Spark 计算框架在敏感地理信息检测中的应用研究
2021-04-29严哲周斌雄张祥燊吴君雄
严哲 周斌雄 张祥燊 吴君雄
(海南集思勘测规划设计有限公司 海南海口570203)
1 引言
地理信息是用于描述地理位置、时空分布以及其它相关自然属性的信息资源,对于社会经济的发展具有重要推动作用。随着互联网技术的深入发展,我国的互联网普及率已接近60%,由于地理信息在互联网中以多种形式广泛传播,使得具有特殊敏感地理信息(如军事基地、重要基础设施等的)的保密工作成为一项重要工作[1-4]。
为了加强敏感地理信息的保密工作,需要对地图中的敏感要素进行准确识别。传统的通过人工检测的方法不仅效率低下,而且在准确性和召回率上都较低,这对于国家涉密敏感地理信息的保护极为不利[5]。为此,李安波等提出基于多属性决策及污点跟踪的敏感地理信息识别方法,该方法基于灰色关联分析及理想优基点法对敏感度进行计算分析[6];翟东海等提出了基于条件随机场的敏感信息检测模型,并从准确率、召回率和F 度量值三个方面证实该模型的可靠性[7]。
Spark 是当前十分流行的大数据分析框架,具有运行速度快、通用性强、易用性好等诸多优点,已被广泛应用于人脸图像检索、路网核密度检测等领域,并取得了较好的应用效果[8-9]。将Spark 框架运用于敏感地理信息检测,同时进行并行化优化[10-11],不仅可以提高检测运行效率,而且还可以大大提升检测各项指标,保护国家的信息安全与利益。
2 Spark 计算框架
2.1 Spark 核心RDD
Spark 核心RDD 是指弹性分布式数据集,包括内存存储、只读以及分区记录等三个集合,其依赖关系包括宽依赖和窄依赖,通过RDD 的依赖关系可以形成Spark 计算框架的任务调度及操作模式,而Spark 的操作模式又分为转换操作和运行操作,转换操作不会被执行,而运行操作会触发Spark 提交任务然后执行。
2.2 Spark 任务调度
当运行操作提交任务后,就会促使Spark 进行执行操作。 Spark 的任务调度系统包括DAGScheduler 和Task Scheduler,前者主要负责对用户的交付应用进行分析,并根据不同的依赖关系建立起不同的分析步骤;而Task Scheduler 的主要作用为任务调度运行,即将任务分配至工作节点中。任务调度过程主要为:
(1)通过RDD 的依赖关系构建DAG 图;
(2)系统将DAG 图交由DAGScheduler 进行解析,并分解为相互依赖的stage,形成任务集Task Set;
(3)DAGScheduler 将 任 务 集 发 送 至 Task Scheduler,并通过集管理器将任务再次分发至各个对应的工作节点;
(4)各工作节点根据任务分配进行执行,然后保存和返回执行结果(见图1)。

图1 Spark 任务调度流程
2.3 Spark 运行模式
Spark 运行模式包括local 运行模式、Standalone运行模式、YARN-Client 运行模式和YARN-Cluster运行模式。不管是在何种运行模式下,其都要经过Spark 应用程序的整体运行。Spark 应用程序框架包括驱动程序、集群资源管理器和任务执行进程;其中,集群管理器会根据不同运行模式决定由谁提供资源分配与管理,如在local 运行模式和Standalone运行模式下,主要由Master 提供,在YARN-Client运行模式和YARN-Cluster 运行模式下,则由Resource Manager 提供,见图2。

图2 Spark 运行程序
2.4 敏感度计算
Spark 大数据分析框架的基本前提是对图像进行敏感度计算,敏感度检测计算流程主要分为四个部分,即词法分析提取特征词集、取特征词集中敏感词、文本特征提取和地图文件敏感度计算,见图3。地图文件的敏感度为地点标注信息敏感值与地图附属信息的敏感值之和,即:
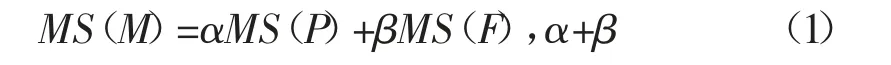
式中:MS(M)表示地图敏感度;MS(P)表示地点标注信息敏感度;MS(F)表示地图附属信息的敏感度;α和β 分别为对应的计算系数,文中分别取值0.4 和0.6。
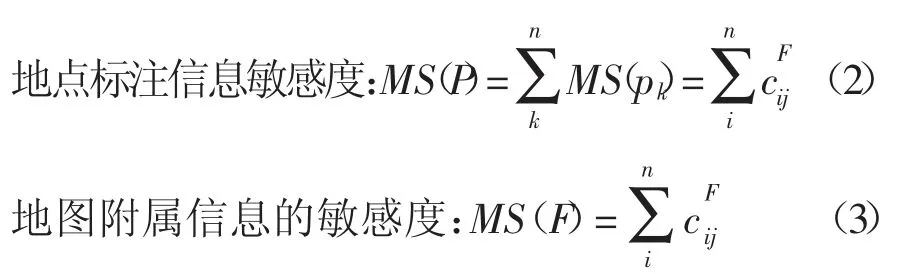


