基于神经网络的文本标题生成原型系统设计
2021-05-12张仕森孙宪坤李世玺
张仕森,孙宪坤,尹 玲,李世玺
(上海工程技术大学 电子电气工程学院,上海 201620)
随着近几年互联网的发展,网络中的文本信息资源的数量呈现指数级增长。根据中国互联网协会发布的《中国互联网发展报告2019》,截至2018年底,我国网页总数量已达到2 816亿,这些网页中所包含的信息覆盖了社会生活的各个领域。然而这其中也包含了海量不规范的文本信息,例如市场上众多移动客户端中自媒体文章的“标题党”,以及互联网中大量无标题的评论、微博等,这些不规范的文本信息给人们带来了巨大的信息过载压力。为这些不规范的文本信息生成一条简洁、切合原文表达的标题可以缓解信息过载压力,提高工作效率并为相关部门监察社会舆论提供帮助。
实际工作中采用传统的人工总结编写标题的方式在耗费大量时间、人力成本的同时难以应对每天产生的海量不规范文本。标题生成是以文本内容作为输入,以标题作为输出的一种文本摘要任务的变体,因此通过标题生成技术可以高效、经济地解决这一问题。
文献[1]通过词频、逆序文本频率等文本特征来计算文章中每一个句子作为摘要的概率,研发出一种基于贝叶斯分类模型的自动文本摘要系统DimSim。但在自然语言中,特征与特征之间并不是相互独立的,而是存在某些内部联系,因此文献[2]使用决策树替换朴素贝叶斯分类器来构造新的摘要系统。文献[3]在谷歌公司提出PageRank[4]算法的基础上提出了TextRank算法来实现文本摘要的生成。这些方法都是通过判断原始文本中各个单词或句子的重要程度,对原文中语句进行重新排序,按照重要性的大小抽取原文中的语句来构成摘要的抽取式技术。抽取式技术实现简单、快速,但是无法满足人们对于生成摘要准确性和流畅性的要求。
随着近年来深度学习技术的发展,对文本内容进行整体的全面总结凝练,然后生成摘要的生成式技术逐渐成为文本摘要任务的主流方法。抽取式技术仅仅是抽取原文中的语句来构成摘要,而生成式技术则更加符合人类的阅读和思考习惯,生成出来的摘要也更符合人工撰写摘要的规律。
