融合注意力机制的Unified-Transformer自动问答系统研究
2021-05-07裴鸣轩冯艳红王金玉
裴鸣轩 冯艳红 王金玉






摘 要:智能问答是自然语言处理领域一个非常热门的研究方向,其综合运用了很多自然语言处理技术。为提高智能问答系统的正确性和准确性,文章提出了融合注意力机制的Unified-Transformer模型。在数据集上对提出的算法进行了测试,实验结果表明,相较于常用的模型,该模型可以更好地解决问答问题,提升问答系统的精度,可以为其他领域的问答系统提供全新的思路。
关键词:记忆网络;智能问答;Transformer
中图分类号:TP391.1;TP18 文献标识码:A文章编号:2096-4706(2021)23-0123-05
Research on Unified-Transformer Automatic Question Answering System Integrating Attention Mechanism
PEI Mingxuan1, FENG Yanhong2, WANG Jinyu1
(1.School of Information Engineering, Dalian Ocean University, Dalian 116023, China; 2.Key Laboratory of Marine Information Technology of Liaoning Province, Dalian Ocean University, Dalian 116023, China)
Abstract: Intelligent question answering is a very popular research direction in the field of natural language processing. It comprehensively uses many natural language processing technologies. In order to improve the correctness and accuracy of intelligent question answering system, this paper proposes the Unified-Transformer model integrating attention mechanism. The proposed algorithm is tested on the data set. The experimental results show that compared with the commonly used models, the model can better solve the question answering problem, improve the accuracy of the question answering system, and can provide a new idea for the question answering system in other fields.
Keywords: memory network; intelligent question answering; Transformer
0 引 言
近年来,智能问答[1-3]一直是自然语言处理领域的研究热点之一,引起人们的广泛重视。智能问答可以追溯到人工智能诞生的时候,图灵于1950年提出观察机器是否具备合理解决某一问题所需能力的设想,并以此检验机器是否拥有人类智能,也就是人工智能。Weizenbaum于1966年设计了一款名叫ELIZA的聊天机器人[4],实现了機器与人之间简单的沟通交流,然而,这并不代表机器真正意义上掌握了自然语言。此后也有大量的研究成果出现,例如Colby设计的Jabberwwacky[5]、ALICE[6]、Parrry[7],IBM公司于2011年设计并开发了超级计算机“沃森”,微软在2014年正式推出小冰机器人。其中,“沃森”在知识竞赛电视节目中上演“人机大战”,打败了两位世界顶尖的人类棋手,这也被认为是人工智能领域的一次里程碑式发展。在传统的智能问答中,基于信息检索的问答是较为常用的经典方法,还有基于知识图谱的问答方法,基于阅读理解的问答方法,等等。
