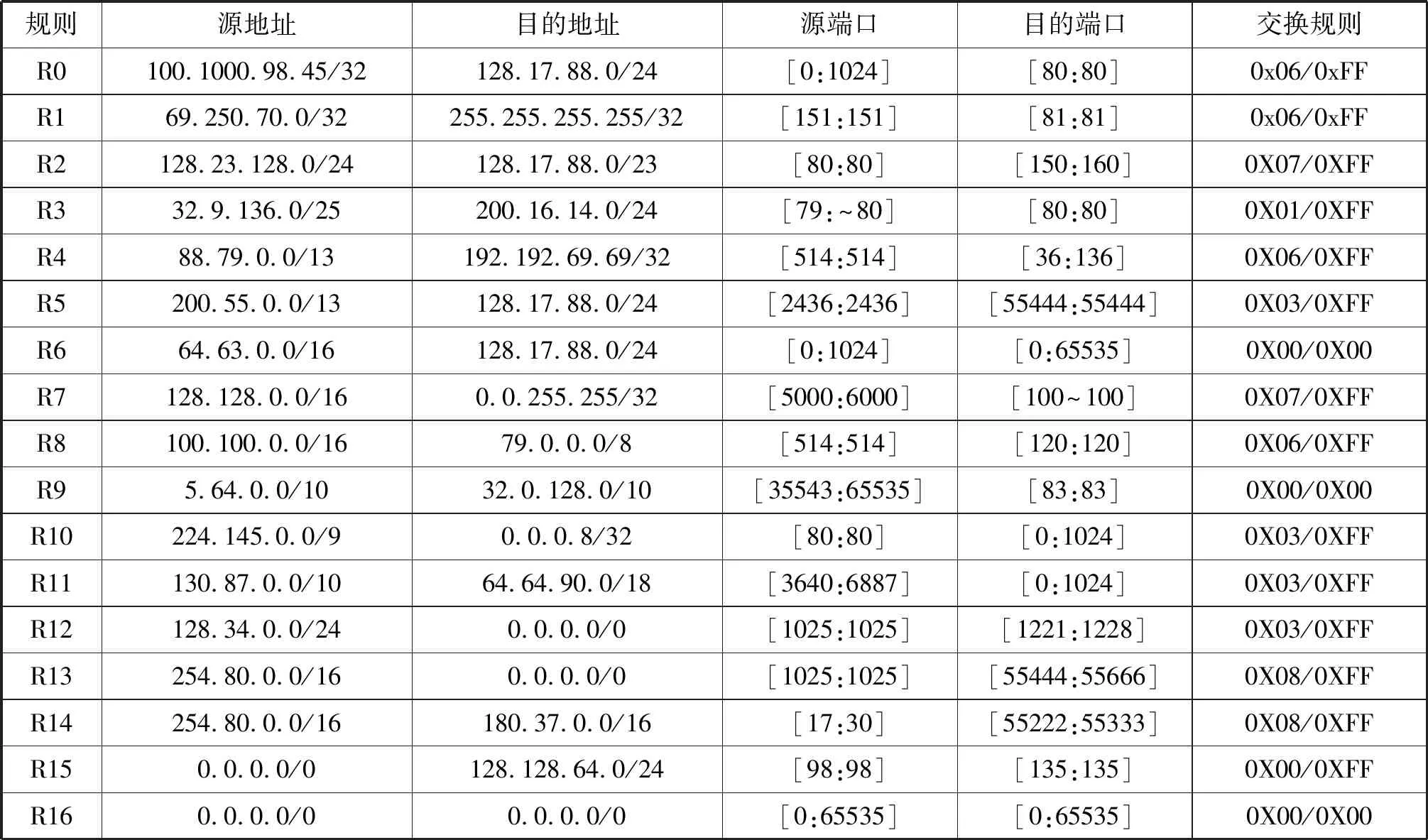
表2 五个字段的规则库
在把规则库分成几个子集后,子集的规则被存储在RFC的数据结构中,运用一个索引规则去描述子集空间。每个索引规则的范围从子集的所有规则的相应字段的最小开始点到最大端点。因此,假如把一个规则库分成k个子集,也就创建了k个索引规则。表3列出了表2的索引规则和它们相应的在每个字段上的范围。在为所有的子集创建了索引规则后,运用一个RFC数据结构(索引RFC)去存储这些索引规则。
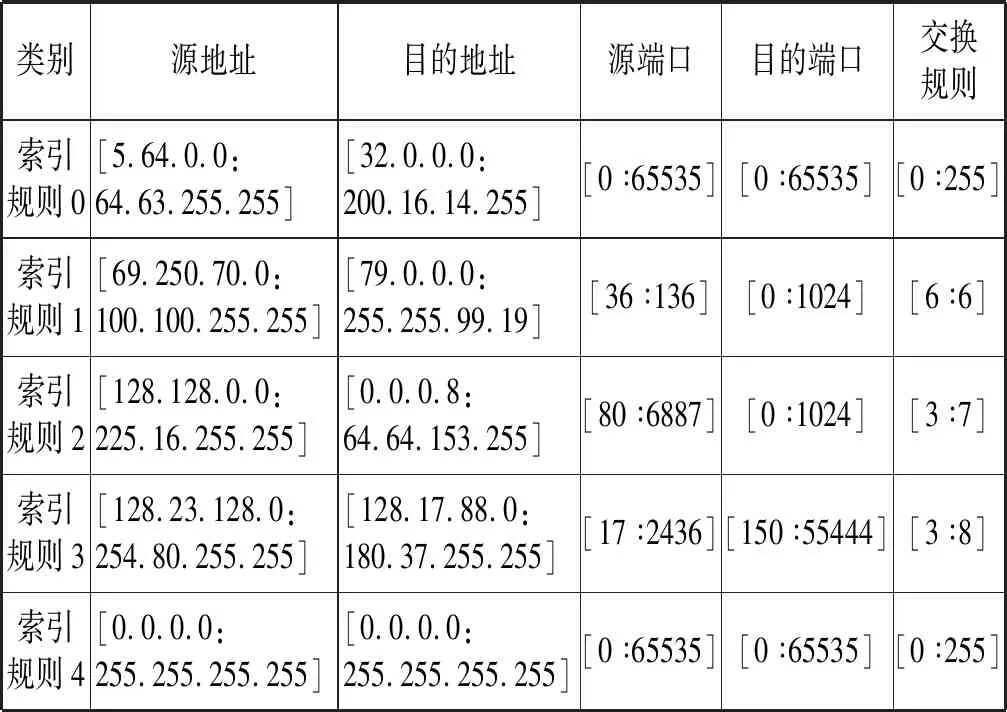
表3 关于表2的索引规则
对于每个RFC数据结构,在第一阶段,五个过滤字段被分成七块,包括六个16位数据块和一个8位的块。对于每个块,相应于包头字段的值,为访问对应的等价类ID(eqID)构造2w实体的索引数组,其中w表示块大小。每个eqID与类位图相关联去指示和块等效集相匹配的规则。每个eqID的类位图是不同的,下一阶段中,通过外积eqID使两到三块组合成一新块,新块的类位图等于所有合并eqIDs的类位图的交积。