一种基于词和事件主题的卷积网络的新闻文本分类方法
2021-05-14吴晓平
于 游 付 钰 吴晓平
(海军工程大学信息安全系 湖北 武汉 430033)
0 引 言
随着大数据、云计算等现代信息技术的发展,传统的纸质文档快速向电子化、数字化文档进行转变,文档管理的分类、检索等基本方法也随之产生了变化,如何有效地管理这些信息并从中获取有价值的内容是文本处理中的一大挑战。文本自动分类[1]是解决这一挑战的基础性工作,是后续文本自动化操作和处理的重要基础。许多学者针对文本分类方法展开了研究,文本分类算法被不断提出,如朴素贝叶斯[2]、支持向量机(SVM)[3]、决策树[4]和神经网络[5]学习等方法。如何实现文本准确高效地分类已是目前研究的一个热点问题。
随着神经网络算法不断发展,其在自然语言领域处理的优越性也日渐凸显。周朴雄[7]分别使用神经网络算法、KNN算法及SVM算法对Web文本进行分类,结果显示神经网络算法的准确度要优于其他算法。相比于传统的分类主要采用有监督的方法,依赖于现有的自然语言处理工具容易导致处理过程中误差累积的问题。文献[8]提出一种结合Word2Vec、改进型TF-IDF和卷积神经网络的深度学习文本分类方法,提高了单个词对文本分类的影响,但是忽略了文本的语义关系,没有考虑上下文结构,有待进一步改善。文献[9]提出了一种基于LDA算法CNN短文本分类方法,该方法将文本主题加入到CNN网络中学习,但是得到的主题是单个词对文本的主题分布,不能深刻地反映文本语义信息。目前,在文本分类任务中,传统神经网络算法在训练过程中参数多且易出现过拟合现象,越来越多的深度学习方法开始走进大众视野。上述几种方法中特征表层信息提取应用成熟,但特征表示过于单一,仅用词对文本进行描述不能够全面地对文本表示,从而难以提高文本分类效果。
为能够更全面地应用文本的语义信息,解决传统文本分类中特征稀疏的问题,本文提出一种基于词和事件主题的CNN文本分类方法,并给出了基于BTM的事件主题模型对事件主题进行提取,通过事件主题特征对文本的语义进行表述,丰富特征语义信息,以CNN作为分类器学习,将传统基于词的特征表示方法与事件主题特征表示方法进行拼接作为CNN的输入,提高文本分类的准确性。
1 基于BTM的事件主题模型
