基于小波-支持向量机的工业取水异常数据挖掘与重构
2021-05-14薛惠锋
王 晗 张 峰 薛惠锋
1(中国航天系统科学与工程研究院 北京 100048) 2(山东理工大学管理学院 山东 淄博 255012)
0 引 言
在现阶段国内水资源形势严峻与水务基础设施持续建设的情况下,水资源数据管理问题仍然突出。以国家水资源监控能力建设项目为例,通过2012年-2014年期间一期运行实施,取得了海量水资源动态监测数据,但是对水资源管理决策支持力度偏弱,主要原因在于数据的完备性、真实性不足,特别是在水体监控、取水许可分析上还存在严重的数据缺口[2]。根据智慧水务对水资源保障和数据管理的需求,目前最为关键的是确保数据的真实性、有效性,构建与智慧水务标准相一致的水资源数据管理体系。
基于水资源数据处理工作的重要性与迫切性,已有相关学者对其进行基础性探索,主要集中在:1) 水资源数据处理与关联性分析。按照水资源数据管理的实际业务需求,数据的基础处理与关联特性分析成为其研究热点,但由于缺乏规模样本数据,多聚焦于适用于小样本的算法优化。如:Reitsma等[3]提出采用面向对象技术模拟的水资源数据多准则评价模型;Dietrich等[4]利用不同水资源评价指标间的关联特性提出湿地水平衡模型,其功效在于简化规模数据输入,但易影响数据准确性;Park等[5]针对农业水资源数据管理的复杂性,采用数据聚类算法及Web数据处理技术,构建了其水资源数据集成模型;Slaughter等[6]基于流域水质数据的稀疏特性,提出引入流量参数控制的方法建立水质系统评价模型;吴海斌[7]采用曲线回归拟合模型提升水环境监测数据预处理的自动化水平;刘家宏等[8]构建复杂水资源系统蓄调计算的数据时变耦合模型,用于提升供需水平衡的评估精度;徐梅等[9]应用灰色理论、小波变换和自回归异方差函数构建流域水质组合预测模型,并验证了其模型的精度。2) 水资源数据挖掘与融合研究。以水资源数据可用性与问题研究需求为导向,水资源数据挖掘的探索集中在水文数据、防洪决策支持系统数据、城市供水数据等方向。Salah等[10]选取决策树方法对底格里斯河水质数据进行挖掘,取得了评估水质质量的关键参数及其状态变化规律;同为对水质数据的研究,Junior等[11]以监测数据为样本,基于不同参数的分析提出基于规则分类的水质数据预测模型;Ioannou等[12]采取自组织映射数据挖掘方法分析家庭用水量数据,并界定了该方法适用的时序统计数据类别;曾羽琚[13]在将样本扩展到水生态数据的基础上,提出双曲方程特征分解数据挖掘方法;张峰等[14]利用粒子群优化支持向量机方法处理国家水资源监控能力建设项目中的异常数据。