记忆网络[8,9]是近年来在智能问答中出现的一种更好的方法。而在这之前,RNN[10,11]、LSTM[11,12]及其变种gru采用了一定的记忆机制。2015年,Facebook AI提出MEMORY NETWORKS[13,14],这也是人类首次提出记忆网络,使用记忆组件保存场景信息,以实现长期记忆的功能。MEMORY NETWORKS相比之前的记忆机制,记忆能力进一步增强。
传统的记忆网络包括I、G、O、R四个组件。在I中将所有输入转换为网络里的向量,然后在G中更新记忆,传输到O中,将所有合适的记忆抽取出来,再返回去一个向量。每次获得一个向量,代表了一次推理过程,最后在R中转化为所需的格式,比如文字或者是answer。End-To-End Memory Networks[15]是在MEMORY NETWORKS的基础上提出的一种端到端训练方法。它指出通过反复的实验来提取有用的信息,并进行反复推理。还有一种是MEMORY NETWORKS的改进版,提出DMN网络模型包含输入、问题、情景记忆、回答四个模块。模型首先会计算输入和所提问题的有关向量表示,然后根据提出的问题触发Attention机制,使用门控制器的方法选出与问题相关的输入。最后,情景记忆模块会结合相关的输入和提出的问题通过迭代生成记忆,并且得到一个答案的向量表示。当前,最火热也是使用最频繁的是长短时记忆网络(Long Short Term Memory Network, LSTM),普通的循环神经网络RNN很难训练,这导致在实际应用中很难处理长距离的依赖。长短时记忆网络成功解决了原始循环神经网络的弊端。
经典的Transformer结构将Encoder和Decoder独立开来。预训练的时候,Encoder将对话历史进行编码,然后将编码后的结果传给Decoder以生成回复。需要注意的是,Encoder部分的mask是双向语言模型建模,Decoder部分是单向语言模型建模。
这样的结构设计会带来两种问题:首先,解码器堆叠在编码器的输出上,使得微调过程在更新编码器参数时效率较低;其次,有部分工作UNILMv2指出Transformer-ED架构中的显式编码器可能是冗余的,编码步骤可以直接合并到解码器中,从而允许更直接地更新参数。
1 相关工作
在基于RNN编码器——解码器模型的神经翻译质量方面,Kim等人提出了预测器——估计器方法,用以解决翻译质量估计这一问题。预测器RNN编码器——解码器模型完成训练建模后,将从中获得针对翻译中每个单词特征生成的质量特征,而估计器则将单词级别特征转换为语句级别特征。针对不能同时对预测器和估计器进行训练的不足,Li等人提出了将预测器和估计器组成一个端到端的深度神经网络,并通过译文质量估计语料训练的整个模型参数。
来自FAIR的学者们提出了一个(Unified Transformer, UniT)模型,它能够同时学习不同领域的重要任务,比如目标检测、语言理解和多模态推理。基于Transformer编码器-解码器架构,UniT模型利用单个编码器对所有输入模态进行编码,并在各个目标任务上利用一组共享解码器对解码后的所有输入表示加以预测估计,最后再对特定于任务的输出表示加以预测估计。而整个模块对各个目标任务的损失实现了端到端训练。与以往采用transformer的多任务学习方式不同,科研人员可以在各个目标任务上共享相同的模型参数,而不是单独微调特定于任务的模型,并处理各个不同领域更加多样的任务。在实验中,科研人员在八个数据集上共同学习了七项任务,并且可以在相同的监督下仅仅使用一组紧凑的模型参数,在各个应用领域均实现了媲美以往模型的性能。
2 Transformer网络模型
本文提出一种融合注意力机制[16]的Transformer模型,用户只需使用一个统一的单一模型即可共同学习不同模式的多个任务。该模型单元建立在变压器编码器-解码器结构的基础上,由各种输入模态类型的独立编码器构成,后跟具有简单任务特定头部的解码器(每个任务或共享)。而对于语言输入,则使用BERT(尤其是12层的无基础版本),将所有输入词(例如问题)都编码为来自BERT最后一层的隐藏状态序列。在将输入模态编码到隐藏状态序列以后,我们将变换器解码器应用到单个编码模态或两个编码模态的级联序列中,这取决于任务是单峰(即仅视觉或仅语言)还是多峰。
