基于激活-池化增强BERT模型的在线课程评论情感分析
2021-05-14张会兵董俊超
潘 芳 张会兵 董俊超
1(广西师范大学职业技术师范学院 广西 桂林 541004) 2(桂林电子科技大学广西可信软件重点实验室 广西 桂林 541004)
0 引 言
由于在线课程开放、方便和优质的特点,使得在线学习者数量快速增加[1]。数量庞大、背景各异、层次多样的学习者对在线课程的管理提出了新的挑战:实时掌握学习动因、学情/状态变化以更好地提供个性化教育服务。为适应这一趋势,在线学习平台会提供评论、论坛等社区功能,方便学习者、教师和平台管理方之间的交流互动。在线交互过程中会产生大量的交互文本等非结构化数据,对评论文本进行情感分析可以有效获取学习者的情感态度、学习体验等,从而理解学习者的需求变化和“学习痛点”,为个性化服务提供参考。
现有的在线课程评论情感分析主要有情感词典、机器学习和深度学习三类方法[1-3]。基于情感词典的方法主要是依据人类先验知识构建情感词典,将课程评论分词后与情感词典比对计算实现对课程评论的情感分析。该类方法受情感词典质量的影响较大,不适用于在线课程海量评论信息情感分析的需要[4]。基于机器学习的方法是将从评论文本中抽取的特征值传入相应模型中进行情感分析[5],此类方法的性能对特征工程依赖较大。随着在线教育平台中课程评论数据规模的快速增长,特征工程需要花费的时间、人力急剧增加使得该类方法缺点日益凸显。近年来,对评论文本进行特征自动抽取的深度学习情感分析模型(如CNN、RNN)在文本情感分类研究中得到了广泛应用。然而,此类模型中文本嵌入层依赖的one-hot编码或词向量编码并不适用于属性众多、语义丰富、句型复杂的课程评论文本。最近,Google提出的BERT模型使用了一种新颖的“MASK”词向量训练方法,不仅可以根据词语在上下文中的含义对其进行编码,而且可以有效捕捉评论文本中分句间的关系,能较好地适应海量课程评论数据中情感分析的需要,但是由于课程评论语料规模与BERT预训练模型采用的维基百科语料规模差距甚大,进行课程评论情感分类下游任务时会发生严重的过拟合问题。