文献[5]在新闻标题生成任务中应用Seq2Seq(Sequence to Sequence)模型取得了良好的效果。文献[6]在Seq2Seq模型的基础上引入了注意力机制,完成了生成式的中文文本摘要生成。本文基于神经网络和生成式技术对中文文本标题生成原型系统进行了设计与实现。
1 自然语言的文本表示
自然语言的文本表示是指由于计算机无法直接识别语言的符号文字[7],因此需要将这些符号文字转换为文本向量这种计算机可以进行运算的数学表达形式。转换之后得到的文本向量一般包含语言的语法、语义等重要特征[8]。自然语言处理技术经过长久的发展,形成了两种最主要的文本表示方法:离散表示与分布式表示。
1.1 离散表示
在离散表示方法中,对于词典中的每一个词一般使用一个长度和词典总词数大小相同的离散高维向量来表示词语。这个离散的高维向量中每一个元素都对应词典中的某一个词,其中只有一个元素的数值为1,其余均是0,元素为1的位置代表其对应词在词典中的位置。
利用离散向量的方式对文本进行表示的方法有两个弊端[9]:(1)离散表示方法向量的维度随着词的数量增大而増大,具有超高的维度和极大的稀疏性,高维度和稀疏性会产生自然语言处理中的“维数灾难”问题,占用较大的运算空间,增加了神经网络的计算代价;(2)离散表示方法会导致任意两个词之间是相对独立的,相当于给每个词分配一个id,导致离散表示方式不能有效地表达词与词之间的语义关系,无法表示语言复杂的语义信息[10]。在一定程度上离散表示是假设了语义的单一性,即认为语义仅仅是一维的,然而实际上语义应该是多维的。例如对于词语“家园”,有的人会联想到“安全”、“温馨”,有的人则会联想到“地球”、“环境”。由于不同人对同一个词的理解存在着较大的差异,因此仅通过给每个词分配一个id很难将词语放在合适的位置。此外,离散也无法衡量词语的相似性,即使是同义词在离散表示上也会被表示为完全不同的向量。
1.2 分布式表示
