人工智能数据中心研究
2021-05-07杨明川刘倩赵继壮
杨明川 刘倩 赵继壮
(中国电信股份有限公司研究院,北京 102200)
0 引言
2020年3月4日,中共中央政治局常务委员会召开会议,明确指出“加快5G网络、数据中心等新型基础设施建设进度”,将数据中心建设列入“新基建”系统布局范畴。2020年4月20日,国家发展和改革委员会明确将大数据中心与人工智能、云计算、区块链等共同纳入新型基础设施的范围。其中,数据中心的发展是重心,人工智能、云计算、区块链等新技术需要通过数据中心进行聚合发展。因此,在政策红利和数字经济加速发展的双重刺激下,数据中心迎来前所未有的发展机遇,并正在迈入人工智能数据中心的新阶段。
1 新基建与数据中心的发展
20世纪40年代,重达30 t的世界第一台全自动电子数据计算机“埃尼阿克”诞生,从此革命性地开启了人类的新时代;20世纪90年代,随着计算机技术、通信技术、互联网技术的逐步发展,全球进入了信息化时代。总体上,呈现从软件化到互联网化,再到云化、智能化的技术演进趋势(见图1)。
从图1可以看到,数据中心的发展与技术演进趋势紧密相关,每个阶段技术的演进也促进了数据中心的发展,具体可以分为几个阶段:第一个阶段是物理数据中心,对应软件化阶段。电信企业面向大型企业提供机房,包括场地、电源、网络、通信设备等基础电信资源和设施的托管及线路维护服务。第二个阶段是互联网数据中心(Internet Data Center,IDC),对应互联网化阶段。随着互联网产业的兴起,服务器、主机、出口带宽等设备与资源集中放置与维护需求激增,主机托管、网站托管等商业模式出现。第三个阶段是云化数据中心,对应云化阶段。在数据中心物理基础设施之上,通过计算和存储虚拟化等云计算技术,使得数据中心能够按需提供计算力。随着人工智能和大数据技术的快速发展,数据中心也即将向智能化发展,主要基于如下几个方面的因素。
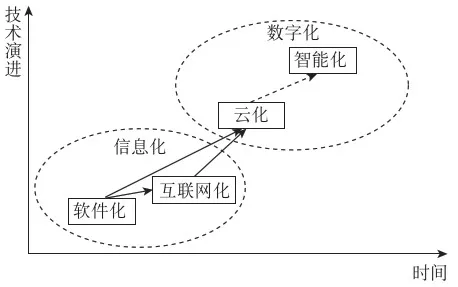
图1 信息化和数字化技术演进趋势
首先,人工智能对算力的需求逐年迅猛增长,已成为最重要的算力资源需求之一。OpenAI在2018年发布的《AI与计算》提出[1],人工智能对算力的需求,2012—2018年增长了30 万倍。国际数据公司(International Data Corporation,IDC)《2019年中国AI基础架构市场调查报告》显示[2],2019年中国AI服务器出货量同比增长46.7%;IDC及浪潮联合发布的《2020—2021中国人工智能计算力发展评估报告》指出[3],2020年中国人工智能服务器占整体服务器市场的16%左右,占全球人工智能服务器市场的1/3。
其次,AI正在规模化、深入地进入各个行业。艾瑞咨询《2020年中国人工智能产业研究报告》显示[4],到2025年,人工智能核心产业规模预计将超过1500 亿元,人工智能产业规模预计超过4500 亿元。中国人工智能市场主要客户来自政府城市治理和运营(公安、司法、城市运营、政务、交通运输管理、国土资源、环保等),互联网与金融行业也位居前列[5]。