而考虑水资源数据的多元特征,国外对于水资源数据融合的探索较少,主要集中于多传感器数据融合,如:Pour等[15]采用距离函数改进参数权重来体现传感数据随机特性;Cammalleri等[16]选取函数映射模型融合卫星与地面观测水资源监测数据,并验证了数据融合误差可控性。相比之下,国内数据融合的研究更加侧重于应用创新,王恭等[17]利用数据融合算法测算水质参数与连排流量的关系,提升系统抗干扰能力;李洋漾等[18]采用跟踪动态规划算法实现多传感器的多目标融合,并运用变转移状态数优化融合效率;张春丽[19]针对高维数据聚类效果的弊端,提出用分形维数来改进投影聚类的算法。
综上,现有相关研究的积累较好地推动了水资源管理向科学化与智能化发展,但是对水资源数据完备与真实性不足、决策支撑效用偏低等问题的研究深度仍待提高。尤其是在国内重点推进最严格水资源管理制度及国家水资源监控能力建设的背景下,以工业企业为代表的取用水大户是水资源监测的重点对象,如何针对目前已取得的工业取水监测数据,深入挖掘其变化规律和问题特点,并有效解决水资源监测数据呈现出体量足而决策支持效用低的难题至关重要。值得注意的是,由于目前国家水资源监控能力建设项目尚处于推进期,工业取水监测数据规模体量虽然较大,但缺乏不同历史年份下的同时期数据进行参考,数据的截面性较强而面板累积性不高,这就增加了提高水资源监测数据质量的难度,急需探索实用性强的数据分析方法。据此,该文按照“粗筛选-精识别-再重构”的思路,提出基于分段拉依达准则(3σ)与小波变换、Fourier函数融合的工业取水监测异常数据的识别方法,采用自适应惯性函数与粒子群优化的最小二乘支持向量机模型重构异常数据,并利用国家水资源监控能力建设项目所取得的重点取用水户数据进行验证。
1 工业取水监测数据异常状态
通过国家水资源监控能力建设项目一期所获取的工业取水监测数据的稽核分析,可归纳出现阶段常出现的数据异常点主要包括以下几种情况。
(1) 零值监测数据。主要反映在取水数据时序动态监测过程中,某些时刻监测数据由正常非零值波动状态突变为零,其后再次回归常规波动趋势。若按照正常理解,该状态表示取水户未进行取水行为。
(2) 非零数值的显著性突变。体现在取水监测数据波动过程中,局部监测点的数据呈现出突变幅度异常偏大或偏低的状况。这意味着取水户在该时刻一次性取水量远超出或低于正常运行的企业用水。
(3) 非零数值的无波动衡定。即随着时间的推移,取水监测数据不是零值状态,但取水监测曲线未出现任何升降。这表示取水户较长时间内固定式批量取水,与正常运行的工业企业实际取水需求不符。
(4) 数值断点。即数据缺失状况,表现在取水监测曲线上为监测数据断点,通常可包括间断性数据断点和连续性数据断点两种类型。
(5) 逆季节性数值波动。按照对不同类型的工业取用水户进行数据对比观测及调研分析,受季节性生产需求的影响,其取水特征总体上呈现夏季偏多而冬季偏低的规律,而实际监测过程中会出现与上述规律相悖的现象。
