基于BERT的诉讼案件违法事实要素自动抽取
2021-04-29徐明月
崔 斌, 邹 蕾, 徐明月
(北京京航计算通讯研究所信息工程事业部, 北京 100074)
违法事实要素作为诉讼案件的关键要素之一,影响着对案件进行决策的效率。违法事实要素抽取可以协助高检人员从海量诉讼案件中快速有效提取出违法事实,以用于案情摘要、可解释性的类案推送以及相关知识推荐等司法领域的实际业务需求中,并可以为高检人员提供参考,以推动案件办理流程,加快处理速度。通常情况下,要素抽取问题[1-4]可以转化为文本分类[5-8]。
早期的研究工作大都采用基于统计规则的文本分类方法来进行相关要素抽取,如王亚坤等[9]提出一种级联模型并通过手动建立规则的方法对相关事实要素进行抽取;程良等[10]通过依存树与规则相结合的方法提取语句关键要素。该类方法可以有效提高抽取效果,但需要人为建立规则,使得抽取效果受人为因素影响较大。随着机器学习的发展,越来越多的学者开始将其用于要素的抽取过程,如Li等[11]提出一种基于马尔科夫逻辑网络方法并将其用于民事诉讼案件的决策中,该方法可以有效抽取出相关要素;文献[12]对事实要素进行扩充,比如添加了双方是否有不良习惯、庭外调解是否有效等,事实要素越全面,就更加符合实际情况。但是该类方法主要适用于训练语料规模较小且要素种类较少的情况。针对上述方法存在的高度依赖人工制订规则模板,只局限于少量数据的问题,很多学者提出将深度学习方法用于相关要素抽取工作中,如刘宗林等[13]提出一种基于双向长短时记忆(bi-long short term memory,Bi-LSTM)模型[14]对法条和罪名要素进行抽取,完成了司法领域的要素抽取工作,利用word2vec[15]得到词向量,采用Bi-LSTM循环网络模型进行深度编码,在对文本进行编码时考虑上下文信息,得到文本表示并抽取出法条和罪名要素。