基于多重注意力机制的服装图像实例分割
2021-04-29徐莹珩钟跃崎
徐莹珩,钟跃崎,2
(1.东华大学 纺织学院,上海 201620; 2.东华大学 纺织面料技术教育部重点实验室,上海 201620)
近年来,随着服装设计行业的蓬勃发展,时装图像的视觉分析引起了越来越多的关注。 其中,服装图像的细粒度分割任务有助于统一服装属性的分类和细分。一方面,服装图像的精确细分可以更好地获得消费者的穿着偏好,从而更好地满足消费者的品味并提高时尚设计的针对性。 另一方面,消费者可以更好地了解服装信息以及不同服装部件之间的联系,增强购物体验。
自2012年AlexNet研究[1]以来,深度学习算法得到了快速发展。与传统的机器学习方法,如随机森林(Random Forest)、支持向量机(Support Vector Machine)和条件随机场(Conditional Random Field)相比,深度卷积神经网络(Deep Convolutional Neural Networks, DCNN)显示了强大的特征提取和表征能力。然而,此类图像分割方法,特别是基于全卷积网络(Fully Convolutional Networks, FCN)[2]的方法,虽然取得了很大进展,但是由于网络结构的固定,FCN无法充分理解空间上下文信息,使得最终使用上采样(Upsampling)将特征图还原到原始图像大小时,会导致像素定位不准确,分割效果不佳。
为了解决该问题,本文在经典的图像分割网络Mask-RCNN[3]的基础上,添加了一种双通路的非局部的注意力机制[4],可用于对时装图像进行细粒度的实例分割,将其称为MA-Mask-RCNN(Multi Attention Mask-RCNN)网络。
1 相关方法分析
1.1 分割网络
图像中每个像素点都与周围像素有一定的关联,大量像素间的互相联系定义了图像中的各种对象。上下文(context)特征就是一个像素及其周边像素间的某种联系。图像的实例分割,其实质是对图像中每个像素点进行分类。为了提高深度神经网络对图像的理解,提高网络获取上下文信息的能力,从而提高分割网络的分割能力,前人提出了许多方法。
第1种方法是DeeplabV2[5]和DeeplabV3[6]网络,包含由空洞卷积组成的空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)结构。该结构通过空洞卷积提高卷积核的感受野,可以获取不同尺度下的上下文信息。而在PSPNet[7]中,使用了金字塔池化结构(Pyramid Pooling Module,PPM),该结构可生成4个不同比例尺的特征图,之后再通过上采样和按位加法运算,获得包含足够上下文信息的特征图用于实例分割。与之类似的分割网络还有很多,包括Unet[8],RefineNet[9],DFN[10],SegNet[11],Deeplabv3+[12],SPGNet[13]等使用编码-解码结构(Encoding-Decoding)来恢复图像中的位置信息,同时保留高级语义特征,提升分割效果。而在GCN[14]中,则使用了图卷积和全局池化来获取全局上下文信息。
第2种方法是利用循环神经网络(Recurrent Neural Network, RNN)可以捕获长距离像素之间依存关系的特征,但是这种关联通常受到RNN的长期存储能力的限制,通常会消耗大量时间和算力。
