针对地理位置信息的时空感知的去匿名攻击
2021-05-08王榕谢玮廖璇丰诗朵白琨鹏
王榕, 谢玮, 廖璇, 丰诗朵, 白琨鹏
(1.中国信息通信研究院 安全研究所 行业网络安全事业部,北京 100191; 2.中国科学院 软件研究所 可信计算与信息保障实验室,北京 100190)
现阶段配备GPS定位功能的智能设备已得到普及,这给人们的生活带来了巨大的便利[1],但同时也带来了巨大的用户隐私泄露风险[2-3]。如通过分析用户的移动轨迹可以推断出用户的家庭地址[4],也可以推断出用户过去、现在、将来的位置[5-6]以及他们的社交关系[7]。去匿名攻击(de-anonymization attack)[7-14]可以根据用户移动轨迹包含的移动模式信息有效地重识别匿名用户。但是根据当前研究来看,大多算法均通过着重考虑移动轨迹中的空间属性来进行用户去匿名攻击,忽略时间属性的作用。
本文定量分析了用户移动轨迹包含的空间属性和时间属性,定义了一种时空感知的用户隐马尔可夫模型(spatio-temporal user hidden Markov model,ST-UHMM)来描述用户的移动行为,进一步提出了基于ST-UHMM的去匿名攻击模型以及2种时空感知的相似度定义。为了评估本文模型的有效性,我们使用微软亚洲研究院(MicroSoft Research Asia,MSRA)采集的GeoLife[26]数据集进行实验。实验结果表明,相比已有方法,本文模型的重识别准确度有显著的提高。
用户移动轨迹中的空间属性在去匿名攻击中往往发挥着不可忽视的作用。De Mulder等[15]使用只能描述地理上相邻2个位置(GSM基站)ID描述GSM网络中用户的移动行为。Xiao等[16]通过定义SLH(semantic location histories)并计算SLH序列之间的相似度来重识别匿名用户。Zang等[17]把GSM网络中每个用户访问频率最高的n个位置作为一个准标识符(quasi-identifier,QI)来重识别匿名用户。Gambs等[1]定义了移动马尔可夫链(mobility Markov chain,MMC)来描述用户的移动行为,通过计算MMC之间的相似度来重识别匿名用户。