基于Hadoop的海上钻完井井场实时数据库设计与实现
2021-05-07吴凡高健祎谢洪路逄勃
吴凡 高健祎 谢洪路 逄勃


摘 要:随着海上油气勘探行业数字化转型的深入,需要在保证实时数据的高质量、全面性、及时性的同时,提供高效稳定的数据服务,为勘探开发相关各应用系统提供灵活的数据支撑。基于传统架构的实时数据传输系统,在实际应用中存在着传输效率低、稳定性差等问题,文章提出一种基于Hadoop技术的海上钻完井井场实时数据库系统架构,并给出了具体的实现方案及实施成效。
关键词:油气勘探开发;海洋石油;大数据;实时数据库;Hadoop
中图分类号:TP311 文献标识码:A文章编号:2096-4706(2021)23-0012-06
Design and Implementation of Real-time Database for Offshore Drilling and Completion Well Site Based on Hadoop
WU Fan1, GAO Jianyi1,XIE Honglu2, PANG Bo3
(1.China National Offshore Oil Corporation, Beijing 100010, China; 2.China France Bohai Geoservices Co., Ltd., Tianjin 300457, China; 3.Petro-CyberWorks Information Technology Co., Ltd., Beijing 100007, China)
Abstract: With the deepening of digital transformation of offshore oil and gas exploration industry, it is necessary to provide efficient and stable data services while ensuring the high quality, comprehensiveness and timeliness of real-time data, so as to provide flexible data support for various application systems related to exploration and development. The real-time data transmission system based on traditional architecture has some problems in practical application, such as low transmission efficiency and poor stability. This paper presents a real time database system architecture of offshore drilling and completion well site based on Hadoop technology, and gives the specific implementation scheme and implementation results of this database system architecture.
Keywords: oil and gas exploration and development; offshore oil; big data; real time database; Hadoop
0 引 言
我國是油气资源消费大国,但随着消费的持续刚性增长,油气生产供应保障能力不足。在此形势下,我国油气资源开发向深层、深水和非常规等领域拓展已成为推进油气增储上产、增强能源安全的必然选择[1]。海洋油气勘探开发是我国实现石油工业可持续发展的重要战略接替区,同时也是保障国家能源安全、建设海洋强国的战略需求[2]。