自然语言中的词语并非是全部独立的,例如“宾馆”和“旅馆”,“母校”和“大学”,它们具有一定的关联性和相似性。离散表示将每一个词看作一个完整独立的个体,假设了语义的单一性,无法衡量词语之间的相似性。为了解决传统离散表示方法的这一缺点,文献[11]提出了词向量(Word Vector)的概念。词向量又称为词嵌入(Word Embedding),是指用一种低维的、连续实值向量的形式来表示词语[12]。通过用词向量对词语进行表示,可使每个词语都变为词典的N维向量空间中的一个点。词向量可以有效解决传统离散表示的“维数灾难”问题。此外,不同词语在N维向量空间对应的点与点之间有距离的远近关系,从而可以通过计算对应点之间的距离得到词与词之间的语义关系。图1展示的是部分中文词向量空间示意图。
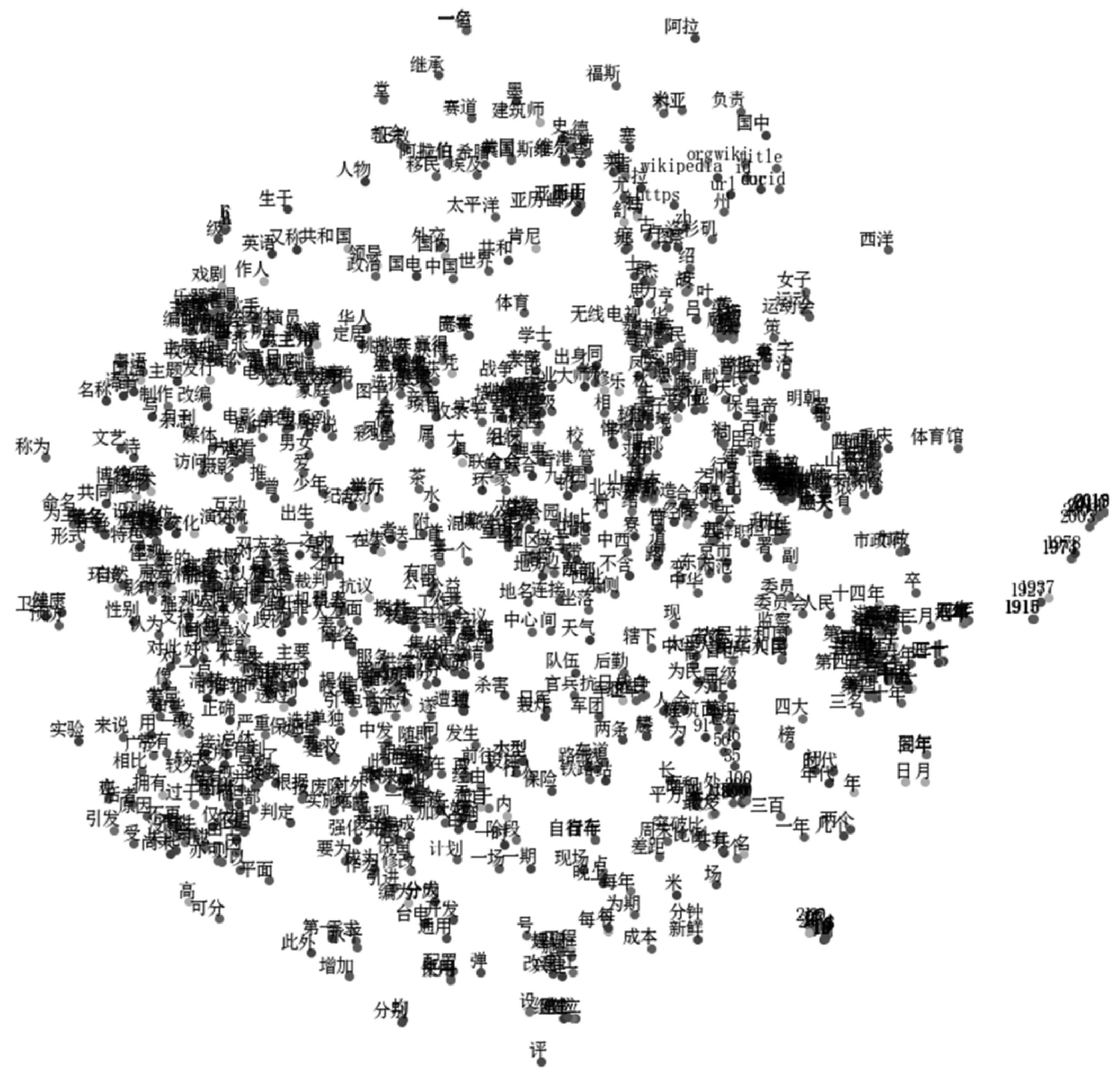
图1 部分词向量空间示意图
从图1中可以看出,语义相关的词在词典向量空间中的相对位置较为接近,例如“健康”和“预防”、“需求”和“增加”等。可以看出,相对于假设语义单一性的离散表示,分布式表示可以有效地表达出词与词之间的联系。
2 带注意力机制的编码器-解码器标题生成网络模型
标准的编码器-解码器标题生成网络模型的结构[13]如图2所示。其是将整个输入序列编码为一个固定大小的上下文语义向量c,之后用这个固定大小的向量进行解码操作,即标题中每个输出词语yi的生成过程为
(1)
其中,f是解码器Decoder的非线性变换函数。由式(1)可以看出,标准的序列到序列模型,在生成标题中每个输出词语yi时使用的上下文语义向量c都是相同的,即无论生成y1,y2,…,yn时,输入文本中任意词语对于某个输出词语yi来说影响力都是相同的。
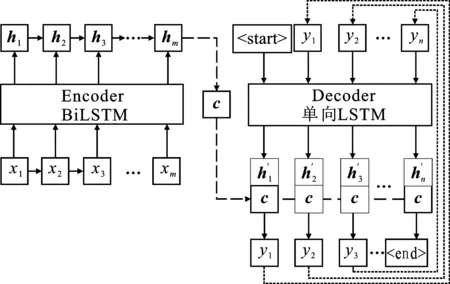
图2 编码器-解码器模型网络结构图
但在实际应用中,编码器Encoder将整个输入序列的信息压缩到一个固定长度的向量会导致这个固定长度的上下文语义向量c无法有效表示输入文本的全部信息,导致文本信息的丢失。