Samet等[18]采用隐马尔可夫模型(hidden Markov model,HMM)描述用户的行为模式,并根据地理位置信息生成基于区域范围的隐藏态,但对于大量跨区域范围的签到位置并不能准确识别出目标用户。Farid等[19]使用用户的位置分布柱状图来描述用的行为规则。Takao[20]则考虑小规模数据集的去匿名化问题,计算匿名数据和已知用户数据的地理位置分布的JS(Jensen-Shannon,JS)散值,识别匿名数据。
上述去匿名方法有共同的不足:依赖空间属性来进行去匿名攻击而忽略了移动轨迹中时间属性的作用。Freudiger等[21]将用户的“home”/“work”对作为准标识符重识别匿名用户,但是如果2个匿名用户的“home”/“work”对相同,这种方法的效果就大打折扣。De Montjoye等[22]提出随机选取2个或4个时空位置可以有效地重识别50%~95%的匿名用户。但是,他们的方法过于依赖随机位置的选择。Chen[23]提出的DBHMM方法以及Wang[24]提出的UHMM考虑了用户的时空信息,但是该方案仅适用于单条或小规模轨迹识别。Yuan等[25]提出的PRED方法可以评估出用户周期性访问的区域,以及访问区域的周期性时间,并利用该方法预测用户未来访问的地点。
总的来说,为了有效地实施去匿名攻击,需要充分地考虑用户移动轨迹包含的空间属性和时间属性。本文在上述从直观上分析了用户移动轨迹包含的空间属性和时间属性及其在去匿名攻击中发挥的作用。使用MSRA采集的GeoLife数据集对用户移动轨迹包含的空间属性和时间属性进行定量分析。
1 移动轨迹中的空间属性和时间属性
1.1 用户移动轨迹中的空间属性
为了衡量不同用户访问不同位置的喜好程度,本文使用位置熵(location entropy,LE)来度量移动轨迹中的空间属性。给定一个用户,其位置熵定义为:

(1)

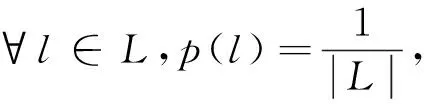
(2)
位置熵度量用户移动行为的空间倾向性。位置熵越大,用户移动行为越缺少空间倾向性。相反,位置熵越小,意味着用户会越有倾向性地频繁访问少数位置,这些少数位置是对用户至关重要的。
因此,计算等概位置熵与位置熵的差值,并将之归一化,以此定义用户移动行为的空间倾向性为:
(3)