为此,提出一种激活-池化增强的BERT(RP-BERT)课程评论情感分析模型。该模型采用深度学习方法从课程评论文本中自动抽取特征,解决了传统课程评论情感分析模型中词典构建和特征工程需要大量人工参与的问题。从维基百科大规模语料中构建BERT预训练模型,既能抽取课程评论句内词语的关键语义信息,又能对课程评论文本句子的逻辑关系进行学习。对直接应用BERT模型在课程评论情感分析任务中存在过拟合的问题,增加激活函数层和最大-平均池化层进行改进。突破了以往基于神经网络模型进行课程评论情感分析中过多依赖数据规模和数据标注质量的局限,为课程评论情感分析提供新方法,以期为学生课程选择、教师授课内容优化和平台服务提升等方面提供数据支持。
1 相关工作
在线课程评论的情感分析吸引了越来越多的研究者的关注。文献[6]使用KNN算法对本科生的课程评论文本进行分析以获得学生的情绪和观点。吴林静等[7]在正负情感词加权的方法的基础上通过计算正负情感词的数量差来计算课程评价评论句子的情感倾向。薛耀锋等[8]结合情感交互和情感计算理论,提出了面向在线课程的多模态情感分析模型,并基于此模型实现了在线学习过程中的情感测量。黄昌勤等[9]针对学习云空间中的“情感缺失”问题,提出一种基于LSTM神经网络的交互文本动态实时情感分析模型,并且采用贝叶斯网络进行情感归因分析,建立情感驱动的个性化学习推荐策略。文献[10]针对不同课程评论文本蕴含的情感偏差,提出基于迁移学习的CNN-LSTM模型自动识别一个帖子是否表达了困惑,判断其紧迫性并对情绪极性进行分类。该模型同时考虑每个单词的特征和长期时间语义关系,显著提高了情感分析的有效性。Dessì等[11]首先构建适合课程上下文的词嵌入,通过改进双向LSTM情感分析模型中嵌入层编码方式提升情感分析的性能。
上述模型没有充分考虑课程评论中上下文信息与分句间关系对情感的影响,而BERT模型中基于Transformer的双向编码器依据海量无标注语料的上下文对词进行编码表征,可以获得文本中丰富的语义信息,预测两个分句间的关联性,只需标注少量课程评论的情感标签即可实现评论情感分析任务[12-15]。文献[13]提出一种基于BERT模型将评论转化为大量知识来回答用户问题的微调方法,该方法可应用在基于属性的情绪分析和情绪分类等任务上。Pei等[16]提出DA-BERT模型来解决传统方法在社交媒体细粒度、短文本情感分类中的计算复杂度和依赖性问题。