主题模型[10]是自然语言处理的一种重要手法,在文本信息挖掘和信息检索领域有着非常重要的作用,通常是通过词或短语的方式对主题进行描述,但此类方法获得的文本主题缺乏深层次语义。事件[11]比词具有更加丰富的语义信息,可以更好地表达文本的主题,更有利于文本中心语义的掌握,且能够有效解决基于词的主题表示方法的稀疏性问题,如词组合{a,b}同属一个事件,利用基于词的主题模型对其进行表示时,可能词a与词b并不属于同一主题,而利用基于事件的主题模型,可以很好地解决这一问题。
1.1 事件抽取方法
在NPL处理领域,事件通常被定义为“谓词+论元结构”,可以表示为“主+谓+宾”结构。对于没有事先定义事件的事件抽取操作,可以使用由斯坦福大学自然语言处理小组开发的开源句法分析器Stanford Parser工具获取每条语句的依存结构,“nsubj”和“dobj”,即名词主语和直接宾语的方法,若其拥有相同的谓语,则可将其看成一个事件,即直接表示为“主+谓+宾”结构,可利用向量表示为:

(1)
式中:·表示点乘运算;⊗表示克罗内克积运算。若是二元事件,则直接采用谓词向量和论元向量点乘的方法表示。
1.2 模型构建
鉴于事件提取的原子是词对,所以在计算事件主题时,应该使用对词对进行主题计算的方法。BTM(Biterm Topic Model)[12]是针对共现对进行建模的一种主题模型,所以本文方法以BTM为基础对事件主题进行建模,模型如图1所示。
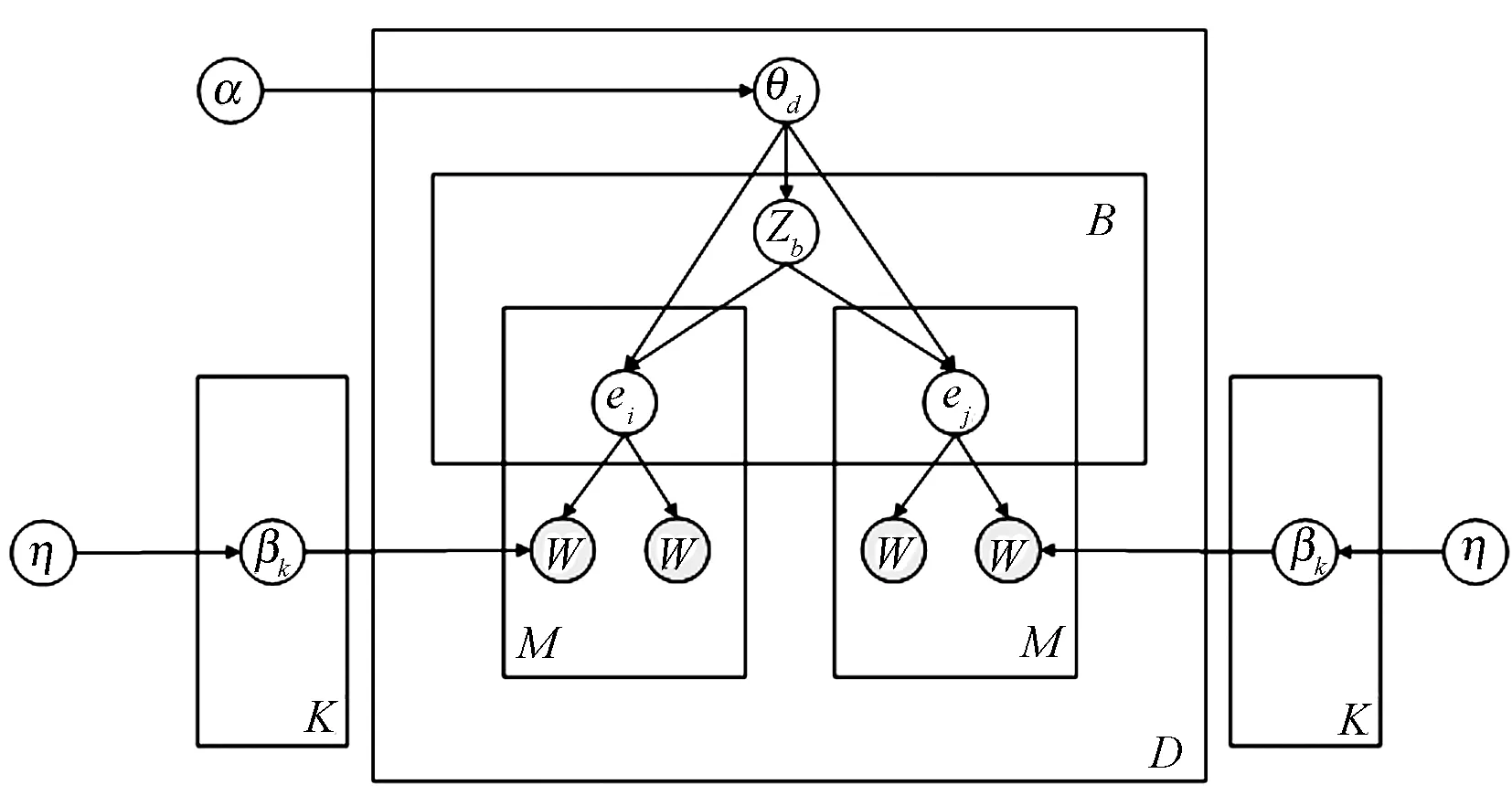
图1 以BTM为基础的事件主题模型
图1中符号含义如表1所示。
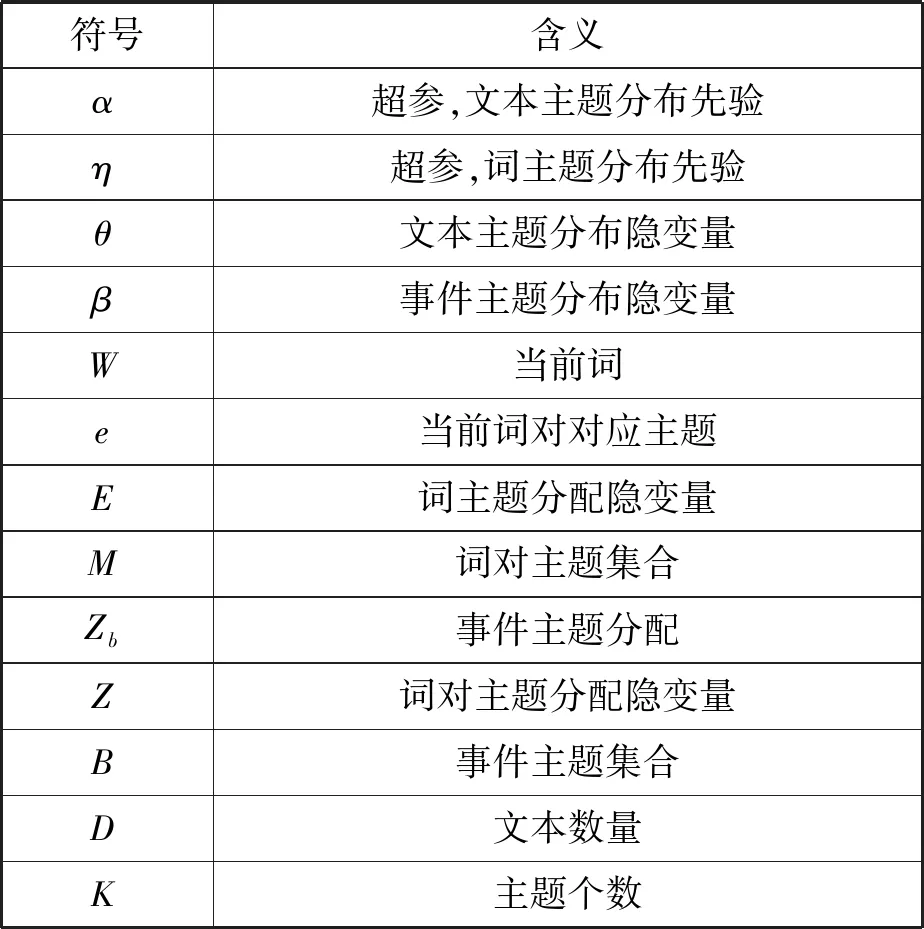
表1 基本符号及含义
因此,基于BTM模型的事件主题生成过程可描述如下:
(1) 生成词对主题多项式分布参数βk~Dirichlet(η);
(2) 生成文档主题多项式分布参数θd~Dirichlet(α);
(3) 从主题分布多项式θd中取样生成主题Zb,Zb~multi(θd),采样生成词对(ei,ej),ei~multi(θd),ej~multi(θd);
(4) 对于文档的词对进行采样,从主题分布多项式θd中取样生成主题eM,采样生成词对(Wp,Wq),Wp~multi(βem),Wq~multi(βem)。