从空间倾向性的定义可见,对于一个用户来说,等概位置熵与位置熵差值越大,他的移动行为越有空间倾向性。本文对GeoLife当中的数据进行分析。由图1可知,GeoLife数据集中的绝大多数用户的等概位置熵与位置熵并不相等(空间倾向性非零)。特别地,有近80%的用户的空间倾向性大于0.10,这表明他们的移动行为普遍具有较明显的空间倾向性,每个用户的轨迹中存在对其具有重要意义的位置,空间倾向性极为明显。
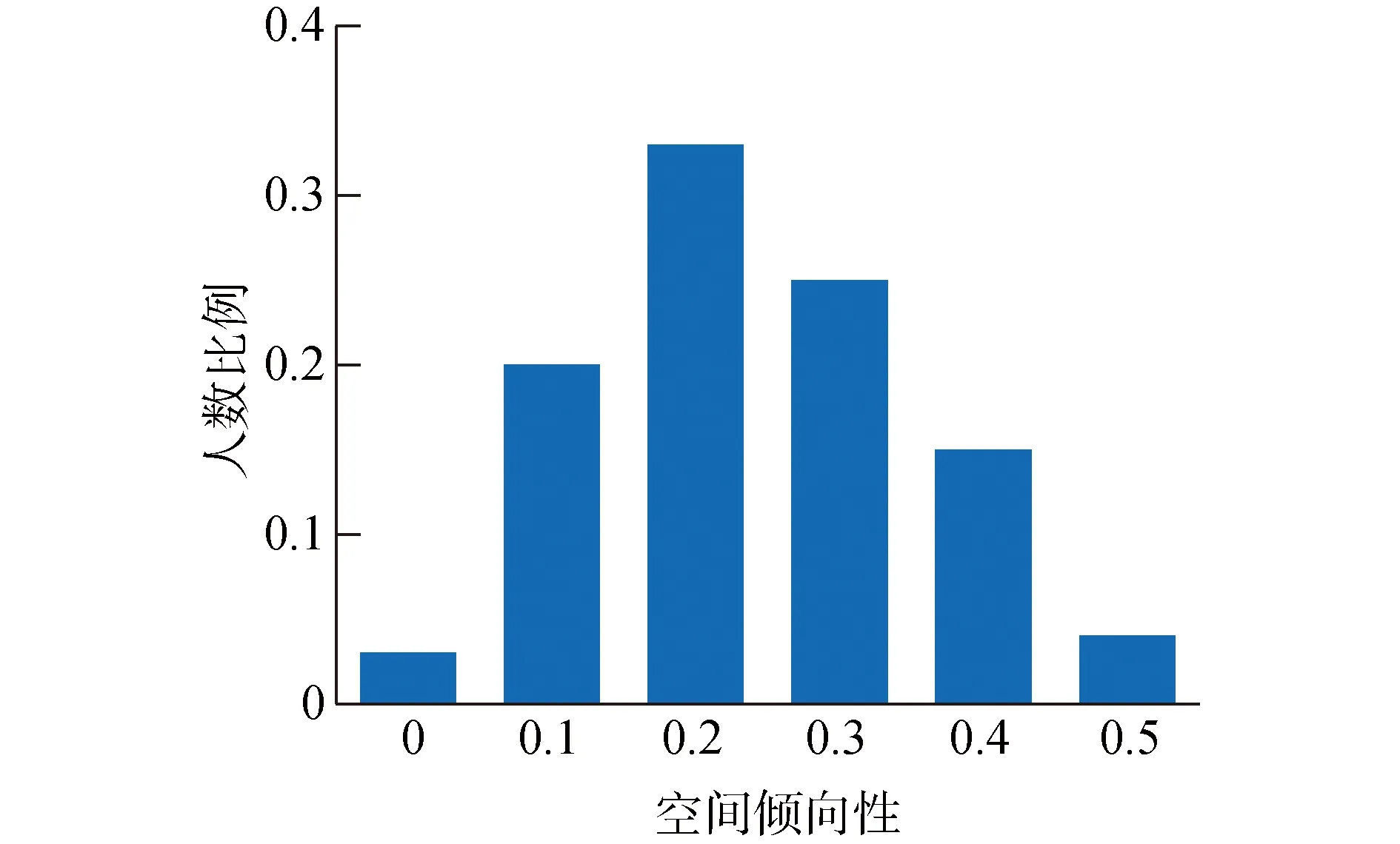
图1 用户移动行为的空间倾向性Fig.1 Spatial tendency of users′ mobility behaviors
1.2 用户移动轨迹中的时间属性
除了空间属性,用户移动轨迹也常常包含时间属性。为了充分度量这种时间属性,本文首先定义一种时间感知的位置熵(time-aware location entropy,TALE)。给定一个用户,其TALE定义为:

(4)
式中:T={0,1,…,23}是时间段的集合,如时间段13表示下午13:00~14:00这个时间段;p(t)是用户在时间段t访问一个位置的概率;p(l|t)是用户在时间段t访问位置l的概率。
TALE度量用户移动行为的时间倾向性。对一个用户来说,TALE越大,该用户在不同时间段访问一个位置的概率分布越均匀,用户移动行为的时间倾向性越低。当用户在所有时间段访问所有位置的概率都相同时,即∀t∈T,∀l∈L,p(l|t)=p(l),则:
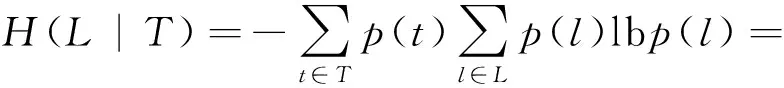

(5)
此时TALE达到最大值,与位置熵相等。反之,TALE越小,意味着用户会越有倾向性地在少数时间段访问某些位置。
因此,本文将用户移动行为的时间倾向性定义为:
(6)
式中:I(L;T)是L和T的互信息[21-22],表示时间段对位置访问频率的影响。根据互信息的非负性[21-22],I(L;T)≥0,即TALE的最大值是位置熵。
从时间倾向性的定义可见,对于一个用户来说,位置熵与TALE差值越大,互信息越大,他的移动行为越有时间倾向性,反之则越没有时间倾向性。本文对GeoLife数据进行试验,结果如图2,GeoLife数据集中的绝大多数用户的位置熵与TALE并不相等(时间倾向性非零)。特别地,有近95%的用户的时间倾向性大于0.10,这表明用户访问不同位置的时间并不是随机,他们的移动行为普遍具有较明显的时间倾向性。