在标准的编码器-解码器标题生成网络模型中引入注意力机制可以减轻上下文语义向量c所承担的信息压力。其具体操作为:使用根据当前生成词而不断变化的上下文向量ci来替换原来Encoder端固定长度的上下文语义向量c,并且在生成上下文向量ci的同时还会生成针对每个输入的注意力权重参数ai。在解码器端解码时,隐藏层向量h′i不仅仅要与Encoder端编码出来的上下文语义向量ci进行混合,还要与注意力权重参数ai进行混合,共同决定当前时刻的输出。
双向门控循环神经网络可以对上下文同时进行建模计算[14],充分利用上下文语句之间的语义联系,提高最终的文本生成效果。因此本文研究选取的模型在编码阶段采用了双向长短期记忆神经网络[15]进行编码建模,在解码阶段则采用了单向长短期记忆神经网络进行解码操作。网络结构如图3所示。
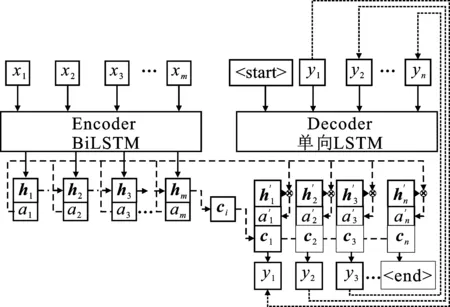
图3 带注意力机制的编码器-解码器模型结构图
图3中注意力权重参数a′i及根据当前生成词而不断变化的上下文向量ci的计算如下
(2)
(3)
式(2)和式(3)中,hj是编码过程中j时刻的LSTM神经网络隐藏层向量,h′i是解码过程中i时刻的LSTM神经网络隐藏层向量;w是注意力权重矩阵。
此时标题中每个输出词语yi的生成过程变为式(4)。
(4)
在每个时间步,解码器会根据当前解码器的隐藏层向量来引导编码器产生的上下文语义向量ci生成对应的输出序列。因此在生成标题的每个词语时,注意力机制将帮助生成模型选择与此部分高度相关的原文信息,进而生成更贴合原文的相关标题。
最终结合注意力机制的编码器-解码器标题生成网络模型标题生成词的条件概率如式(5)所示。
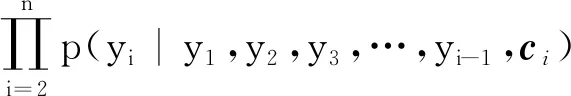
(5)
3 标题生成原型系统的设计
3.1 标题生成原型系统的整体结构
