深度学习说话人识别中语音特征参数提取研究
2021-05-13张兴明杨凯
张兴明,杨凯,2
(1.四川大学视觉合成图形图像技术国防重点学科实验室,成都610065;2.四川川大智胜软件股份有限公司,成都610045)
0 引言
近年来随着深度学习技术的迅猛发展和计算机硬件设备的计算能力大幅提升,生物特征识别技术的研究进展迅猛。部分生物特征识别技术已趋于成熟,逐渐在从学术研究阶段走向商业应用阶段。在众多生物特征识别技术中,声纹识别技术相比于其他生物特征识别技术,它有着其独特的优势:安全性高、隐私性弱、采集便捷、非必须接触等。正是由于声纹识别所具有的这些独特优势及其应用价值,使得越来越多的研究者投入到声纹识别技术的研究中。
近年来,得益于深度学习技术强大的学习能力,使得基于深度学习的说话人识别研究成为说话人识别领域的一个研究热点。2014 年Google 提出了d-vector[1]识别模型,它将Filterbank 特征参数作为模型输入,使用DNN 网络构建了一个简单的识别模型,将最后一个隐藏层作为说话人特征。它仅使用一个简单的网络模型,就取得了不错的识别效果。d-vector 对说话人识别研究贡献巨大,它掀起了基于深度学习的说话人识别研究热潮。通过阅读相关文献,发现大多数研究使用的是单一的传统语音特征作为模型输入数据,x-vector[2]识别模型使用24 维Filterbank 特征参数,h-vector[3]识别模型使用20 维的MFCC 特征参数,百度在2017 年提出的deepSpeaker[4]系统使用的是64 维的Filterbank 特征。还有少数研究使用神经网络来学习语音特征。Chen Nanxin 等人[5]提出的j-vector 识别模型使用深度神经网络来作为一个特征提取器,通过训练后该特征提取器可以学习得到语音特征。2018 年Ravanelli 等人[6]提出使用SincNet 来进行说话人识别,该网络直接从原始语音信号中自动学习语音特征,不依赖于传统的手工特征。仲伟峰等人[7]提出了一种深浅层特征融合的方式来提取语音特征用于说话人识别,他们使用深度神经网络来学习语音的深层特征,然后将深层特征与浅层特征相结合一同作为语音特征。本文采用融合特征的方式来进行特征参数提取,并设计了多种融合方式,以找到合适的特征提取方案,用于后续的说话人识别研究。
1 语音特征参数提取
在基于深度学习的说话人识别中,首先我们需要将语音信号转换成可以作为模型输入的数据,且该输入数据还必须要携带较多的说话人信息。之前的研究多采用的是单一的传统语音特征参数来作为模型的输入数据。常用于说话人识别的传统特征有:梅尔倒谱特征参数、Filterbank 特征参数和语谱图特征参数。
