基于随机森林算法的铁路货物运达时间预测研究
2021-05-10董宝田
邓 蕲,董宝田
(北京交通大学 交通运输学院,北京 100044)
铁路货物运输本质上是铁路为顾客提供的对于货物的位移服务。随着经济发展和社会需求不断增加,市场对铁路货物运输提出了更高的要求。如何从接受货物开始将货物更安全、更快速、更准时地送到目的地,已经成为铁路行业在货物运输市场中必不可少的一个考量因素。
梁栋[1]在原有的货物运输组织基础上构建了时空隧道图,基于车辆在每个技术站的作业需求,对作业流程进行了预估并预测了运输时间;李玮[2]分析了货物在运输途中的主要时间分布,并据此对最终的运达时限做出了预测;李夏苗[3]通过分析货物到达时间数据集,列出了铁路货物运输送达时间的回归方程,并做出优化;贾玉卫[4]将可靠性理论应用到铁路货物送达时间预测中,得到铁路运输过程的时间分布函数,建立了可靠性评价体系,提出保障时间可靠性的方法。
目前,货物运达时间的主要研究方向是从现有运达时限的基础上出发,提出保障运达时限的具体措施或构建优化组织的模型,但涉及到车辆的某些具体特征(装载的货物种类、车次等)时,现有算法都将车辆进行了无差别处理,导致在一定程度上对车辆具体运达时间的预测出现偏差[5-6]。在这种情况下,本文基于随机森林算法,结合铁路货物运输组织过程,将运输路径上的起始站、技术站做为节点,根据货物相关信息,将其各种属性转化为特征值加入到运达时间预测中,从而预测货物终到时间,并根据实时运行情况在每一个技术站都重新计算货物终到时间,以求得到最新的货物终到时间。
1 货物运达时间预测需求与难点
1.1 货物运达时间预测需求
在铁路的日常货物调度中,调度人员都是根据货物的距离、种类、数量等信息,以自己的经验来预测货物到站时间。仅根据个人经验来判断,不够科学和精确,无法对设备工作能力和线路的通过能力进行最大化的利用。货物运达时限的准确预测能让调度人员更加明确铁路货物运输所需时长以及即将到达的货物流信息,从而更好的对整个物流有全局的认识,也方便调度人员安排调度计划和编组计划,扩大铁路运输量[7]。由此可见,更准确地预测铁路货物运达时间不仅对客户有益,也利于提升铁路自身效益和员工工作效率。
1.2 货物运达时间预测难点
铁路货物运输过程中有较多作业流程,因此会有较多因素影响铁路货物运达时间的预测,如工作人员进行工作的时间、线路的选择、等待配轴配长的时间等。从数据分析角度来看,具有相同的特征的货物流,从始发站到终点站的时间也是发散的,导致运达时间的预测较为困难。基于随机森林算法对铁路货物运达时间预测会遇到以下难点:
(1)车流路径不确定,部分货物在线路上可能会离开选定的目标线路去向别的线路,而后在线路的某一段又回到目标线路上;
(2)货物的优先级不同,导致在其他特征相同的情况下,最后到达终点站的时间也不同;
(3)调度人员水平不同,各站工作人员工作效率也不同;