长期以来,由于海洋钻井的高成本,在海上油气勘探阶段往往只有少量的探井数据来支撑油气开发的目标评价,从而导致在海上油田开发项目实施之前,对地质油藏的认识存在一定的不确定性。因此,在海洋石油勘探开发过程中必须实时获取现场复杂的地质情况信息。在此背景下,如何利用实时数据,提高实时决策的及时性和科学性,以提升油田的单井产量、最终采收率、钻完井作业时效和油藏管理精细化水平,对增加勘探开发的经济效益具有重要的现实意义。
海上钻完井井场实时数据[3,4]是指海上油气勘探开发钻完井过程中,由传感器实时采集的工程地质数据,包括钻井数据、录井数据、测井数据和测试数据。实时数据记录的时间序列和深度序列实时信息,不仅可以用作实时监测和决策分析,还可以用作大数据应用研究,是智能油田建设的重要数据基础,也是实现智能分析、智能钻井、随钻决策、生产运营一体化等应用场景的必要条件。
1 架构分析
1.1 传统数据库架构
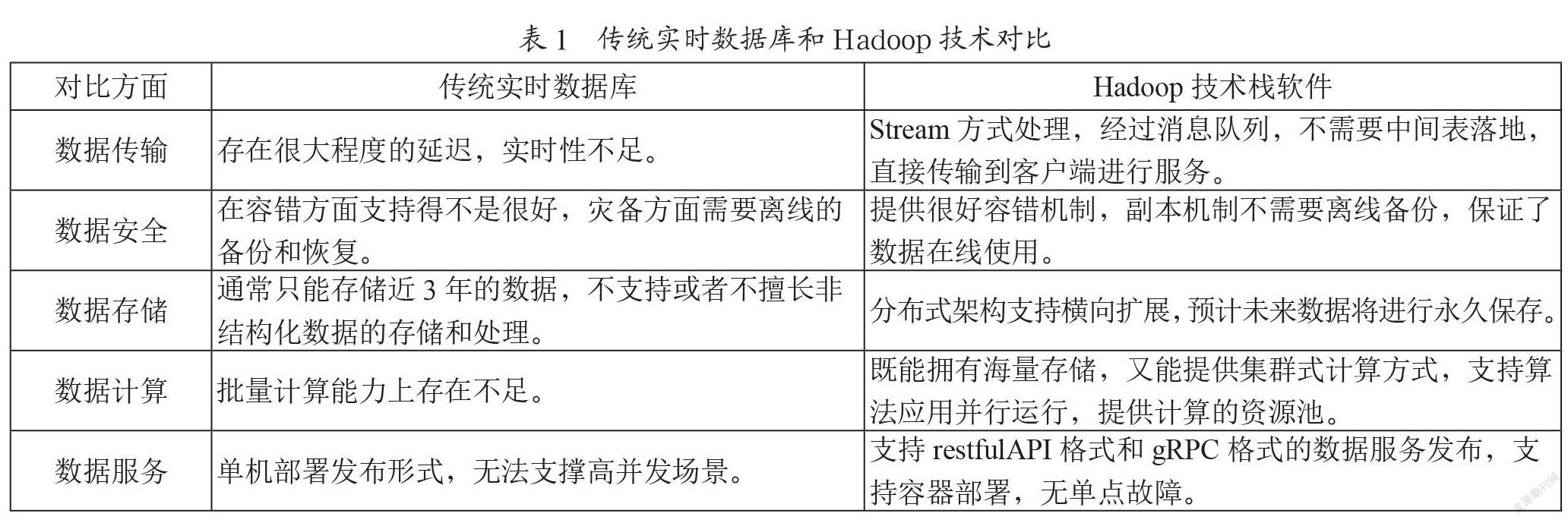
传统石油、电力工业领域对数据的实时处理是先通过OPC、Modbus等方式将数据采集上来,然后直接将数据存到关系型数据库中。业务的实时计算是直接从关系型数据库中取一段时间的数据或者取实时数据库中的数据进行聚合及实时的统计分析。这种方式在数据传输、处理等任意一环出现问题都会导致数据丢失,同时也增大了数据库的访问压力。具体来说,基于传统数据库架构的井场实时数据库存在以下几个方面的不足:
(1)数据传输方面。海上钻井平台通常采用wits0数据传输标准,传统的数据传输系统在采集数据以后,需要先落盘存入数据库,保存好以后再定时的向外循环发送,存在很大程度的延迟,实时性不足。
(2)数据安全方面。传统数据库架构通常采用单机版本的关系型数据库SQLserver、Oracle等,在容错方面支持得不是很好,在灾备方面还需要离线的备份和恢复。
(3)数据存储方面。传统数据库架构通常采用只能存储近3年以内的数据,而勘探开发大数据分析等需求往往需要10年以上历史数据的支撑。同时,关系型数据库只方便用来处理结构固定的表结构数据,不支持或者不擅长非结构化数据的存储和处理。
(4)数据计算方面。传统数据库架构基于SQLserver、Oracle等关系型数据库进行并发读取,批量计算能力上存在不足。在数据量达到100万以上需要开始优化,一般会进行水平拆分,分表、分区和作业同步等操作,这样做大大提高了逻辑的复杂性,难以维护,没有多库负载均衡并行计算功能。
(5)数据服务方面。传统的数据库架构往往采取单机部署发布形式,无法支撑高并发场景。
1.2 基于Hadoop的架构
Hadoop具有高可扩展性和高容错性等优点[5-7],能够实现海量异构数据的低成本高效处理,可解决传统实时数据库架构的不足,主要体现在:
1.2.1 实时计算和分布式存储
海上钻完井井场实时数据库采取Kafka、Kudu、Hbase、Spark及Flink等组件,基于分布式架构,能够同时支持实时计算和离线计算,主要体现在:
Kafka:分布式发布订阅消息系统。在系统中用作于消息队列,数据首先进入消息队列,达到数据的缓冲、错峰、解耦的功能。通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。高吞吐量的特点确保了即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
Kudu:分布式存储系统。Kudu独立于HDFS,具有自有的管理存储数据文件系统,在系统中主要使用是存储结构化数据的大量数据。采用副本方式保证数据安全,通过Raft协议来保证数据一致性。配合impala进行数据查询做到数据秒级响应。
Hbase:分布式存储系统。Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
Spark:分布式内存计算框架。比传统的MapReduce速度提升100倍,在系统中主要适用于数据清洗和数据挖掘,在高并发低延迟方面表现非常出色,面对海量数据配合impala对数据查询写入性能非常好。Spark在实时数据方面提供了对数据流的处理加工功能,在历史数据处理方面能够提取批量数据进行二次清洗,性能非常出色。