Yang等[17]将BERT模型用在对话文本的情感检测上,并实现了对话语境信息的分析。BERT除了单独用在情感分类任务外,还可与LSTM、Bi-GRU等传统神经网络模型组合应用在情感分类任务中的情感属性标注和情感极性预测任务中[18-19]。然而,经实验发现直接应用原始BERT模型进行课程评论情感分类任务时会发生严重的过拟合问题。
2 RP-BERT在线课程评论情感分析模型
适用于在线课程评论情感分析的RP-BERT模型如图1所示,其中:E为输入表征层中每个子层(包括位置、分段、令牌3个子层)所对应的嵌入表示;C为BERT模型中表示开始的特殊令牌[CLS];Tok为BERT模型中的令牌;T为语义抽取层输出的令牌;Trm为Transformer编码器结构,语义抽取层包含多个Transformer。输入表征层对预处理完成后的原始课程评论进行编码;语义提取层对输入表征层输出的评论编码进行语义提取,并将其输入到激活函数层进行非线性映射;池化层进一步缩减激活函数层的网络规模,提取关键特征,输出结果到情感分类层;最后,通过情感分类层对课程评论情感极性进行分类表达。通过在原始BERT模型中新增Leaky ReLU激活函数层、最大-平均池化层和情感极性二分类层,改进原始BERT模型在课程评论情感分析任务中存在的泛化能力不佳和过拟合的问题。
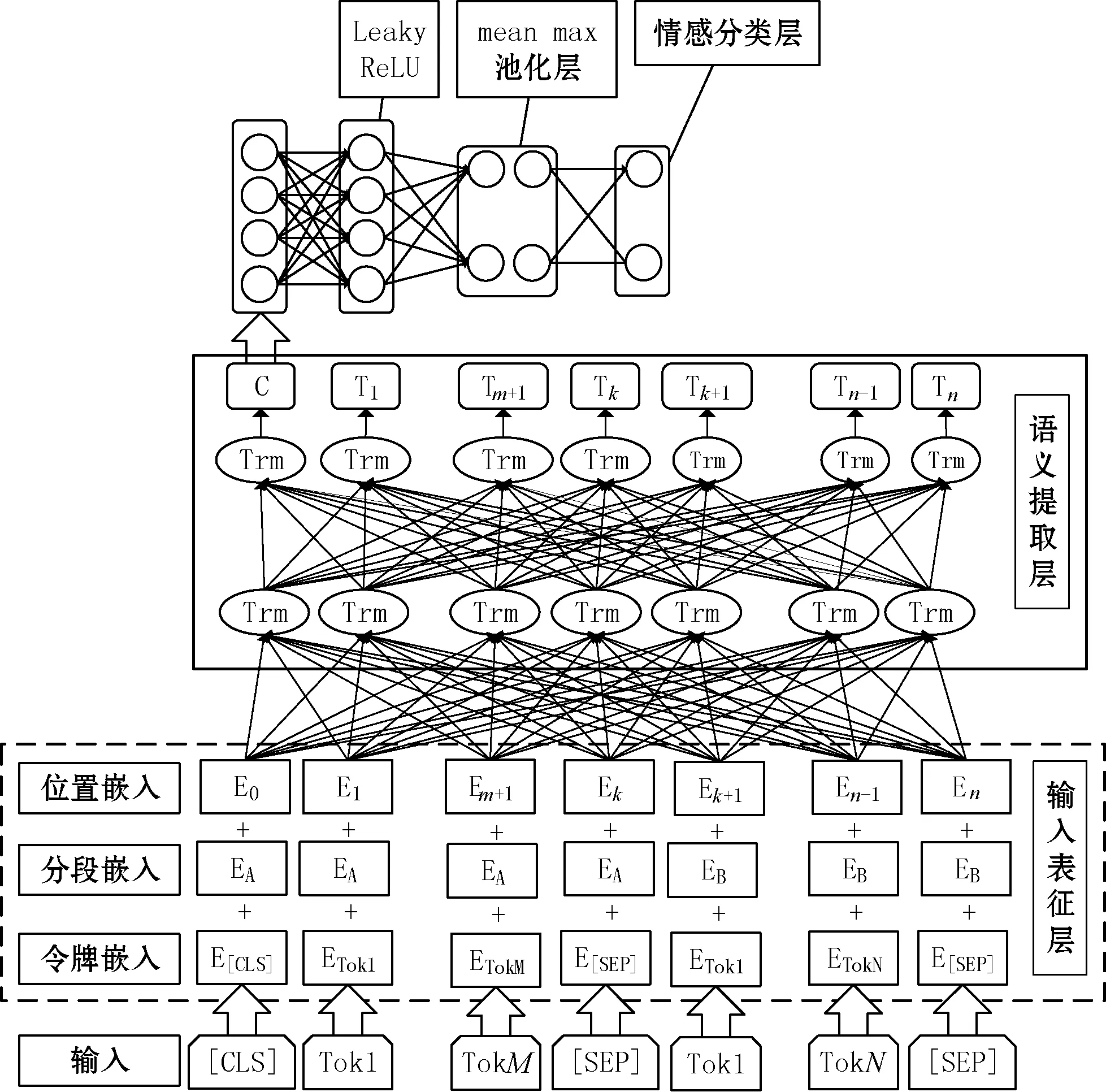
图1 在线课程评论情绪分析模型框架
2.1 输入表征层
RP-BERT模型采用与上下文有关的句向量级编码的BERT预训练模型,能够准确量化课程评论短文本内同一词在不同语境中的含义,同时能够对课程长句评论文本中的分句间关系进行编码,具体流程如下:
(1) 对原始评论数据做预处理:去除重复灌水评论以及与情感表达无关的链接、代码等类型数据;对课程评论中含糊不清的情感字符、数字和英文词汇等使用语义相同的中文词汇进行替换。
(2) 使用WordPiece嵌入模型,按照双字节编码方式对单个汉字进行编码,使其更加适用于词汇数量众多、含义丰富、结构复杂的在线课程评论文本,相比于传统词向量编码方式大大缩减了评论文本的编码规模和复杂度[20]。