在新的阶段中,每一个不同的类位图表示一组等价的集,然后给每一个等价集分配一个eqID。新eqIDs存储在一个索引数组中,这个索引数组的大小等于合并eqIDs的乘积。这个过程继续到所有的块都被合并。对传入的数据包,搜索过程在一个RFC数据结构中首先把数据包报头分成七块。每个块的值用来访问索引数组的eqID。如果有任何后续阶段,搜索过程使用eqID组合去生成下一阶段的索引。随着搜索过程遍历到最后阶段,最终诞生一个eqID,和这个新诞生的eqID对应的类位图被用来访问最终匹配的规则。
对于一个进入的数据包,这个完整的搜索过程首先遍历索引RFC数据结构找到匹配的索引规则,然后通过访问相应的RFC的数据结构继续搜索匹配索引规则的子集。本文算法框架由六个RFC的数据结构组成,其中,五个关于结果子集,一个关于索引规则。表4展示了原始RFC的外积表实体和本文算法的外积表实体。在这个例子中,本文算法减少了63%原始RFC的外积实体。

表4 原始RFC和本文算法在每个阶段的外积表实体
2 算法的进一步改进
本文提出三种技术来进一步改善本文所提算法的时间和内存消耗性能。
1) 合并小的子集。在对规则库进行分割时,可能会产生小的子集,这些小的子集将导致无效的RFC数据结构,最终造成额外对这些数据结构的内存访问。为了避免这种情况,本文设计了一个阈值,当某个子集的规则数小于这个阈值时,就将其与别的子集合并。这些合并的子集存储在一个共同的RFC数据结构中。
2) 合并第一个阶段中不同的RFC数据结构。规则库分割成K个组需要设计K+1个RFC数据结构。每个RFC数据结构都需要单独遍历,从而在第一个阶段中的索引数组中为了检索到相应的eqID就需要7×(K+1)内存访问。可以把不同RFC数据结构但相同块的索引数组进行合并,达到减少内存访问的次数。这样一次内存访问就可以获得不同RFC数据结构相同块的eqIDs。第一阶段的RFC数据结构检索的内存访问的次数就从7×(K+1)降到7。
3) 减少内存消耗。第一阶段每个RFC数据结构存储eqIDs需要6个16 bit的块和1个8 bit的块,每个16 bit的块的搜索表是216个实体的索引数组,每个8 bit的块的搜索表是28个实体的索引数组。