基于FM&ResNet模型的点击率预测研究
2021-05-07罗逸伦
罗逸伦
(广东财经大学,广东广州 510320)
0 引言
随着移动设备的普及,移动互联网时代已经来临。广告商利用互联网以及数据媒体平台进行广告营销成为趋势。同时,海量的推荐信息往往会影响用户的上网体验。因此,在网络资源有限的情况下,如何高效地提取用户行为特征,精准推荐适合用户的业务和内容,成为广告推荐领域需要解决的问题。
广告推荐领域中的一个重要环节就是对将广告投放到一个曝光机会(ad Impression)的用户点击概率进行预测[1],将广告尽可能的投放到点击率高的曝光机会用以最大化广告商的收益。因此,广告推荐的问题一般可以理解为广告点击率(Click-Through Rate,CTR)预测的问题。
CTR预测是一个典型的回归问题,逻辑斯蒂回归(Logistic Regression,LR)可以很好的将非线性的原始数据处理成线性的输出结果[2]。但是由于线性模型无法学习并提取数据中的高阶组合特征(非线性信息),从而限制该模型的性能。为了解决这一问题,因子分解机(Factorization Machine,FM)模型将数据中的高维隐形稀疏特征映射到低维稠密向量中,并使用向量内积方法来学习两两特征之间隐含的特征信息,在学习非线性信息的同时大幅度降低了特征两两组合导致的计算复杂度[3]。但是受限于计算复杂度和计算效率,FM模型一般只考虑提取2阶交叉特征,无法更深层次的提取高阶特征。
在过去几年,深度学习在自然语言处理、语义识别以及计算机视觉等一系列领域中取得了令人瞩目的成就,其挖掘数据特征间高阶隐含信息的能力也被应用于CTR预测领域中。文献[4]中提出了一个FM与深度神经网络(Deep Neural Network,DNN)相结合的模型FNN。该模型的特点是使用预先训练好的FM模型,得到特征之间的稠密隐含向量,之后将这些隐含向量作为DNN的输入进行训练得到最终的预测结果[4]。但是模型性能受限于FM的预训练的效果,同时FNN模型无法很好的学习低阶的特征组合,进一步限制了模型的性能。Google的研究人员为了满足同时学习低阶与高阶组合特征信息的需求,在文献[5]中提出了Wide&Deep模型,该模型使用融合结构将线性模型和深度学习模型融合在一起并行训练,在利用深度学习提取特征间高阶隐含信息的同时,使用线性模型学习低阶特征携带的信息,因此预测性能超过了FNN等模型[5]。文献[3]在该模型的基础上,将Wide&Deep模型中线性模型模块使用的LR模型替换成FM模型,从而提出了DeepFM模型,进一步的改进了模型的预测性能。
本文借鉴了Wide&Deep以及DeepFM模型的设计思路,在模型的深度学习模块中加入残差神经网络,提高模型特征间高阶隐含信息的学习能力。在线性模块中采用FM模型去学习低阶特征里携带的信息,得到一种由残差神经网络和因子分解机组成的模型——FM&Resnet模型,并验证该模型的效果。
1 相关理论
1.1 因子分解机模型
FM(Factorization Machine)因子分解机最早是由Steffen Rendle(现任职于Google公司)于2010年的ICDM会议(Industrial Conference on Data Mining)上提出的,该模型在数据非常稀疏的情况下,依然可以估计出可靠的特征参数,并进行预测[6]。FM模型思想是基于线性回归模型,对于一个给定的特征向量X=(x1,x2,…,xn)T,线性回归模型为=w0+w1x+…+wnx,其中特征分量xi与xj(i≠j)之间相互独立,此时的 仅仅考虑单个特征的分量,而没有考虑互异特征之间的组合关系。因此FM引入了二阶组合项xixj,模型变换为:
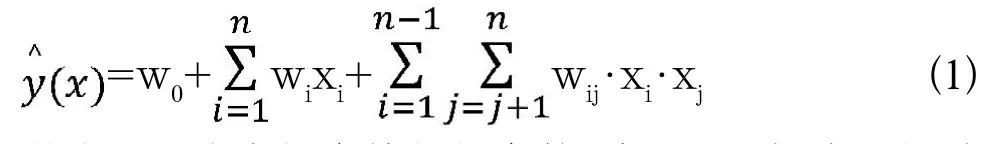
其中,wij代表组合特征的参数,在xi和xj都非零的时候才有意义,但是数据稀疏的问题在实际应用场景中普遍存在,在样本数据本身就比较稀疏的情况下,能满足“xi和xj都非零”条件的样本数量将会更少,训练样本不足会影响到模型性能。为了解决这个问题,FM模型针对每一个特征分量,引入了一个隐向量的概念Vi=(vi1,vi2,…,vik)T∈RT,i=1,2…n,用于替代参数wij,其中k∈N+为根据实际情况与经验设置的超参数,可得到新的FM模型公式如下:

此时公式中有两层循环和k维内积,方程的时间复杂度为O(kn2),因此在计算的时候可以采用下式的优化方法,将时间复杂度从O(kn2)降低至O(kn),提高FM模型的计算效率。

1.2 残差神经网络

图1 FM&ResNet模型架构图Fig.1 FM&ResNet model architecture diagram
随着深度学习发展的不断深入,更多的深度神经网络模型被提出,如Lenet、Alexnet以及VGG-16等。然而在许多情况下,训练深层网络的过程中,我们都会发现一个更加复杂的8层的网络的效果往往不如相对简单的3层的神经网络。残差网络为了解决深层网络训练的问题,增加一个恒等映射(identity mapping),将原始所需要学的函数H(x)转换成F(x)+x。假设某段神经网络中的输入与输出是x和H(x),如果将原始输入x直接传到输出作为初始的结果,那么学习的目标就从H(x)变为了F(x)+x,即残差。虽然两种表达式效果相同,但是F(x)+x的优化难度比H(x)简单的多。给网络末端添加一个恒等映射不会给网络增加额外的参数和计算量,并且在模型层数增加时能够很好的解决模型的退化问题。
1.3 FM&ResNet模型
由前文所分析,FM模型在逻辑回归模型的基础上提出了使用隐向量作为内积用来表示特征之间的组合,但是受限于模型的计算复杂度考量,FM模型一般也只是提取二阶的特征组合进行学习。在广告点击率预测领域,低阶特征和高阶特征组合同样重要,但是特征组合阶数越高越复杂,学习的难度也随之上升,同时学习两种特征组合的性能要比只学习其中一种的性能要好。所以本文从同时学习高阶隐性特征与低阶显现特征的角度出发,在原有的DeepFM模型上进行改进,引入残差神经模块,增强高阶组合特征的挖掘能力,得到了由残差深度神经网络和因子分解机组成的模型——FM&ResNet模型,图1是FM&ResNet模型的架构图。
如图1中可以看出FM&Resnet模型主要分为两个部分:深度残差神经网络部分和FM部分,利用FM模型学习一阶以及二阶组合特征,完成样本低阶特征的提取;在深度神经网络中引入残差模块,利用深度学习提取高阶特征的能力,来学习样本中的高阶特征信息。又在深度残差深度模块输入层前部引入了嵌入层,将输入的样本向量压缩成低位稠密的向量,既解决了数据稀疏的问题,又避免了多类型的特征one-hot编码之后维度过大增加计算复杂度的问题。由残差神经网络和FM共同组成模型,同时进行训练,最终得到的结果如下:

其中,YResNet代表深度残差神经网络部分的输出,YFM代表FM部分的输出,两者的输出结果通过一个Sigmoid函数将结果转换为(0,1)之间的一个数值,最终模型得到了点击率预测的计算结果。
2 实验结果
本文采用的实验数据集来自于Criteo点击率预测挑战赛的公开数据集,该数据集的样本量为4千万的训练样本,5百万的测试样本,一共有13个数值特征和26个分类特征。模型的评估方法采用的是AUC评分和LogLoss损失函数,其中AUC定义为ROC曲线下与坐标围成的面积,AUC值越大代表模型性能越好;LogLoss代表交叉熵损失,用来评估预测值与真实值不一致的程度,LogLoss值越小,说明预测模型性能越好。本次实验以DeepFM、FM&ResNet两个模型作为对比分析。从Criteo数据集中分别抽取2千万条记录与1千万条记录作为数据A和数据B,训练样本与测试样本比例10:1,实验结果如表1。

表1 对比实验结果Tab.1 Comparative experimental results
可以看出FM&ResNet模型引入残差神经网络后,模型提升了高阶隐形特征的学习能力,在不同数量级的数据集上比较原模型有更好的预测效果,AUC值平均提升了0.25%,LogLoss平均降低了0.41%。FM&ResNet增强了提取样本中高阶隐形特征的能力,预测效果要比DeepFM模型要好。
3 结语
本文针对点击率预测问题,改进原模型DeepFM,增强了高阶隐形特征的学习能力,得到了基于因子分解机和残差神经网络的模型——FM&ResNet,并与原模型进行了比较,最终发现在不同数量级别的训练样本上,FM&ResNet模型的预测效果要更好,可以有效的挖掘样本中的特征组合,提高广告推荐的精准性。综上,利用FM&ResNet模型可以从用户行为习惯中高效地挖掘用户行为特征,提高广告点击率预测性能,帮助广告商精准、高效地投放广告,达到最大化收益的目的,对于用户来说可以大量减少无效信息的干扰,提高了用户上网体验,从而达到一个双赢的局面。