(3) 按照评论文本语句结构的不同,将其分为短句和长句两种类型。针对短句评论文本采用遮蔽LM方法构建语言模型,通过随机遮盖或者替换评论文本中15%的任意汉字,让模型通过理解上下文的内容去预测遮盖或者替换的部分,替换方式包括:80%几率替换为[MASK],如老师讲得非常好—>老师讲得非常[MASK];10%的几率被替换成为另外一个令牌, 如老师讲得非常好—>老师讲得非常美;10%的几率保持原本内容不变,如老师讲得非常好—>老师讲得非常好。针对长句评论文本,在评论文本语义逻辑处添加一些判断上下句起止位置的特殊令牌[SEP],如图2输入所示。按照1∶1的比例将上下文相关和上下文无关的评论文本作为输入表征层输入,以便模型理解课程评论文本句子间关系。例如:
输入=[CLS]老师[MASK]讲得好[SEP]我[MASK]爱听[SEP]
标签=有下文关系
输入=[CLS]老师[MASK]讲得好[SEP]吃[MASK]晚饭[SEP]
标签=无下文关系
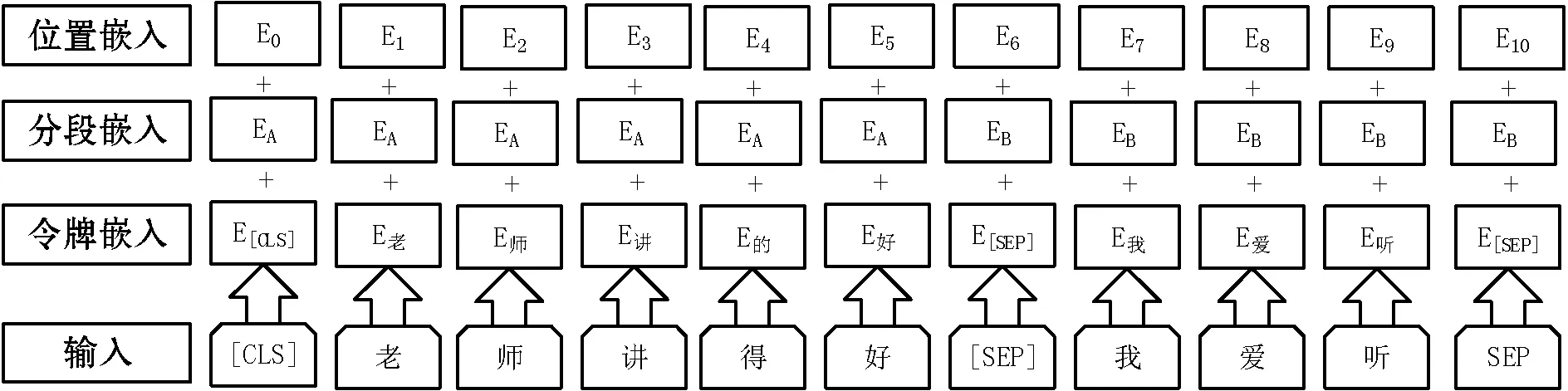
图2 输入表征层
输入表征层除了输入和令牌嵌入外,还要随机初始化一个可训练的分段嵌入。通过分段嵌入信息使得模型能够判断上下句的起止位置以分开上下句,如表1所示。输入表征层最终输出为令牌嵌入、分段嵌入、位置嵌入的总和。
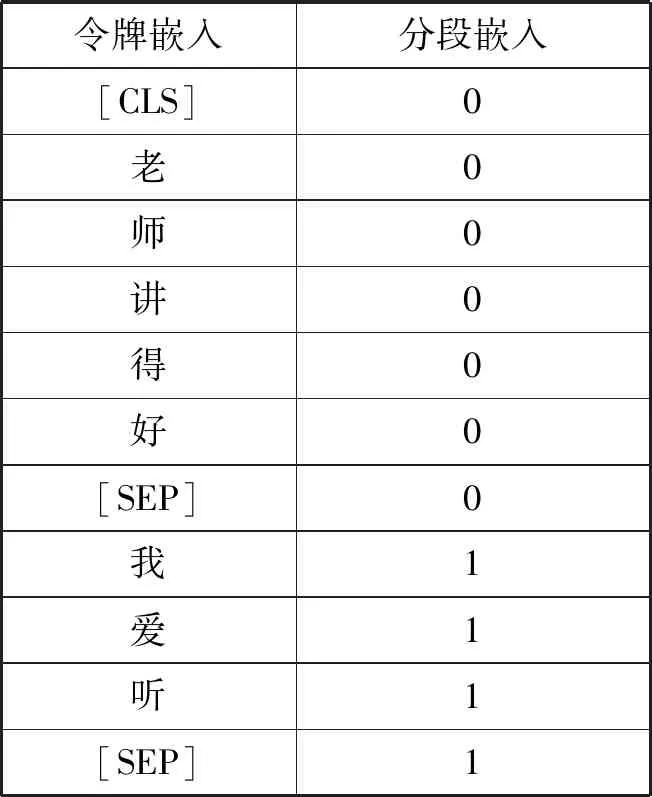
表1 分段嵌入示例
2.2 语义提取层
图3中的语义提取层是以Transformer编码器为基础单元组成的多层双向解码器。Transformer编码器包括字向量与位置编码、注意力机制、残差连接与层标准化和前馈四部分[21],如图3所示。
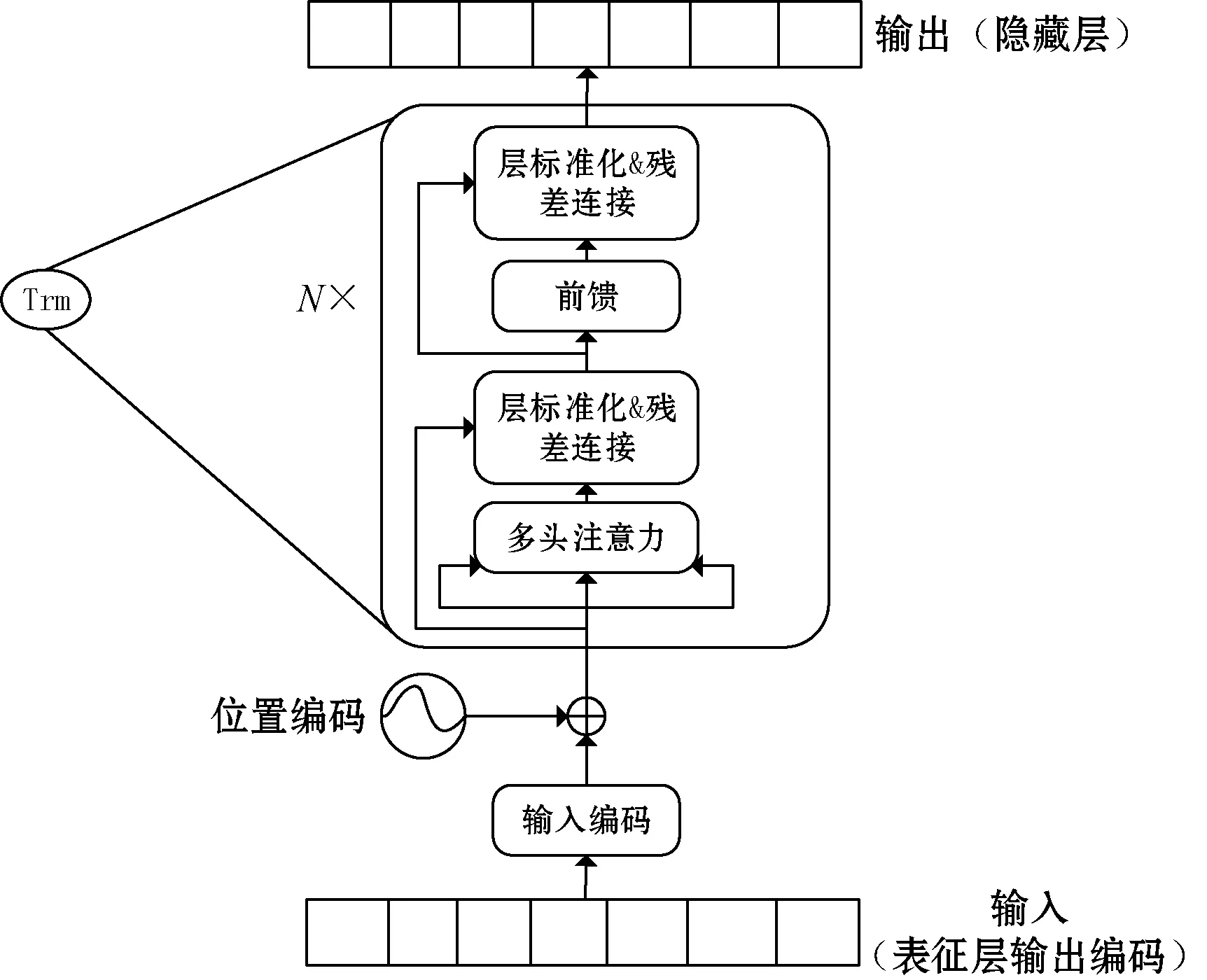
图3 Transformer编码器结构
(1) 字向量与位置编码。位置编码提供课程评论文本中每个字的位置信息给Transformer用来识别字在评论文本中的依赖关系和时序特性。
X=E(X)+PX∈Rbatch-size×seq.len×embed.dim
(1)
P(pos,2i)=sin(pos/1 0002i/dmodel)
(2)
P(pos,2i+1)=sin(pos/1 0002i/dmodel)
(3)