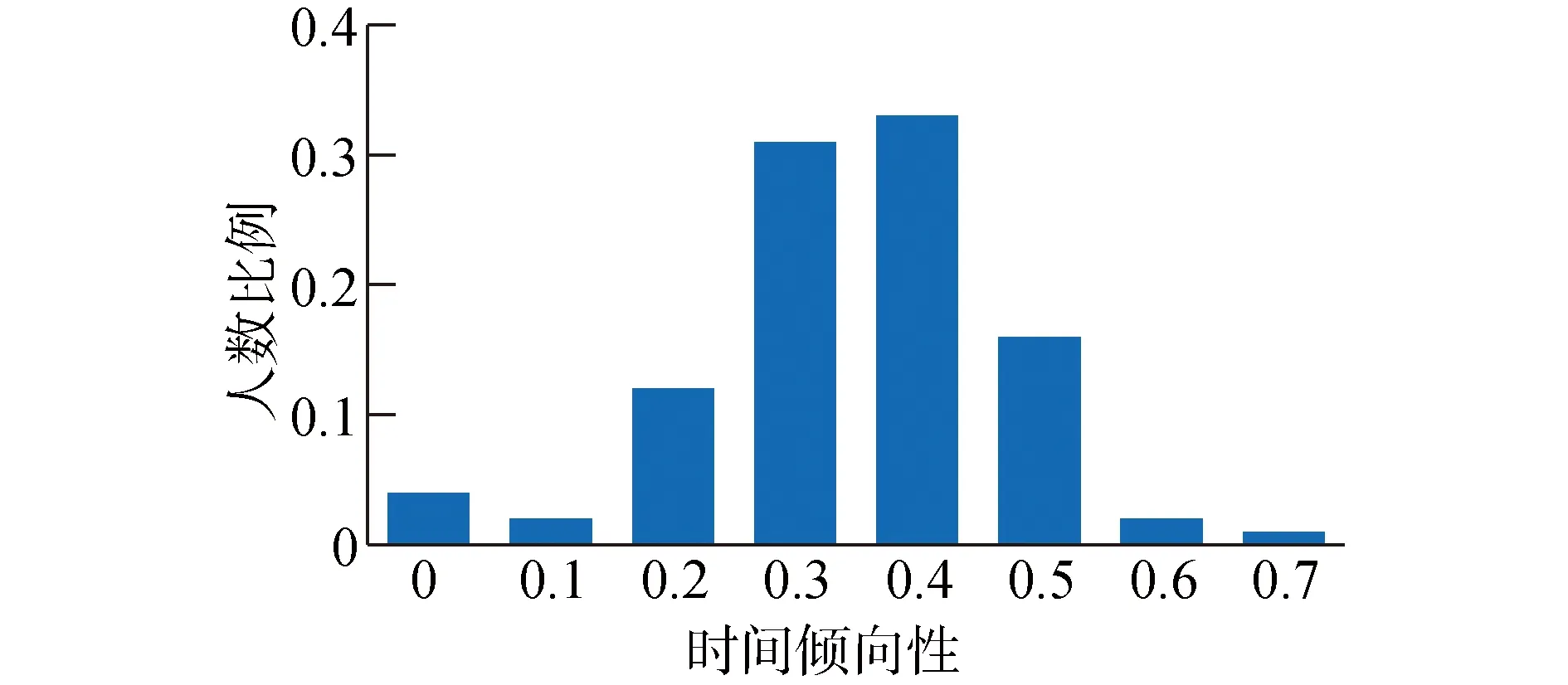
图2 用户移动行为的时间倾向性Fig.2 Temporal tendency of users′ mobility behaviors
2 时空感知的用户隐马尔可夫模型
当前针对用户的移动轨迹主要有2种建模方式,一类是根据位置的频繁程度进行挖掘建模,另一种就是基于马尔可夫模型的。Gonzalez[3]和Song[4]分析了用户的移动数据,并且证明了人类的位置转移具有很高的时空规律性。在位置推理过程中,通常使用一阶马尔可夫模型的转移有序性推测用户位置。但是一阶马尔可夫模型有一个严重的问题就是关注了位置间的转移时序性。因此本文充分在用户行为建模时充分考虑用户移动行为的时间属性。利用隐马尔可夫模型进行建模,将用户的轨迹行为的时间作为隐藏态,将用户在不同时间下出现的位置信息作为输出态。
基于上述分析,本文提出一种时空感知的用户隐马尔可夫模型(spatio-temporal user hidden Markov model,ST-UHMM)作为分析用户移动模式和进行去匿名攻击的基础。
对于一个用户,将其ST-UHMM定义为一个五元组μ=(S,Π,A,O,E):
1)S={s0,s1,…,s24}是状态空间,每个元素作为一个隐藏状态,s24作为终止状态。除s24外,每个隐藏状态对应一个时间段,如s0对应0:00~1:00这个时间段,s22对应22:00~23:00这个时间段。如果状态转移到s24,用户在这一天不再访问任何位置。
2)Π是状态的初始概率集合。一个状态st(t∈T)的初始概率是每天这个用户首先在时间段t访问一个位置的概率,定义为:
(7)
式中αt表示有多少天这个用户首先在时间段t访问一个位置。
3)A是状态转移概率集合。状态st1(t1∈T)到状态st2(t2∈T∪{24})的转移概率定义为:
(8)
式中:βt1表示有多少天用户在时间段t1访问一个位置;βt1,t2表示有多少天这个用户在时间段t1访问一个位置,然后在时间段t2访问下一个位置。如βt1,24表示有多少天用户在时间段t1访问一个位置,然后在当天不再访问任何位置。一个状态到它自身的转移是存在的,这是因为一个用户可能在同一时间段内访问多个不同的位置。