该类方法相比传统机器学习方法抽取效果有较大的提高。但是,此类方法采用word2vec模型得到的词向量是固定的,不能跟随上下文语境进行改变,所以不具备词义消歧能力,影响了最终的抽取效果。为了提高抽取效果,有学者提出了基于BERT的增强型(BiLSTM conditional random field,BiLSTM-CRF)模型[16],来对推文恶意软件名称进行抽取,相比基于word2vec的词向量编码方法,该方法借助双向编码器表示(bidirectional encoder representations from transformer, BERT)预训练模型[17],获得了具有语义消歧能力的增强型抽取模型,提高了抽取效果。然而,对诉讼案件违法事实要素抽取效果往往依赖相关领域内知识,BERT作为一种预训练模型,可以将丰富的领域知识输入到后续模型训练中用来提高抽取结果。
综合以上分析,针对诉讼案件违法事实要素抽取效果依赖领域内知识的问题,现提出一种基于BERT的诉讼案件违法事实要素抽取方法,通过领域内知识对BERT模型进行预训练可以将其融入到模型中,使得模型参数对诉讼案件数据变得更为拟合。同时,模型采用BERT来获得词向量,具备词义消歧能力,以期提高抽取效果。最后,采用循环卷积神经网络(BiLSTM convolutional neural networks, BiLSTM-CNN)[14,18]对文本进行编码并获取在文本分类任务中扮演关键角色的信息并完成违法事实要素抽取。
1 诉讼案件违法事实要素抽取模型构建
诉讼案件违法事实要素抽取模型结构如图1所示,主要包括BERT模型预训练模块、诉讼案件特征提取模块(包括BERT文本表示、BiLSTM-CNN特征提取)和模型输出模块三个部分组成。