上述5类工业取水监测数据的异常状态基于截面数据的分析可较易识别。但是在实际监测中还存在一些难以通过简单的统计手段发现的异常值,如数据突变强度不高但仍与其实际取水量不符的数值,这就需要建立相应的数据挖掘模型对其异常数据进行判定与重构,这也正是目前国家水资源监控能力建设项目重点推进的核心工作内容之一。
2 模型构建
鉴于目前可获取的工业取水时序监测数据中通常会存在数值为零、突变等状况,若直接采用3σ准则会容易受到上述异常值的影响,造成其阈值区间范围偏差过大,而无法实现异常数据的有效识别[20]。但同时考虑到工业取水监测数据通常具有“季节性”周期波动规律,即不同季节之间工业取水量整体上存在较为显著的差异性,而同一季节内工业取水量虽然成持续波动状态,但其波动幅度要显著低于季节之间的变化幅度。因此,可尝试采用分段式的3σ准则应用策略,将各年度按照不同季节划分为4个子区间,各子区间分别利用3σ准则确定取水监测数据的初步认定正常范围,以此完成数据的“粗筛选”。该过程是对前文概述的典型异常工业取水监测数据进行初步筛选,避免由于突变幅度过高、零值数据等影响后面采用小波变换和Fourier函数对取水监测数据正常阈值区间划定的准确性,进而导致异常值判断准确度受损。
2.1 基于小波变换-Fourier函数的异常数据识别模型
小波变换是信号处理领域中的常用方法,其优点在于充分挖掘时序数据的时空频率局部变化特点,采用伸缩平移算法对其进行多尺度细化,提高时频数据的自适应分析能力[21]。工业取水监测数据从采集、传输到存储的基本流程具备信号传递与分析过程的基本特征,同时,取水监测时频数据不仅具备一定低频序列,还存在较多高频序列,满足小波变换应用的要求。据此,提出采用小波变换模极大值(WTMM)方法处理取水监测时频数据,采用降噪的方式分离其高低频序列,进而通过误差控制方法识别异常数据。其表达式如下:
(1)

利用WTMM方法时,若对于尺度a0下的∀τ,都满足|WTf(a0,τ)|≤|WTf(a0,τ0)|不等式条件,且两端邻阈符合|WTf(a0,τ)|<|WTf(a0,τ0)|,则可认为(a0,τ0)属于|WTf(a,τ)|于a0下极大值点,|WTf(a0,τ0)|被命名为|WTf(a,τ)|在(a0,τ0)上的模极大值。该点即为时频函数f(x)经过小波变换后求解的最大值,从小波模型运算机理上来看,这类数值对应的是样本数据中数值增大或降低等突变幅度较高的点。而对于工业取水监测数据样本中,其异常数据的表征状态除了前文概述的5类直观性数据,其他非直观性异常数据通常是属于幅度突变型。据此,将小波求解的模极大值所对应的点暂定为监测数据异常点,其后需要根据人工数据反馈校验判断异常值的真伪。