此时,其联合概率计算方法如下:
(2)
(3)
2 基于词和事件主题的CNN文本分类
在CNN[13]学习训练过程中,通常采用词作为网络的输入,往往忽略了文本中的语义信息,当文本中的句子信息较少时,则需要全局信息对其进行补充。主题模型恰好能够有效地对文本的语义信息进行描述并在一定程度上表示句子的全局信息,传统的主题模型得到的仅仅是文本中词对应的主题分布,在很大程度上忽略了词之间、上下文之间的语义关联,不能够深层次地表示文本的语义信息。对此,本文提出一种基于词和事件主题的模型CNN(Word Event-Topic CNN)对文本进行分类,下简称为W-E CNN。
W-E CNN模型主要包括两个部分:基于事件的词-主题向量生成和CNN运算过程,如图2所示。

图2 W-E CNN结构图
W-E CNN的基本过程可以描述为:(1) 对文本进行预处理,得到分词结果和BTM词对;(2) 利用Stanford工具获取每条语句的依存结构,进而得到事件;(3) 基于事件,利用融入事件知识的BTM方法得到其对应的主题;(4) 对事件进行分解得到对应的词与主题;(5) 将得到的词与主题进行拼接,对词和主题进行向量化表示,得到对应的词-主题向量;(6) 输入至CNN进行学习训练。
W-E CNN网络中的输入层的功能与原CNN层的功能基本一致,只是在原有词向量的基础上,再拼接上主题向量,则其输入可以表示为:
(4)
式中:n为词的个数;wi和ti分别为第i个词的词向量和主题向量;m为维度,词向量与主题向量采用相同的维度,方便后续计算;[witi]表示词向量与主题向量的拼接。
该过程如算法1所示。
算法1基于词和事件主题的文本分类
输入:数据集D,主题集K。
输出:文本类别category。
1. processed text←text preprocessing ofD
//文本预处理
2. word←word segmentation of processed text
//分词
3.B←dependency analysis of word
//依存关系分析
4. fori
5. forj
6. ifei(verb)=ej(verb)