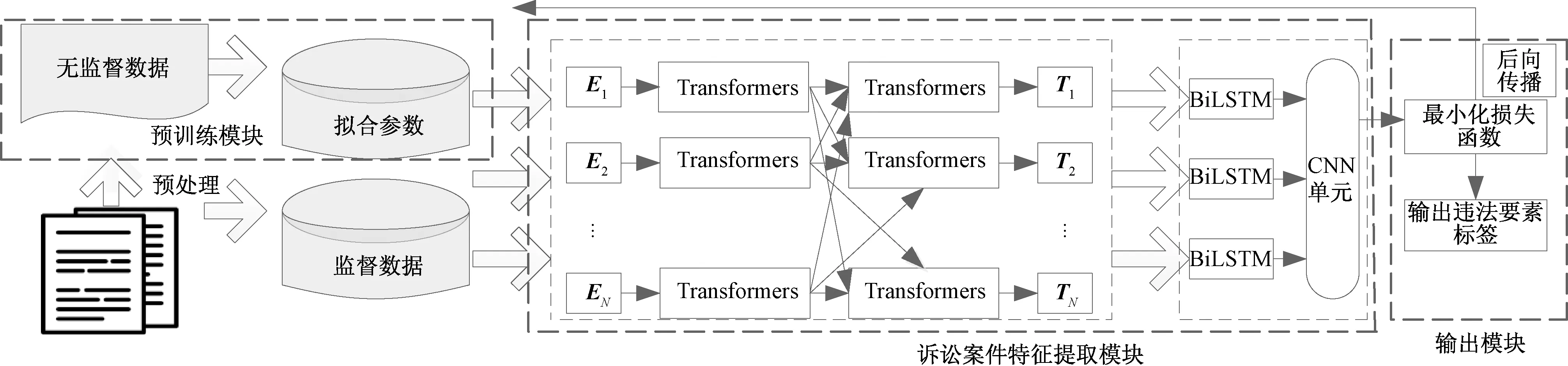
E1,E2,…,EN为监督数据的向量化表示;T1,T2,…,TN为经过BERT模型的输出
1.1 模型预训练
对于诉讼案件,采用领域内的无监督数据对BERT模型进行预训练。将原始诉讼案件数据经过分句处理,每一个句子作为预训练阶段的输入,经过掩码语言模型(mask language model,MLM)和下一句预测(next sentence prediction,NSP)任务预测[17],训练得出相关模型参数。其结构框图如图2所示。
图2中,输入的无监督数据用Z1,Z2,…,ZN表示,经过词嵌入向量化输出为I1,I2,…,IN[式(1)]。经过BERT预训练模型的输出为T1,T2,…,TN。
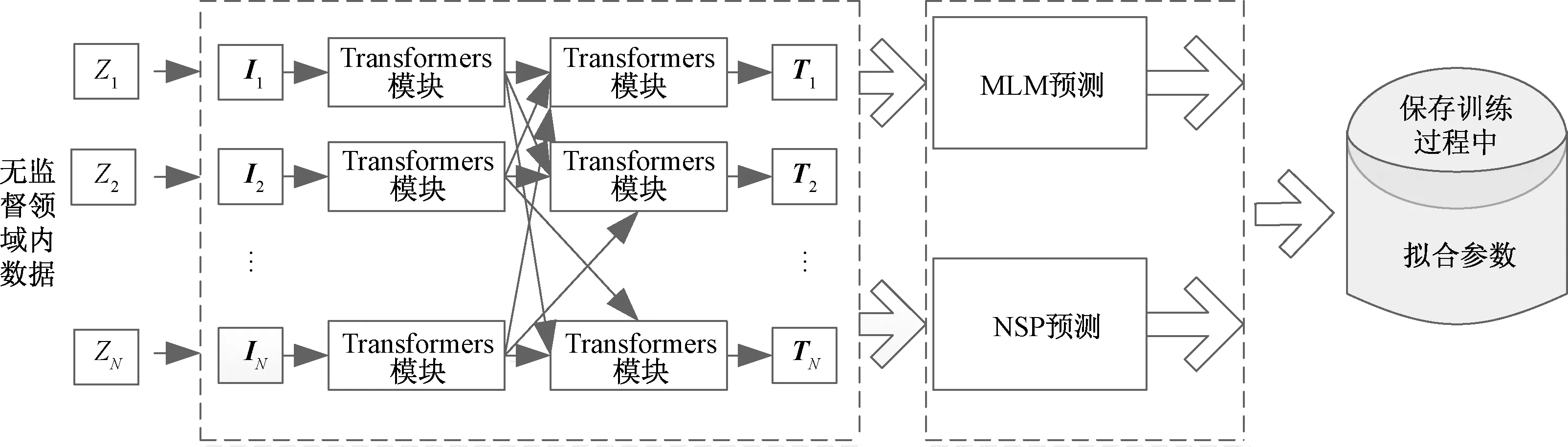
图2 经过MLM和NSP两个任务预测输出模型的参数Fig.2 The parameters of the output model predicted after MLM and NSP
BERT通过MLM任务进行预训练,即在一句话中掩蔽掉几个单词,然后通过上下文对掩蔽掉的单词进行预测。假设无监督领域内数据用Z1,Z2,…,ZN表示,经过向量化输出为I1,I2,…,IN[由式(1)得到]。这个嵌入过程包括三个部分:词嵌入Ke(token embeddings),分割信息嵌入Se(segment embeddings),位置信息的嵌入Pe(position embeddings)。词嵌入Ke是对输入的每一个字信息Ze(1≤e≤N)进行编码,分割信息嵌入Se是对分割信息Fe进行编码,位置信息嵌入Pe是对位置的信息We进行编码。对无监督数据的向量化表示过程如图3所示。