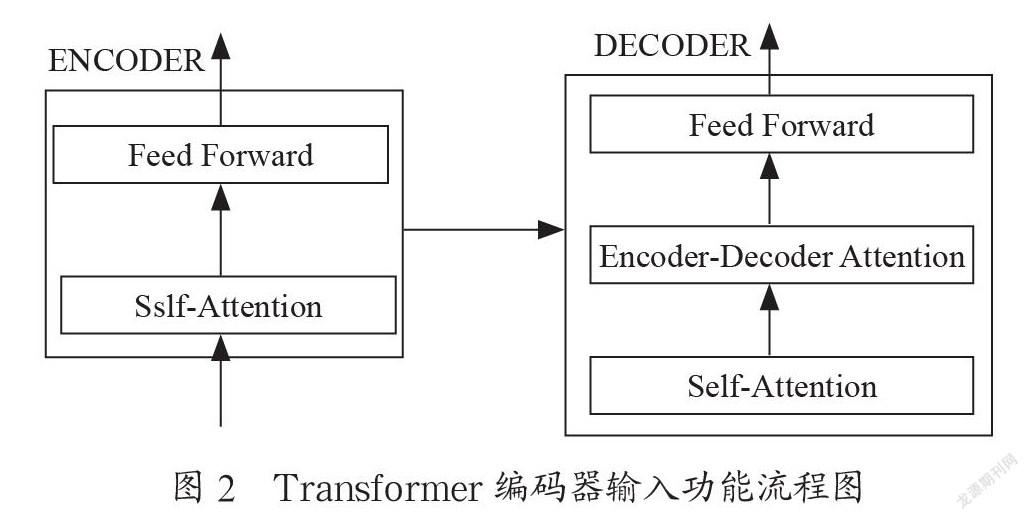
Transformer[17-19]可以将它看作一个黑盒,比如在机器翻译中,接收某一种语言的词句进行输入,之后再将其翻译成另外的语言输出。Transformer由编码组件、解码组件以及连接层构成。如图1所示,编码组件由六层编码器首尾相连堆砌而成,解码组件也是由六层解码器堆砌而成的。编码器结构是完全相同的,但是它并不会共享参数,因为每一个编码器都可以拆解成以下两个字部分。编码器的输入功能是首先通过一个self-attention层,该层帮助编码器能够看到输入序列中的任何其他单词。
self-attention的输出会流向一个前向网络,而每个输入位置与相对应的前向网络是相互独立且互不干扰的。如图2所示,解码器同样也有这些子层,只不过是在两个子层之间添加了attention层,该层有助于解码器注意到输入语句的相关部分,与seq2seq model[20]的Attention作用很相似。
Transformer在编码器和解码器中均采用自注意层堆栈。位置编码和多头结构用于在更高维度上提供位置信息和建模关系。标准的多头注意力将相同的输入特征序列投影到不同的特征空间中:密钥、查询、值分别由aK∈Rn×dm、Q∈Rn×dm、V∈Rn×dm表示,其中n表示序列长度,dm表示特征维度。基于密钥和查询计算注意力权重,公式为:
其中,、∈Rdm×dk和Am∈Rn×n表示头部m={1,2,…,m}的注意力权重。然后我们采用权重和值来计算注意力的值,Attnm=AmV。其中,∈Rdm×dv和Attnm∈Rn×dv是前面m的注意力值。最后,我们将每个头部的结果连接起来以获得多头部注意力:MH Attn=[Attn1,…,AttnM] WO。其中,WO∈RMdv×dm表示线性投影,[·]表示串联操作。在多头自我注意力的帮助下,变换器通过让输入特征序列彼此关注来编码输入特征序列,其中输出特征捕获远程上下文,促使我们将其应用于密集的每像素分类任务。
3 试验结果与分析
对上文中所提出的融合了注意力机制的Unified-Transformer模型及改进方案分别进行实验评估和结果分析。首先,对实验中应用的公开数据集DuConv中的问答数据集加以简单说明;然后,对融合了注意力机制的Unified-Transformer模型中的评估指标及实验参数设置做出简单解释;最后,根据试验结果进行相应的模型比较和实验分析。
4 实验方法与比较
4.1 实验数据集
在百度公司之前所发表的DuConv数据集中进行实验,如图3所示该数据集中包含30 k对话Session,其中对话轮数约为120 k。我们将数据切分为训练集(100 k轮对话)、开发集(10 k轮对话)、测试集(10 k轮对话)。
另外,该数据还给出了影视、演员等相关领域的知识图谱,进行人工标注,每个对话Session过程最后都需要引导到一个预先指定的实体,而且对话也必須围绕知识图谱中的相关知识进行。
4.2 实验指标
在融合了注意力机制的Unified-Transformer模型的实验部分中,采用自动评估(Automatic Evaluation)和人工评估(Human Evaluation)两种评价指标对算法的性能进行判断。
4.2.1 Automatic Evaluation
在某些文字生成场景(对话、广告文案等)中,需要追求文本的多样化。李纪为等人提出了Distinct指标,之后陆续被很多人采用。Distinct的定义为:
其中,Count(unique ngram)表示回复中不重复的ngram数量,Count(word)表示回复中ngram词语的总数量。Distinct-n值越大意味着所生成的多样性越高。
4.2.2 Human Evaluation
在人工评价中,我们采用四个语料级别和对话级别的指标,其中包括连贯性(Coherence)、信息量(Informativeness)、参与度(Engagingness)和人性化(Humanness)。我们要求三名众包工作者在[0,1,2]范围内对回应/对话质量进行打分,最后的分数由多数人的投票结果决定。分数越高越好。下面将介绍评分标准(即评价指标):
(1)连贯性(Coherence)是一个语篇级的指标,衡量反应是否与上下文相关并一致。