式中:ωi表示ci在文本中的TF-IDF 权重值;Vsj表示sj对应的地理信息敏感系数值;Lsi表示ci在地点标注POI 中的位置属性;Mij表示ci与sj的相似度值。
3 算法性能实验
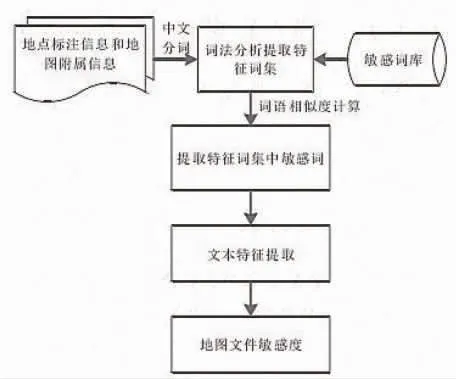
图3 敏感地理信息敏感度计算
为了验证Spark 算法的合理性,采用仿真模拟手段,对比分析了Spark 算法、SCRFs 算法以及SW算法的检测结果。在分析过程中数据集大小为200~1800 个,呈200 等间距递增,并选取10 次实验结果的平均值作为分析结果,见图4。从图中可以看到:随着数据集大小的逐渐增加,所有算法的准确率、召回率以及F 度量值基本呈先增加后逐步稳定的变化趋势;同一数据集下,Spark 算法的准确率、召回率以及F 度量值最大,其次为SCRFs 算法,最小的为SW算法,这是因为Spark 算法不仅考虑了特征词与敏感词之间的直接匹配度,而且还考虑了两者之间的相似性敏感信息以及特征词在文本中的位置属性和权值情况等。因此从提取信息完整度来讲,Spark 算法更全面,对敏感词的检测覆盖程度高于SCRFs 算法以及SW 算法,故准确率和召回率有较大提升。

图4 不同算法仿真结果对比
4 并行化优化
4.1 结构设计
由于Spark 算法需要提取大量的信息,因此,对于运行内存和效率有较高的要求。参考Spark 算法在其它领域的应用,对其进行并行化优化处理。为了提升运行效率,基于Hadoop 和Spark 计算框架,采用HDFS 分布式文件系统和Hbase 数据库,建立包括数据处理层、计算框架控制层、数据预处理层、文本特征提取层以及地图敏感度计算层的由下到上的统一处理结构,见图5。
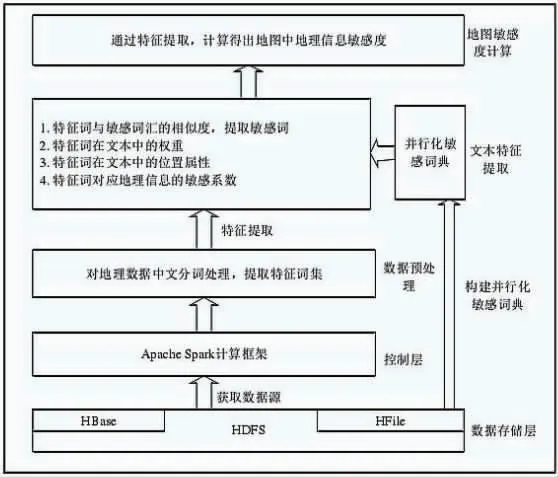
图5 并行化结构设计
4.2 并行化算法流程
根据并行化框架处理结构,将并行化算法流程分为六个步骤:一、将HDFS 的数据文件转化为RDD格式并将其读入Spark 计算框架;二、对读入的数据进行重新分区;三、将重新分区后的数据进行mpa 操作,即进行数据的预处理;四、使用fiter 算子对敏感词进行过滤,生成新的敏感词RDD,并进行词语相似度分析;五、对位置权重、文本权重以及敏感系数等信息进行特征提取;六、计算得到地理信息敏感度,并存储在分布式文件系统中,见图6。

图6 并行化算法流程示意
4.3 并行优化效果
对不同模式下的运行时间效率、加速比以及性能指标进行了仿真分析,结果见图7。从图7 中可以看到:随着数据集个数的增加,在单机模式下,运行时间呈指数型增大,在mapreduce 和Spark 模式下,运行时间近似呈线性增大,随着数据集的增大,Spark 模式下的运行时间与其它两种模式下的运行时间差值逐渐加大,当数据集为4000 个时,Spark 模式的运行时间仅为单机模式的42%;加速比与节点个数呈对数型函数关系变化,当节点数大于6 后,加速比基本达到稳定状态,相同节点数下,Spark 模式的加速比明显大于mapreduce 模式,当节点数为8时,前者加速比为后者的1.6 倍;同理,对并行化优化过后的算法性能指标进行了对比,相比于单机运行模式下,Spark 集群模式下的准确率、召回率和F度量值均有一定程度提高,表明并行优化过后,不仅提高了检测算法的运行效率,而且并未对算法精确度造成影响。

图7 并行优化后仿真结果
5 结束语
本文以互联网地理敏感信息安全为研究背景,将spark 框架运用到敏感地理信息检测中,该算法与其它检测法相比具有更高的准确率、召回率和F 度量值,通过并行优化处理后,其运行效率明显提高,同时不影响算法精确度,可为涉密地理信息的高效、准确检测提供借鉴。