根据上述解释,工业取水监测过程中导致数据点出现异常的原因较为复杂,而利用WTMM方法可对其监测数据进行不同时频下的数据序列波动特征的动态分解,挖掘最能表征数据时频变换的波动曲线。但该过程还需要对取得小波模极大值后的数据序列进行重构,具体包括:(1) 确定小波变换的最大尺度及其所对应的极值阈值区间,保留阈值区间内的极大值点;(2) 分析所设定尺度下与极大值所在点相应的数据位置,并剔除非极大值点的数据;(3) 采用交替投影算法对筛选出的极值点进行小波重构。
选用WTMM重构工业取水监测数据时,通常会剩余部分残差序列,这类序列仍属于时频数据,而且其高频特征较显著。由于残差序列中也涵盖了部分原始监测数据的潜在变动特点,若直接将残差序列进行剔除,则易造成数据信息的损失。因此,提出利用Fourier函数修正小波重构残差序列。Fourier函数较强的降噪功能使其不仅可以有效补偿WTMM重构导致的随机误差,同时还能较大限度地滤除取水监测时频数据残差中噪声,进而提高时频拟合精度。过程如下:
步骤1设定时频残差。
V=[V(1),V(2),…,V(n)]
(2)
步骤2利用Fourier变换残差。
k=2,3,…,n,T=n-1
(3)
(4)
(5)
把V(1)=0代入式(3):
(6)
步骤3根据式(4)-式(6)和时频残差,计算an、bn和a0值,进而确定Fourier变换残差V。
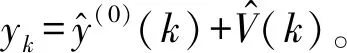
2.2 基于惯性函数-粒子群优化的支持向量机数据重构模型
最小二乘支持向量机(LSSVM)是机器学习高维模式识别的常用方法之一,其良好的泛化性能和非线性拟合效果,以及较快的计算速率等特点正是解决工业取水监测异常数据重构问题的需求方向[22]。据此,提出利用LSSVM模型重构取水监测异常值,并选取自适应惯性函数调整后的粒子群对LSSVM模型的核函数进行优化,提高数据重构精度。基本流程如下:
y(x)=ωTρ(x)+b
(7)
式中:ρ(x)表示映射函数;ω为权重向量;b指偏置向量。按照式(7)表达LSSVM目标函数:
(8)
式中:θ为误差项;γ表示惩罚因子,γ>0。利用Lagrange函数对其转换:

(9)
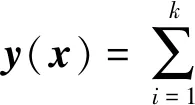
(10)
考虑RBF核函数处理非线性映射关系的良好转换能力,取其作为模型的核函数:
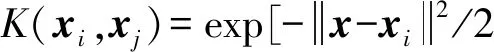
(11)
(12)
式中:L为粒子间最大距离;ο是粒子数;aid表示粒子坐标。为避免粒子群产生早熟而造成测算结果出现偏差,采用粒子方差控制其误差状态,即:
(13)
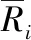
(14)
(15)