标题生成原型系统主要由前端展示和后端算法两部分组成,系统的整体结构如图4所示。
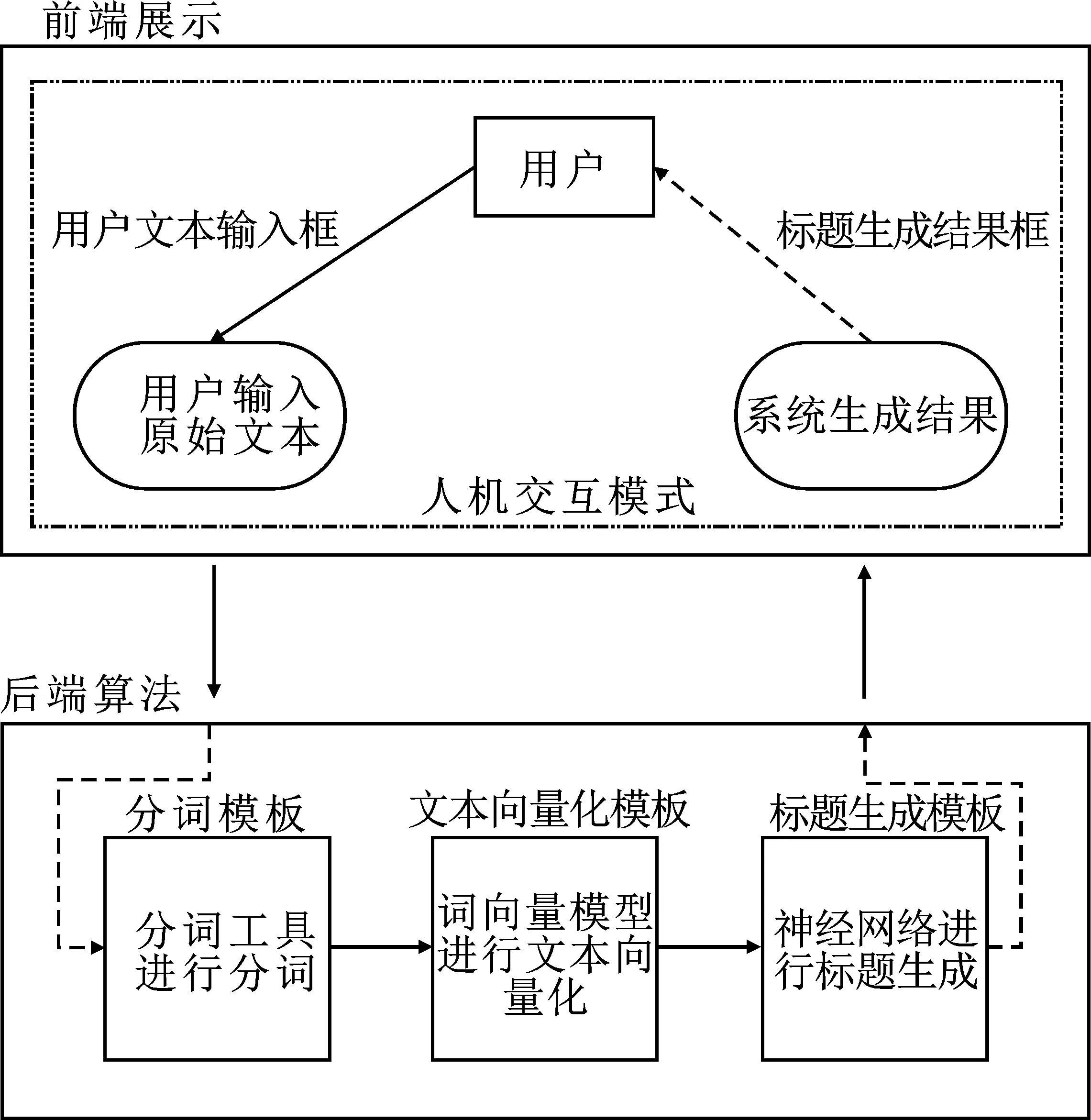
图4 标题生成系统的整体结构
其中前端展示模块主要的作用是进行人机交互,即用户输入想得到标题的文本后,前端界面可以返回给用户该文本在标题生成原型系统中生成的对应标题。后端算法部分则在接收到用户输入的原始文本后,对用户的输入文本进行分词、文本向量化表示、标题生成等步骤,并将系统生成的标题传递给前端界面并展示给用户。
3.2 标题生成原型系统的功能模块
3.2.1 人机交互模块
人机交互模块在前端可视化界面中展示,主要用于负责接收用户输入的待生成标题的原始文本,并将接收到的输入文本传递到后端进行处理,最后再将后端生成的标题展示在可视化界面中。
本文在人机交互模块中使用Tkinter模块来搭建标题生成系统的可视化界面。Tkinter模块是Python的标准Tk-GUI工具包的接口,可以在Windows和大多数的Unix平台下使用,从而解决了跨平台的兼容性问题[16]。
3.2.2 分词模块
分词模块使用jieba开源分词工具对输入的文本进行分词操作,作为后续的文本向量化模块的预处理操作。
例如输入文本:近年来,一些社会培训机构擅自招收适龄儿童、少年,以“国学”“女德”教育等名义开展全日制教育、培训,替代义务教育学校教育,导致相关适龄儿童、少年接受义务教育的权利和义务不能依法实现。对此,教育部印发《禁止妨碍义务教育实施的若干规定》。该文本经过分词模块后的输出见表1。

表1 分词模块处理示例
3.2.3 文本向量化模块
文本向量化模块将分词模块的输出文本通过词向量模型转变为计算机可以识别的向量表示,之后将经过向量化表示的文本信息传递进标题生成模块进行最终的标题生成。
3.2.4 标题生成模块
标题生成模块基于上述模块和带注意力机制的编码器-解码器标题生成网络来生成用户输入原始文本所对应的标题,并将生成结果传递回前端部分的人机交互模块进行展示。
4 标题生成原型系统的实现