//等同于判断nsubj(verb)=dobj(verb)
7. ifnsubj(sub)∪dobj(obj)≠null
8.B(ei,ej)←(sub,verb,obj)
9. end if
10. end if
11. end for
12. end for
13.Zb←BTM(B(ei,ej))
//BTM主题计算
14. [word,topic]←vectorization ofZband (B(ei,ej))
//得到输入向量
15. category←[word,topic]
//CNN学习训练
16. return category
该方法可以在不增加CNN算法参数运算复杂度的基础上,增加文本的主题特征,将词向量与主题向量作为一个整体输入到CNN网络中进行训练。主题特征可以丰富文本特征,充分利用文本的语义信息,减少了传统基于词的主题模型中因错分主题而导致精度下降的问题,有效提高文本主题的可解释性;而词特征可以弥补事件依存分析中不准确的地方。
3 实 验
本文使用的实验数据来自于搜狗语料库——搜狐新闻数据(SogouCS)[14],该数据收集来自搜狐新闻2012年6月至7月期间国内、国际、体育、社会和娱乐等18个频道的新闻数据,包含的数据有URL、标题、正文内容等,可从搜狗实验室下载得到格式为.dat的数据包,大小为1.43 GB。依据.dat格式对其进行切分得到单篇新闻数据,其基本格式如图3所示。
图3 新闻数据
CNN网络处理的是二维数据,所以在对数据进行处理时,首先要将文本数据转换为特征向量矩阵形式,本文采用Word2vec。Word2vec是一个用于计算词特征向量的工具,它一般有两种方法获取特征向量:一种是使用现有词库中的全局词向量库,这种方法使用的库规模一般十分庞大,如由北京师范大学中文信息处理研究所与中国人民大学DBIIR实验室开发的《中文词向量语料库》[15],该库中包括了知乎、人民日报、百度百科、古汉语等数十种常用语料的训练词向量;另一种方法通过使用者自己对文本语料进行训练得到的词向量库。为方便计算,本文采用后者,通过训练文本语料库,得到一个局部的特征向量库,并通过CBOW方法[16]对原输入其进行转换。