(4)铁路特征向量的种类较多,导致维度较多,在机器学习构建决策树时更为复杂,计算所需花费的时间更长。
2 铁路货物运达时间预测建模
随机森林是一种集成的统计学习分类和回归算法,针对不同特征,组合多个决策树对相同现象产生相似的预测结果,在随机森林回归的过程中,其输出值为随机森林中所有决策树结果的平均值,随机森林回归模型的核心在于根据特征建立多棵回归决策树。
2.1 始发站随机森林预测建模
本文将铁路货物运达时限的影响因素,如车辆类型、始发站、终到站等作为输入的特征向量,用货物运达时间点作为预测结果,通过训练样本进行拟合得到预测模型,具体步骤如下:
(1)车辆i到达终点站的报文时长为yi,将报文中可能对运达时间有影响的因素(报文ID、车次、车次ID,车辆在始发站、中间站、终点站的时间)作为特征向量,车辆i的特征向量xi~{Ii1,Ii2,···,Iin},其中,Iin表示车辆i在预测期间的第n个影响因素。
(2)建立单颗回归决策树,对x和y进行搜索,将整个向量空间依据回归树划分为m个分区{R1,R2,···,Rm},对于其中任意分区可以映射为时间集合cm,该分区通过分裂得到R1(j,s) 和R2(j,s)两个部分:

其中,j表示变量类型,即铁路货物运达时限的一个影响因素;s表示进行分裂时每个分区划分对应特征向量的值。
时长方差z公式如下:
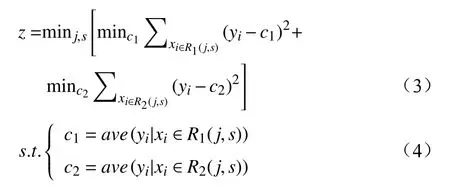
其中,c1是第1 部分车辆到达终点站的实际值的平均值;c2是其余车辆到达终点站的实际值的平均值。
为了在一定程度上减少计算量,提升运算效率,本文对决策树的层数进行控制,设置分裂效果较好的特征向量在第4 层时停止分裂,从而提升决策树的效率。
(3)构建整个随机森林,从n个初始数据样本中有放回的抽样m个样本集,构建m个决策树进行训练,将没有被抽取到的数据作为测试集。参数m为总的数据集的1/3 时预测效果较好,当决策树的数量大于100 时,准确率较为稳定,本文设定为300。
报文信息特征向量个数为p,在每棵决策树模型的内部节点随机抽取k(k≤p) 个变量作为备选分枝变量,按照单棵决策树构建过程寻找最佳分枝;调整叶子节点的大小,控制随机森林和决策树的生长,结果较好的分裂到4 次时即可停止分裂,否则继续分裂直至得到较好结果,最终生成随机森林组合模型。
(4)随机森林模型验证,本文采用拟合度(R2)、均方根误差(RMSE)和预测精度(P)来检验,R2和P值越高,说明模型构建越好,RMSE值越小,说明模型精度越高,计算公式如下:
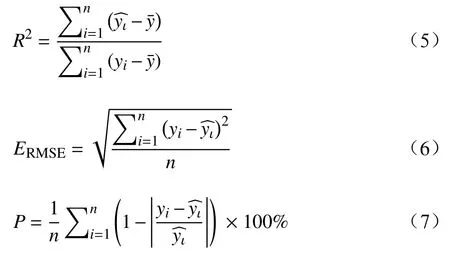
式中,ERMSE是均方根误差;yi是车辆实际到站时间;是预测的车辆到达时间;是实际平均到站时间;n为样本数量。
2.2 中途技术站随机森林预测建模