假如把规则库分割成K个子集,在第一阶段就需要6×216×(K+1)+28×(K+1)实体。为了减少内存消耗,可以在第一阶段中设计用二进制搜索数组替换索引数组,对于每个索引数组,存储在相邻实体中的eqIDs可以是相同的。将它们合并为一个区间,从第一个实体到最后一个实体的eqID相同。通过这种方式,可以将索引数组2w实体转换成一个n-间隔数组,它可以采用二进制搜索。该方法可以减少在第一阶段的内存消耗。
3 实 验
本文运用真实的和合成的规则库去评价本文算法的性能,在实验中运用三种类型的规则集:访问空列表(ACL)、防火墙(FW)和IP链(IPC)。这些数据集可以从文献[7]获取。实验目的是为了比较本文算法和其他几种算法的性能。
实验结果由三部分组成:第一部分描述不同规模的子集在时间和内存消耗之间的平衡;第二部分展示了基于不同子集合并阈值的性能改进;第三部分是一项性能研究,比较本文所提算法与已存算法的性能。
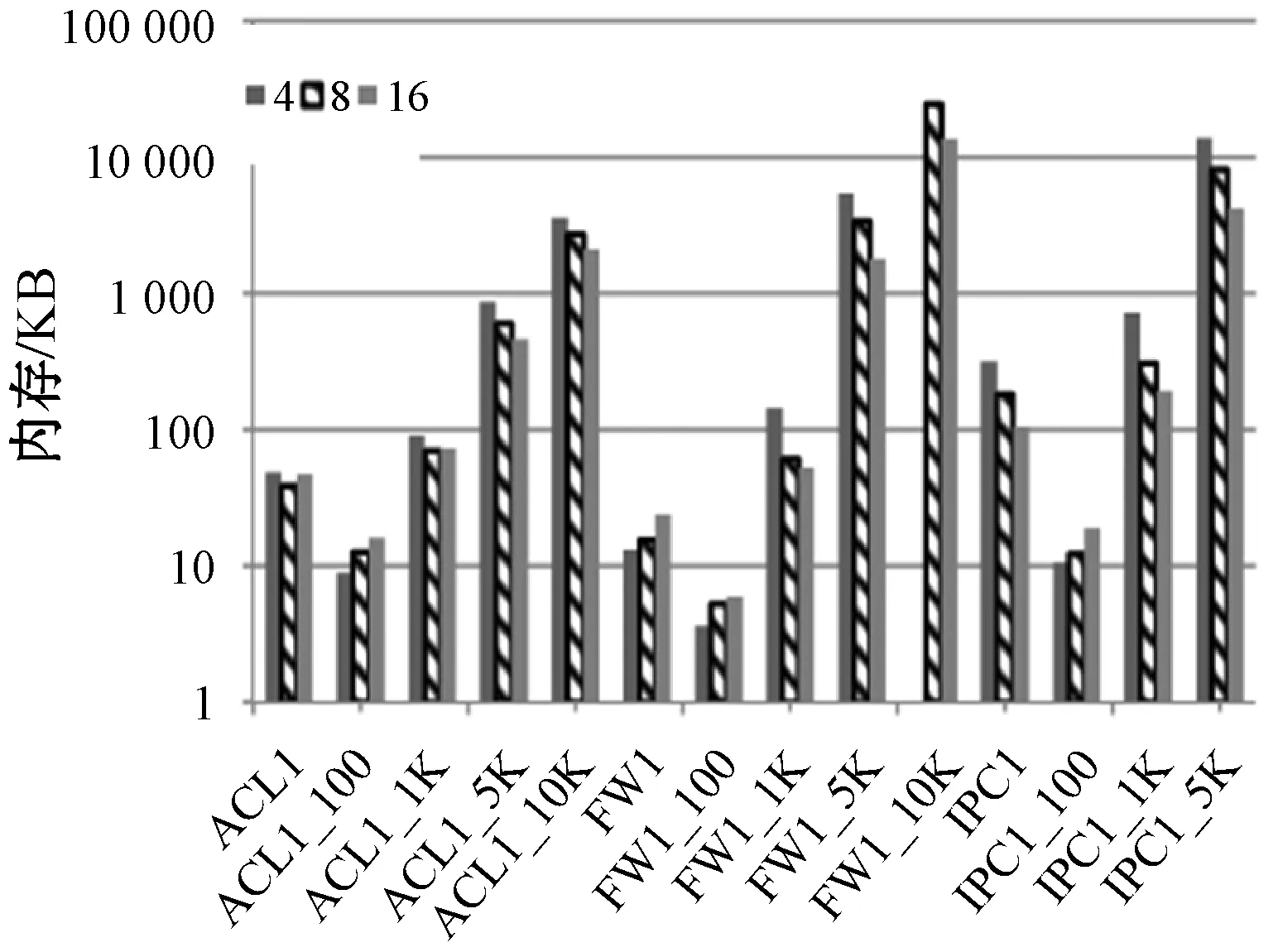