4)O={o1,o2,…,on}是观察集合,集合中的每个元素是用户访问的一个位置,n是用户访问的位置数。
5)E是状态输出概率集合。当前状态为st(t∈T)时输出观察为ok(1≤k≤n)的概率是:
(9)
式中:f(st,ok)表示有多少次用户在时间段t访问观察(位置)ok。
3 时空感知的去匿名攻击模型
本文提出一种时空感知的去匿名攻击模型(spatio-temporal de-anonymization attack model,ST-DAAM)。
如图3所示,ST-DAAM使用的数据集包括训练集和测试集。训练集由用于构建一个去匿名知识库;测试集是匿名轨迹集合,是ST-DAAM的重识别对象。

图3 时空感知的去匿名攻击模型Fig.3 Spatio-temporal de-anonymization attack model
ST-DAAM包括2个过程,即训练过程和测试过程。在训练过程中,根据训练集中的用户移动记录,使用ST-UHMM描述每个用户的移动行为,构造去匿名知识库。在测试过程中,根据测试集的匿名轨迹,使用ST-UHMM描述每个匿名用户的移动行为。计算测试集ST-UHMM与训练集ST-UHMM的相似度,将其相似度最大的训练集ST-UHMM对应的用户就是重识别结果。
本文定义2种时空感知的ST-UHMM相似度:1)时空感知的余弦相似度(spatio-temporal cosine similarity,STCS);2)时空感知的增强相似度(spatio-temporal enhanced similarity,STES)。
首先将同一时间段不同用户的位置集合作为不同的向量,衡量同一时间段不同用户访问位置的余弦相似度,然后将不同时间段的相似度累加。ST-UHMM之间的STCS为:
SimSTC(μ1,μ2)=
(10)
式中:μi=(Si,Πi,Ai,Oi,Ei)(i=1,2)是描述用户ui的移动行为的ST-UHMM;φi(o,t)=1表示用户ui在时间段t访问过观察位置o;φi(o,t)=0表示用户ui在时间段t没有访问过观察位置o。
STCS的定义考虑了ST-UHMM在每个时间段的共同位置。直观上,不同用户在同一时间段内访问共同位置的概率(倾向性)越接近。因此,本文将STES定义为:
SimSTE(μ1,μ2)=