1.1 传统语音特征参数
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)是基于人耳听觉特性设计的,梅尔频率倒谱频带划分是在Mel 刻度上等距划分的,频率的尺度值与实际频率的对数分布关系更符合人耳的听觉特性,所以可以使得语音信号有着更好的表示。Filterbank 特征参数的提取方法就是在梅尔倒谱特征参数提取过程中去掉最后一步的离散余弦变换。与梅尔倒谱特征参数相比,Filterbank 特征参数保留了更多的原始语音信息,且提取该特征参数时计算耗时较短。频谱图特征参数表示随着时间变化,频率与能量之间的关系,可以直观的看到静态和动态的信息。
1.2 多特征融合参数
既然大多数研究者大多使用了单一特征参数来进行说话人识别研究,同时也证明了这种单一特征参数的方式是有效的,那么将这些单一特征进行融合而生成的融合特征,其包含了更多的不同类型、不同维度的特征参数,理论上,这些特征参数更加有利于模型从中提取出更加深层(抽象)的说话人特征。基于这样的假设,本文采取了多种特征融合方式,生成多种融合特征,来进行对比研究。
1.3 数据处理及特征提取
对语音信号进行分析,提取特征参数时,首先要进行分帧和加窗处理。语音信号具有短时平稳性,对语音信号的分析和处理须建立在“短时”的基础上,即将一段语音信号分为多帧来分析其特征参数,帧长一般取为10-30 毫秒。为了使帧与帧之间平滑过渡,保持其连续性,前一帧和后一帧会保留重合部分。后一帧对前一帧的位移量,简称为帧移。本文选取的帧长为25 毫秒,帧移为10 毫秒。分帧之后就要进行加窗操作,本文采用汉明窗函数来进行加窗操作。
语音进行预处理之后就可以开始提取语音的特征参数,本文提取了7 组不同的特征参数来进行特征参数提取研究,它们分别是:20 维的MFCC 特征参数、20维的Filterbank 特征参数、128 维的语谱图特征参数、40 维的MFCC 与Filterbank 融合特征参数、128 维的MFCC 与语谱图融合特征参数、128 维的Filterbank 与语谱图融合特征参数、128 维的全融合特征参数。各特征信息说明见表4。
2 说话人识别模型
本文为研究适合于深度学习说话人识别的语音特征参数,基于卷积神经网络(Convolutional Neural Networks,CNN)[8]构建了一个浅层的说话人识别模型。整个模型由输入层、卷积层、特征维度转换层、平均池化层和全连接层构成。其中,卷积层用于提取说话人的深层(抽象)特征,平均池化层用于将帧级特征转换为语句级特征,全连接层主要用于特征降维。在训练时,以交叉熵作为损失函数,最后一层采用Softmax 作为激活函数,进行一个多分类模型训练;在预测时,去除Softmax 层,将最后一个隐藏层得到的向量用来表示该语句对应说话人的特征向量。根据输入特征的参数维度的不同,模型的参数设置也有细微的不同。