1) 不同规模子集下的性能平衡。第一部分的一个子集的规则数是通过一个因子决定的。定义因子d1,子集的规则大小等于规则总数除以d1。规则集被分割,直到在每个子集的规则数小于阈值。本实验使用三个因数:4、8、16,在接下来的评价中选择最佳性能的因子。
图3显示了在三种不同类型的规则库、三个不同大小的子集下,最坏情况下的内存需求和内存访问的次数。如图3(a)所示,随着子集中规则数减少,即子集个数增多,内存需求逐渐劣化。然而,图3(b)也显示,随着子集中规则数增加,子集个数减少,内存访问增加。这是因为传入数据包可能匹权衡利弊后,设置因子d1为8,因为此值可以更好地权衡存储和速度性能。因此子集的大小等于规则的数量除以8。
(a) 内存需求

(b) 访问次数图3 三种类型的规则库在三个因子下内存需求和访问次数
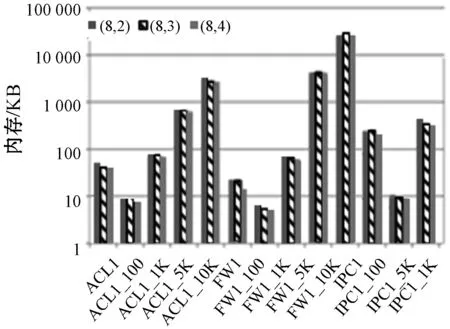
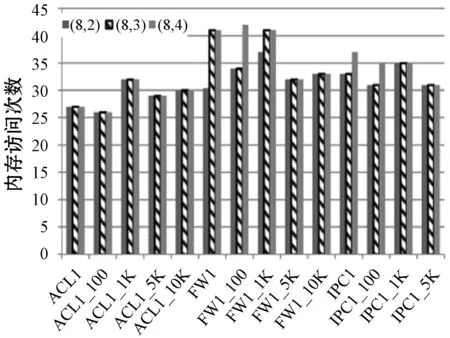
2) 子集合并的不同阈值。第二部分实验,设置一个阈值来合并小的子集从而达到提高算法性能。合并阈值也决定使用因子d2,合并阈值等于子集的大小除以d2。子集合并如果它们的规则数小于合并阈值。初始设置三个因子:2、3、4。在接下来的评价中选择的最佳性能的因子。