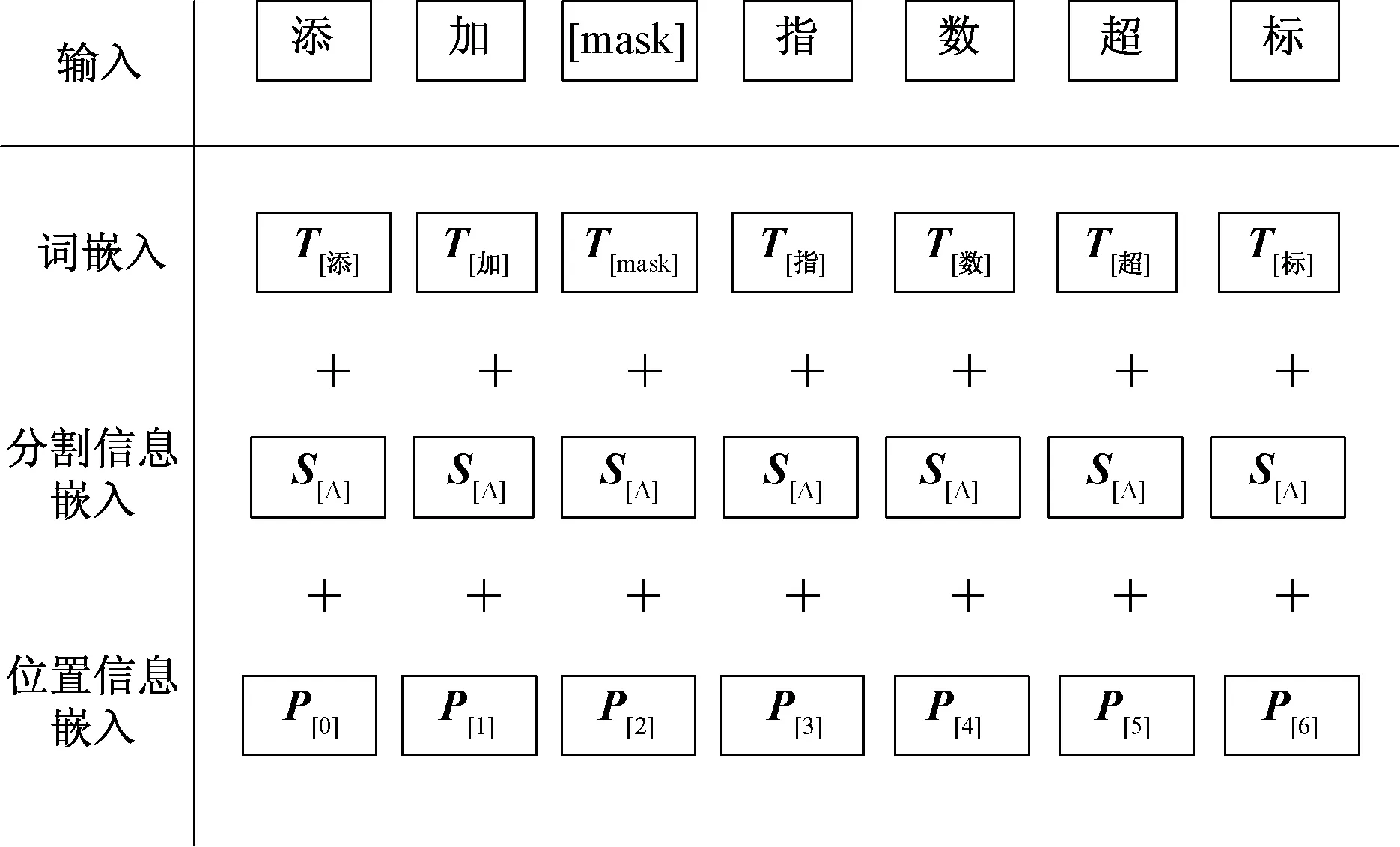
图3 无监督数据的向量化表示Fig.3 Vectorization representation of unsupervised data
由图3可得最终BERT编码器的输入信息Ie可表示为
Ie=Ke+Se+Pe
(1)
式(1)中:
Ke=Ze×W1
(2)
Se=Fe×W2
(3)
Pe=We×W3
(4)
式中:W1、W2、W3为可以训练的参数。
同理,BERT对监督数据的向量化表示为Ee,其原理与图3类似。
1.2 诉讼案件特征提取模块
诉讼案件特征提取模块包括BERT对训练过程中的监督数据进行文本表示和BiLSTM-CNN特征提取两部分构成。BERT主要采用多层多个Trm(transformer)模块对文本进行编码,对于每一个Trm,输入监督数据的嵌入信息Ee,由“多头注意力网络”和“前馈神经网络及正则化”两部分构成,Trm的结构如图4所示。
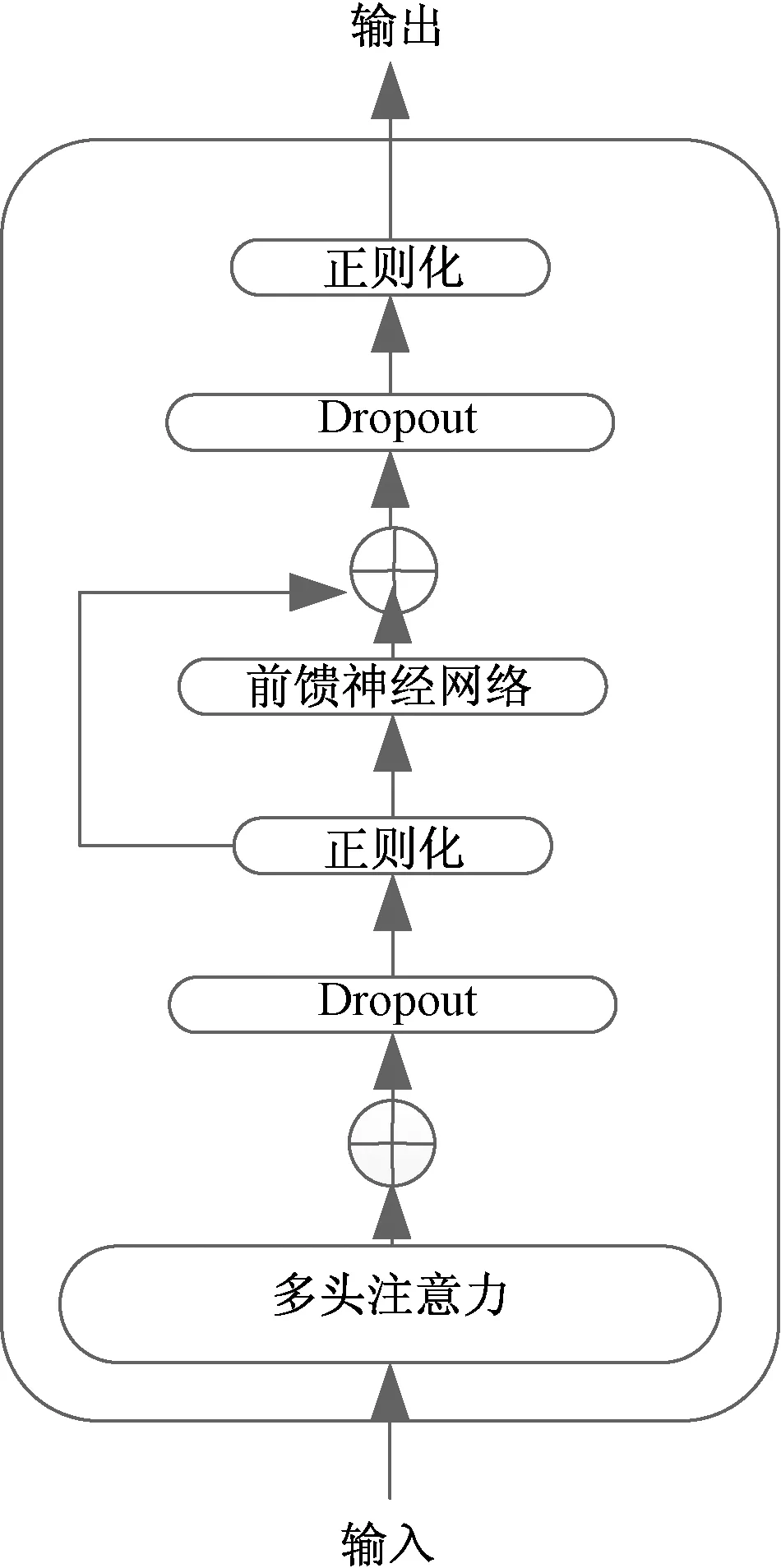
图4 Trm 结构图Fig.4 Structure of Trm
1.2.1 多头注意力网络
其中多头注意力网络是由多个“头”组成的网络,对于一个“头”,其结构图如图5所示,输出hi为
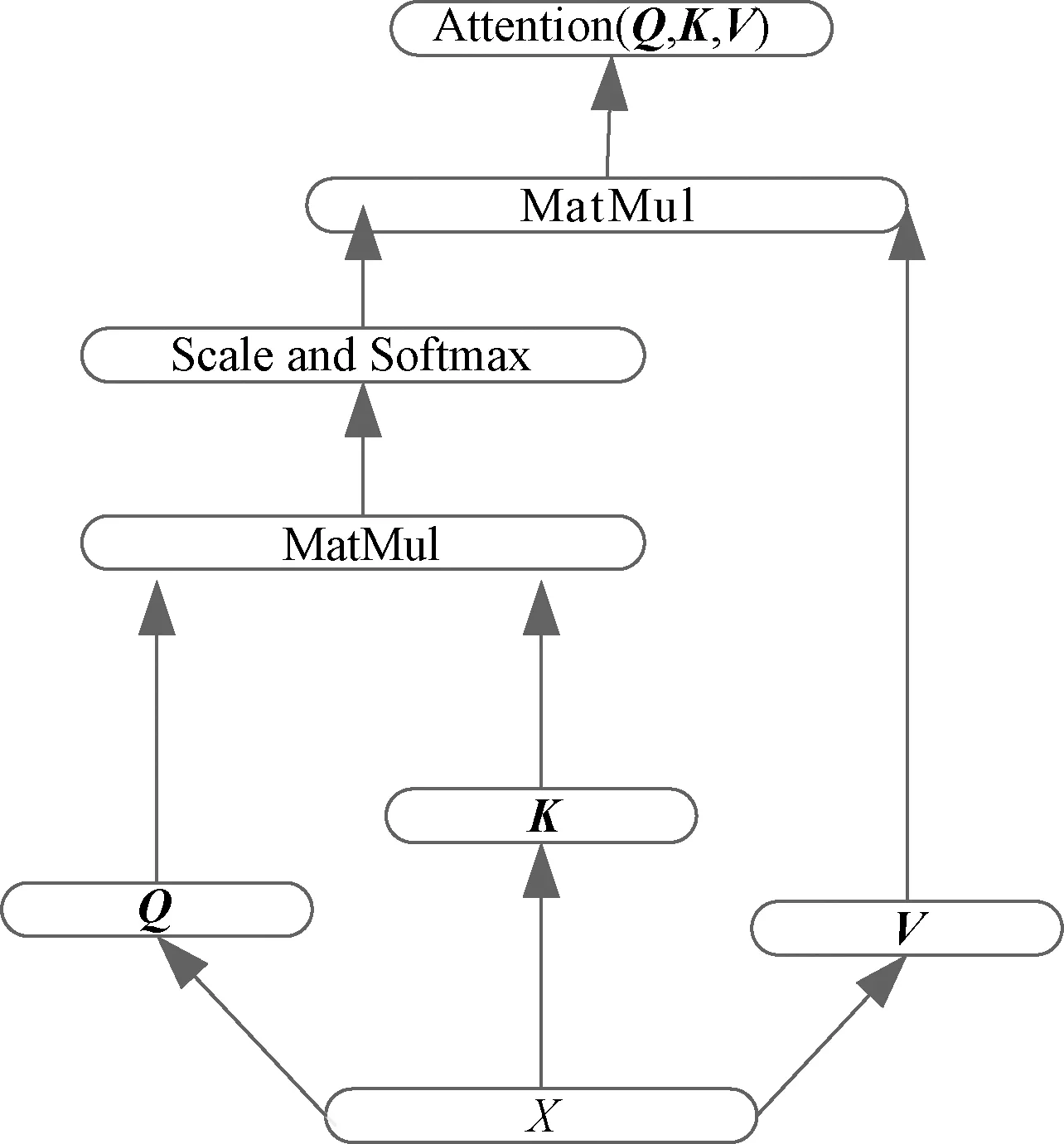
图5 单头注意力机制Fig.5 Single-headed attention mechanism
hi=attention(Qi,Ki,Vi)=
(5)
MultiHead(X)=Concat(h1,h2,…,hN)Wo
(6)
式(6)中:Wo为网络里可以训练的参数。
1.2.2 前馈神经网络及正则化
在多头注意力机制之后,文中采用前馈神经网络来防止网络中产生“退化”问题,由两层线性的ReLU函数构成,输出FFN(x)为