输入特征参数为128 维时的识别模型的结构及其参数设置如表1 所示。
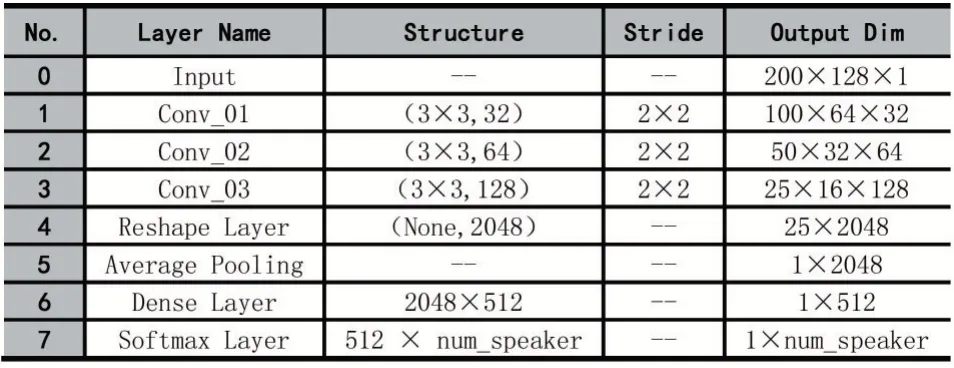
表1 128 维输入特征时的识别模型参数配置
输入特征参数为20(40)维时的识别模型的结构及其参数设置如表2 所示。

表2 20(40)维输入特征时的识别模型参数配置
3 实验及结果分析
为了研究不同的语音特征参数作为模型输入时对模型性能的影响,本文首先对数据集进行处理,得到最终的实验数据集;然后设计不同的语音特征,提取出各自的特征参数;接着搭建说话人识别模型,将不同的语音特征作为模型的输入,经过训练得到不同的模型;最后对各个模型进行测试和分析,得出结论。
3.1 实验数据
本文实验数据采用Free ST Chinese Mandarin Corpus 公开数据集[9]。该数据集一共有855 个说话人的语音数据,每个说话人120 条语音数据,共计102600 条语音数据。对数据进行预处理,首先检查每条语音是否有效,去除其中损坏语音;接着进行语音端点检测(Voice Activity Detection),去除语音中的静音部分,尽可能使每条语音中包含较多的说话人信息,本文使用的VAD 工具为:Google WebRTC VAD[10];最后去除时长小于1 秒的语音数据,得到最终的数据集,包含854 位说话人,共计101974 条语音数据。为准确验证不同语音特征对说话人识别效果的影响差异,将数据集按照8:2 的比例划分为训练集和测试集(训练集和测试集中的说话人没有任何交集)。训练集和测试集的统计如表3 所示。
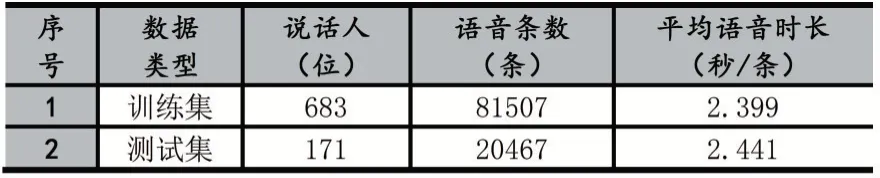
表3 数据集统计结果
3.2 实验评价标准
实验采用准确率(Acc)、F1 值和等错误率(EER)对识别结果进行评价。准确率(Acc)和F1 值的计算方式如下:

其中,tp 为模型正确将受试语音(该语音为注册者语音)识别为注册者的个数;tn 为模型正确将受试语音(该语音非注册者语音)识别为非注册者的个数;fp 为模型错误将受试语音(该语音非注册者语音)识别为注册者语音的个数,fn 为模型错误将受试语音(该语音为注册者语音)识别为非注册者语音的个数。
在评定说话人识别系统时,有两个非常重要的指标:错误拒绝率(False Rejection Rate,FRR)和错误接受率(False Acceptance Rate,FAR),其计算方式如下:
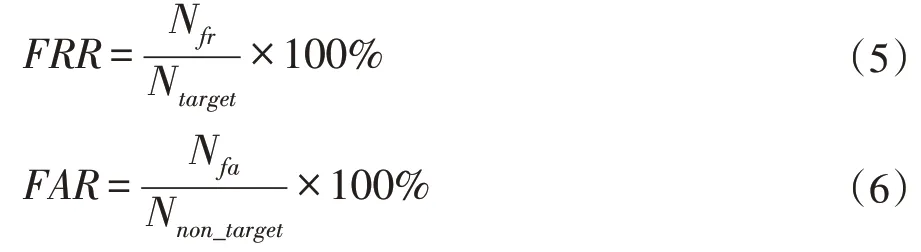
其中,Nfr和Nfa分别指测试中错误拒绝次数和错误接受的次数,Ntarget和Nnon_target分别指测试中总的类内测试(真实测试)次数和类间测试(冒认测试)次数。当系统中的阈值一定,FRR 与FAR 便确定。EER 为FRR等于FAR 时的错误率。
3.3 实验设置
实验采用TensorFlow 深度学习框架搭建了基于卷积神经网络的说话人识别模型。为了研究不同的语音特征参数作为模型输入时对识别结果的影响,本文共设计了7 组不同的语音特征数据来作为模型的输入数据,训练7 个说话人识别模型。其详细的信息如表4所示。
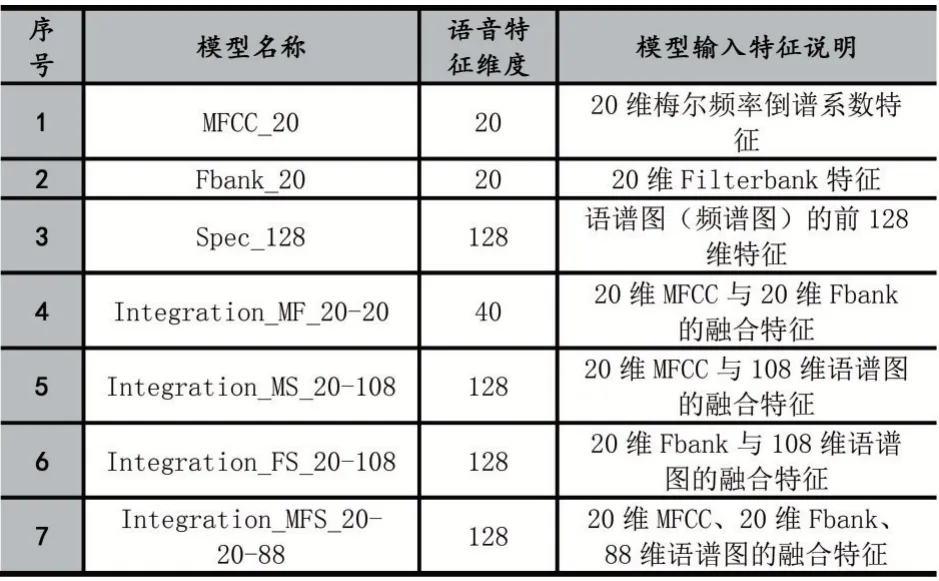
表4 模型及其对应输入的语音特征说明
训练集设置:训练集中共683 位说话人,为了保证训练出的模型可靠,以及便于观察模型训练过程,进一步将训练集按照8:2 的比例划分为训练集和验证集,划分后训练集共65163 条语音数据,验证集共16344 条语音数据。
测试集设置:测试集中共171 位说话人,对每一位说话人进行验证测试,即共有171 组测试。对于某一个说话人的测试,本文随机选择该说话人的1 条语音作为注册语音,再随机选取该说话人的50 条语音(不包含注册语音)和150 位其他说话人的语音(3 条/人)作为验证语音,共计500 条验证语音。为了保证测试结果的准确、可靠,本文采用随机选取的方式选取了3组测试集。在后续的测试中,将这3 组测试集分别经过每一个模型测试。
3.4 实验结果及分析
模型训练结束之后,根据之前的实验设置分别对每个模型在3 组测试集上进行测试,以3 组测试结果的平均值作为该模型最终的测试结果。测试结果采用3.2 小节中所提到的公式计算,测试结果如表5 所示。
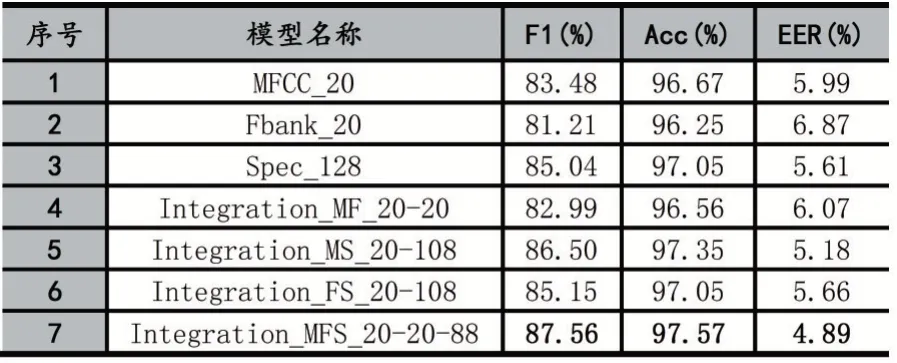
表5 模型测试结果
使用单语音特征参数作为模型的输入数据时,128维的语谱图特征:Spec_128 的效果最佳,在F1 得分和准确率上均高于20 维的MFCC 特征与20 维的Filterbank 特征,在等错率上也比其他两项特征值的结果低。Spec_128 与MFCC_20 特征相比,在F1 分值上分别高1.56%,在准确率上高出0.38%,在等错率上降低了0.38%;Spec_128 与Fbank_20 特征相比,在F1 分值上高了3.83%,在准确率上高了0.8%,在等错率上降低了1.26%。