(11)
式中:wt为赋给不同时间段的权重;Oi,t是用户ui在时间段t的观察集合。STES的定义在考虑用户在每个时间段的共同访问位置的同时,也考虑了他们访问共同位置的概率。
4 实验结果与分析
为了评估本文模型的有效性,本节使用MSRA采集的GeoLife数据集进行实验,分析已有的去匿名攻击方法,并将本文模型与之对比。
4.1 数据集
GeoLife数据集包括北京市178个用户的17 621条GPS轨迹数据,总长度120×104km,总时长48 000 h。这些数据以1~5 s的高频采集,采集时间是从2007年4月—2011年10月,记录了用户日常的上班、回家、购物、运动一系列活动。
本文首先对GeoLife数据集进行预处理,包括2个步骤,即地图划分和数据组织。在地图划分过程中,把二维的北京市地图均匀地划分成10 000个格子,然后使用格子ID来表示对应的位置,借以描述所有用户的移动轨迹。数据组织过程按天组织每个用户的移动轨迹,并按小时组织每天的移动轨迹,如表1所示。

表1 用户轨迹Table 1 User trace
在去匿名攻击过程中,一个符合实际且不失一般性的假设是,敌手可以通过一段时间的观察来获得一部分用户移动记录,并可以将其作为训练集。构建训练集后,根据训练集对匿名轨迹的匿名用户进行重识别。因此,本文将所有用户的移动数据划分为2个不相交的轨迹集合:一半数据用来构建训练集Train1;另一半数据用来构建测试集Test1。
Rand方法[22]从训练集中提取测试集,为了和这种方法做全面的比较,本文也构建了训练集Train2和测试集Test2。其中,Train2由所有用户的所有移动数据构成;Test2由Train2中随机抽取的半数移动数据构成。
4.2 评估的去匿名方法
本文构建了Train1-Test1和Train2-Test2的2个对数据集,并用这2个对数据集对已有去匿名方法和本文模型做分析。本文的实验共分析5种去匿名方法,如表2所示。

表2 评估的去匿名攻击方法Table 2 Evaluated de-anonymization attack methods
4.3 实验结果
为了公平地比较本文模型与已有去匿名攻击方法,本文首先分析已有方法,找出他们的最佳参数,然后将本文方法与配置最佳参数的已有方法进行比较。