FFN(x1)=max(W4x1+b1,0)W5+b2
(7)
式(7)中:x1为公式中的MultiHead(X);W4、W5、b1、b2为网络中可以训练的参数。
对FFN(x)进行正则化操作,设输出h′f为
为考察该方法用于实际样品中Hg2+检测的性能,人体尿液为检测对象构建检测体系。实验采用加标法,向离心管中加入4 μL的本底尿液,然后加入不同浓度的汞离子溶液,反应溶液中的汞离子浓度分别为15 pmol/L、20 pmol/L、50 pmol/L。结果如表2所示,检测尿液样品的平均回收率为97.6%~103.7%之间,RSD在1.7%~3.1%之间;说明设计的传感器可用于尿液样本中的汞离子检测,具有较好的准确度。
h′f=LN[FFN(x1)]=LN[max(W4x1+b1,0)W5+b2]
(8)
式(8)中:LN(layer normalization)为正则化函数。
1.2.3 循环卷积神经网络
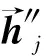
h″j=BiLSTM[h′f]
(9)
之后将其输入给CNN单元,提取关键信息kj为
kj=CNN(h″j)
(10)
1.3 输出模块
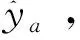
(11)
采用focal loss[19]作为模型的损失函数,表达式为
(12)
2 实验及结果分析
2.1 实验数据和评价指标
数据来自“裁判文书网”的公益诉讼类型数据,以公益诉讼案件中的食品安全案件为例,经过数据预处理,得到训练集869条数据,开发集192条数据,测试集208条数据。请法律专业博士生对数据集的要素标签进行标注,其中相关事实要素标签有20种。部分数据如表1所示。