(2)信息性(Informativeness)是一个语篇级的指标,评价反应在上下文中是否具有信息性。
(3)参与性(Engagingness)是一个对话级的指标,评价注释者是否愿意与说话者进行长时间的交谈。
(4)人性化(Humanness)是一个对话级的指标,判断说话者是否是人。
4.3 实验设置
4.3.1 实验环境
本研究中融合了注意力机制的Unified-Transformer模型通过pytorch深度学习框架实现,所运行的实验环境支持Nvidiacuda深度学习平台。其中,Python版本为3.7,PyTorch版本为1.7.0,CUDA版本为11.0。
4.3.2 模型参数
本研究所选用的模型参数具体为:epochs=3、batch_size=8、lr=5e-5、weight_decay=0.01、warmup_steps=2 500、max_grad_norm=0.1、max_seq_len=512、max_response_len=128、max_knowledge_len=256。
其中,epochs表示训练轮数;batch_size表示每次迭代每张卡上的样本数目;lr表示基础学习率大小,将其与learning rate scheduler产生的值相乘作为当前学习率;weight_decay表示AdamW优化器中使用的weight_decay的系数;warmup_steps 表示学习率逐渐升高到基础学习率(即上面配置的lr)所需要的迭代数;max_grad_norm 表示梯度裁剪允许的最大梯度值;max_seq_len表示输入序列的最大长度;max_response_len表示输入response的最大长度;max_knowledge_len表示输入knowledge序列的最大长度。
4.4 实验结果及分析
4.4.1 外部模型间性能对比
将融合注意力机制的Unified Transformer模型与近几年先进的问答系统算法进行比较,具体如表1所示。由表1中的数据可以看出,本文所提出的方法(无论是HumanEvaluation还是AutomaticEvaluation)在DuConv数据集上的测试效果均优于其他问答系统算法。同时,与当前最先进的问答系统算法相比,Conherence提升了0.020,Informativeness提升了0.115,Engagingness提升了0.049,Humanness提升了0.059。
4.4.2 内部模块间性能探究
为了验证本文提出的框架中不同模块的有效性,以控制变量的形式设计了几组内部模型之间的对照实验。为了能够更加直观地探明各个模块对模型性能的贡献度及其相应的最优配置,所有后续对照实验均使用DuConv数据集。
为检验注意力机制在模型中的有效性,将本文算法与不加注意力机制的Unified-Transformer算法进行比较。如表2所示,在模型不采用注意力机制的情况下,模型在DuConv数据集上的各指标均有较大程度的下降。实验结果表明,使用注意力机制的效果优于不使用注意力机制的效果。
4.5 实际应用
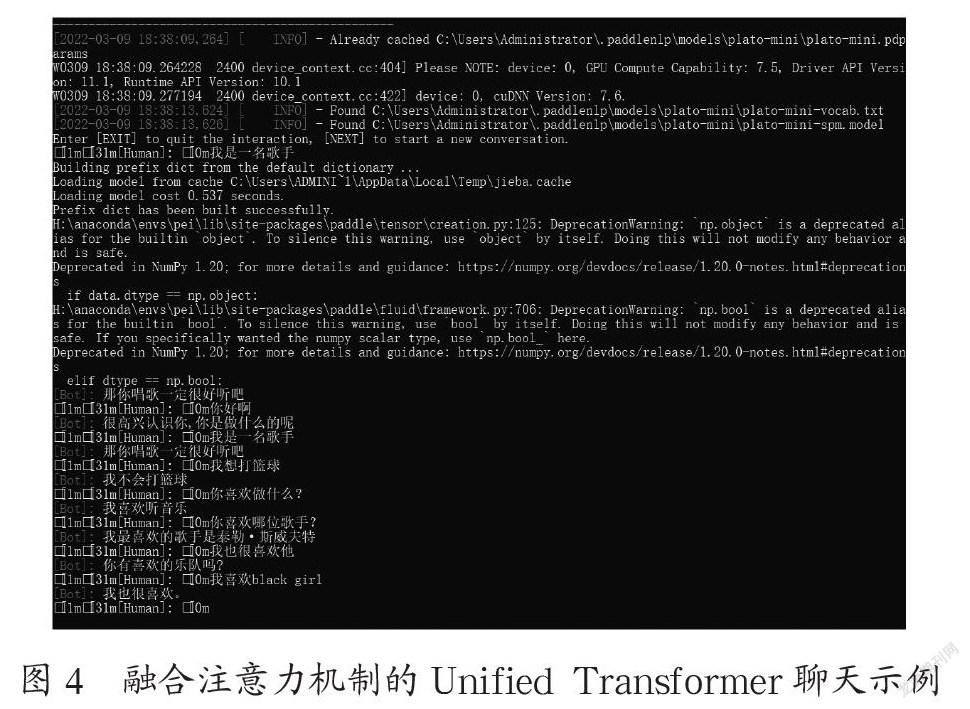
图4为融合注意力机制的Unified-Transformer模型的实际效果图,我们进行了五轮对话,网络模型能够很好地回答对它提出的问题。
5 结 论
为了解决问答系统的精度问题,本文提出了融合注意力机制的Unified-Transformer框架模型。首先基于UniLM思想,提出了融合检索与生成为一体的simBERT模型,用随机替换丰富增广DuConv数据集,提升模型的泛化能力。然后在融合了注意力机制的Encoder-Decoder框架里的变压器编码器中对问句进行编码,由解码器进行解码,用以提升精度。而在取得性能提升的同时,所增加的计算成本几乎可以忽略不计。最后通过五组模型进行对比,实验结果表明融合了注意力机制的Unified-Transformer框架模型优于Transformer模型。综上所述,本文提出的融合了注意力机制的Unified-Transformer框架模型能够有效地回答问题,并且可以有效降低人力成本和時间成本。
参考文献:
[1] 郑实福,刘挺,秦兵,等.自动问答综述 [J].中文信息学报,2002(6):46-52.