在对数据集数据读取后,会发现其中夹杂着少部分往年新闻数据,对其进行过滤。首先对文本的事件主题提取,因为处理的数据是新闻,文本长度较短,所以参数设置为:迭代次数为500,主题数目为10,每个主题中显示概率最大的3个事件。部分结果如表2所示。

表2 主题提取结果
对NPL处理的分析指标主要有准确率、召回率和F1值。其中:准确率是检验方法的查准率,召回率是检验方法的查全率,F1值是查准率与查全率的综合值。
随机从Sogou CS中选取财经、军事、体育、娱乐四个类别的新闻各1 000篇作为实验数据,其中80%作为训练数据,20%作为验证数据。在结合事件的主题模型中,狄利克雷函数的参数设置均设置为:α=0.05,η=0.1。在W-E CNN算法中,由于新闻文本长度都较短,所以词向量维度设置为200。文献[17]的实验结果表明当卷积核的个数设置为100~200时,提取出的特征比较全面,所以卷积核个数设置为128,卷积核大小为3、4、5,全连接层神经元个数为128个,批尺寸为64,迭代训练次数50次,丢弃率为0.4,学习率为0.001。在对文本进行处理时,可见,由于新闻文本长度普遍较短,所以其长度一般都在50左右,K=50,即CNN的输入向量大小为50×400。
对事件主题和词之间的相辅相成关系进行验证,分别以词为输入的CNN方法(Word CNN)、以事件主题为输入的CNN方法(Event CNN)和本文提出的W-E CNN方法做文本分类实验。实验结果如表3所示。
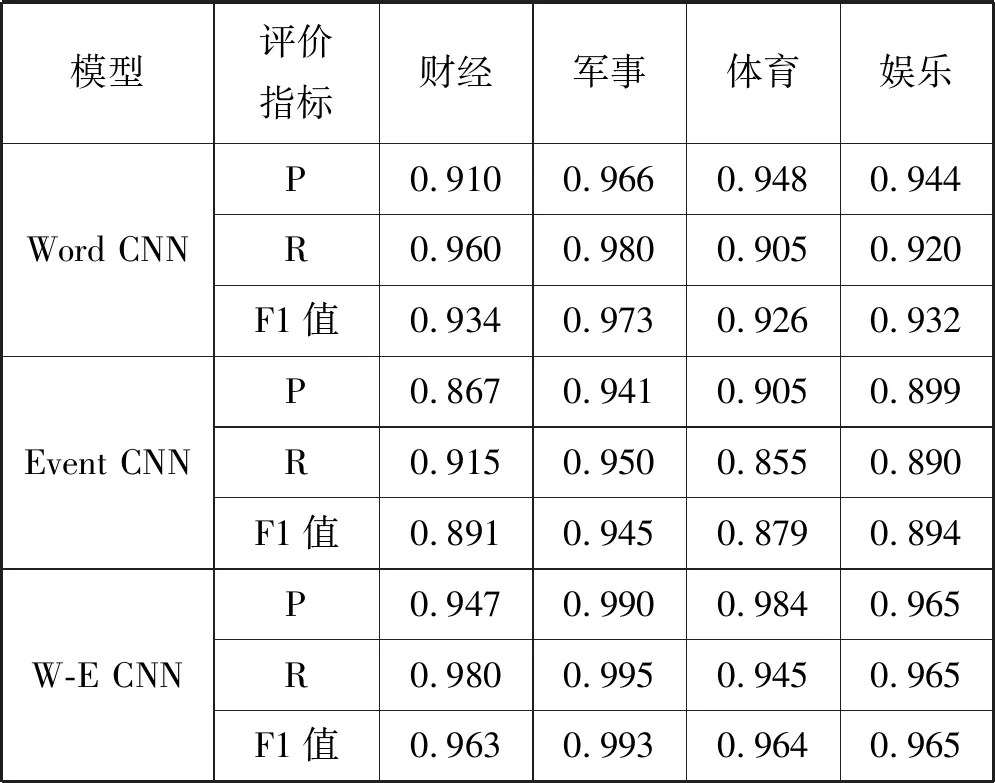
表3 实验结果
可以看出,W-E CNN文本分类方法的效果要优于Word CNN和Event CNN方法,且Event CNN方法的分类结果要劣于Word CNN方法,这说明在对文本依存关系进行分析时存在不准确的地方,而将其与词特征进行连接可以弥补这些不足,而事件主题又可以弥补Word CNN中缺乏语义信息的缺点。
为验证W-E CNN方法较其他方法的优越性,本文进行对比实验,分别为以主题向量为输入的朴素贝叶斯(NB)、K-最邻近(KNN)、支持向量机(SVM)算法和基于词和主题的CNN(W-T CNN)文本分类方法。其中,W-T CNN方法中的主题是指用词对主题进行描述的方法。具体实验结果如表4所示。