式中:E(·)为字对应的嵌入表示;P为位置编码;batch-size为输入课程评论文本数;seq.len为每条课程评论文本的长度;embed.dim为课程评论文本中每个字的嵌入维度;pos为课程评论文本中字的位置;i为字对应的向量维度;dmodel为特定位置向量维度。
(2) 注意力机制。注意力机制保证了每条评论文本中的每个字向量都含有该条课程评论文本中所有字向量的信息。
(4)
式中:Linear(·)表示线性映射;X为课程评论文本向量;WQ、WK、WV为权重。
Xattention=SelfAttention(Q,K,V)=
(5)
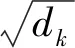
(3) 层标准化与残差连接。层标准化归一化神经网络中的隐藏层为标准正态分布,从而加快模型训练和收敛的速度:
(6)
(7)
(8)
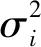
残差连接可以解决梯度消失和网络退化问题,如式(9)所示。
X=Xembedding+attention(Q,K,V)LayerNorm(X+subLayer(X))
(9)
式中:LayerNorm(·)为子层的输出;subLayer(·)为子层本身实现的函数;Xembedding为隐藏层输出;attention(·)表示计算注意力。
(4) 前馈。前馈由两层线性映射组成,并用ReLU激活函数激活,输出课程评论文本经过输入编码层和语义提取层处理完成后的隐藏序列,计算公式如下:
Xhidden=ReLU(Linear(Linear(X)))
(10)
其输出的隐藏层即为课程评论文本的数学表达,其中隐藏层的任一隐藏单元经过Transformer编码器中的注意力机制之后,均含有评论文本中的所有成分的信息。
2.3 激活函数层与池化层
在原始BERT模型第一个令牌[CLS]的最终隐藏状态后新增激活函数层和池化层,以逐步解决课程评论情感分析任务中存在的过拟合问题。激活函数层选用Leaky ReLU函数进行非线性映射,增强原始BERT模型评论文本复杂数据类型的学习能力,提高模型收敛速度[22]。然而,由于BERT模型中预处理模型数据规模极大,模型微调采用的含情感标注信息的课程评论数据与之相差甚大,增加激活函数层后仍然存在过拟合问题。因此,在激活函数层后继续增加池化层,缩减网络规模,融合输出特征,增强特征鲁棒性,进一步解决模型过拟合问题。