图4给出了在三种不同类型的规则库、三个子集合并的不同阈值下,在最坏情况下的内存需求和内存访问的次数。图4(a)表明在RFC算法中,一个大的合并阈值可能招致更多的内存需求,因为越来越多的子集合并导致更大的外积表。图4(b)显示一个小合并阈值可能招致更多的内存访问,因为RFC的数据结构的数量不能有效减少。因此,传入数据包在搜索过程中匹配更多的子集可能导致更多的内存访问。
(a) 内存需求
(b) 访问次数图4 三个合并阈值下内存需求和访问次数
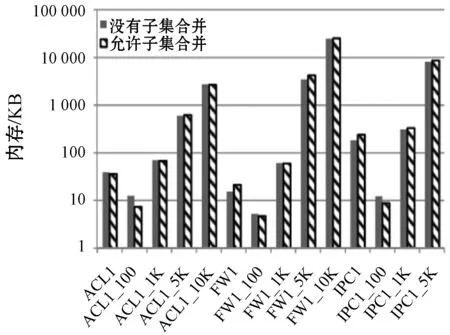
进一步比较本文算法在允许子集合并(设置因子d2为3)和没有子集合并两种情况下的性能,如图5所示。图5(a)显示,随着子集的合并,内存需求略有增加,RFC数据结构存储更多的规则通常会导致更多的外积实体。图5(b)表明,子集合并可以减少内存访问。要在存储和速度性能之间权衡,本文倾向于速度,因为本文算法相比于RFC算法显著降低了内存需求。
(a) 内存需求
