基于优化YOLOv3算法的违章车辆检测方法
2021-05-12谷玉海饶文军王菊远
刘 朔,谷玉海,饶文军,王菊远
(北京信息科技大学现代测控教育部重点实验室,北京 100192)
近年来,随着我国经济的快速发展,我国人民的生活水平也在不断提高,汽车拥有量逐年增长,与此同时,交通事故的发生也越来越频繁。超速行驶是交通事故多发的主要原因之一[1],为了约束驾驶人员的超速行为,目前很多国家和地区都在道路上安装了车辆超速自动拍照设备,对拍下来的车辆进行检测和识别,获取超速行驶车辆的车型、车牌号、驾驶人员以及乘坐人员等信息,然后对相关车辆的驾驶人员进行处罚,使用这种警示措施,更好地约束驾驶员,减少因超速造成的交通事故。
目标检测技术是对车辆超速自动拍照设备所拍摄到的图像中的车辆进行检测的关键技术[2],随着科学技术的发展,目标检测在智能交通系统中的应用越来越广泛。近年来,卷积神经网络在目标检测领域取得了一系列突破性的研究成果,YOLOv3模型便是基于卷积神经网络的目标检测模型,YOLOv3是由Joseph Redmon等在2018年4月提出来的,YOLOv3是在YOLO和YOLOv2的基础上进行改进的算法,是目前检测性能较高的目标检测算法。YOLO算法将目标检测视为回归问题进行求解,所以具有检测速度快并且背景检测错误率较低的特点[3],但是检测精度较低,并且容易产生漏检现象,对于小目标(面积小于322像素)物体的检测效果非常差。YOLOv2在YOLO的基础上,使用新的网络结构(darknet19)和技巧(batch normalization、high resolution classifier、convolutional with anchor boxes等),提高了检测速度和检测精度[4]。虽然YOLOv2准确性有所提高,但是对小目标检测效果依然不好。YOLOv3算法借鉴了残差神经网络的思想[5],引入多个残差网络模块和使用多尺度预测的方式改善了YOLOv2对小目标识别上的缺陷,其检测的准确率高并且时效性好,成为目标检测算法中集检测速度和准确率于一身的优秀方法[6]。
本文使用YOLOv3算法对交通路口图片中的车辆、车牌、人脸进行目标检测,由于车牌和人脸在交通路口图片中比较小,为了提高YOLOv3算法对小目标的检测能力,增加多个尺度检测,提高模型对车牌、人脸等小目标物体的检测能力,并增加k-means算法中生成的anchors的数量,提高目标检测的准确率。在真实交通卡口资源下使用不同的尺度以及不同的anchors进行训练、测试,对实验结果进行分析,发现改进后的YOLOv3算法模型的mAP为89.52%,帧频为45.25 FPS,检测性能优于原始算法,且能够满足实时检测要求。
1 YOLOv3网络模型
YOLO、YOLOv2和 YOLOv3算法是 Joseph Redmon等[7]提出的通用目标检测模型,YOLOv3在网络模型上相对于YOLO和YOLOv2有较大改进,在同等检测速度下,YOLOv3在进行检测任务时的平均准确率相较于YOLO和YOLOv2都有较大地提升,并且对小目标检测的平均准确率有较好的效果。YOLOv3有如下特点:
1.1 Darknet-53网络结构
在对图像进行特征检测的过程当中,YOLOv3使用Darknet-53网络代替了YOLOv2的Darknet-19网络。YOLOv3借鉴了残差网络(Residual Network)的方法,在某些层设置了快捷链路[8],从而提高了效率。图1为 Darknet-53网络框图[9],Darknet-53网络相对于Darknet-19网络,平均准确率有较高地增长,处理速度略微降低,同时Darknet-53网络可以实现较高的测试浮点运算,因此其可以更好地利用GPU,使预测效率更高[10]。
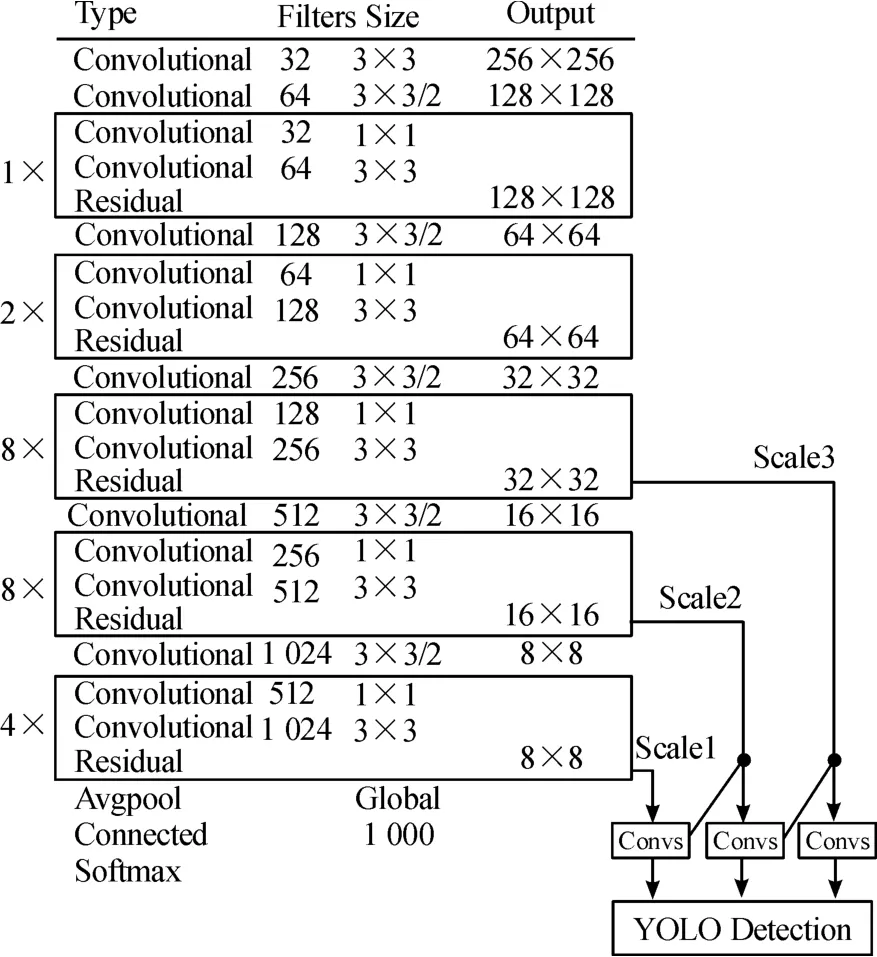
图1 Darknet-53网络框图
1.2 边界框预测
YOLOv3的anchor boxes是通过聚类方法得到的。如图2所示,YOLOV3对每个bounding box预测4个坐标值,分别为 tx、ty、tw、th。在图像中,一般左上角为坐标原点,图像的偏移为cx、cy,且对应的边框的长和宽分别为ph、pw,在预测的边框中,式(1)为边框的中心点横坐标的计算公式,式(2)为边框的中心点纵坐标的计算公式,式(3)为边框的宽的计算公式,式(4)边框的长的计算公式[11]。