第三,行业领头企业纷纷布局人工智能基础设施。百度在AI的基础设施上有百度大脑、飞桨、昆仑等底层基础设施,有百度智能云、Apollo、小度等融合基础设施。阿里达摩院发布了Al芯片含光800,并构建亚洲种类最全、规模最大的人工智能集群,包括图形处理器(Graphics Processing Unit,GPU)、现场可编程门阵列(Field-Programmable Gate Array,FPGA)、网络处理器(Neural-network Processing Unit,NPU)、中央处理器(Central Processing Unit,CPU)、超算集群、第三代神龙架构等在内的公共云服务,形成面向人工智能产业的支持。
2 人工智能数据中心的机遇与挑战
人工智能数据中心从概念上来看,是以数据中心为基础的人工智能的基础设施[6]。具体来说,人工智能数据中心是在超算中心和云计算数据中心大规模并行计算和数据处理的技术架构基础之上,通过大数据和深度学习技术保障其高效、安全运营,以人工智能专用芯片为计算算力底座,融合公共算力服务、数据开放共享、智能生态建设、产业创新聚集“四位一体”的综合平台,可提供算力、数据和算法等人工智能全栈能力,是当前人工智能快速发展和应用所依托的新型算力基础设施。人工智能数据中心在发展过程中主要面临如下挑战[7]。
2.1 异构算力融合
算力是人工智能发展的基础,AI模型构建所需算力呈现出阶跃式增长。单一架构处理器已无法满足人工智能等新型数字化技术对算力的需求。为确保人工智能进一步快速发展,充分释放算力,需要将CPU、GPU、FPGA等异构算力进行充分融合。
2.2 算力的虚拟化调度
当前,大多数AI芯片及服务器仍然为独占使用,无法同时支持多用户或者多任务并行处理,导致算力资源利用率低。通过GPU虚拟化切片技术及相应的池化调度技术,可以充分利用算力资源,实现灵活调度,并降低碎片化,从而节约算力成本,帮助企业降本增效。
2.3 面向AI调度的数据中心网络
在数据中心应用架构从集中式走向分布式的背景之下,广义的算力应包含计算能力、存储能力和网络能力。近年来,SSD及GPU等AI芯片已大幅提升了数据存储和处理能力,而数据中心网络通信时延却成为算力进一步提升的瓶颈,零丢包、低时延、高吞吐的智能无损网络将成为下一代数据中心的网络解决方案。
2.4 数据与算力的融合
IDC在《IDC:2025年中国将拥有全球最大的数据圈》白皮书中预测[4],2018—2025年全球数据总量将增长5倍以上,2025年将达到175 ZB,其中人工智能相关数据复合年增长率为68%。5G与万物互联带来数据爆炸,为人工智能提供了充足的“燃料”,算力是人工智能发展的“引擎”,数据与算力融合是人工智能数据中心的使命[8]。
2.5 数据安全和隐私保护
随着人们对用户隐私和数据安全关注度的不断提高,在不同的组织之间,甚至在同一家公司的不同部门之间,收集和分享数据变得越来越困难,一些高度敏感数据只允许数据所有者拥有,进而形成各自孤立的数据孤岛。安全多方计算、可信执行环境、联邦学习等技术,可在充分的数据安全和隐私保护前提下,实现数据共享、协作和融合[9-10]。
2.6 AI数据中心节能