Flink:阿里提供的分布式开源计算框架。相对于批流一体的设计架构使用起来更加方便,在系统中主要的作用是实现对实时数据的质量进行动态的监控,以及实现单位时间数据写入量的条数计算对比检查等工作。
1.2.2 高扩展性
Hadoop架构在可用的计算机集簇间分配数据并完成计算任务,这些集簇可以方便地扩展到数以千计的节点中。面对海上勘探开发数据量日益增加,磁盘的容量要求会不断增加,因此采用具备分布式特性的Hadoop存储架构,在增加硬盘的时候全部采用动态扩展空间,在不中断业务的同时进行数据存储扩容。同时,在计算能力方面,分布式架构在指标阈值出现需要增加计算节点的情况下,同样也采取不中断业务的设计架构动态横向地对计算节点进行添加,可以瞬间满足计算的需要。
1.2.3 高效性
Hadoop架构能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。Hadoop的高效性主要體现在:
(1)在数据存储过程中,Hadoop系统架构把所有的数据根据规定随机写入不同的存储节点,以达到数据写入均衡;
(2)Hadoop系统架构在存储管理中会定期检查存储的数据大小,进行数据均衡操作,达到历史数据的均衡;
(3)由于Hadoop系统架构中全部采用万兆网络互联技术,再加上系统的参数设定,数据在节点之间互相流动的效率性能非常高。因此,Hadoop架构在数据提取计算的过程中不会出现数据倾斜或是热点数据节点的情况,避免资源不均衡。
(4)高容错性。Hadoop架构能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。在存储方面,Kudu具备的副本平衡机制,能够通过 Raft 协议来保证数据一致性,副本数量一般采用1、3、5等基数数量,当副本数量少于设定的数量的时候系统会自动进行副本均衡。Hbase依赖于HDFS,同样也是通过副本形式保证数据安全性,使用均衡副本机架感知等技术进行数据平衡。此外,在Hadoop架构进行分布式计算的时候,一旦发现副本不可用的情况,Hadoop架构系统将自动切换重启任务,获取均衡后可用副本进行数据读取使用。
1.3 架构对比
海上钻完井井场实时数据库的高性能要求主要体现在数据写入频率高、查询展示实时性要求高、实时数据的查询展示要求秒级响应、对外提供数据服务的访问并发性高和响应时间短等方面;计算能力要求高则主要体现在实时数据产生频率高,且需要长期保存,要求数据库具有海量数据处理能力并具有复杂SQL计算能力。
针对井场实时数据库需求,Hadoop架构可在如下几个方面解决传统实时数据库方案存在的不足,如表1所示。
2 海上钻完井井场实时数据库设计
2.1 总体架构
总体架构如图1所示。
海上钻完井井场实时数据库全面采集4大类业务数据,通过Web Service传输给Kafka,实时数据进入Kafka消息队列后缓存起来,由SparkStreaming主动地从消息队列获取,然后保存到Kudu/HBase中。最终利用Restful接口,对外提供满足Wits0、WitsML传输协议的数据服务。
上述各环节都会产生很多作业,各作业之间存在依赖关系。实时数据库系统需要对这些作业进行管理,因此需要具备任务调度、任务监控和日志管理功能。
2.2 数据采集架构
数据采集架构如图2所示。
数据采集关键技术采用Kafka消息队列技术,Kafka消息队列本身具有高吞吐、低延迟以及弹性扩展的特点,配合Spark Streaming计算框架能够保证数据传输的实时性。Kafka本身无状态,实时数据进入队列后缓存起来,由SparkStreaming主动地从队列获取,这样就避免了当Spark Streaming故障导致数据丢失的问题;Kafka能够对消息队列进行消息分区,分区后的消息队列能够让SparkStreaming用多个消费进程并行地进行数据消费,可以大大提高数据传输的速率。
对于实时数据,使用Web Service接入陆上数据库,然后再次通过Web Service传给Kafka,由SparkStreaming主动地从Kafka消息队列获取数据后,最终把实时数据存入Kudu/HBase数据库。
2.3 数据存储架构
数据存储架构如图3所示。