图2 位置预测的边界框
1)跨尺度预测
YOLOv3采用多尺度结合进行预测。YOLOv3借鉴 FPN(Feature Pyramid Networks)网络中的融合(融合了3层)和上采样方法,进行多样本、多尺寸检测[12],在网络第 82、94、106层进行了跨尺度预测,极大地提高了YOLOv3对小目标检测的准确率[13]。
2)分类预测
YOLOv3没有使用YOLOv2的softmax分类方法,softmax分类只能输出1个分类,YOLOv3采用多个简单的逻辑回归sigmoid输出类别得分[14],用二元交叉熵计算类别损失,每个分类器对于目标边框中出现的物体只判断其是否属于当前标签,即简单的二分类,这样便实现了多标签分类。
常见的基于回归的目标识别算法有YOLOv2、YOLOv3、SSD,在Microsoft COCO数据集下对它们的性能进行测试,测试结果如表1所示[15]。

表1 基于回归的目标检测算法性能对比
经观察对比发现,YOLOv3在Microsoft COCO数据集下的识别平均准确率和帧频有较好表现,并且在将尺寸归一化为416像素时,可满足实时处理需求。
2 YOLOv3模型改进
2.1 增加检测尺度
YOLOv3算法的模型借鉴了FPN网络的思想,同时利用底层特征的高分辨率和高层特征的信息,使用上采样的方法,将不同层的特征进行融合,在3个不同尺度的特征层上对物体进行检测。由于在违章车辆检测的过程当中,车辆距离摄像头的远近会导致车辆在图片中所占比例的大小不一样,且在违章车辆实时检测中还需要检测车牌信息以及驾驶员的面部信息,这些目标物在图片中为小目标物体,为了提高YOLOv3网络模型对小目标物体的检测能力,本文对YOLOv3算法模型中的尺度检测模块进行改进,将原有的3个尺度检测扩展为4个尺度检测,给特征图分配准确的锚框,提高检测精度。本文提出的YOLOv3多尺度检测模块如图3所示。