数据中心是能耗大户,除了IT设备本身的能耗外,用于制冷的非IT设备能耗带来的巨额的额外电能费用已经成为数据中心高速发展的瓶颈,空调制冷系统优化成为降低数据中心基础设施能耗的关键所在。通过人工智能技术,根据历史数据学习各项参数对电源使用效率(Power Usage Effectiveness,PUE)的影响,可满足温控要求,并进一步降低PUE,突破传统节能天花板[11]。
2.7 数据中心智能化、自治化管理
随着数据中心规模越来越大,运维成本越来越高,单纯的人工已经无法满足运维要求,自动化运维成为必然。一方面,采用自动化脚本、深度学习等方式,通过对数据的学习,实现关键设备的预警或者自愈;另一方面,通过自动化巡检机器人代替人工巡检,以零人工的全自动化运维为最终目标。
3 人工智能数据中心关键技术
3.1 异构算力融合
在数据中心加快步伐部署48核以及64核等更高核心CPU来应对激增的算力需求的同时,为了应对计算多元化的需求,越来越多的场景开始引入通用加速芯片,加速硬件承担了大部分的新算力需求。
(1)GPU
具有数以千计的计算核心,相比CPU可实现10~100 倍应用吞吐量,使用GPU来训练深度神经网络,所使用的训练集可以更大,所耗费的时间能够大幅缩短,占用的数据中心基础设施也更少。相比于其他的定制化神经网络计算芯片,GPU具有良好的可编程性和通用性。
(2)FPGA
其灵活性介于CPU、GPU之间,在硬件固定的前提下,允许灵活使用软件进行编程。近年来,FPGA在数据中心的应用日益广泛,已在全球七大超级云计算数据中心IBM、Facebook、微软Azure、AWS、百度云、阿里云、腾讯云得到部署。
(3)专用集成电路(Application Specific Integrated Circuit,ASIC)
是一种为专用目的设计,面向特定用户需求的定制芯片统称。目前,全球各大芯片公司都在积极地进行AI芯片的布局,谷歌的TPU、Pixel Visual Core,英特尔的Myriad系列VPU等,各式各样的ASIC芯片相继在市场上得到了充分的实践与验证。
超威半导体公司(Advanced Micro Devices, Inc.,AMD)的Chiplet、英特尔的Foveros等技术,正在致力于设计统一的高速互联技术,实现CPU、GPU、FPGA、ASIC等计算单元的按需组合,来应对更多样的异构计算需求[5]。
3.2 GPU虚拟化与vGPU调度
当前,GPU仍然是数据中心最通用、最主流的加速计算方案。算力应用方往往由于GPU资源本身的相对稀缺性,面临大规模训练无法完成或训练效率低下、推理环节时延长导致前端用户体验不佳等问题。GPU虚拟化切片技术及相应的虚拟图形处理单元(virtual GPU,vGPU)池化调度技术能够有效提升GPU利用率,充分发挥算力,帮助企业降低成本。
(1)GPU虚拟化切片技术
NVIDIA vGPU是目前主流的GPU虚拟化技术方案,把一块物理GPU虚拟成多块vGPU卡,每个虚拟机(VM)可以独占一块vGPU,每个vGPU直接跟物理GPU对接,在多个工作负载之间共享GPU,从而带来了成本效益和可扩展性。在某些场景下的AI模型训练或推理时,其算力要求不需要占用整块GPU,一块GPU卡多租户共享使用,使得GPU负载任务量以及利用率成倍提升。
(2)vGPU池化调度技术