4.1 标题生成网络模型的训练
4.1.1 训练数据的获取
训练标题生成任务的神经网络模型需要文本-标题对结构的大规模高质量文本数据集。基于此,本文研究主要使用了哈尔滨工业大学的LCSTS(Large Scale Chinese Short Text Summarization Dataset)[17]数据集。
LCSTS是一个大规模的中文短文本摘要数据集,其数据主要来源于一些具有影响力的机构或者媒体在新浪微博平台上向公众发布的信息。LCSTS的数据内容如图5所示。
其中,human_label是志愿者对每条短文本与摘要的相关性程度的标注,从1~5,数字越大代表短文本与摘要的相关性越高;summary则是这些具有影响力的机构或者媒体在发布消息时所用的标题;short_text则是发布的消息内容。

图5 LCSTS数据示例
LCSTS数据集共包含超过24万条短文本摘要数据,其数据长度分布如图6所示。
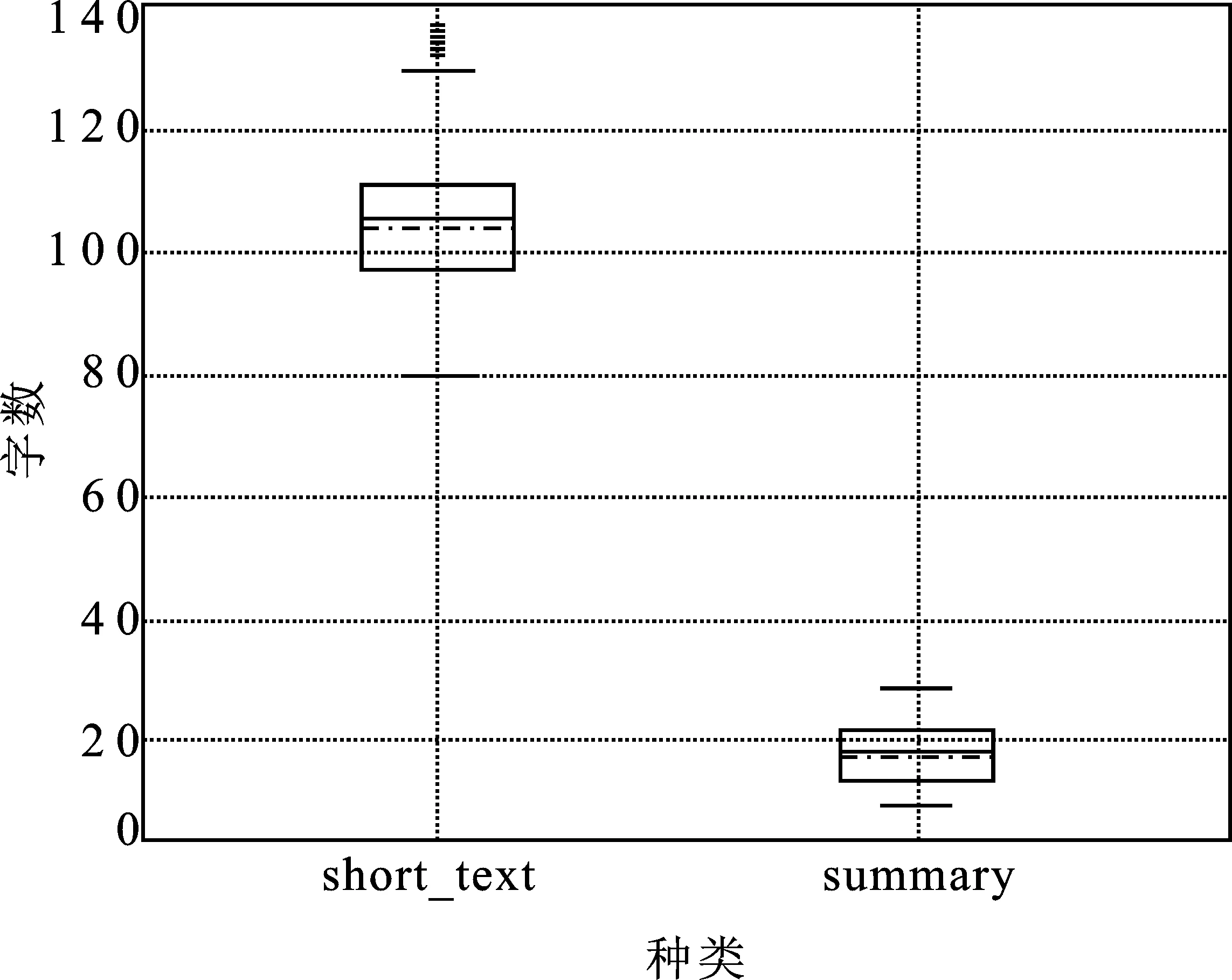
图6 LCSTS数据长度分布箱形图
由图6可以看出,LCSTS数据集中多数short_text的长度大于100,与之对应summary的长度通常小于20,即可以使用summary的内容作为输出标题,short_text的内容作为输入文本进行模型训练。
4.1.2 标题生成网络的训练参数设置
标题生成网络模型的训练环境主要为Intel CORE i7 9700,NVIDIA Tesla V100 32G TPU,Python3.6,Tensorflow1.4,Keras2.1.2,Numpy1.17,Pandas0.23,单次训练耗时约8 h。实验参数设置如表2所示。
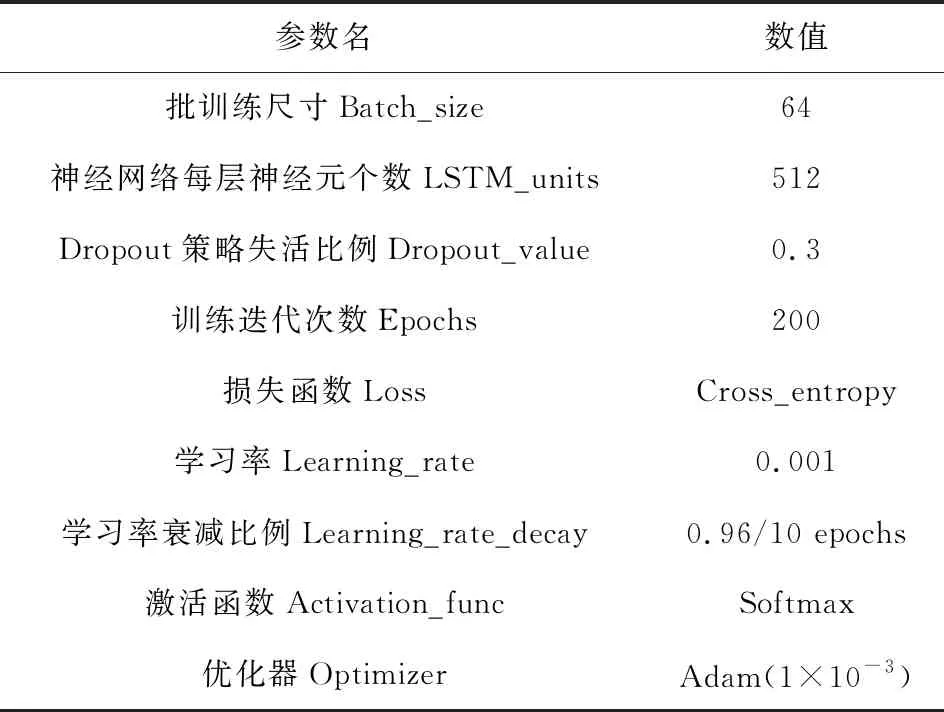
表2 TGMCN模型训练参数设置
4.2 原型系统的效果展示