图3 改进后的YOLOv3网络结构
2.2 优化锚框数目
YOLOv3算法模型依然延用了YOLOv2算法模型中的思想,使用k-means聚类的方法对训练数据集中标记的目标框进行聚类,获得合适的anchors(锚框),anchors的选取会影响到目标检测的速度以及精度。YOLOv3算法模型在VOC和COCO数据集上进行聚类,每个尺度的anchors的数量为3,本文根据违章车辆检测数据集和4个尺度检测层的特点,采用准确度更高的FCM聚类算法对训练集的边界框做聚类,选取合适的边界先验框,对违章车辆以及车牌、驾驶员面部进行更好的预测。在使用FCM聚类算法对样本框进行聚类时,计算各个样本框与聚类中心的IOU(intersection over union),然后使用(1-IOU)作为 FCM聚类算法的距离函数,得到如式(4)所示的FCM聚类算法的目标函数,

式中,IOUij为第j个样本框和第i个聚类中心的重合度;b为模糊加权指数,且1<b<∞,b取值的最佳区间[16]为[1.5,2.5],本文 b值取 2;uij为第 j个样本框属于第i类聚类中心的隶属度,取值介于0~1之间,且满足式(5)所示的约束条件。

通过最小化式(4)中的目标函数,可得到各样本框对于各聚类中心的隶属度,最后根据式(6)可实现最终的聚类。

最终得到的 anchors为(4,7)、(8,9)、(7,17)、(8,12)、(11,23)、(22,12)、(34,12)、(19,31)、(36,18)、(35,64)、(84,40)、(94,53)、(34,188)、(105,66)、(81,125)、(63,223)、(169,116)、(130,198)、(145,240)、(190,274)。
在3个尺度检测中的每个尺度下分别使用anchors数目为2、3、4、5的网络模型进行目标检测,然后在4个尺度检测中的每个尺度下分别使用anchors数目为2、3、4、5的网络模型进行目标检测,对比实验结果,以此来选择每个尺度下合适的anchors数目。
作为对比,采用k-means维度聚类的方法对训练集的边界框做聚类,选取合适的边界先验框,kmeans聚类方法中距离公式定义如式(7)所示[17]:

得到的 anchors为:(4,8)、(8,9)、(6,14)、(10,14)、(12,20)、(25,11)、(33,14)、(19,31)、(37,18)、(35,64)、(84,40)、(93,53)、(34,188)、(105,66)、(81,122)、(63,223)、(175,117)、(132,200)、(148,239)、(192,277)。
使用k-means维度聚类的方法所获取的anchors,在筛选得到的最优尺度和最优anchors数目下进行实验并对比实验结果,验证FCM聚类算法的优越性。
3 实验
3.1 实验数据
对于交通图像目标检测属于监督学习,因此制作训练集时需标注图像的位置和类别,本文利用实际交通场景原图资源作为训练集、验证集以及测试集。在实际交通场景图片中采用labelimg开源工具标记出所需要检测的目标物体,并使用不同的标签代表所需要检测的不同物体,本次实验分别检测车辆、车牌以及人脸3种目标物体,标签代号分别为“car”“plate”“face”。
图像资源共有23 741张,图像资源分辨率有2 048×1 380、1 616×1 046两种。训练集包含20 000张真实交通卡口图像,验证集包含2 000张真实交通卡口图像,测试集包含1 741张真实交通卡口图像。
3.2 实验配置与训练
实验环境配置如下:CPU为 Intel(R)Core(TM)i5-8500@3.00 GHz,NVIDIA GeForce GTX 1080 Ti显卡,CUDA版本为8.0,CuDNN版本为6.0,操作系统为 ubuntu16.04.05(64位)。
YOLOv3网络的训练参数配置如下:将输入图片的batch、subdivisions分别设置为64、16。迭代次数设置为30 000次。学习率使用分步策略,初始值设置为0.001,变化的次数为25 000,比率为0.1。
网络训练过程中损失变化曲线如图4所示,IOU曲线如图5所示。