Rand方法[22]通过随机选取2个或4个时空位置作为准标识符来重识别匿名用户。如图4所示,纵坐标表示去匿名方法的重识别准确度,本文共比较4种Rand方法:
1) S-Rand-2:考虑空间属性,选2个随机位置;
2) S-Rand-4:考虑空间属性,选4个随机位置;
3) ST-Rand-2:考虑时空属性,选2个随机位置;
4) ST-Rand-4:考虑时空属性,选4个随机位置。
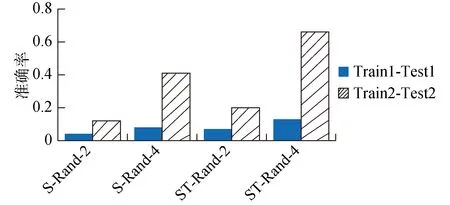
图4 Rand方法[22]的重识别准确度Fig.4 Re-identification accuracies of rand methods[22]
由图4可以看出,ST-Rand-2和ST-Rand-4的重识别准确度分别比S-Rand-2和S-Rand-4高,表明考虑时空属性的Rand方法优于只考虑空间属性的Rand方法,这再一次说明了用户移动轨迹中时空属性对用户移动行为分析的作用。此外,S-Rand-4和ST-Rand-4的重识别准确度分别比S-Rand-2和ST-Rand-2高,表明Rand方法选取4个随机位置表现更佳。ST-Rand-4方法是4个方法中表现最优的一个,对于Train1-Test1数据集的重识别准确度可以达到13%左右,对于数据集Train2-Test2的重识别准确度约为66%。
MMC方法[1]分别为训练集和测试集中的每个用户构建MMC描述,然后通过计算MMC之间的距离来确定用户相似度,以与测试集匿名用户相似度最高的训练集用户作为重识别结果。这种方法可以配置地理距离阈值参数,本文将这个参数配置为1、2、3、4 km,并将配置有这4个参数的MMC方法分别命名为MMC-1、MMC-2、MMC-3、MMC-4。这4个方法的重识别准确度对比如图5所示,可以观察到MMC-1和MMC-2表现最佳。对于数据集Train1-Test1,这2种方法的重识别准确度约为11%;对于数据集Train2-Test2,这2种方法的重识别准确度约为14%。MMC方法的准确度比较低,说明这种方法对时间属性的考虑并不充分。
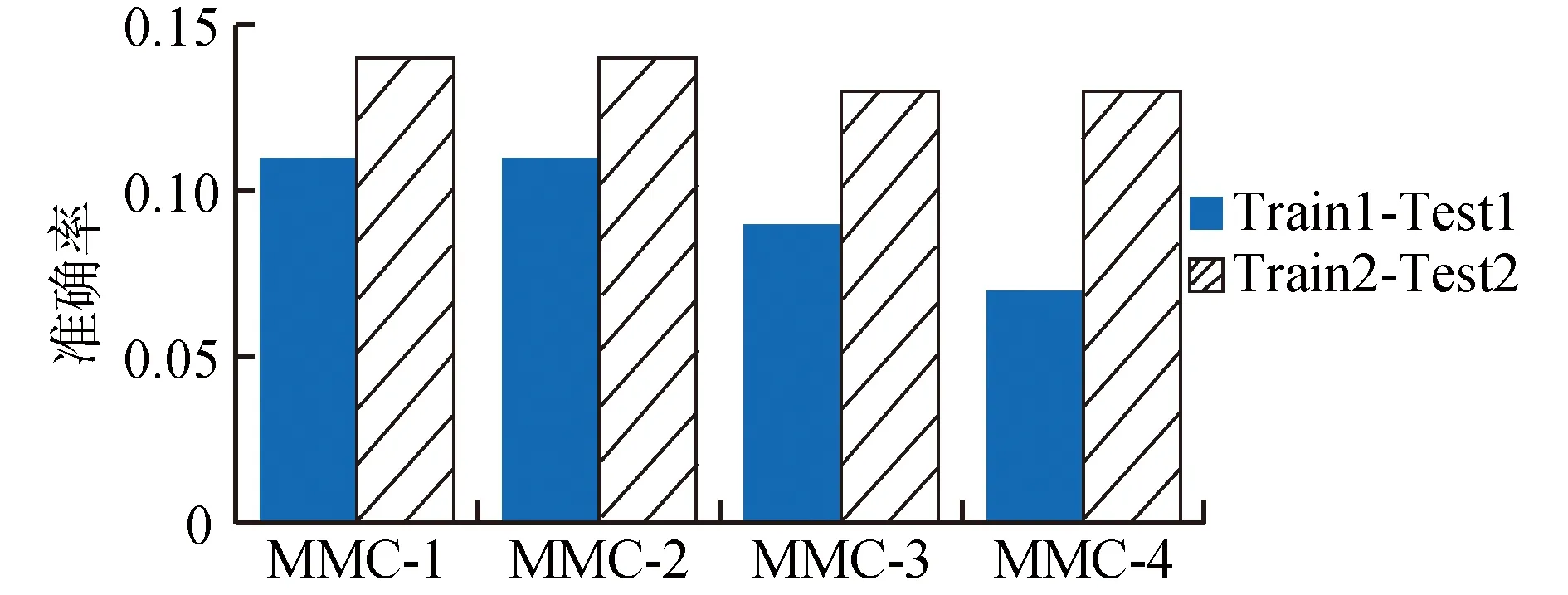
图5 MMC方法[1]的重识别准确度Fig.5 Re-identification accuracies of MMC methods[1]