1.2 注意力机制
注意力机制(attention mechanism)广泛用于机器翻译,场景识别和语义分割中。非局部注意力机制(non-local attention mechanism)将自我注意力(self-attention)机制作为子模块添加到机器视觉任务中,以进行视频分类,目标检测和实例分割。CCNet[15]、DANet[16]和HMANet[17]分别改进了非局部注意力机制,并设计了单通道、双通道和三通道的不同注意力模块,将其用于航空影像的全景分割。其中,CCNet提出了Criss-Cross模块,解决了注意力机制中参数量过大的问题。通过2个串行Criss-Cross模块组成循环十字串行注意力模块(Recurrent Criss-Cross Attention, RCCA),可获取全图的空间上下文信息。DANet使用了通道注意力模块和位置注意力模块并行的结构,可以学习到多种上下文信息。HMANet构造了一个复合网络结构。将类别的增强注意力模块(Class Augmented Attention,CAA)和区域改组注意力模块(Region Shuffle Attention,RSA)并行连接后,与输入的原始特征图组合起来,构成了混合多重注意力模块,从而实现多种上下文信息的融合。
注意力机制可以提升神经网络对图像的理解能力,有利于提取图像中的深度特征,提升服装图像细微部分的分割能力。但是目前的注意力机制更多的关注于如卫星云图、地形地势图等大型场景,对于服装图像而言,尚没有一种合适的网络可用于细粒度的分割。
2 网络设计
为了解决目前分割在服装细微部件上分割精度低的问题,本文在经典的图像分割网络Mask-RCNN[13]的基础上,添加了一种双通路的非局部的注意力机制[14],可用于对时装图像进行细粒度的实例分割,将其称为MA-Mask-RCNN(Multi Attention Mask-RCNN)网络。
首先将服装图像输入MA-Mask-RCNN,再通过骨干网络进行特征提取,之后通过多重注意力机制,训练神经网络去学习上下文信息,接着将所得特征图发送到区域生成网络(Region Proposal Network,RPN)中生成候选框,最后在原始图像的基础上进行实例分割。换言之,MA-Mask-RCNN分3个阶段完成图像的细粒度实例分割:
①将原始图像输入到特征提取骨干网络ResNet中进行特征提取,得到特征图X。
②将所提取的特征图发送到通道注意力和位置注意力2个网络分支中获取包含上下文信息的特征图,对该特征图中的像素按位相加,可获得具有上下文信息的特征图X′。同时,另一支路通过特征Mask-RCNN自带的金字塔模块(Feature Pyramid Networks,FPN),之后将2个支路得到的特征图按像素相加,得到包含多重上下文信息的注意力特征图X″。
③将得到的特征图X″输入Mask-RCNN网络的头部即可完成分类、回归和掩码操作。
3 MA-Mask-RCNN网络
3.1 网络架构设计
参考非局部注意力机制设计了一个细粒度的实例分割网络MA-Mask-RCNN,如图1所示。并行结构的注意力模块由上层位置注意力模块(Position Attention Module,PAM)和下层通道注意力模块(Channel Attention Module,CAM)构成。其中,PAM模块旨在从特征图中的提取基于类的相关性,而CAM模块则通过类通道的加权来改善特征重建的过程,以获得更好的上下文表达。特别地,在PAM模块中用CCNet中的Criss-Cross Attention模块代替了传统的非局部注意力模块,从而减少网络参数的数量,降低计算复杂性,同时从同一通道的不同位置中学习全局上下文信息。