由于实时数据体量巨大,而且需要快速响应,因此选择采用基于X86集群的分布式存储架构(Kudu/ HBase),从而满足大容量、多样化数据的低成本存储需求。
利用Kudu/HBase的分布式架构能够弹性扩展,满足海量数据的存储,内部三副本的机制能够避免机器故障带来的数据丢失。Kudu的批量写入特性,能够在大吞吐的情况迅速高效地将数据落地入库;HBase的海量数据高速查询特性能够支撑亿级数据查询的秒级响应。同时,根据数据存储和使用较频繁的业务场景,设计主键或者RowKey,优化各项参数;并使用缓存机制,减少磁盘IO操作等。通过这些性能优化措施,海上钻完井井场实时数据库完全能够支撑对外数据服务的需求。
2.4 数据处理架构
数据处理与计算如图4所示。
数据处理主要是将数据输入到处理器,通过一系列去重、转换、校核等步骤的“处理”工作,然后以期望的格式输出处理过的数据。它从数据的准确性、完整性、一致性、唯一性、适时性、有效性几个方面来解决数据的丢失值、越界值、不一致代码、重复数据等问题。
2.5 数据服务架构
数据服务架构如图5所示。海上钻完井井场实时数据管理系统采用Restful API接口开发,满足Wits0、WitsML井场传输协议对外提供数据服务。这些数据服务主要分为批量数据服务和实时数据服务。其他应用系统可以通过调取这些数据服务,共享海上钻完井井场实时数据资源。
利用标准通用的Restful API和gRPC技术定制化开发实时数据的数据服务,便捷的URL访问和gRPC服务调用,能够实现一次开发,多次调用,从而支撑广泛的业务场景;并利用公司内部数据服务平台,对数据服务进行申请、审核、审批、发布和监控等全生命周期管理。
3 海上钻完井井场实时数据库的实现与成效
海上钻完井井场实时数据库实施方案的总体思路是将实时数据经海上钻井平台汇总后,传输至陆上数据库,再利用企业端实时数据库将其采集存储。利用Web Service将钻井平台采集数据推送至陆上数据库,然后将数据推送至Kafka工具,最终存储至Kudu/HBase中,对外提供数据服务。其中,在钻井平台端,开发完善实时数据传输接口,采用Wits0协议,通过Web Service把实时数据传输到陆上数据库;接着对陆上数据库的实时数据接口进行封装,把实时数据推送给企业端实时数据库。主要技术是利用ETL工具开发抽取工具,抽取的实时数据并写入Kafka消息队列缓存,编写Kafka消费端读取数据,然后写入Kudu/HBase中,最终统一对外提供数据服务。总体实施方案如图6所示。
当前,本文提出的海上钻完井井场实时数据库架构已在某能源企业成功实施,并在降低数据库故障率、提升系统效率、提高历史数据存储时限等方面取得了显著的成效。具体体现在:
(1)降低数据库故障率。基于Hadoop的海上钻完井井场实时数据库在数据的传输方面提供了高可用集群方式进行架构部署的消息队列方式,无单点故障,在传输过程中采用SparkStreaming方式进行流式计算,计算过程中通过数据检查点和记录数据的更新,保证数据容错不会丢失数据,从而降低了停止服务的故障率;同时,利用分布式存储采用副本策略保证数据安全,若是副本丢失,系统会及时地通过算法补充上丢失副本,保障数据健康状态,在此过程中数据服务不会停滞,这种分布式存储大大降低了故障导致的数据服务不可用的情况。基于以上分布式架构,井场实时数据库整体故障率较传统数据库故障率下降60%。
(2)提升运行效率。首先,在传统的实时数据库系统需先落盘再定期提供服务,数据写入后再读取进行服务会存在延迟现象。基于Hadoop的海上钻完井井场实时数据库全部采用流方式进行数据服务,不考虑网络因素可以做到秒级响应,整体效率提升80%。
其次,传统的实时数据库系统使用单台服务器,在大数据获取并发计算的需求时性能和计算能力明显不足。基于Hadoop的海上钻完井井场实时数据库采用了分布式集群架构,在数据存储方面采用分布式架构常用的副本方式保证数据的安全可用,同时由于采用当前技术先进的存储和计算平台,在存储容量,存储时间以及读取数据计算的功能方面达到了领先水平,在系统的存储效率上得到提升,在存储成本方面大大降低。理论上可拓展支持到PT级别数据。