GPU虚拟化切片技术使得按需调度GPU资源成为可能,vGPU调度方法在共享计算环境中公平有效地分配资源。基于Kubernetes原生调度器可以深度开发满足企业需求的容器编排引擎,调度器以最终计算资源利用率最优为目标,挑选满足要求的节点来部署容器。常用的调度算法有Binpack、Spread等。如图2所示,Binpack算法会优先将一张GPU卡分配完后,再分配另一张GPU卡,减少资源碎片;而Spread算法,系统会尽量将申请的显存分散到各个GPU上,减少资源空置。
3.3 面向AI调度的数据中心网络
可以承载远程直接数据存取(RDMA)的无丢包损失、无吞吐损失、无时延损失的开放以太网,是面向AI调度的数据中心网络主要发展方向。当前,华为已经发布了AI Fabric智能无损数据中心网络方案。通用的无损网络拥塞控制算法DCQCN需要网卡和网络进行协作,每个节点需要配置数十个参数,全网参数组合达到几十万,而通用的配置又无法同时达到零丢包、低延迟和高吞吐要求。AI Fabric方案,一方面通过研发提炼流量模型特征;另一方面通过在交换机集成AI芯片,实时采集流量特征和网络状态,基于AI算法,本地实时决策并动态调整网络参数配置,使得交换机缓存得到合理高效的利用。同时,基于全局采集的流量特征和网络状态数据,结合智能拥塞调度算法,对未来流量进行预测,从全局视角实时修正网卡和网络参数配置,实现RDMA业务流的零丢包、高吞吐和超低时延,加速AI时代的计算和存储效率[12]。
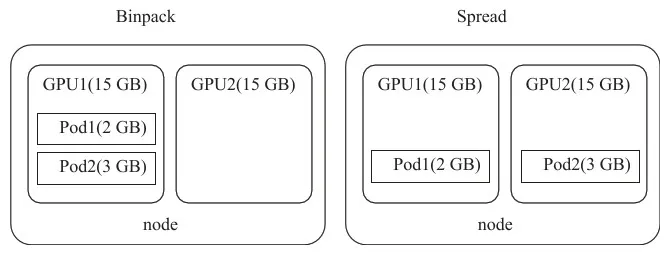
图2 Binpack与Spread调度算法
3.4 AI及大数据混合计算加速
在数据上云的大背景下,随着网络和存储硬件能力的提升,存储计算分离逐渐成为了大数据处理的一大趋势。但是,通过网络从远端存储读取数据仍然是代价较大的操作。在深度学习训练场景下,海量训练数据预处理带来更高的数据吞吐,性能瓶颈更加明显。此外,跨平台业务无法自动化调度、数据多平台重复存储、数据处理流程长、热点数据访问慢等诸多问题更是应运而生。AI及大数据混合计算加速技术可解决以上问题。
在大数据湖之上、计算节点之下构建虚拟数据湖,即在存储框架和计算框架之间增加中间缓存层,提高缓存效率及缓存命中率,快速定位和读取缓存数据;简化存储接入,统一各种持久化存储系统(如Amazon S3、Google Cloud Storage、OpenStack Swift、HDFS、Ceph、NFS等),向上提供统一的API和全局命名空间;构建基于内存、固态硬盘及磁盘的智能多级缓存机制,一方面降低数据应用存储成本,另一方面为关键热数据提供内存级I/O吞吐率。
提供GPU加速计算服务,直接利用GPU进行数据预处理。如表1所示,使用Pandas对DataFrame二维表格进行操作,通过计算在CPU上使用RAPIDS-CUDF用时与在GPU上用时的比值,可以看到,在海量数据预处理场景下,GPU与CPU相比处理速度可达几十倍以上(GPU型号:NVIDIA©V100 Tensor Core;CPU型号:Intel©Xeon©Silver 4214)。提供数据编排调度服务,根据用户业务需求,通过智能调度系统,组建完整的数据流程,满足AI业务需求。