表1 数据集举例Table 1 Example of data set
以精确率P、召回率R、F1和准确率A为评价指标。
(13)
(14)
(15)
(16)
式中:TP、FP、TN、FN分别为正类判定为正类、负类判定为正类、负类判定为负类、正类判定为负类。
2.2 实验环境和参数设置
实验采用python语言进行编程,采用基于tensorflow的框架实现模型架构,操作系统是Win10, 64位,处理器采用Nvidia 系列GPU 12 GB 显存。
输入数据集相关参数设置:训练集批次大小batch_size 32, 验证集和测试集batch_size 8,最大句子长度设为128。对于模型主要参数如表2所示。
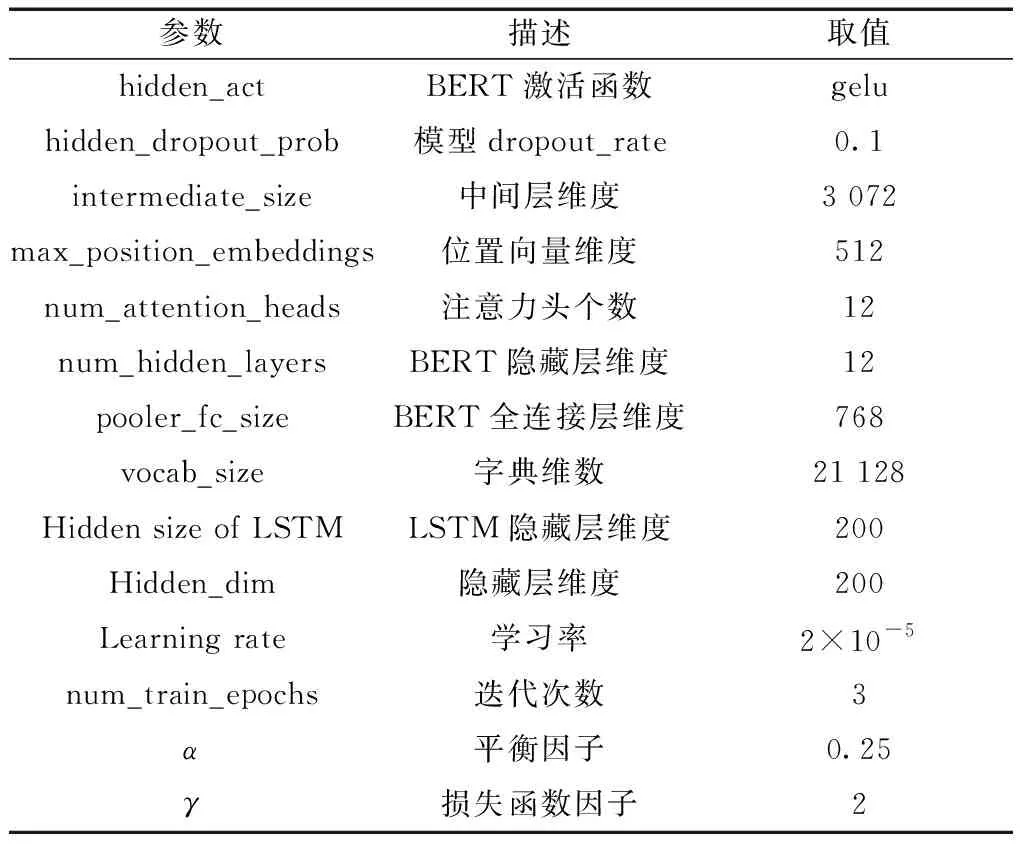
表2 相关参数设置Table 2 Related parameter setting
2.3 实验结果与分析
为了验证本文方法的有效性,实验中采用Text-CNN、BiLSTM、CNN-BiLSTM、法律判决预测模(LJP)[20]、BERT-FC进行实验。
2.3.1 各模型结果对比
表3是各种方法对比结果,从中可以得出两个结论。一是本文方法相比其他方法,无论是否经过预训练,在各指标上,取得了一致性的结果,均优于其他方法。本文方法相比表现最好的 (BERT fully-connect,BERT-FC)方法,未经过预训练和经过预训练,在F1指标上,分别提高了1.31%和1.27%,原因在于本文方法在用BERT得到向量文本表示后,又添加了BiLSTM-CNN对文本进一步进行编码并提取出对后续分类任务中具有影响力的关键词语,捕捉到了文本中的关键信息,以此信息作为分类依据,可以提高分类结果。