式中:s表示惯性因子;Vid指粒子速度;χ表示加速因子;Qid指个体极值;Qpd指全局搜索极值;Sid为粒子位置;r为[0,1]区间内的随机数。PSO中,惯性因子s的取值直接影响到粒子的收敛精度,而鉴于粒子极值搜索中的随机性特征,本文借鉴Feng等[23]提出的基于混沌优化理论的惯性权值调整方法,该方法在处理离散时频数据中已得到相关学者的验证[24],其表达式为:
s(t)=(Smax-Smin)(UM-Ut)/DM+Smin·
q·rand·(1-rand)
(16)
式中:UM、Ut分别表示最大与当前迭代次数;rand表示[0,1]区间内的随机数;smax和smin分别表示惯性因子在粒子搜索初期与结束期的取值;q表示混沌系统控制系数。
根据惯性函数-粒子群优化的支持向量机模型,对剔除WTMM与Fourier函数所识别异常数据后的取水监测数据样本进行训练拟合,进而通过误差分析来验证模型的有效性,并完成对异常数据的重构恢复。
3 实验与结果分析
3.1 数据说明
本文选取国家水资源监控能力建设项目所取得的工业取水数据为样本,以广东省某工业企业取水数据为例,对其2017年1月5日至2017年12月20日期间数据进行统计,见图1。将该段时间内原始取水监测数据序列记为Da_i,且根据其数据波动曲线可以观测到样本区间内存在部分数值突变、为零等异常状态。
3.2 基于3σ准则的取水监测数据粗处理
受企业生产计划的影响,通常工业企业的取水监测数据呈现出来的季节性波动规律特征较为显著,若直接选取3σ准则评估其取水监测数据时,则易受到突变数据(含零值)的影响而导致正常数据的阈值区间被拉大,会造成异常数据判定存在较大误差。但是相比之下,同一季度中工业取水监测数据变动幅度相对较小。因此,本文考虑取水监测数据的季节性周期的波动特点,将3σ准则拓展应用到不同季节下的取水监测数据异常值分析中,即分别测算各季节下的工业取水监测数据3σ区间,通过分段式3σ准则筛选超出该阈值区间的异常数据,实现对监测数据的粗处理。其中,3σ区间下限为负时将数值设为零,如图2所示。
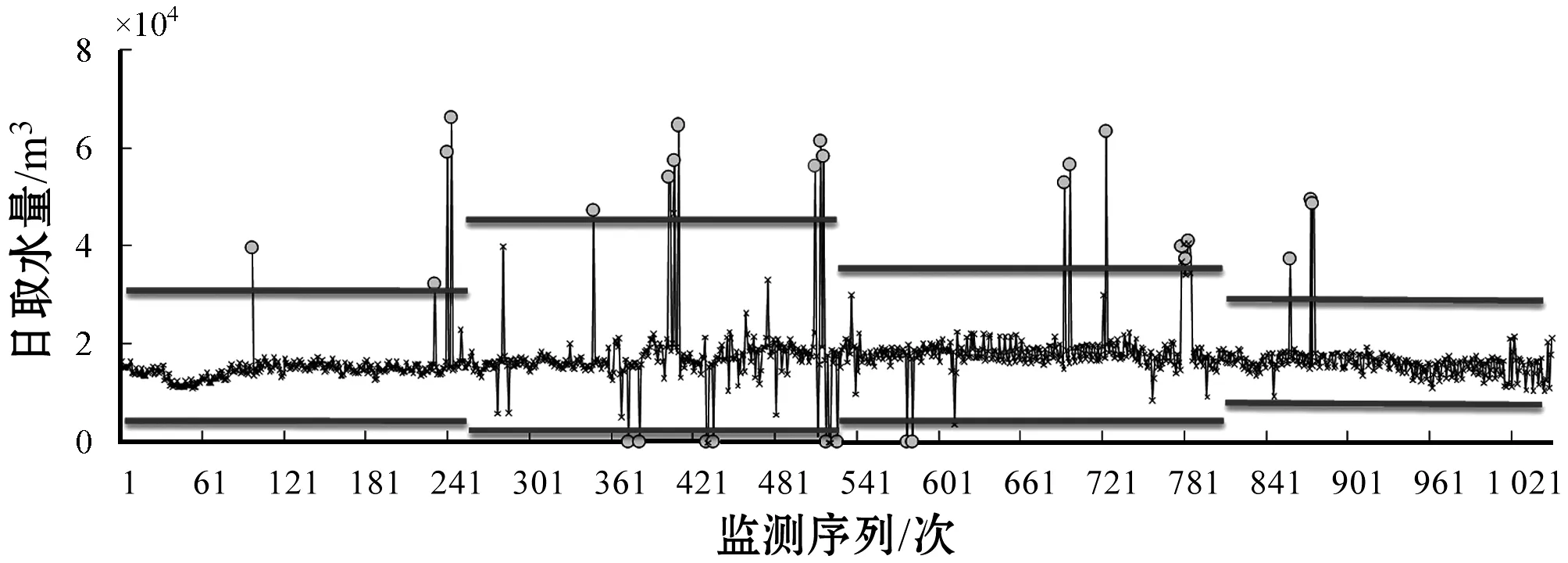
图2 基于3σ准则的取水监测数据分析
注:横线表示3σ上下阈值;圆点表示超出阈值区间的异常数据。
观测图2中对取水监测数据的粗处理结果,同时利用3σ准则测算出的数据阈值区间从左到右依次分别为(715.16,29 853.99)、(0,41 509.05)、(953.06,37 029.70)、(4 724.50,27 928.94),且在上述阈值区间之外的数据共有26项。若直接对样本数据采用3σ准则,则划分的异常数据边界为(0,35 475.23),过大的阈值范围导致较多的突变数据未能得到有效的识别,同时也会对后期数据重构过程中的样本数据拟合造成影响。通过各季节下的分段式3σ准则提取出的异常数据具有易识别的特点,但这也仅是部分直观性的异常数据,而对于隐含在剩余工业取水监测数据序列中的非可直观辨识数据难以进行有效判断(见图3,记为Da′_i)。对此,本文尝试采用WTMM方法和Fourier函数对去除3σ准则所判定出的异常数据序列进行分析,进一步挖掘取水监测时频数据中潜在的异常值。