为了对本文方法与已有方法进行公平地比较,本文为已有方法配置最佳的参数,即将本文的STCS方法和STES方法与ST-Rand-4方法、MMC-1方法、H/W方法进行比较,如图6所示。可以看出,对于数据集Train1-Test1,STCS方法可以达到约32%的准确度,远优于ST-Rand-4方法和MMC-1方法,但相比H/W方法优势不大;而STES方法可以达到约57%的准确度,远优于其他方法。对于数据集Train2-Test2,STCS方法的重识别准确度约为57%,而STES方法的重识别准确度可达到约98%。总的来说,由于Train1-Test1数据集的划分方式更有实际意义,而对于这一对数据集来说,STCS方法相比已有方法有微弱优势。而无论对哪一对数据集来说,STES方法都具有极明显的优势。这说明:
1) 考虑时空属性确实比只考虑空间属性更能有效地进行匿名用户重识别。
2) 相比STCS方法,STES方法对时空属性的考虑更充分,这与第3节的分析是吻合的。
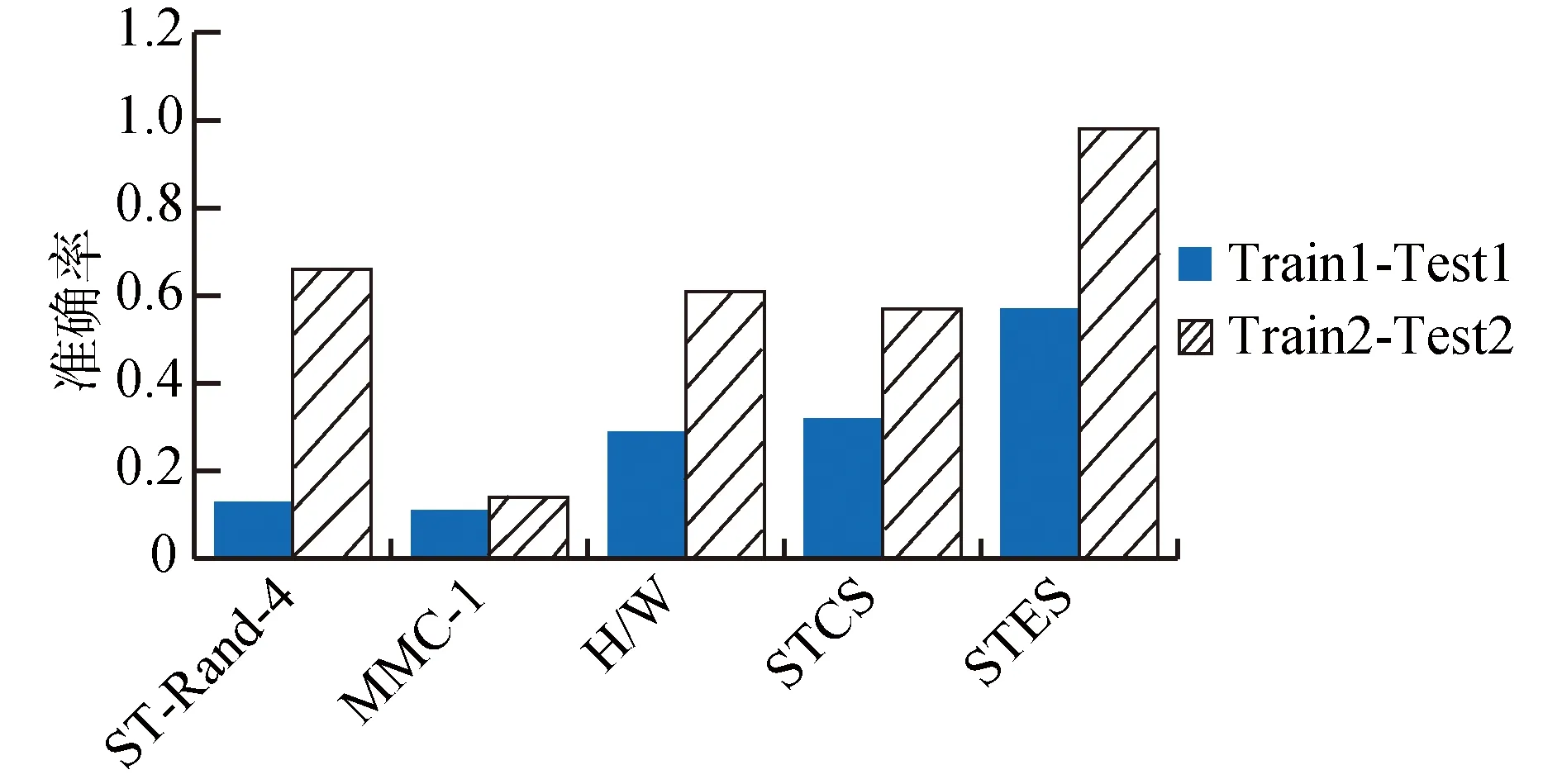
图6 本文去匿名攻击与其他攻击方法的对比Fig.6 Comparison between our attack and other ones
从上述实验可以看到,对于数据集Train1-Test1的重识别准确度要低于对Train2-Test2的重识别准确度。这是因为前者训练集与测试集并无交集,而后者的测试集就是从训练集中抽取出来的,从直观上来看,后者的重识别准确度也应该高于前者。然而,显然基于前者的假设是更有实际意义的,基于后者的比较只是为了与已有方法做更全面的比较(因为Rand方法是基于后者做的实验)。
5 结论
1)本文基于信息熵定量分析了用户移动轨迹中时空倾向性。
2)基于用户移动轨迹中的时空倾向性,提出了一种时空感知的用户隐马尔可夫模型ST-UHMM以及时空感知的去匿名攻击模型ST-DAAM,相应定义了2种时空感知的相似度定义STCS和STES。
3)本文使用MSRA采集的GeoLife数据集进行实验。实验结果说明,本文的STCS方法相比已有方法略有优势,而STES方法则具有明显的优势。说明了时间属性对用户移动行为分析的显著作用,为以后的去匿名攻击方法设计提供了参考。