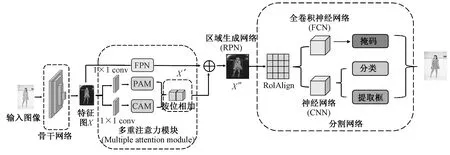
图1 MA-Mask-RCNN的结构
如图1所示,经过骨干网络提取的特征图X,输入PAM和CAM模块,分别得到包含位置、通道上下文信息的特征图D,并将其接位相加得到X′,同时将特征图X输入FPN模块中构成完整的多重注意力模块(Multiple Attention Module),并将这2个部分的输出按位相加,以获得充分学习了上下文信息的特征图X″,然后将该特征图送入RPN模块得到目标框的位置,最后输入FCN和CNN以输出最终的分割图。
3.2 骨干网络
本文选择ResNet101[18]作为特征提取的骨干网络。该网络可以通过残差连接结构提取大量有效特征,在具体实现时,还需为ResNet增加空洞卷积以提高卷积核的感受野。同时,作为特征提取器,删除了最后的全连接层。输出特征图X,其尺寸为原始图像的1/8。将X通过1×1卷积层后,送入双分支注意力模块。
3.3 双分支注意力模块
非局部注意力旨在给出空间某处的像素与空间中其余像素之间的联系:
(1)
式中:x为输入的任意位置像素点,y是输出,i表示当前位置的响应,j表示全局响应。xi是一个向量,其维度与x的通道数一致,而函数f(xi,xj)则是用于计算xi与xj之间的相似关系。函数g(xj)=Wgxj为一元映射,其中Wg是需要神经网络学习的权重矩阵,可以通过1×1的卷积实现,而式(1)中的C(x)则是归一化函数。
从式(1)可以看出,为了计算输出层的一个像素点,需要将输入图像的每个像素点都加以考虑。f(xi,xj)可选择使用高斯函数、嵌入式高斯函数、向量点积和串联函数等形式。在具体实现时,本文选择使用高斯函数来计算xi与xj之间的相似性:
f(xi,xj)=exiΤxj
(2)
3.3.1 通道注意力模块(CAM)
通道注意力模块的结构如图2所示,输入为特征图X。
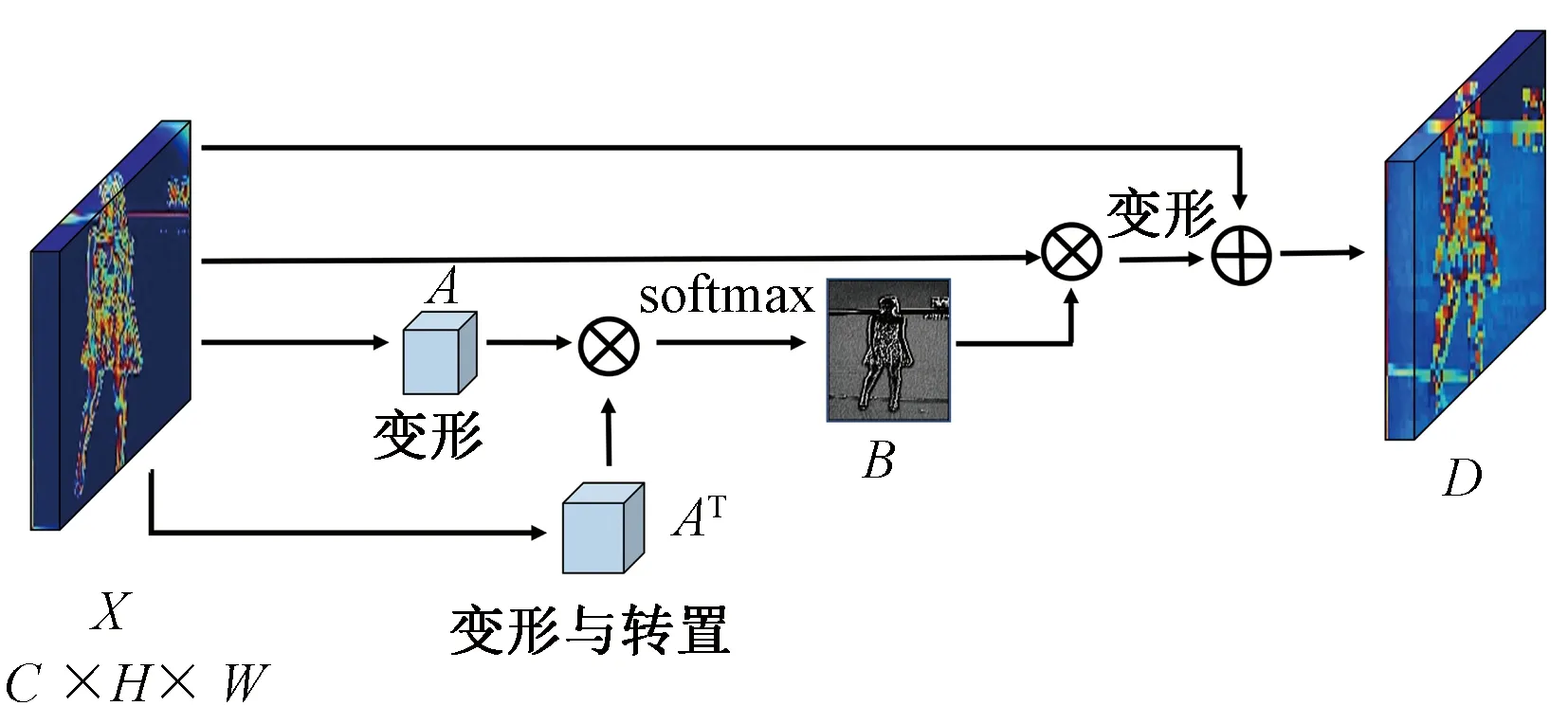
图2 通道注意力模块的结构
对输入CAM的特征图X∈C×H×W,通过变形(reshape)和转置,分别生成新的特征图A∈C×N和AΤ∈N×C,其中N=H×W,然后将A和AΤ经过乘法(⊗)运算为新的特征张量,送入Softmax层得到通道注意力特征图B∈C×C:
(3)
式中:Bij表示第i个通道对第j个通道的影响。为了将其还原至与X相同的维度,将B与X做矩阵乘法,并将其维度变形为C×H×W,最后再与X按位相加,得到D∈C×H×W:
(4)
式中:Xi和Xj分别为第i和第j个通道的特征图,β是一个可学习的参数(初始值为0)。由式(4)可知,每个通道的最终的特征是所有通道的特征与原始特征的加权和,这确定了不同通道特征图(Xi和Xj)之间的长距离相关性,有助于区别不同类别的特征。
3.3.2 位置注意力模块(PAM)
区分不同特征的重点是对场景的理解,捕获更多上下文信息尤为重要。然而,在传统的FCN中,当特征被提取和分类时,一些局部特征会导致错误的分类,从而影响分割效果。