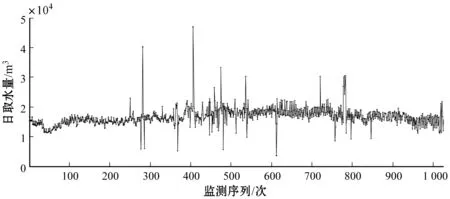
图3 取水监测数据的粗处理序列
3.3 基于WTMM-Fourier函数的取水监测数据处理
在数据粗处理的基础上,按照式(1)对Da′_i实施离散小波变换,取得离散小波最大分解尺度下的小波基及其模极大值序列,见图4。可以发现,不同尺度下的小波极大值序列能够较好地分别体现出取水监测时频序列的低频与高频特征。而按照Lipschitz指数[25],进一步可以判断出,随着小波分解尺度的提高,取水监测时频序列中的白噪声密度逐渐降低,这表示其小波极大值主要集中在高分解尺度下的时频数据内。考虑到传统小波变换中测算模极大值时通常是采用逆小波的方式,这种将小波系数进行零值转化的方式虽然计算简便,但是易造成测算结果的偏差。本文选取Mallat交错投影法[26],利用不同尺度下分解的小波模极大值序列,对取水监测数据进行分尺度时频重构(见图5),在此基础上,结合小波系数完成对时频监测序列的逆变换,对各尺度下的重构数据进行集成处理,取得新时频序列Da″_i。

图4 各尺度下小波模极大值序列分解

图5 小波重构变换
观测图5中重构曲线可知,重构序列Da″_i可以实现对取水监测数据的总体变化趋势特征的表征,但由于在数据降噪重构的过程中将部分数据误判为高频噪声并进行剔除处理,造成重构信息的损失,影响了重构序列对局部取水监测数据特征的有效反映,而小波变换本身无法实现对这类已损失信息的再处理。因此,本文进一步利用Fourier函数对Da″_i重构过程中剩余的残差序列进行修正,挖掘可补充于WTMM方法重构序列的取水监测数据信息。通过测算图3中取水监测数据的粗处理序列Da′_i和序列Da″_i之间的残差Er′,采用Fourier函数对Er′及小波变换重构数据进行数据的再重构,取得残差修正的序列Da‴_i,见图6。比较小波变换及其与Fourier函数重构数据序列,可发现利用Fourier函数修正的Da‴_i能够在小波重构数据表征取水监测数据变化特征的基础上,进一步完善其局部监测点的数据变化情况,从而更为精准地反映工业取水的总体变化趋势。
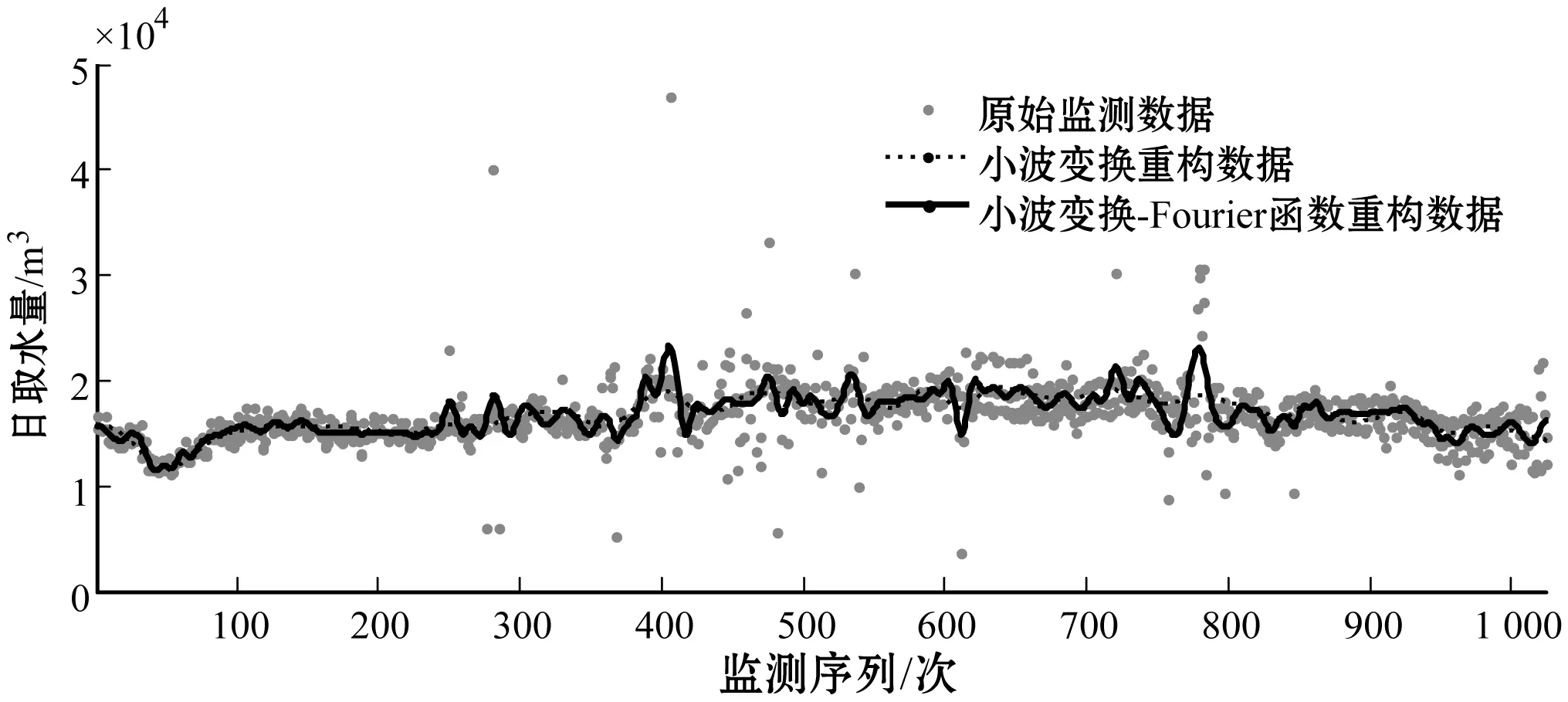
图6 基于WTMM-Fourier函数重构数据序列