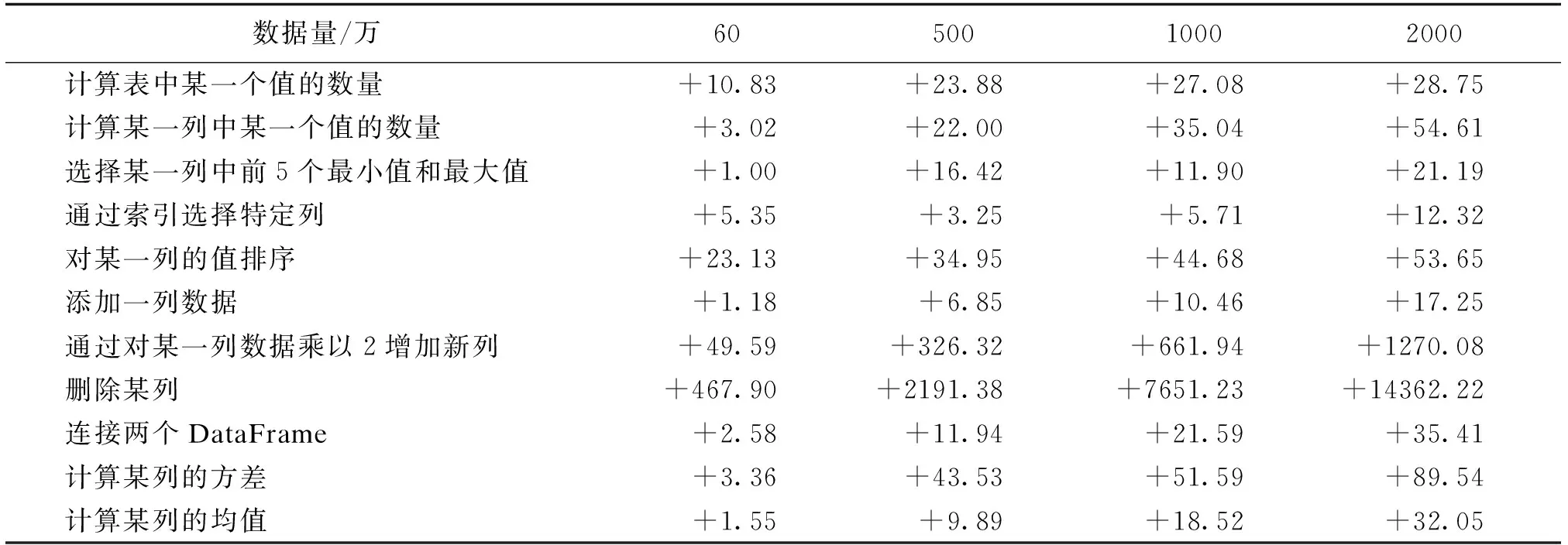
表1 CPU与GPU各类数据操作处理时间比值
3.5 数据协作与隐私保护技术
数据协作与隐私保护技术主要包括安全多方计算、可信执行环境、联邦学习[13]。
(1)安全多方计算(Secure Multi-Party Computation, MPC):指在没有可信第三方的情况下,通过多方共同参与,安全完成协同计算。基于秘密分享、模糊传输、同态加密、混淆电路等,优势在于采用单次随机加密策略、原始数据不能被还原、每次数据都需要参与方共同协调,很好地保证了计算的安全性。
(2)可信执行环境(Trusted Execution Environment, TEE):基于硬件实现,在CPU上构建一块区域,为数据和代码执行提供独立的安全计算空间,其可信前提是硬件不存在漏洞,市面上常见的解决方案包括英特尔的SGX、ARM的TrustZone。
(3)联邦学习(Federated Learning,FL):随着人工智能技术的不断发展,训练人工智能算法模型所需要的数据也正面临数据共享的问题,人工智能数据中心需要通过新的技术来保证不同企业间的数据协作。而联邦学习不仅可以在保证数据隐私安全的基础上,将模型的存储和训练分配给本地边缘侧设备完成,同时各个节点根据各自学习到的信息共同对模型进行更新,进而完成模型的多维度信息训练。联邦学习通过多方的补充拓展数据维度,同时在整个模型训练的过程中不涉及原始数据的传输,保障了参与各方的隐私。另外,在联邦学习加持下的服务来源于本地,避免了网络传输原始数据造成的计算时间开销。
3.6 人工智能开发平台
人工智能开发平台是数据中心AI基础设施及资源与产业下游AI产品及解决方案连接的重要枢纽,互联网厂商(如百度、阿里巴巴、腾讯、京东等)、AI科技公司(如科大讯飞、商汤等)、行业企业(如华为、中兴、浪潮等)等纷纷参与到AI开发平台的建设中,中国电信作为运营商,为满足自身企业数字化转型的需求,也研发了具有自主产权的AI赋能平台。
人工智能开发平台提供集中资源管理、集约数据接入、一站AI开发、统一模型管理、便捷AI服务,促进多团队流水线“一条龙”协作,服务企业AI及数据科学探索,主要包括以下功能。
(1)数据接入及标注模块:提供数据接入、清洗、探索等预处理服务,以及数据标注和特征工程服务。
(2)模型训练模块:提供面向人工智能模型学习的训练能力,满足算法研发人员进行AI能力模型的设计、开发、测试和发布等要求。
(3)模型管理模块:提供统一的AI模型管理能力,对AI模型的基础信息、生命周期、配套引擎、使用申请等内容进行集中管控,提升模型的复用效率。
(4)推理服务模块:提供人工智能在线推理环境,实现AI能力的对外服务,并可支持海量服务请求。
(5)资源管理模块:提供各类应用部署运行环境,并根据各应用的使用要求对基础资源进行动态调度。
3.7 数据中心AI节能
Google利用Deepmind系统节省30%数据中心能耗,节省上亿美元电费;阿里巴巴通过DC Brain智能化电力和热能管理实现25%的节能;中国电信目前也已在多个机房试点AI节能效果,挖掘潜在节能空间,实现精细化、定制化节能。数据中心智慧节能的实施包括数据采集、场景化AI建模、策略执行3个环节。