池化层采用如图4所示的最大-平均池化方法[23]。最大-平均池化沿着评论文本长度和嵌入维度分别求均值和最大值,然后将均值和最大值级联为一条向量,实现了隐藏序列到向量的转换,具体公式如下:
max_pooled=max(Xhidden,dimension=
seq_len)∈Rbatch_size×embedding_dim
(11)
mean_pooled=mean(Xhidden,dimension=seq_len)∈
Rbatch_size×embedding_dim
(12)
max_mean_pooled=concatenate(max_pooled,mean_pooled,dimension=
embedding_dim)∈Rbatch_size×embedding_dim×2
(13)
式中:max_pooled、mean_pooled、max_mean_pooled分别表示最大池化、平均池化、最大-平均池化;Xhidden为隐藏序列;seq_len为课程评论文本长度;dimension为向量维度;concatenate表示向量连接;embedding_dim为嵌入维度;batch_size为课程评论文本数目。
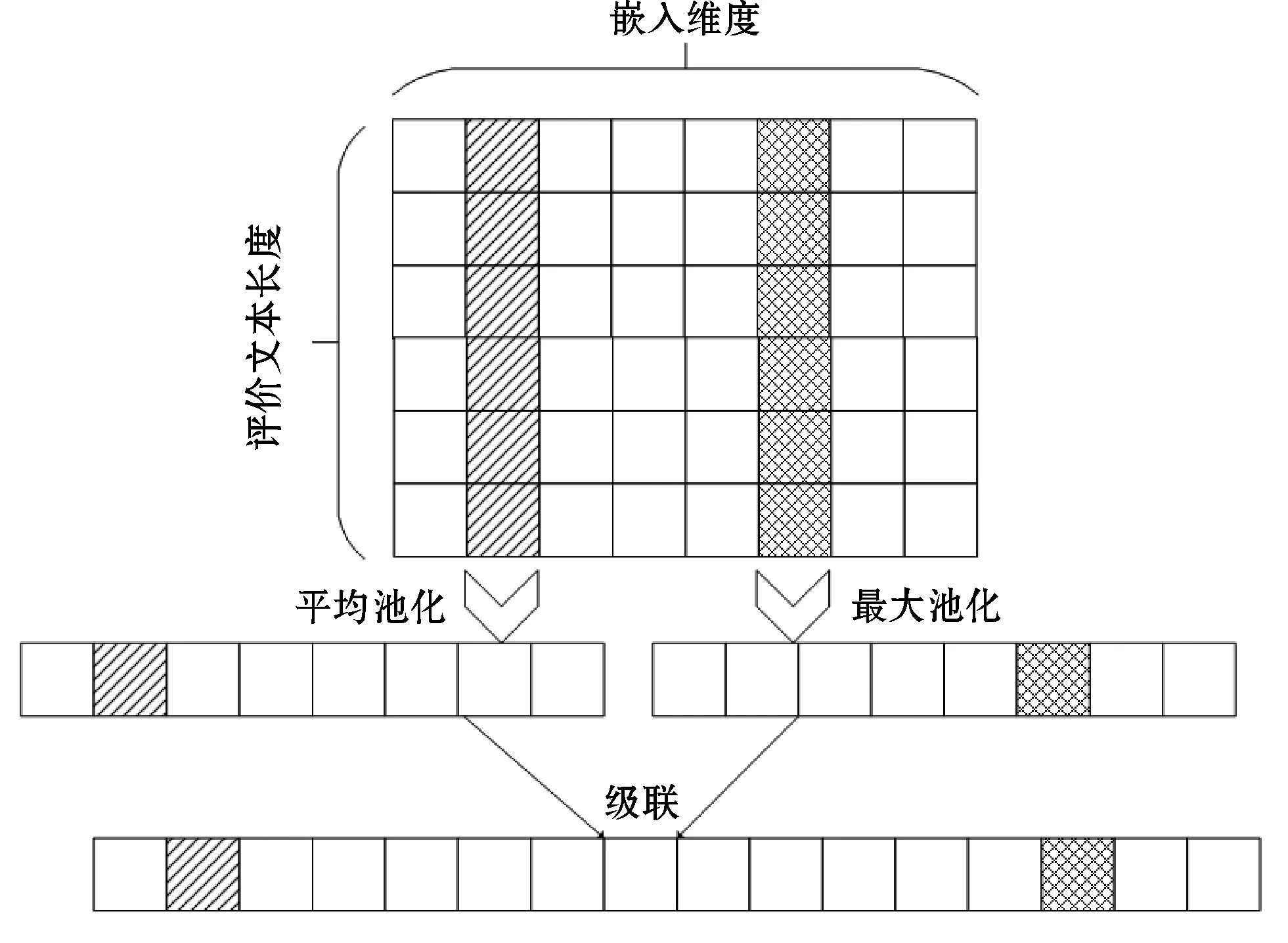
图4 最大-平均池化层
2.4 情感分类层与模型训练
构建情感分类器来获取课程评论文本的语义表示Xhidden对于情感标签的得分向量并输出最终情感标签。利用Sigmoid函数对池化层的输出max_mean_pooled进行相应计算,从而进行课程评论文本情感分类。具体公式如下:
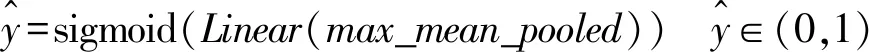
(14)

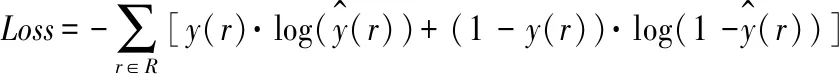
(15)
RP-BERT在线课程情感分析模型利用输入表征层进行课程评论文本特性编码,构建一个含有长句和短句评论的特征向量;然后,对特征向量进行学习,在每个Transformer编码器单元中进行评论语义信息捕获;并将抽取的特征输入到激活函数与池化层中进行语义信息的进一步选择;最终,输入情感分类层将课程评论分为积极课程评论和消极课程评论两类。