(3)提升历史数据存储时限。传统的实时数据库架构在存储数据的时间周期方面非常受限制,这主要是由传统架构的服务器存储硬盘大小及操作系统对硬盘支持大小的所导致的。企业在目前只能存储将近3年的完整数据,如需要历史数据可能需要离线数据进行手动回复,增加了操作难度,费时费力。基于Hadoop的实时数据库架构在数据存储方面采用分布式存储,把写入的压力分散到集群不同的存储节点上,大大提高了存储的并发能力,可以随时横向增加服务器存储动态扩容的功能,数据可以长时间大容量的保存,实测存储节点可以达到2 000台服务器。在实施基于Hadoop架構的海上钻完井井场实时数据库之后,隶属数据存储将由传统系统的短期临时存储提升到无限拓展的长时限存储。
4 结 论
文章设计一种基于Hadoop的海上钻完井井场实时数据库,通过Kafka、Web Service、SparkStreaming等技术实现秒级的数据实时采集传输;通过现场传输服务器建立数据通信,接收数据后存储于基于Hadoop环境架构的实时数据库中;对外支持Socket和Restful API接口方式的数据服务,并支持Wits0和WitsML两种井场传输协议。该系统的实施,能够从全局提供涵盖钻、录、测、试四大业务数据采集、存储、管理、服务等全流程的一体化解决方案,覆盖钻完井作业全生命周期,确保海上钻完井井场实时数据的高效采集、无缝流转、统一管理和互联共享。
基于Hadoop技术的海上钻完井井场实时数据库建设,将有利于在海上油气勘探开发环节进行实时诊断、精准预测和高效决策,有效支撑钻完井风险预测分析系统,以减少复杂井况及事故,实现作业风险防控,为基于大数据分析的虚拟地球物理、智能勘探、智能工程建设、智能化生产、智能化设备等应用领域提供强大的多模式实时数据服务能力。该架构具有良好的推广应用前景,可广泛应用于各类海上油气勘探信息化应用。
参考文献:
[1] 王陆新,潘继平,杨丽丽.全球深水油气勘探开发现状与前景展望 [J].石油科技论坛,2020,39(2):31-37.
[2] SINGHAL M.Issues and approaches to design of real-time database systems [J].SIGMOD Record,1988,17(1):19-33.
[3] 陈锡荣.中国石化产业发展趋势研究 [J].现代化工,2019,39(6):1-5.
[4] 李阳,廉培庆,薛兆杰,等.大数据及人工智能在油气田开发中的应用现状及展望 [J].中国石油大学学报(自然科学版),2020,44(4):1-11.
[5] DEAN J. MapReduce:Simplified Data Processing on Large Clusters [J].Symposium on Operating System Design & Implementation,2008,51(1):107-113.
[6] GHEMAWAT S,GOBIOFF H,LEUNG S T.The Google File System [J].ACM SIGOPS Operating Systems Review ACM,2003,37(5):29-43.
[7] CHANG F,DEAN J,GHEMAWAT S,et al. Bigtable:a distributed storage system for structured data [C]//USENIX Symposium on Operating System Design and Implementation (OSDI06).Seattle:USENIX:2006:205-218.
作者简介:吴凡(1988—),男,汉族,黑龙江庆安人,工程师,硕士研究生,研究方向:石油地质、数字技术应用以及数据管理;高健祎(1992—),女,汉族,黑龙江哈尔滨人,中级工程师,硕士研究生,研究方向:数据管理及平台建设;谢洪路(1984—),男,汉族,天津人,工程师,本科,研究方向:录井工程及油气勘探开发信息化;逄勃(1981—),男,汉族,辽宁东港人,高級工程师,博士研究生,研究方向:大数据、自动控制、人工智能。