PAM旨在利用整个图像中任意2个点之间的关联来增强其各自特征的表达,并利用非局部注意力模块使图像中的任一像素与图像中的其他像素建立远程依赖关系。这使得网络不仅可以学习局部特征,还可以捕获全局空间上下文信息。PAM的结构如图3所示。由骨架网络输出的特征图X,再通过3个1×1的卷积之后,输出Q∈C′×H×W,K∈C′×H×W,V∈C×H×W,其中C′ 图3 位置注意力模块的结构 给定Q上任意位置的像素u,可以得到向量Qu∈C′,由于Q与K均定义在H×W的区域上,因此在K中可以得到与u同一行或同一列的特征向量Ku∈(H+W-1)×C′。其中,特征向量Ku中的第i个元素为Ki,u∈C′,由此定义Affinity操作如下: (5) bi,u∈B建立了图3中十字区域内像素间的联系,其中i=[1,2,…,H+W-1]。 同理,对于V中任意位置的像素u,可以得到向量Vu∈C,以及V中与像素u位置同一行或同一列的特征向量φu∈(H+W-1)×C,与B做矩阵乘法运算,并将维度变形到C×H×W,再与X按位相加,最终输出D∈C×H×W: (6) 式中:Du是D∈C×H×W在u处的特征向量,Bi,u是在特征图B上i通道u处的标量。 经过一次PAM后,可学习到十字区域的上下文信息。而为了学习到全图的上下文信息,还需要再做一次PAM。这种设计在学习全图的上下文信息的同时,减少了网络的参数,减轻了算力的负担。 3.3.3 特征融合 为了充分利用长距离上下文信息,将CAM和PAM获得的特征图逐像素相加,以完成特征融合,得到特征图X′。为了将输出的X′与FPN提取的多尺度特征图P融合,对X′进行下采样操作,得到不同尺度的X′。如图4所示,从FPN提取的多尺度特征图P和注意力模块输出的特征图X′执行按位相加运算,得到特征图X″。 图4 FPN网络与注意力模块特征融合 如图4所示,将X″发送到感兴趣区域对其(Regions of Interest,ROI Align)以生成感兴趣区域,然后将其分为2支,分别发送到FCN以获取掩码(Mask)以及用于分类和回归的CNN中,从而完成分割,分类和回归。 实验中使用的是Kaggle竞赛中的Imaterialist-fashion(2019)[19]数据集,其中的数据来自于日常生活、名人活动和在线购物场景,共计50 000张服装图像,包含46种服装类别,其中每件服装至多包含19个服装部件(如衣领,袖口,口袋等)。为训练和验证MA-Mask-RCNN的性能,将其中40 000张用于训练集,10 000张用于测试集。 鉴于每张图像都包含多个重叠的类别目标,因此除了评估模型的预测框和掩码,还必须评估分类效果,故使用掩码的mAP(平均精度)值来评估MA-Mask-RCNN网络对服装图像的细分能力。 本文所有实验均在一台搭载Intel i7 8700f,3.7 GHz CPU,8 G内存,和一块显存为12 G的NVIDIA GeForce RTX 2080ti显卡的PC机上进行,并使用PyTorch深度学习框架验证算法的性能和计算效率。 训练时,使用在mmdetection框架下发布的预训练权重。为了防止过拟合,采用学习率衰减的方法,将初始学习率设置为0.002 5,并在完成第8次和第11个轮次(epoch)后,将此时学习率乘以0.8进行衰减。优化器采用动量梯度下降法(动量为0.9,将权重衰减系数为0.000 1)。