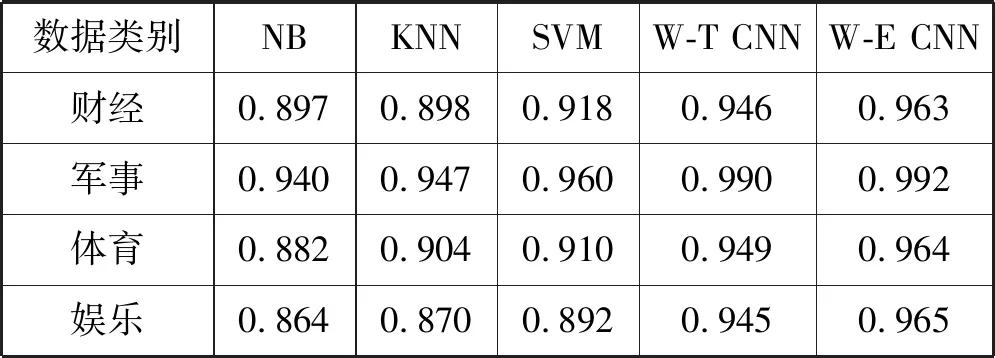
表4 对比实验F1值
通过测试,W-E CNN分类方法的平均准确度、召回率、F1值分别达到了0.972、0.971、0.971。在本实验中,W-E CNN方法要明显优于机器学习中的NB、KNN、SVM方法。通过对比W-E CNN方法与W-T CNN文本分类方法可以发现,无论是准确率还是召回率,W-E CNN分类方法都要高于W-T CNN分类方法,这说明事件主题能够更加地对文本的特征进行提取,更有利于文本语义信息的表示。通过图4所示的运算时间对比可以看出,W-E CNN分类方法在运算时间上要长于基于词和主题的分类方法,这是因为W-E CNN分类方法需要首先对词进行依存分析得到事件,进而决定该词对所属的主题。

图4 W-E CNN分类方法和W-T CNN分词方法的运算时间
为进一步对W-E CNN的学习能力进行更深入的研究,以学习文本数量为自变量进行实验,四类文本从每类文本100篇开始逐渐增加,每增加50篇记录一次结果,其中80%作为训练数据,20%作为测试文本,结果如图5所示。

图5 不同规模文本数量分类方法对比效果
根据实验结果可以发现,当训练文本数量较少时,传统的基于机器学习的分类效能要明显优于W-E CNN方法,而随着训练文本数量不断增加,W-E CNN的分类效果要明显优于其他几种机器学习方法。通过图5可以发现,朴素贝叶斯、K-最邻近、支持向量机方法的学习能力达到一定值后开始趋于平稳,而W-E CNN方法的学习能力则不断增加,这也是深度学习算法相比于机器学习算法的一个优点。
4 结 语
本文针对传统词表示特征时不够全面、可解释性差的问题,结合基于事件的主题模型提出了一种基于词和事件主题的CNN文本分类方法,并给出了基于BTM的事件主题提取方法,能够有效解决词特征稀疏的缺点。将该方法应用于新闻文本分类中,通过实验证明了W-E CNN方法在分类上的优越性,但实验也发现,W-E CNN方法所用的时间要高于基于词和主题的分词方法,这是因为W-E CNN在运算过程中需要组建事件对,再对其进行主题确定所造成的。所以,寻找高效的事件主题表示方式和计算方法及如何提高本文方法在深度学习计算框架上的运算效率是下一步研究的方向。