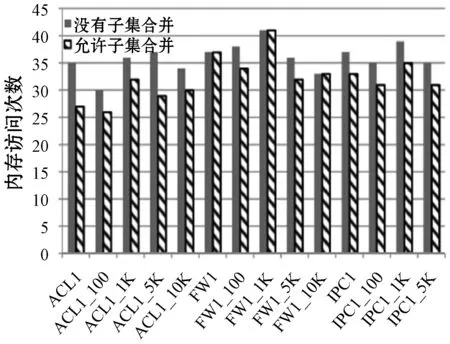
(b) 访问次数图5 三种类型的规则库,两种合并阈值下的内存 和速度性能比较
3) 算法性能比较分析。比较本文算法与RFC[6]、HSM[8]、Hypercuts[4]、ISET[9]的性能,结果如图6-图8所示。一些结果不能显示是因为用于构建数据结构程序内存消耗太大,导致无法运行。

(a) 内存需求
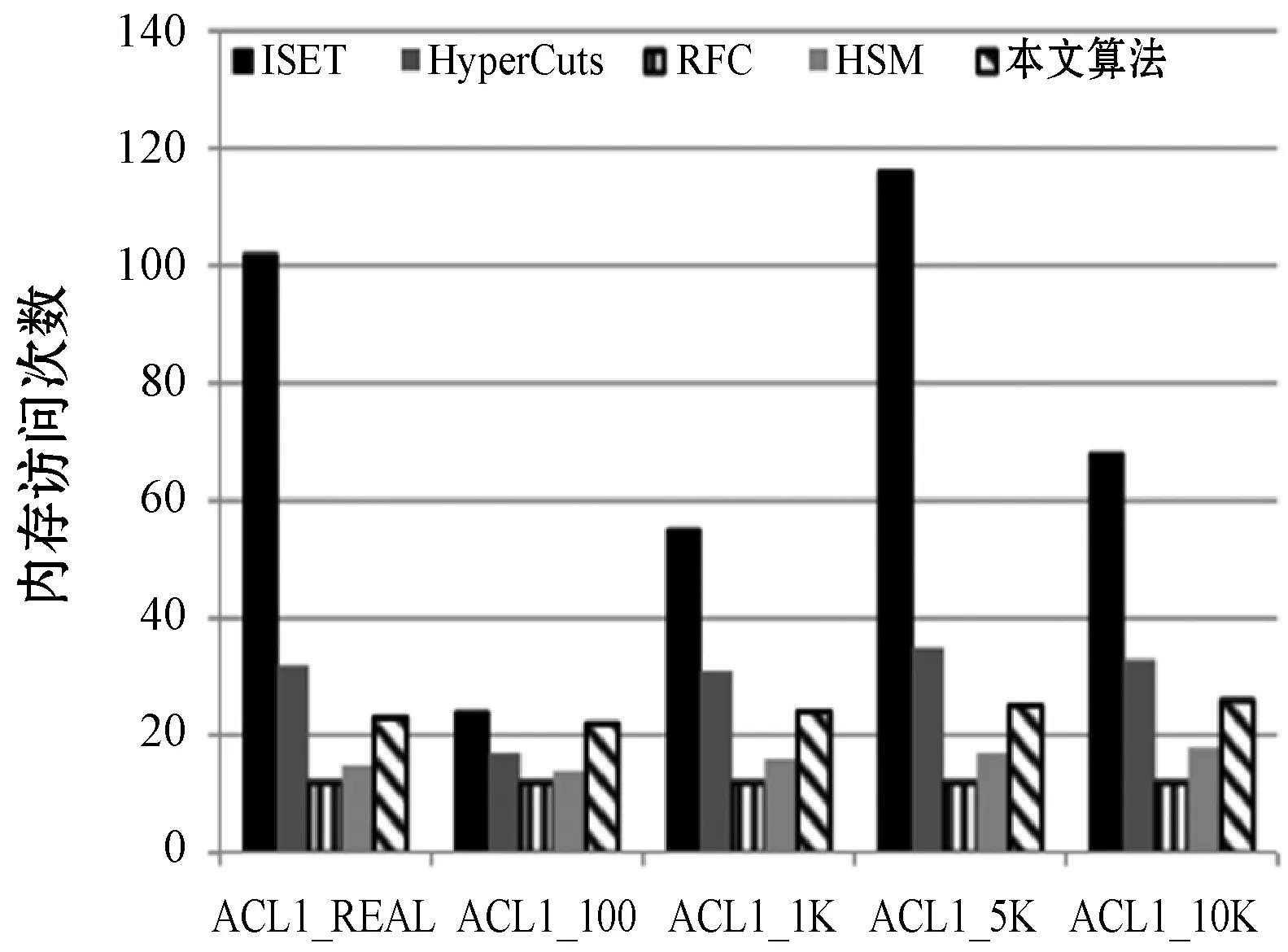
(b) 访问次数图6 ACL1规则库中的五种算法的速度性能比较
(a) 内存需求

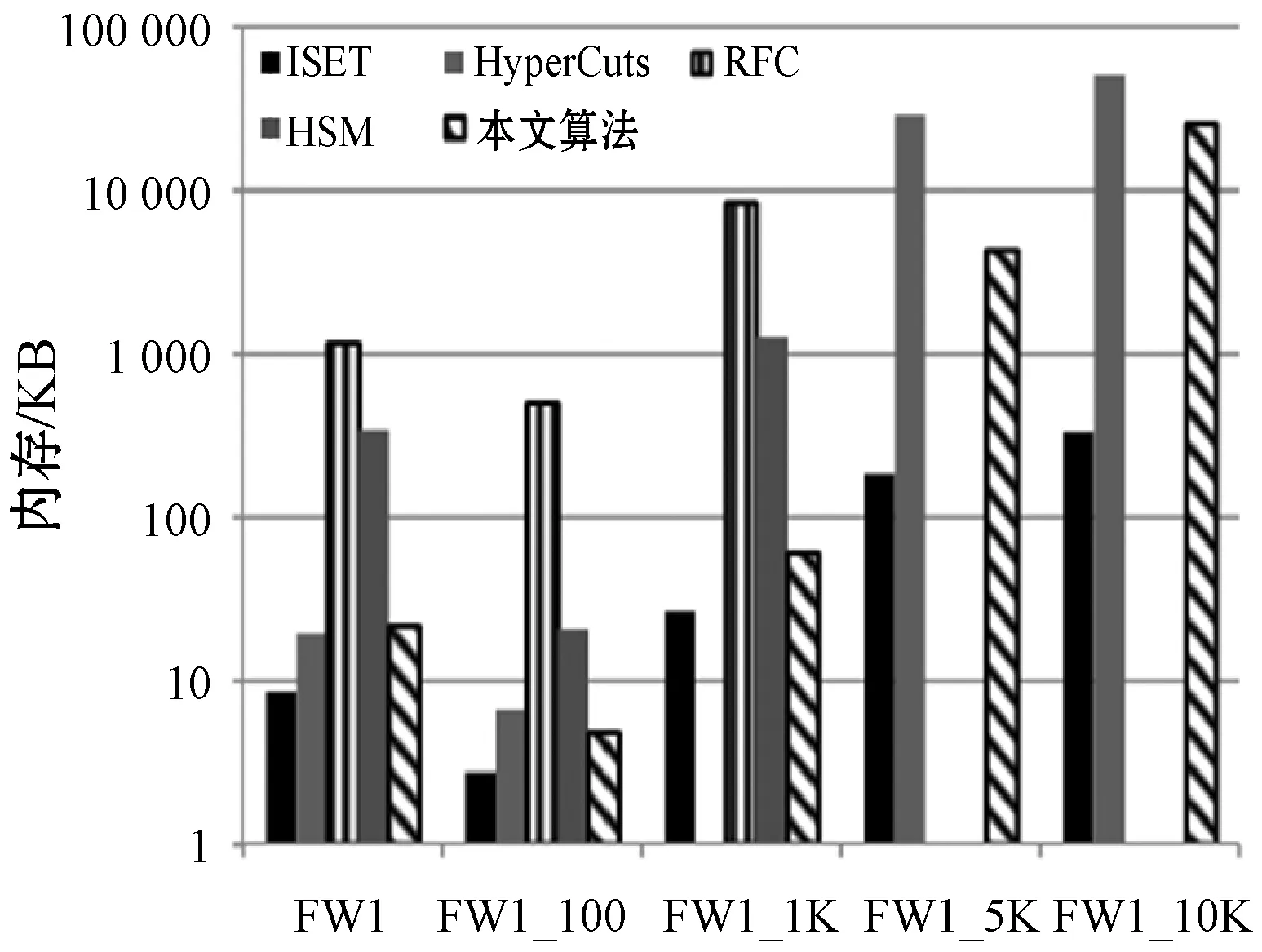
(b) 访问次数图7 FW1规则库中的五种算法的速度性能比较
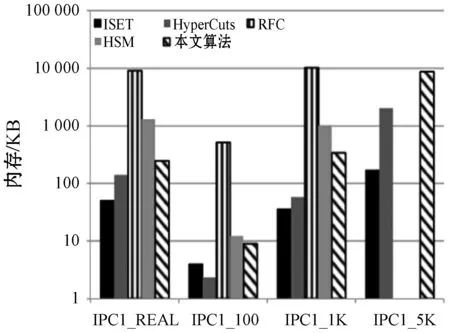
(a) 内存需求
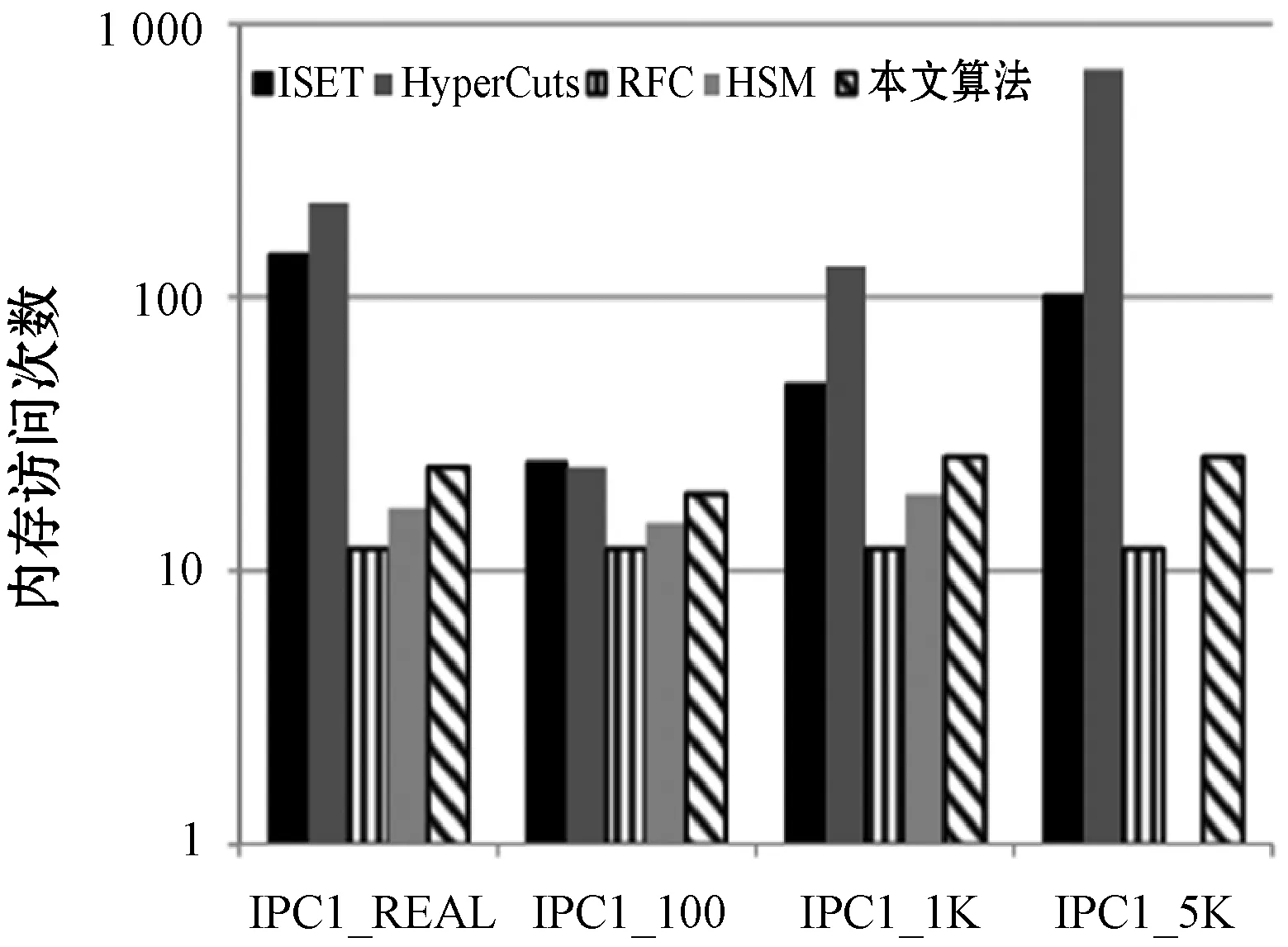
(b) 访问次数图8 IPC1规则库中的五种算法的速度性能比较
图6(a)、图7(a)和图8(a)显示五种算法的内存性能比较。本文算法改善了RFC和HSM存储性能,因其都使用类似的数据结构。本文算法内存需求比ISET大,然而ISET的速度性能也明显逊色于本文算法。针对不同规则库Hypercuts的结果有所不同。虽然在ACL类型中Hypercuts表现良好,但运用于FW和IPC时其性能却严重恶化,而本文算法在这两种类型的规则库速度和存储性能都优于Hypercuts。总之,本文算法是最好的可行性方案。虽然从单一性能角度可能不是最好的方案,但它总是提供一致的吞吐量且避免最坏情况。
4 结 语
RFC是一个性能很好的包匹配算法,但是在生成外积表时要消耗大量内存,因此不适用于大规模的规则库。为了改善内存性能,本文基于RFC提出一个改进算法把规则库分割成几个子集。在同一子集中的规则被存储在同一RFC数据结构中,每个子集用一个索引规则来进行描述。所有的索引规则被存储在一个RFC索引中,这些RFC索引指向相应的RFC数据结构。并进一步提出三种技术去改进内存和速度性能。运用三种规则库去评价该算法的性能,实验表明,本文提出的算法综合性能最优。