通过分析WTMM-Fourier函数重构的Da‴_i序列与粗处理序列Da′_i之间的相对误差Err′来进一步识别取水监测数据的异常值,见图7。其中,按照国家水资源监控能力建设项目中取水监测数据的规模统计经验,设定Err′的正常数据区间为[-0.5,0.5],若|Err′|>0.5,则认为取水监测值呈异常状态。依据该标准可挖掘Da′_i序列中存在异常数据为12项。综合上述分析,通过WTMM-Fourier函数残差修正方法能够较为有效地识别取水监测时频数据中的异常点。为便于观测,将异常数据的值设为零,从而更为清晰地辨识异常点在序列中的具体位置,如图8所示。
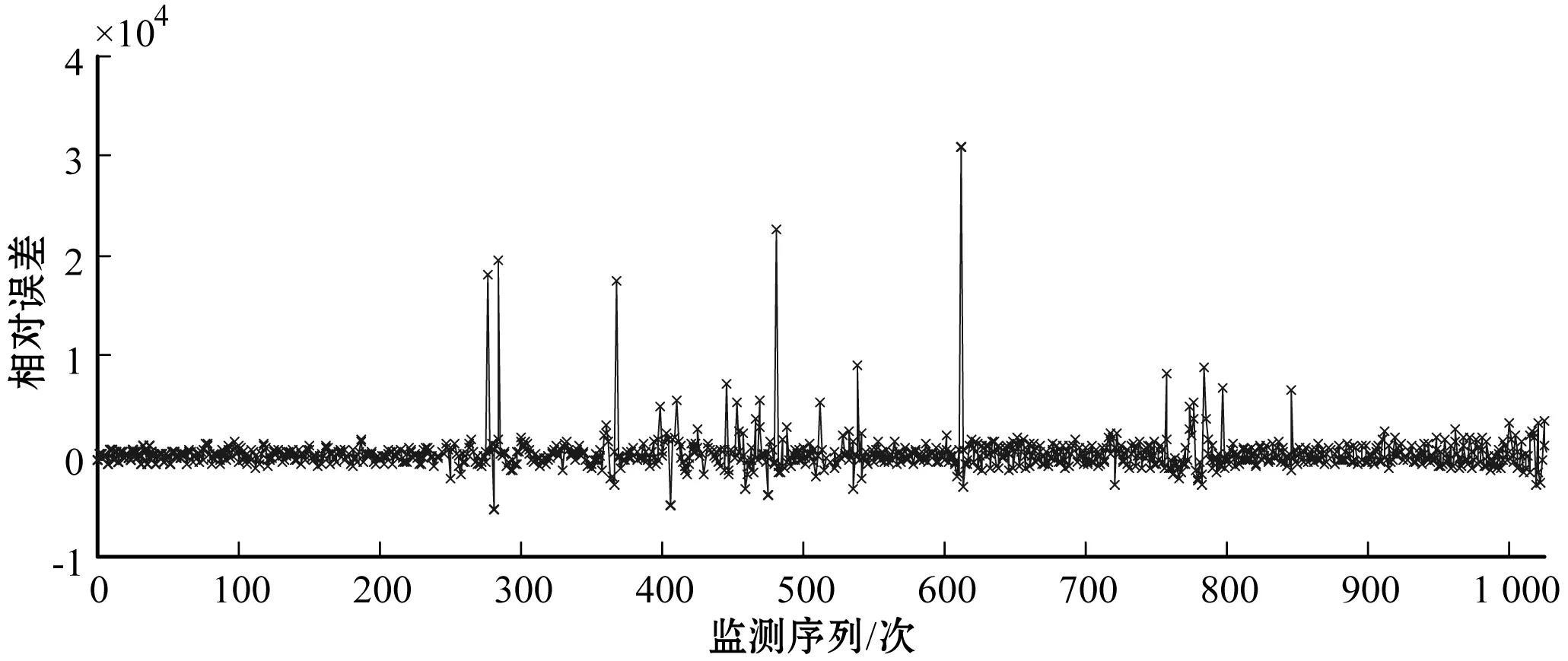
图7 WTMM-Fourier函数重构数据的误差序列
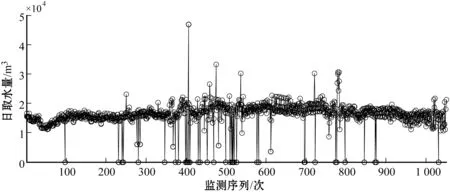
图8 基于3σ准则和WTMM-Fourier函数识别的异常数据
为进一步体现所提出的采用3σ准则和WTMM-Fourier函数识别取水监测数据中异常值的有效性,引入经典统计学中箱线图进行同样本测算,其结果见图9。可以看出,采用箱线图方法对取水监测数据序列Da_i的异常值挖掘数目为11项,要明显低于基于3σ准则和WTMM-Fourier函数识别的异常数据项,其部分异常数据未能够得到有效的挖掘,同时由于忽视工业企业季节性取水波动规律特征,容易导致异常数据识别能力受限而造成监测数据对水资源管理决策的支持力度不足。
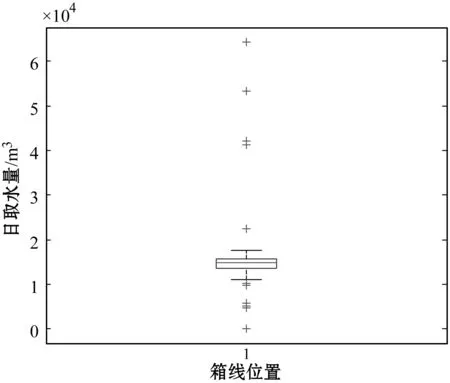
图9 基于箱线图的取水监测数据异常值分析
3.4 利用惯性函数-粒子群优化的支持向量机重构异常数据
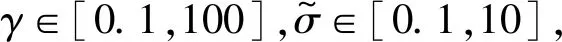
(17)

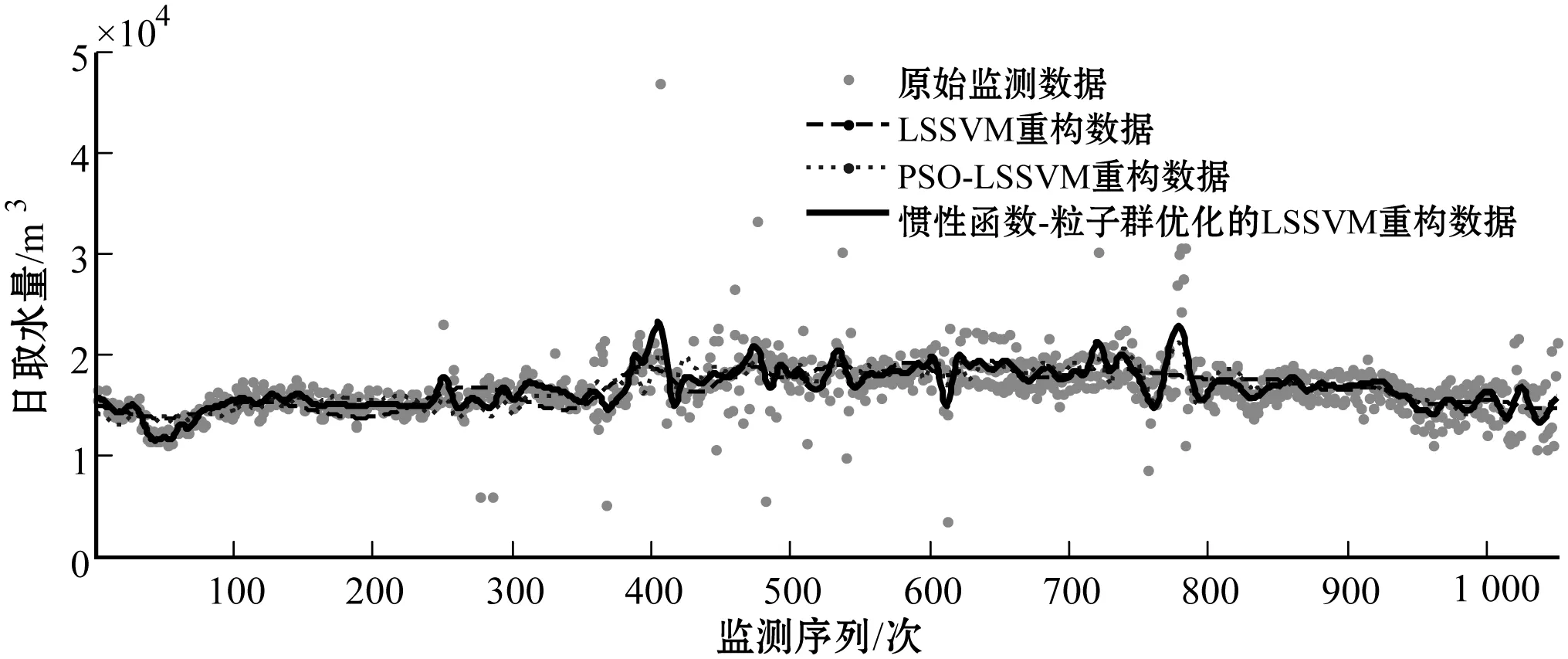
图10 不同类型支持向量机数据样本拟合结果
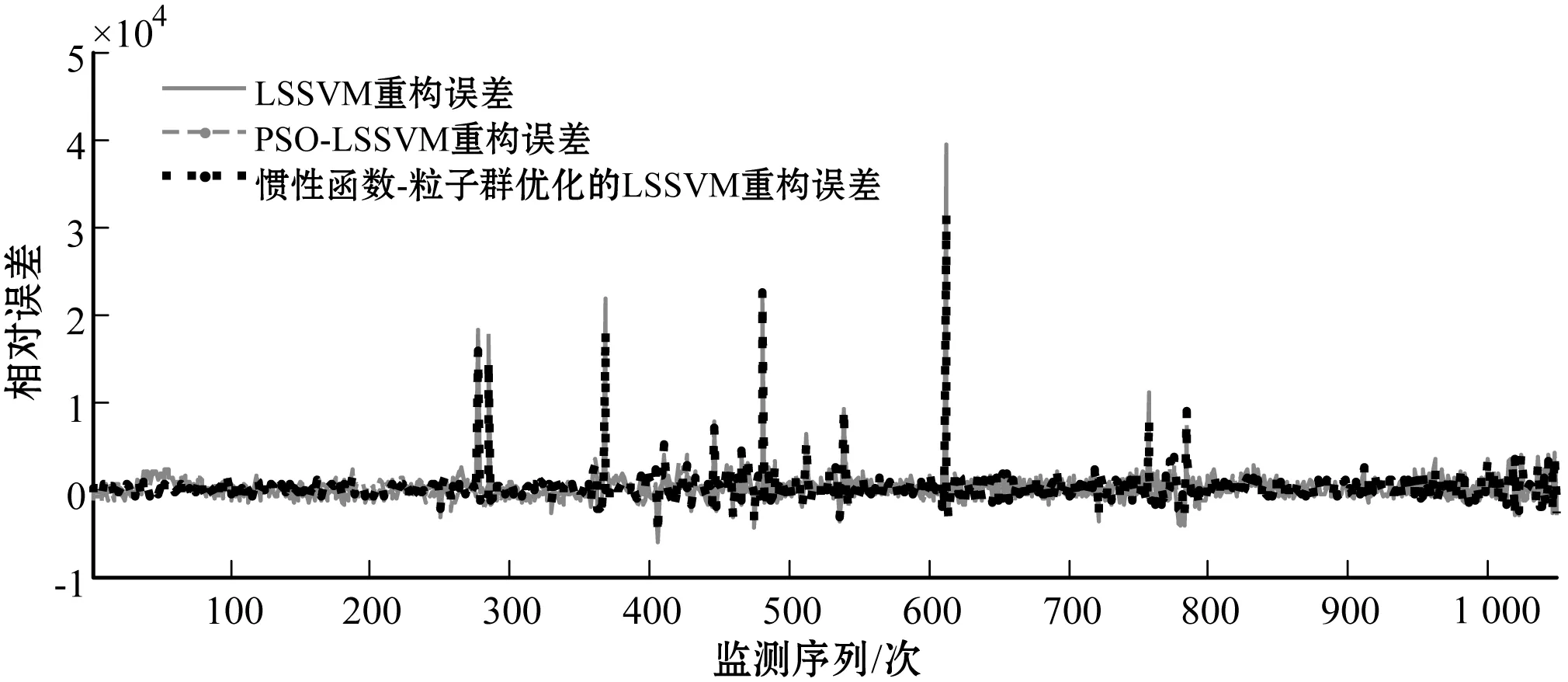
图11 不同类型支持向量机数据样本拟合误差
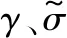
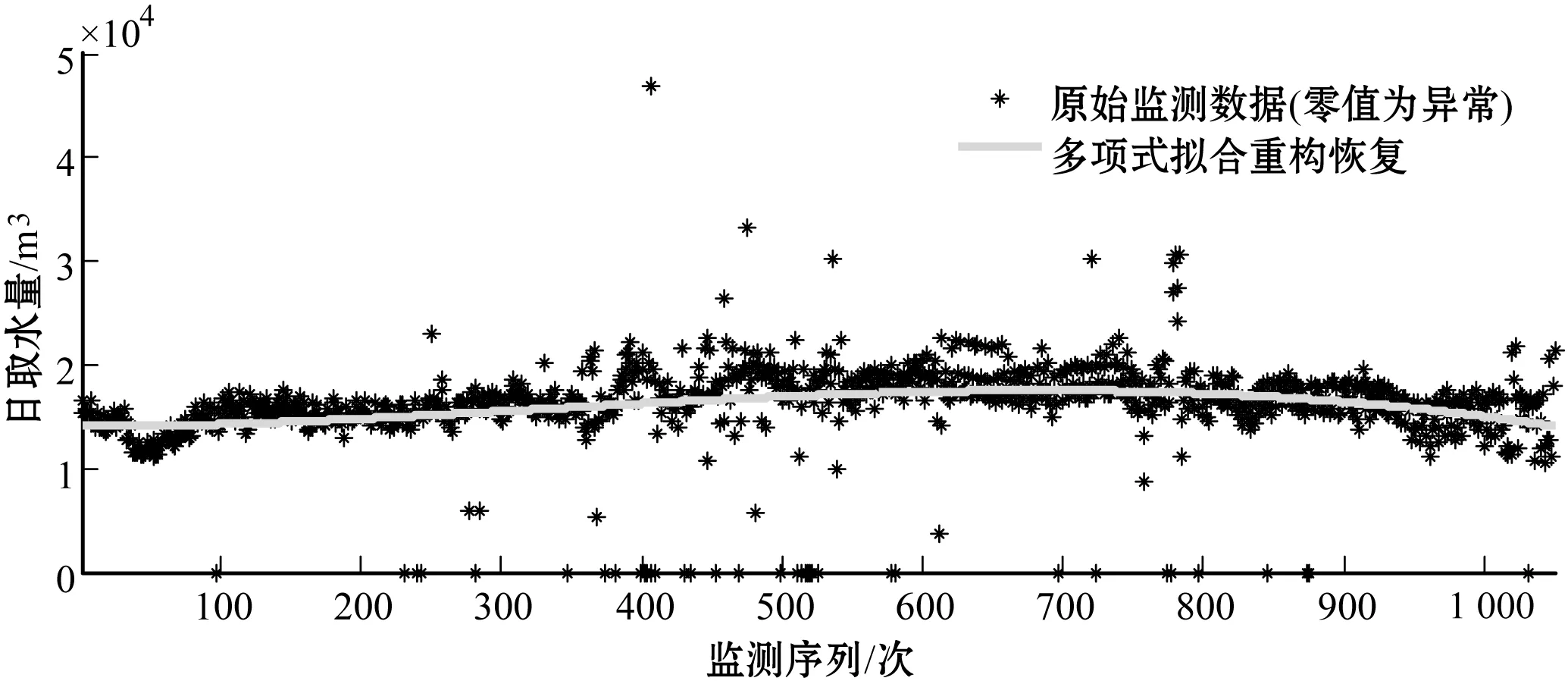
图12 基于曲线拟合的异常数据重构恢复
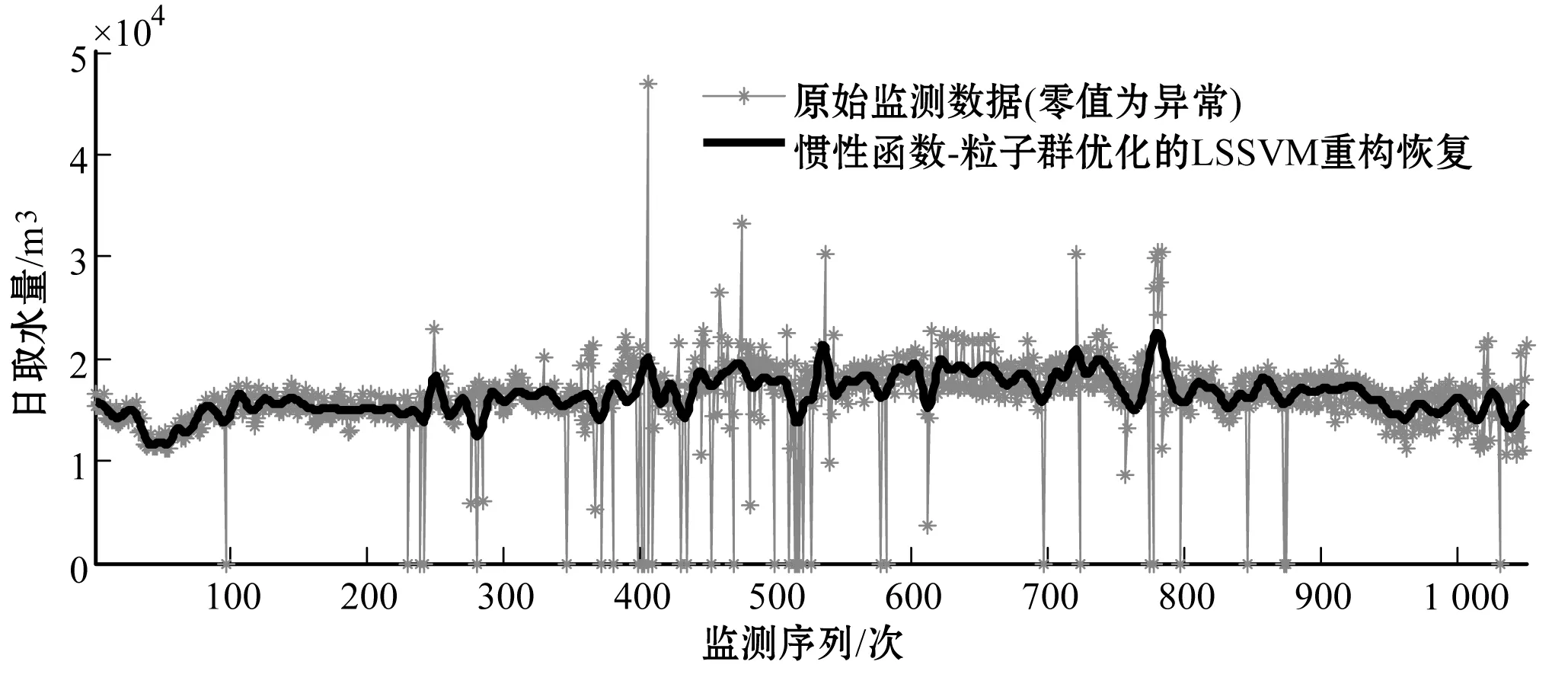
图13 基于惯性函数-粒子群优化的LSSVM异常数据重构恢复
3.5 分析讨论
从方法的适用性与可操作性角度,目前国家水资源监控能力建设项目取得的取水监测数据呈现出“截面数据规模大而纵向数据体量小”的现状,即由于项目推进年度较近,虽然数据规模总量较大但还尚未取得较长历史年份下的时间序列数据,这就造成了同一监测对象在不同历史年份下的取水监测可对比性差,也提高了异常数据挖掘的难度。但面对加快提升水资源数据管理与决策支持的需求,提高取水监测数据质量又势在必行,因此基于当前取水监测能力及数据样本提出有效的异常数据分析方法迫在眉睫。