图4 损失变化曲线

图5 IOU曲线
3.3 实验结果分析
在使用3个尺度的网络模型进行检测时,分别使用每个尺度的anchors数目为2、3、4、5的网络模型进行目标检测,检测的AP(准确率)和IOU(重叠率)如表2所示,平均检测每张图片所需的时间如表4所示;在使用4个尺度的网络模型进行检测时,分别使用每个尺度的anchors数目为2、3、4、5的网络模型进行目标检测,检测的AP和IOU如表3所示,平均检测每张图片所需的时间如表4所示。
由表2、表3可以得出结论:在相同anchors数目的情况下,针对大目标物体的检测,以对车的检测为例,使用YOLOv3原本的3个尺度进行检测的检测效果,与使用改进之后的4个尺度进行检测的检测效果相差不大,但是针对于小目标物体的检测,以对车牌的检测为例,使用4个尺度检测时,检测效果明显要优于使用3个尺度进行检测,说明YOLOv3网络模型的尺度的优化对小目标的检测性能有所提高。在网络模型的检测尺度相同的情况下,每个尺度下anchors数量在4个的时候准确率达到最高,对比YOLOv3原本每个尺度下anchors数量为3时的检测效果,改进之后的检测效果明显更优。由表3可知,改进之后的网络模型的检测速度比改进之前的网络模型的速度稍慢些,但是都小于50 ms,都能够满足实时检测的需求。选取 4个尺度、4个 anchors作为最终的YOLOv3优化模型,测试的mAP为92.53%,帧频为44.58 FPS。

表2 3个尺度检测时使用不同anchors数目的AP与IOU %

表3 4个尺度检测时使用不同anchors数目的A P与IOU %

表4 平均检测每张图片所需的时间 ms
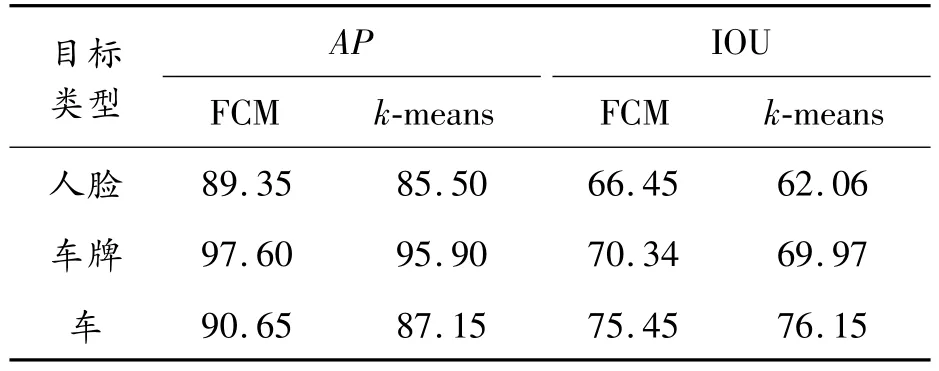
表5 使用FCM聚类算法与k-means聚类算法的AP与IOU %
在4个尺度下使用k-means聚类算法生成的4个anchors进行实验,实验结果如表5所示,由表可知,除了在检测车辆的时候,使用FCM聚类算法的IOU稍逊于k-means聚类算法,其他指标,FCM聚类算法均优于k-means聚类算法,因此,使用FCM聚类算法生成anchors是一种有效可行的方法,且具有一定的优越性。
实际场景检测图如图6所示。当在有反光的条件下进行检测的时候,使用原YOLOv3网络模型进行检测,产生了人脸漏检的情况,而使用改进之后的YOLOv3网络模型对相同的图片进行检测,则能够成功检测出人脸,如图7所示。

图6 实际场景检测图

图7 反光条件检测对比图
4 结论
为了提高对违章车辆检测的准确性与实时性,并对违章车辆的车牌以及驾驶员的面部等小目标物体进行检测,提出一种基于YOLOv3框架的违章车辆实时检测改进算法。该算法以YOLOv3为基础网络结构,结合违章车辆检测任务特点进行优化与改进,使用增加检测尺度、优化锚框数目等方法来改进检测效果。实验结果表明,提出的方法在违章车辆检测的实验中比原始YOLOv3方法检测效果更好,且能够满足实时性的要求,基本达到实际应用的要求。