同时,使用Inplace-ABNsync[20]代替ResNet网络中的Batch Norm层,以节省内存并避免在训练或验证数据时出现梯度爆炸。每5个轮次执行一次验证集验证,总共训练12个轮次。在完成训练之后,在测试集上测试网络的相关性能表现。 使用MS-RCNN[21]和Hybird Cascade Mask RCNN(HTC)[22]作为对照,并选择Mask-RCNN作为基线网络。 4.4.1 对照实验 本文提出的MA-Mask-RCNN消融实验结果如表1所示。 表1 在验证集上的消融实验 由表1可以看出,仅添加位置注意模块,Mask RCNN的性能已有一定程度的提高,其mAP增加了约2%。仅添加通道注意力模块时,其可以将Mask RCNN的mAP提高0.8%。与Mask RCNN相比,已取得了进步。此外,将2个注意力模块整合在一起后,网络性能将进一步提高2.2%。此外,实验还比较了基于Mask RCNN的其他改进网络的分割性能。表2比较了Mask RCNN,MS-RCNN和HTC的分割效果。可以看到,添加注意力机制后,mAP增加了2.2%,这与MSR-CNN分割性能相近。暗示级联结构的网络性能可能比直接串行连接的网络更好,原因可能在于直接串行连接时,该注意力范围所指示的区域,并不利于类别信息的提取。 表2 与现有方法的对照实验 由表2可以清楚地看到,添加注意力模块后,MA-Mask-RCNN网络与基线网络相比,APm的结果增加了2%,与MS-RCNN的分割能力相似。此外, HTC网络获得了最高的APm,这表明选择骨干网络和网络的级联结构确实可以增强网络的学习能力和分割能力。 4.4.2 实验可视化 图5~9展示了MA-Mask-RCNN和基线网络之间所进行的定性比较。图中(a)~(c)分别为原始图像、基线网络分割结果和本文提出的MA-Mask-RCNN实例分割的结果,并使用红色的虚线框来标记难以分类的衣服边缘,如衣服的边缘或袖口等位置。 图5 服装衣领细粒度分割效果对比 图6 服装轮廓细粒度分割效果对比 图7 细小服装部件细粒度分割效果对比1 图8 细小服装部件细粒度分割效果对比2 图9 服装边缘细粒度分割效果对比 很显然,红色矩形框选中了衣领、褶皱、帽子、鞋子等难以分割的细微服装部件。本文提出的MA-Mask-RCNN网络完美地还原了细分的细节,而基线网络在细分某些细微零件时存在很大缺陷。这说明MA-Mask-RCNN可以更准确地预测分割图,获取更精细的边界信息并保持对象连续性,证明了学习上下文信息有助于服装边缘的分割。 针对服装图像的密集预测和实例分割的任务,本文提出了一种新颖的基于注意力的框架,即多重注意Mask-RCNN(MA-Mask-RCNN),该框架可以从空间和通道的尺度捕获全局的上下文信息。实验结果表明,基于MA-Mask-RCNN的模型在服装分割任务中取得了良好的效果,并优于目前使用最多的Mask-RCNN网络。 未来还可针对以下2点进行优化:①对于改进的MA-Mask-RCNN,可以借鉴MS-RCNN,对Mask分支添加评分机制,分别获得Mask的得分,以提高网络掩码的训练效果,加速收敛并获得更好的分割效果。②可以使用级联连接代替直接连接,网络的分割效果可能会提升。

4 实验部分
4.1 数据集
4.2 测试指标
4.3 实验细节
4.4 Imaterialist数据集上的实验







5 结论与展望