基于上述状况,本文提出的采用3σ准则和WTMM-Fourier函数识别取水监测数据中异常值的策略,能够基于分段式3σ准则的数据粗处理过程将取水监测量季节性波动规律特征考虑在内,从而选取小波变换与Fourier函数对其中的异常数据实现深度挖掘与有效辨识。其中,小波WTMM变换可以实现取水监测序列中的高低频数据的分离,在维持原始取水监测序列时序特征的基础上完成数据的重构,而Fourier函数则是对上述重构残差序列中取水监测数据波动特征的再次提取,提高取水监测数据的整体重构精度。由实际检验情况可知该策略的重构精度要显著高于传统统计方法。
从方法的有效性角度,现阶段国家水资源监控能力建设项目推进中出现的数据异常状况,可大致分为“需求型异常”与“非需求型异常”两种类型。前者是指受人为操作、环境干扰、设备损坏等因素导致的取水监测数据出现异常,这类异常不是取水数据状态的真实反映,需要被修正;后者是指由取用水户实际取水需求与行为引发的监测数据突变的情况,这类数据是对真实取水状况的反映,不需要再进行数据重构修正。本文采用3σ准则和WTMM-Fourier函数联合识别的取水监测异常数据共38项,而通过将异常数据反馈至取水监测户进行二次校验,发现其中“需求型异常”数据有31项,异常数据判断准确率达81.6%,利用惯性函数-粒子群优化的LSSVM模型重构恢复的取水监测异常数据与校对反馈真实值对比,发现其重构误差率均低于5%。同时,取水监测数据重构曲线对整体与局部数据变动趋势及季节性周期波动特点均具有良好的体现。由上可见,本文提出的工业取水监测异常数据的多尺度挖掘与重构策略相对有效,还可将其拓展至其他相关领域进行监测数据分析。
4 结 语
通过梳理目前国家水资源监控能力建设项目实施中出现的水资源异常状态,提出运用3σ准则和小波模极大值变换-Fourier函数相结合的工业取水监测异常数据识别方法,并根据传统LSSVM模型样本训练的特点,提出采用惯性函数-粒子群优化的LSSVM异常数据重构恢复模型。实例验证发现,在考虑取水监测数据季节性波动特征的基础上,运用分段式的3σ准则能够实现对取水监测数据的粗处理,避免了由数据突变引起判别区间过大而易导致异常数据识别不充分的弊端;而进一步利用小波模极大值变换模型可以完成监测数据的高低频分离与重构,但重构过程中存在数据信息损失问题,采用Fourier函数残差修正的方式可以有效解决上述问题,提高样本拟合精度,从而实现对取水监测数据的有效识别。经过惯性函数-粒子群优化的LSSVM模型可满足异常数据较高精度的重构恢复需求,其重构精度要强于LSSVM及其被粒子群优化的模型。上述工业取水监测异常数据的多尺度挖掘与重构策略不仅可为国家水资源监控能力建设项目提供方法支持,还可为其他相关领域的数据挖掘提供技术参考。