3 实验与结果分析
3.1 数据集与评估指标
(1) 数据集。在线评论情感分析任务中,采用从中国大学MOOC爬取的课程评论正负情感数据各5 000条,数据字段如表2所示。对RP-BERT情感分析模型进行训练和测试,训练集与测试集按照7∶3划分。
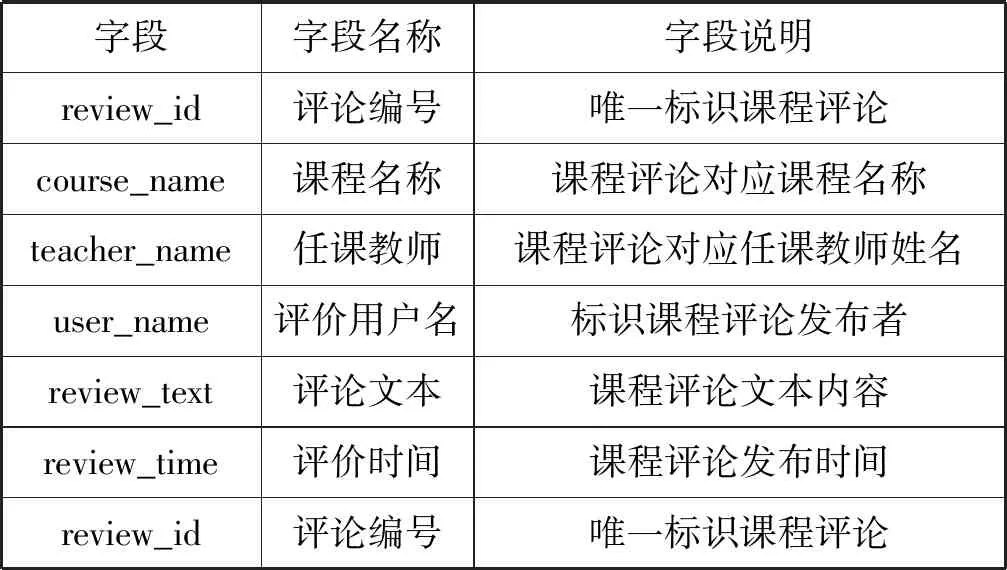
表2 中国MOOC课程评论数据集字段说明
(2) 评估指标。根据数据样本真实情感类别与预测情感类别组合划分为真正例(TP)、假正例(FP)、真负例(TN)、假负例(FN)四类,并依此计算情感分类正确的样本数与总样本数之比的准确率(Accuracy)和表示正例样本排在负例之前概率的AUC值(Area Under Curve),公式为:
(16)
(17)
3.2 实验环境与参数设置
(1) 实验环境。本次实验环境配置如下:操作系统为Ubuntu 18.04长期服务版,CPU为Intel Xeon Silver 4114@2.20 GHz,GPU为GTX 1080 Ti 11 GB,内存为16 GB,程序语言是Python 3.6,深度学习模型框架采用PyTorch 1.0.0。
(2) 参数设置。利用中文维基百科语料库训练原始BERT的预训练模型[25]。Google提供Base和Large两种原始BERT预训练模型,两者参数不同但网络结构完全一致。受硬件环境限制,实验采用Base参数设置:Transformer模块数为12,隐藏层尺寸为768维,12个自注意力头部,总共参数大小为110 MB[12]。最大序列长度为300,Batch为32,学习率为5e-5。
3.3 结果分析
(1) RP-BERT模型验证。将RP-BERT与SVM、条件随机场、原始BERT进行比较[15,26-27]。为了保证实验结果的准确和客观,将四种模型分别在同一训练和测试数据集上各自运行10次,求得准确率和AUC值的平均值作为模型最终结果,如表3所示。
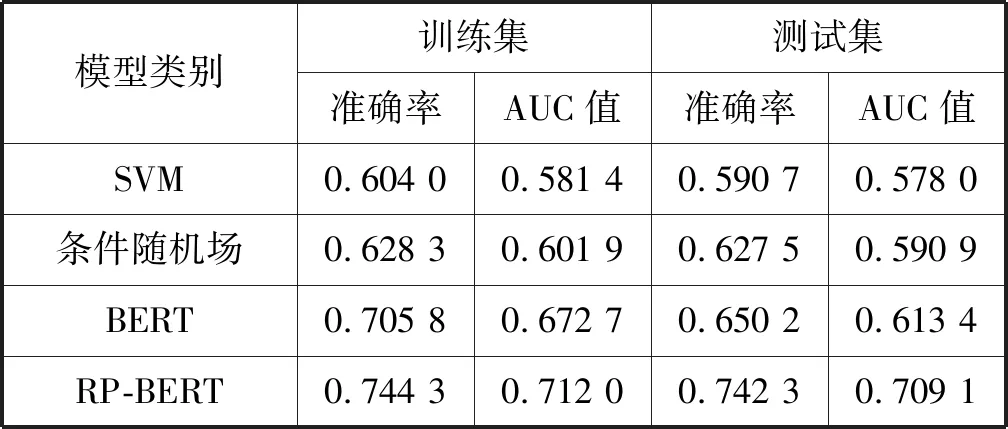
表3 四种在线课程评论情感分析模型准确率和AUC值