使用多特征融合参数作为模型的输入数据时,由三类单特征融合后形成的融合特征:Integration_MFS_20-20-88 具有最优的效果,无论是与单特征相比,还是与其他融合特征相比,均取得了最优的测试结果。与Integration_MF_20-20 特征相比,在F1 分值上高了4.57%,在准确率上高出0.38%,在等错率上降低了1.18%。与比Integration_MS_20-108 特征相比,在F1 分值上高了1.06%,在准确率上高出0.22%,在等错率上降低了0.29%。与比Integration_FS_20-108 特征相比,在F1 分值上高了2.41%,在准确率上高出0.52%,在等错率上降低了0.77%。
上面通过在三组测试集上的计算均值的方式给出了各个模型的测试结果,接下来观察各个模型分别在三组不同测试集上的表现。在3 组测试集上分别绘制出DET 曲线,其绘制出的结果如图1、图2、图3 所示。
通过在三组不同测试集上绘制出的DET 曲线,可以明显看到,在三组测试集上,由MFCC 特征、Filterbank 特征、频谱图特征融合而成的128 维特征:Integration_MFS_20-20-88 均取得了最小的等错率值。也再次证明了Integration_MFS_20-20-88 是最优结果。
通过以上分析,可以得出结论:由MFCC 特征、Filterbank 特征、频谱图特征融合而成的128 维特征:Integration_MFS_20-20-88 能够包含更多的浅层的说话人信息,有利于基于卷积神经网络的说话人模型从这些浅层信息中抽取出深层的说话人信息,从而得到一个优秀的说话人识别模型。该语音特征可以用于后续的基于深度学习的说话人识别研究。
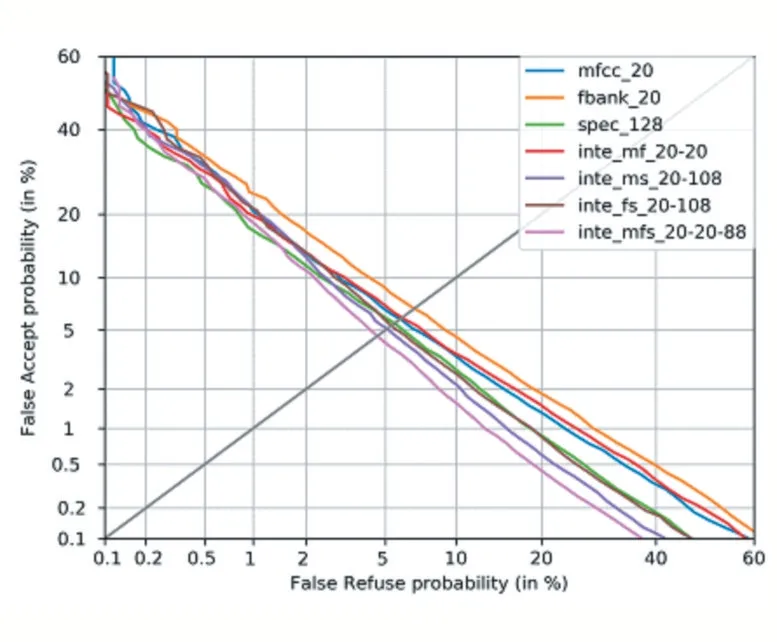
图1 测试集1的DET曲线
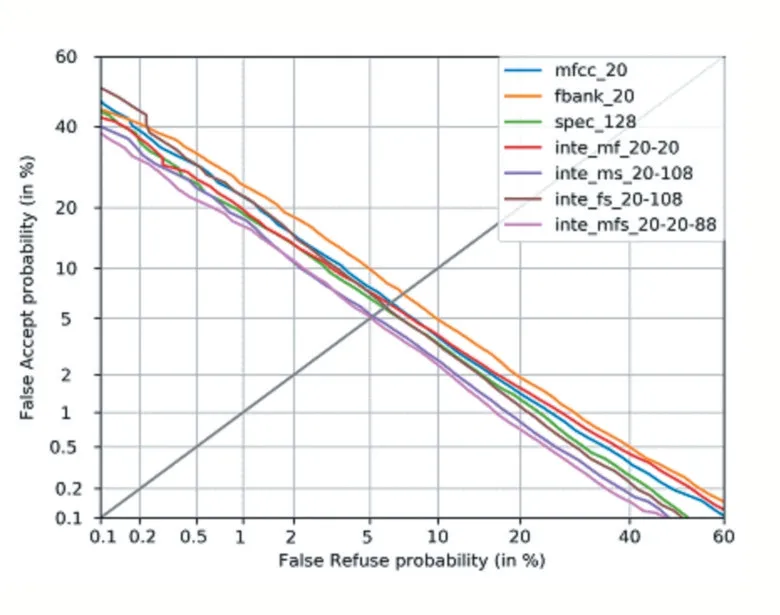
图2 测试集2的DET曲线
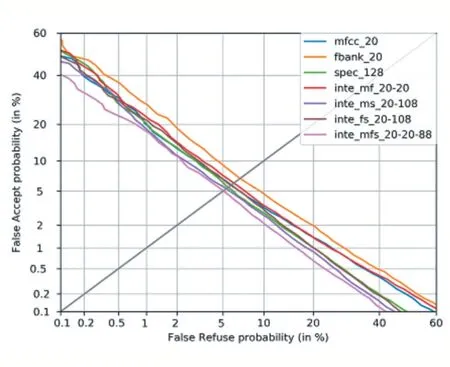
图3 测试集3的DET曲线
4 结语
本文研究了深度学习说话人识别中用于模型构建时输入的语音特征参数,得到了可以用于深度学习说话人识别中作为输入的语音特征:Integration_MFS_20-20-88。通过理论分析和实验证明了该特征方案是有效的。但这只是做了一小部分工作,后续还会在以下方面进行深入研究:①该融合特征只在基于卷积神经网络构建的说话人识别模型上验证了其有效,还并未在其他的神经网络来进行验证,后续还会进一步测试该特征在其他网络上的有效性;②由于本文构建的说话人识别模型比较简单,所以取得的测试结果都未达到一个较高的水平,后续也将会在模型结构上进行深入研究。