本文方法和BERT-FC方法相比,其他基于词嵌入编码的方法(Text-CNN,BiLSTM,CNN-BiLSTM,LJP),在F1指标上也均有了较大的提高,说明基于BERT的编码方法,要优于基于词嵌入的编码方法,原因在于BERT在对字或者词进行编码时,考虑到了上下文的关系,可以解决“一词多义”问题,可以根据上下文情况不同,灵活对当前字或者词进行理解,这样得到的编码更符合现实,以此为依据得到的分类结果势必会提高,而基于词嵌入的编码方法,对词的理解是机械性的,没有考虑到上下文关系,一个词往往只赋予一个向量或者一个编码,不能解决“一词多义”问题。二是对各方法,经过预训练的模型较未经过预训练的模型,各指标均有所提高。比如,经过领域内预训练后,每种方法在F1指标上平均提高了2%,说明对模型进行领域内数据的预训练,可以提升分类任务结果。其中的一个原因可能是经过诉讼案件领域内数据的预训练,使得模型的参数与数据变得更为“拟合”,利用这种拟合后的参数再去对案件进行违法事实要素抽取(分类),分类结果得到提升。为了进一步说明本方法的有效性,对比了不同方法对违法事实要素抽取的准确率,结果如图6和图7所示,图6是各个方法经过预训练后抽取准确率,图7未经过预训练,对比图6和图7可以看出,对于每一种不同的方法,经过预训练后,均取得了更高的准确率,这也验证了预训练是可以提高抽取结果的。单独比较每一种方法,无论是否经过预训练,本文方法均取得了最高的准确率,分别达到98.80%和96.90%。

图6 经过预训练的各方法准确率对比Fig.6 Accuracy of each method after pre-training
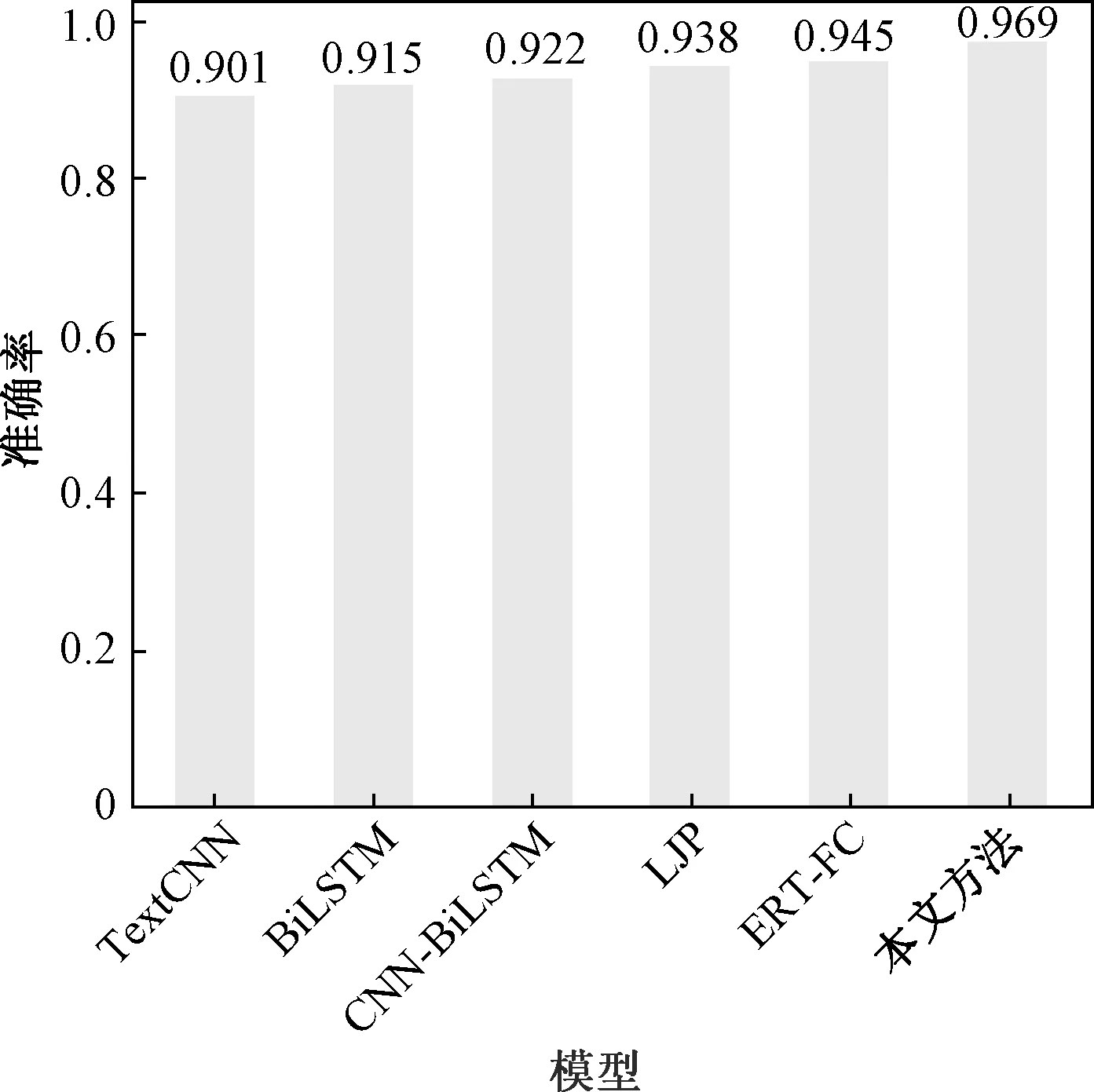
图7 没有经过预训练的各方法准确率对比Fig.7 Accuracy of each method without pre-training