标题生成原型系统的可视化界面主要包括以下几部分:(1)用户文本输入框。用户文本输入框用于输入待生成标题的原始文本;(2)标题生成结果框。标题生成结果框用于展示系统根据原始输入文本而生成的标题;(3)标题生成按钮。标题生成按钮用于启动生成系统;(4)清空界面按钮。清空界面按钮用于清空输入的文本和系统输出的标题。标题生成原型系统的可视化界面如图7所示。

图7 标题生成原型系统的可视化界面
如果用户输入的原始文本为空,则系统无法生成对应标题,此时系统进行弹窗,提醒用户原始输入文本不能为空,点击“确定”按钮回主界面重新进行输入,如图8所示。
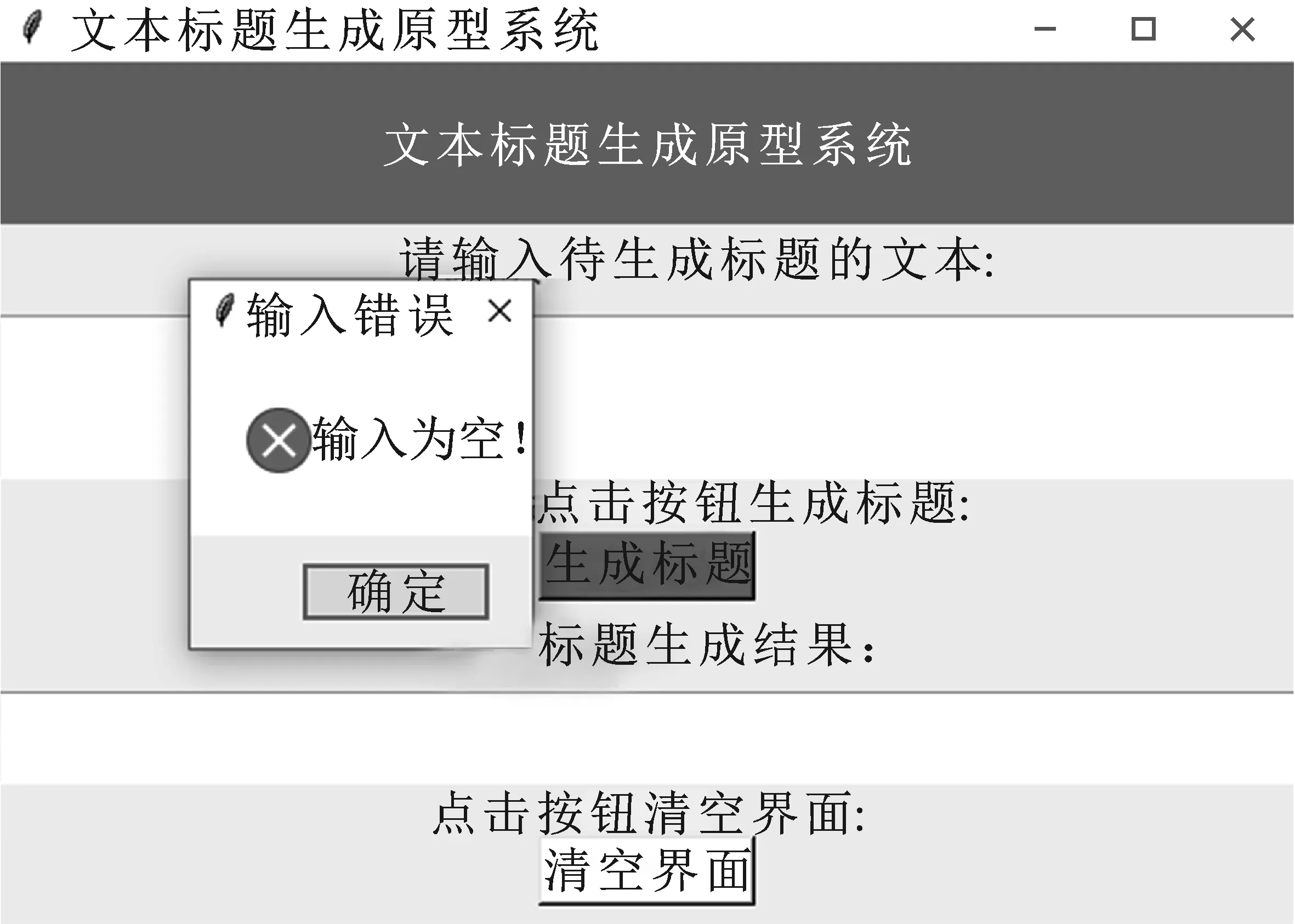
图8 输入文本错误时的系统界面
当用户输入没有错误的原始文本后,系统会调用后端算法模型来生成输入文本对应的标题,并将生成结果展示在标题生成结果框中,如图9所示。

图9 生成结果展示
4.3 原型系统的性能评价
4.3.1 ROUGE评价指标
本文标题生成原型系统的性能评价采用的评价指标是基于召回率统计的ROUGE(Recalloriented Understudy for Gisting Evaluation)[18]指标。ROUGE指标由ISI的Lin和Hovy提出,是自动摘要研究领域基于机器摘要和人工摘要中N-gram匹配的情况来生成量化结果的一种评价方法。ROUGE-1、ROUGE-L的计算方法如式(6)和式(7)所示。
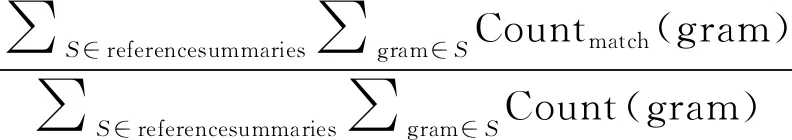
(6)
式(6)中,referencesummaries是人工编写的摘要,Countmatch(gram)表示系统自动生成的摘要和人工摘要中相同N-gram的最大数量,Count(gram)表示人工摘要中出现的N-gram个数。
(7)
式中,X和Y分别代表模型自动生成的摘要和人工标准摘要;L(X,Y)是X和Y的最长公共子序列的长度;m和n分别表示人工标准摘要和系统自动生成的摘要的长度,即组成摘要的词语个数;Rl和Pl则分别表示召回率和准确率;β被设置为一个趋向于正无穷的极大参数,因此ROUGE-L在数值上约等于Rl。