建模方式同上,需额外增加2 个特征向量:(1)当前站的繁忙程度,本文规定繁忙程度为该站该时刻前30 min 内接入的车辆数量;(2)车站等级,不同等级的车站业务处理能力不同,会导致效率差异。
3 案例验证
3.1 模型案例预测分析
计算机环境为Intel(R)Core(TM)i7-8750H CPU@2.20 GHz2.20 GHz 64 bit 操作系统,开发软件采用Python 3.7。
本文以张兰—孝南—绥德—子洲—杨桥畔—靖边—定边铁路线段为案例进行预测,OD 图如图1 所示。以实际报文时间为依据,与随机森林算法预测出的时间数据进行比对。
(1)整体报文比对
图1 OD 线路图
基于本文的随机森林算法模型,以煤炭货物运输为例,完成该线段运输的预测平均所需时间为6 936 min,实际时间和预测时间的对比如图2 所示。
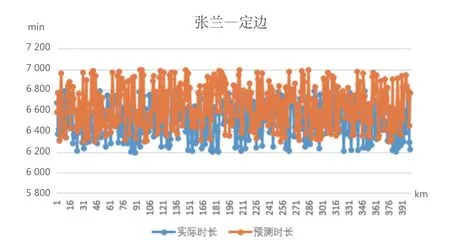
图2 张兰—定边误差预测值与实际值对比
R2为0.97,P为0.95,ERMSE为388.2,可满足日常的调度需求和准时度需求。
(2)单一报文比对
随机抽取一条报文,抽取报文中该时间段内车辆号为4910314 的车辆在各个站点的的相关信息,报文信息如表1 所示。
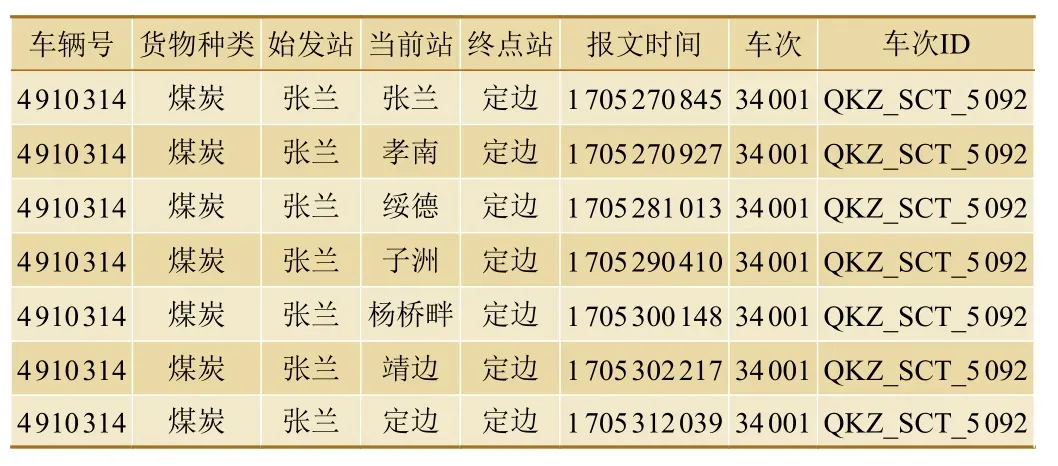
表1 抽取4910314 号车辆的报文数据
在始发站输入车辆的报文信息,代入本文的随机森林算法,预测运达时间为6 925 min。
当车辆从始发站出发后,可能会与预测状态不同。例如,某个技术站车辆数量较多,工作人员不能胜任作业任务,从而导致车辆通过时间延后。在实时报文的情况下,本文引入繁忙程度和车站等级两个特征向量。4910314 号车辆的特征向量和预测时长,如表2 所示。

表2 4910314 号车辆在孝南站的特征向量与预测时长
将此报文带入随机森林算法中进行计算。步骤与始发站运到时间预测计算步骤相同,得到在当前站到终点站剩余所需时长。
3.2 误差分析
将实际报文数据与模型预测值进行对比,结果如表3 所示。
单一报文时长预测准确率如图3 所示。
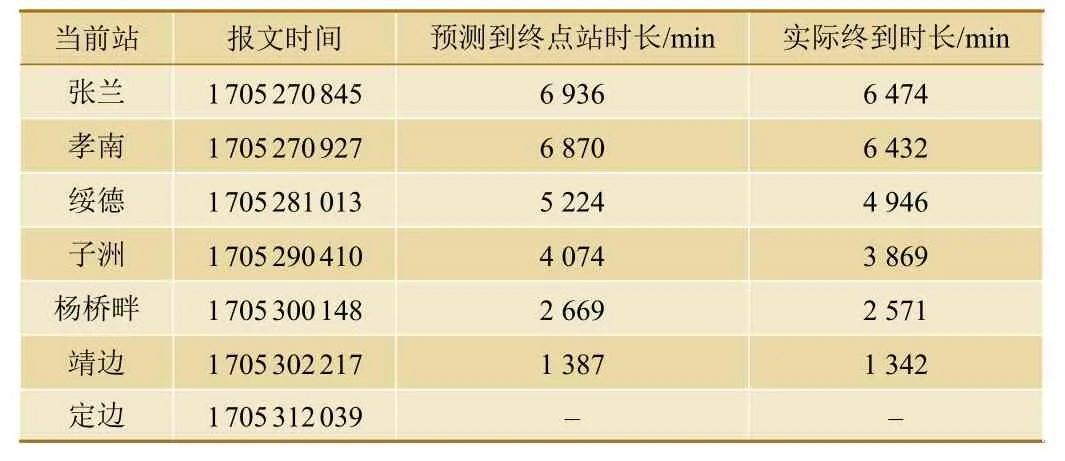
表3 预测时长与实际书记对比
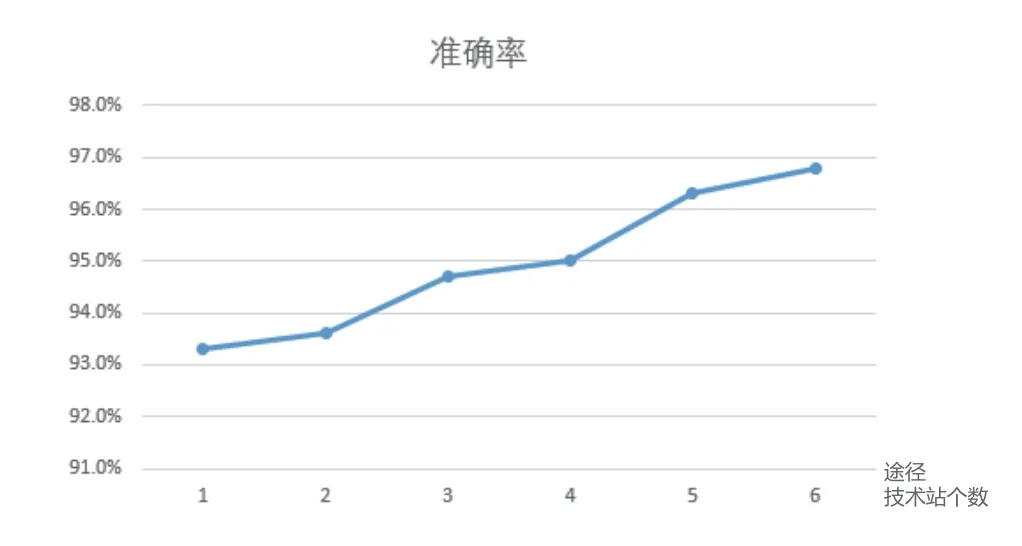
图3 准确率走势
初始站的预测误差值为93.3%,但在接下来的行驶过程中,误差值逐渐减少,本文算法没有让误差累计,在不断的实时预测下,准确率稳步提升。最后一站的时长预测准确率为96.8%,证明该算法可行。
4 结束语
本文运用Python 语言,设计实现了基于随机森林算法的铁路货物运达时间预测模型。根据不同的车辆属性预测车辆到达终点站的时长,将车辆的各种影响因素考虑进去,进行特征向量的计算,在行驶过程中不断修正误差,使得终到时间预测更为精确。下一步可计算每个特征向量对目标函数的增益,从而调整各个特征向量,使结果更优。