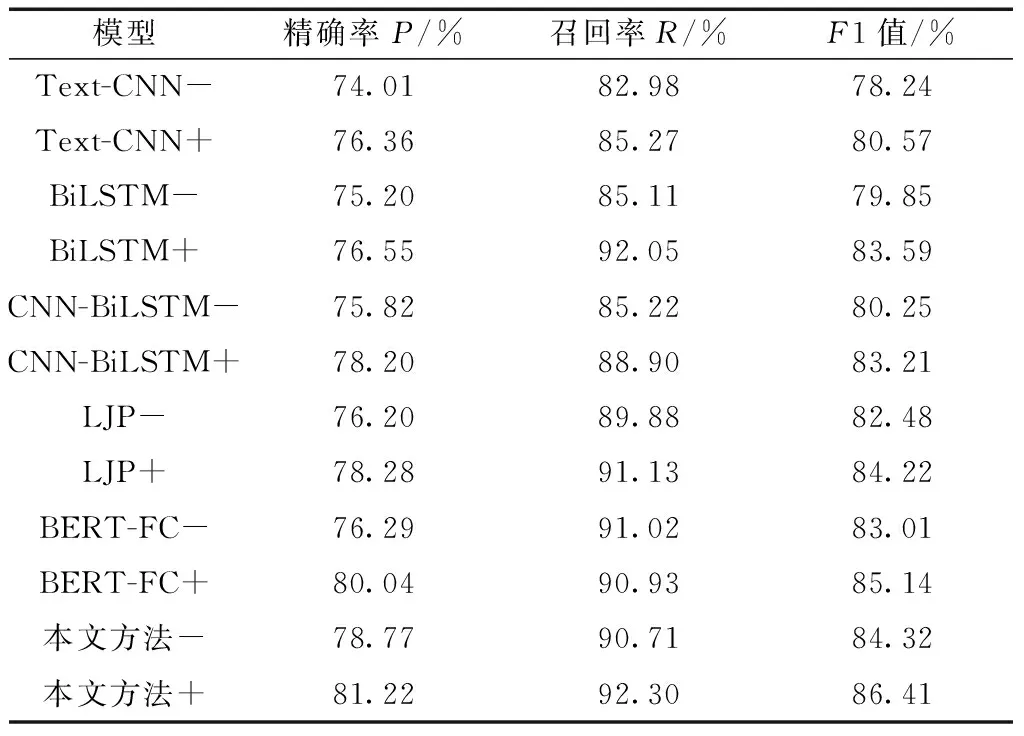
表3 各个模型的违法事实要素抽取结果Table 3 Extraction results of illegal fact elements of each model
2.3.2 focal 损失函数对比实验
实验目的是对比交叉熵损失函数和focal损失函数对最终分类结果的影响,分类结果如表4所示。
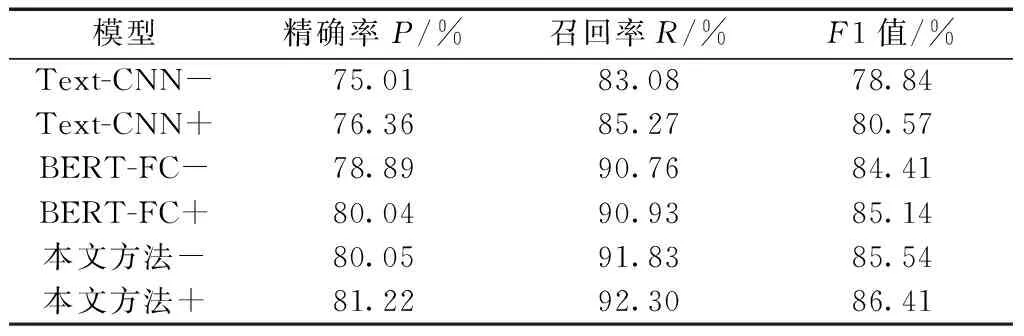
表4 不同损失函数结果对比Table 4 Comparison of results of different loss functions
从表4可以看出,对于不同编码方法,采用focal损失函数比交叉熵损失函数均取得了较高的分类结果,前者在F1值指标上,对于Text-CNN、BERTFC、本文方法平均提高了1%,这说明focal损失函数对于不同难度的类别均有了正确的分类,原因在于采用focal loss函数时,通过调整因子γ的取值减少易分类样本的权重,使得模型在训练时更专注于难分类的样本,从而减少了简单样本的影响。这说明focal损失函数可以处理诉讼案件存在的违法事实要素种类繁多,同时可能存在好几种,而且每一种要素对应的样本数量不一样,存在容易区分的和难以区分的类别等问题。
3 结论
基于BERT的诉讼案件违法事实抽取模型相比传统模型,抽取效果均有较大的提升。模型融入领域内无监督数据,能够使其参数更为“拟合”抽取过程的监督型数据,提高抽取效果。BERT对诉讼案件进行编码,可以解决特征提取中存在的“一词多义”问题。加入BiLSTM-CNN网络,能够抽取出与结果相关的关键信息,提高诉讼案件违法事实要素抽取的性能。对于各个模型经过预训练后,均取得了更高的准确率,说明预训练可以提高违法要素抽取的准确率。