[2] 毛先领,李晓明.问答系统研究综述 [J].计算机科学与探索,2012,6(3):193-207.
[3] SHI M. Knowledge Graph Question and Answer System for Mechanical Intelligent Manufacturing Based on Deep Learning [J].Mathematical Problems in Engineering,2021:1-8.
[4] WEIZENBAUM J. ELIZA—a computer program for the study of natural language communication between man and machine [J].Communications of the ACM,9(1):6–45.
[5] CARPENTER R. Jabberwacky [EB/OL].[2021-08-16].http://www.jabberwacky.com.
[6] WALLACE R S.The Anatomy of A.L.I.C.E. [M]//EPSTEIN R,ROBERTS G,BEBER G.Parsing the Turing Test,Dordrecht:Springer,2009.
[7] COLBY K M,WEBER S,HILF F D. Artificial paranoia [J].Artificial Intelligence,1971,2(1):1-25.
[8] CHEN Y,WY L F,ZAKI M J. Bidirectional Attentive Memory Networks for Question Answering over Knowledge Bases [J/OL].arXiv:1903.02188 [cs.CL].(2019-03-06).https://arxiv.org/abs/1903.02188.
[9] MILLER A,FISCH A,DODEG J,et al. Key-Value Memory Networks for Directly Reading Documents [J/OL].arXiv:1606.03126 [cs.CL].(2016-06-09).https://arxiv.org/abs/1606.03126.
[10] ZAREMBA W,SUTSKEVER I,VINYALS O. Recurrent Neural Network Regularization [J/OL].arXiv:1409.2329 [cs.NE].(2014-09-08).https://arxiv.org/abs/1409.2329.
[11] 胡新辰.基于LSTM的語义关系分类研究 [D].哈尔滨:哈尔滨工业大学,2015.
[12] 杨鹤,于红,孙哲涛,等.基于双重注意力机制的渔业标准实体关系抽取 [J].农业工程学报,2021,37(14):204-212.
[13] TAI K S,SOCHR R,MANNING C D. Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks [C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing.Beijing:Association for Computational Linguistics,2015:1556-1566.
[14] 李洋,董红斌.基于CNN和BiLSTM网络特征融合的文本情感分析 [J].计算机应用,2018,38(11):3075-3080.
[15] Facebook Inc. END-TO-END MEMORY NETWORKS:US20170200077A1 [P].2017-07-13.
[16] 黄立威,江碧涛,吕守业,等.基于深度学习的推荐系统研究综述 [J].计算机学报,2018,41(7):1619-1647.
[17] HU R H,SINGH A. UniT:Multimodal Multitask Learning with a Unified Transformer [J/OL].arXiv:2102.10772 [cs.CV].(2021-02-22).https://arxiv.org/abs/2102.10772.
[18] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All You Need [J/OL].arXiv:1706.03762 [cs.CL].(2017-06-12).https://arxiv.org/abs/1706.03762.
[19] ZHU F R,ZHU Y,ZHANG L,et al. A Unified Efficient Pyramid Transformer for Semantic Segmentation [J/OL].arXiv:2107.14209 [cs.CV].(2021-07-29).https://arxiv.org/abs/2107.14209.
[20] XIAO Y Q,LI Y ,YUAN A,et al. History-based attention in Seq2Seq model for multi-label text classification [J/OL]. Knowledge-Based Systems,2021,224(19):107094. [2021-08-27].https://doi.org/10.1016/j.knosys.2021.107094.
作者简介:裴鸣轩(1997—),男,汉族,河北衡水人,硕士研究生在读,研究方向:自然语言处理;冯艳红(1980—),女,汉族,黑龙江绥化人,副教授,硕士研究生,研究方向:自然语言处理、机器学习。王金玉(1995—),女,蒙古族,河南南阳人,硕士研究生在读,研究方向:自然语言处理、机器学习。