(1)数据采集环节
收集机房面积、机柜数量、空调额定显冷量等静态数据,动态采集机柜温湿度、负载、地板出风量等机柜数据,空调出/回风温度、电流等空调数据,冷冻水出/回水温度、冷却出/回水温度、水流量、泵频率、冷塔频率及各部分功率等水冷机组数据。
(2)场景化AI建模环节
包括机柜出风温度预测模型,通过机柜负载、机柜进风温度与出风地板开度预测机柜出风温度,指导出风地板调节;热平衡模型,建立机房设备发热与空调输出冷量,空调功耗的平衡关系,指导空调温度与PID参数调节;水冷机组功耗/制冷量预测模型,采集水冷机组运行参数,建立主机功耗与制冷量预测模型,寻找最优主机功耗下的冷冻出水温度。通过数据中心机房数字孪生系统可对预测结果进行可视化展示。
(3)策略执行环节
根据数据中心机房本身的基础设施条件的不同,一部分机房可以实现全自动控制,另一部分机房可根据AI策略进行人工实施。
3.8 数据中心智能预警与自愈
建设数据中心基础设施管理系统(Data Center Infrastructure Management,DCIM),通过软件、硬件和传感器等对数据中心关键设备(如电源、交换机、路由器、服务器等)进行集中监控、容量规划、一键控制等管理操作[14]。
在此基础上,采用自动化脚本、深度学习等方式实现对数据的学习、对关键设备智能监测的预警。从揭示设备运行状态劣化发展趋势规律与特征入手,预报设备运行状态,预测今后多长时间设备运行状态将达到不可接受的程度,并根据恶化程度进行早期故障预警,制定可行的安全保障措施及设备维修计划,实现关键设备监控、调配、预警及自愈。
3.9 自动化巡检机器人
人工巡视效率低、成本高、漏检多,信息传递流程繁琐,故障溯源困难。自动化巡检机器人为降低运维成本、提升运维效率提供了新的解决方案,不仅可以对服务器等设备进行全天候巡视和自主检测,还可以针对涉密关键区域及高风险区域等人工巡检难以开展的区域进行监控和诊断[15]。
当前,巡检机器人以机器人技术为硬件主体,以AI图像识别检测等技术为算法核心,可通过计算机视觉方案完成机房的检测巡视、故障灯识别;通过红外传感器实现机房设备温度监控;通过声光、气体传感器实现火灾等隐患的排查。主流巡检机器人具有支持7×24 h设备巡检,温湿度、异味、空气质量、噪声等动态环境监测,以及设备盘点等功能[16]。
4 结束语
人工智能数据中心代表了未来数字化的发展方向。随着智能化社会的不断发展,人工智能数据中心将成为新基建的核心,不再局限于算力供应,而成为融合公共算力生产、数据开放共享、智慧生态建设、产业创新聚集四大功能为一体的综合平台。通过人工智能数据中心,可以把数据、算力、网络、存储等资源有效地整合起来,并将大数据、人工智能、区块链、物联网、新型网络等新技术充分融合。以人工智能数据中心为载体,为数字化的新基建提供统一的承载方案,其广泛应用将加速推动产业AI化和AI产业化,带动形成多层级产业生态体系,推动数字经济与传统产业深度融合,加速产业转型升级,促进经济高质量发展。目前,人工智能数据中心还处于起步阶段,诸多技术还处于探索之中,特别是资源和技术的充分融合还有很长的路要走。