可以看出,BERT 模型和RP-BERT模型的准确率和AUC值在训练集和测试集中均高于其余两个模型。一个原因是这两种模型中的预训练模型为无须人工参与的大规模语料的无监督训练,它们的注意力机制能够准确联系上下文语义挖掘课程评论文本中准确句意。另一个原因是RP-BERT模型针对课程评论情感分析任务只需少量人工情感标注完成的课程评论数据对模型微调即可,而SVM和条件随机场过度依赖课程评论文本情感标注质量和数量,实验采集标注的各5 000条正负情感课程评论对这两个模型而言较小。此外,与BERT相比可知RP-BERT未发生欠拟合或过拟合问题,验证了RP-BERT模型对原始BERT模型过拟合问题改进的有效性。
(2) 基于情感分析的课程评论词云图。通过课程评论词云图对评论语义的可视化,可以直观地了解学生对课程或者老师的看法,为学习者选课、教师改进教学等提供参考。图5和图6分别展示了课程评论情感积极和消极的词云示例。

图5 课程评论积极反馈关键词云图

图6 课程评论消极反馈关键词云图
可以看出,学生更加喜欢条理清晰、通俗易懂、生动形象的课程,非常反感照本宣科的课程。此外,实验结果分析还发现学生对课程字幕和PTT课件比较关注,老师的方言或者口音问题成为课程辍学率上升的主要因素之一。因此在线课程在发布时候不仅要考虑课程本身内容外,课程平台还应该为在线课程提供对应字幕和课程配套PPT方便学生学习,开课教师应该提高普通话水平避免出现方言和地方口音的问题,做到课程内容丰富、配套资源齐全、老师讲解清晰明了,降低在线课程辍学率。
图7为《高等数学(同济版)》课程评论文本生成的词云图。可以看出,高等数学(同济版)课程评论反馈整体比较好,课程内容丰富,讲解思路清晰、通俗易懂是影响评论积极的关键因素,用户普遍感觉课程讲解细致清楚,自己学完课程后有所收获。

图7 《高等数学(同济版)》课程评论词云图
4 结 语
RP-BERT通过在原始BERT模型中增加激活函数层和池化层改进了直接应用BERT模型做课程评论情感分析任务时出现过拟合的问题,同时增加了情感分类层对课程评论情感进行分析。相对于传统课程评论情感分析模型,RP-BERT模型具有精确度高、训练容易的优点。融合RP-BERT课程评论情感分析模型和词云图可以对课程评论反馈的关键信息进行分析挖掘和可视化展示,为课程选择、内容优化和平台服务提升等提供有益参考。后续将研究融合课程评论文本和评分的在线课程评论情感分析模型,使得情感分析更加准确实用。