4.3.2 原型系统的性能测试结果
由于LCSTS数据集中human_label标签数值为“5”的文本代表经过志愿者标注,认为该条文本的标题与文本内容相似度较高。因此在测试原型系统性能时,在LCSTS数据集中所有human_label标签数值为“5”的文本中随机选取了510条,并将该510条文本数据移出训练集来构成测试集以避免训练过程中的数据泄露。
LexPageRank模型[19]是将PageRank算法应用到文本句子关系表示的方法,是一种基于图模型的标题生成模型。MEAD模型[20]是通过联合考虑句子的质心、位置、公共子序列及关键词这4种特征的标题生成模型。为了验证标题生成原型系统的性能,本文选取了LexPageRank和MEAD模型作为基线模型。系统性能测试结果见表3。

表3 系统性能测试结果
5 结束语
随着互联网时代的快速发展,网络中存在着大量不规范的文本信息。本文针对人工编写标题无法应对每天产生的海量文本数据这一现象,基于生成式文本摘要技术对中文标题生成原型系统进行了设计与实现,并对系统功能进行了详细的介绍和展示。通过在LCSTS数据集上的实验表明,采用训练结合注意力机制的编码器-解码器标题生成网络模型,可以使系统生成的标题更符合人工撰写摘要的规律,在一定程度上满足人们对于生成标题的流畅性和准确性的要求。其中,ROUGE-1、ROUGE-L评价指标的数值分别为29.91和24.68,均高于基线模型,证明了标题生成原型系统的有效性。
但是,因为计算机硬件设备限制的客观原因以及自身水平有限的主观原因,本文仍然存在着有待完善优化的地方,例如距离生成真正意义上的语义准确、表述清晰、行文连贯的高质量文章标题仍有着不小的差距。此外,本文所设计并实现的标题生成原型系统仅仅具备简单的基础功能,距离实际工业应用还有一定距离。在今后的工作中,研究人员将会持续关注国内外在文本生成领域的最新研究,从而继续优化和改进标题生成系统的性能。
