基于GMM的导游服务语音评分算法研究
2021-04-28杨雪祎
杨雪祎

摘 要:随着时代的快速发展,有关带有对情感分辨的语音识别马上就将进入人们的视线。现在已经有了对情感分辨的初级应用,比如微信的语音会通过特殊词以及说话人的语气在翻译中给出小表情。本文浅写了带有情感的语音识别以及对于语音评分给出的不同思路。
关键词:语音评分;语音识别;情感分辨
现今,随着我国旅游产业发展越来越快,导游行业出现人才供应不足的现状,在这样的大环境下,出现一款有关情绪,有关讲解的评分的语音评分系统是势在必行的趋势。
语音情感识别是指计算机可以自动识别语音信号的情感状态。语音作为人类的主要交流媒介之一,不仅承载了语义信息,还包含了说话者的情感信息。让机器感知人类的情感,将有助于在人机交互中进行更自然的、更和谐的对话。语音情感识别在人机交互中的重要作用,目前已经成为模式识别、多媒体信息处理和人工智能等领域的研究热点。赋予机器识别语音情感的能力,可以进一步提高语音识别和说话人识别的性能,是实现自然人机交互的关键。
1 语音识别
在相同的情感语言信息中共享相似的聲学特征,也涉及不同说话人的个体风格。因此,成熟的语言情感识别系统具有良好的泛化性能,需要训练才能获得鲁棒的语义特征。情绪的出现不是瞬间的,而是通过暂时的积累来表现的。因此,如何从时间维度思考情感的发展是语言情感识别的一个重要突破。在以往的许多操作中,基于帧级音频特征提出了不同的处理方法,希望能够捕捉到连续帧特征中包含的时序信息,并学习情感上相关的语义特征。该方法不局限于均衡、最大库、卷积神经网络、循环神经网络和长度记忆单元。
情感特征提取作为语音情感识别的重要组成部分,引起了众多研究者的广泛关注。这些研究大多致力于设计一些最具特色的手工特征进行情感识别。更具体地说,特征提取包括两个阶段。首先,从每一帧语音信号中提取一些声学特征,通常包括韵律学特征、基于谱的相关特征、声音质量特征和非线性特征等,还有一些通过改变算法提取的情感特征。然后,将不同的统计函数(均值、最大值、方差等)应用于每个话语的声学特征得到统计特征。通过大量精心准备的实验,寻找表现出与情感高度相关的特征,这是一项耗时耗力的工作。此外,所选特征的有效性在很大程度上仍然依赖于所实现的模式识别模型,导致其通用性较低。
2 语音评分准则
2.1 完整性
对于这个方面,最重要的是开始的语言和结束的语言,以及是否能将景物,景点的重要点都讲出来。
2.2 流利性
上下的连贯,整体的流利性作为评分的重点一环。停顿是衡量语言流畅性的一个重要指标。1)在适当的词汇量中,语义组之间的间隔适当的长度;2)连续词汇量之间不应停止。仅仅通过话语的流动性来衡量句子的流畅性是远远不够的。该方法的目的是通过计算句子的表达流来获得句子流畅性模型。判断句子流利程度的方法也适用于句子的等级划分。
2.3 发音正确性
发音的正确性的权重比较低,由于导游的证书里会对普通话有所要求,一般不会有很多的发音不正确,所以它的比重相对较小。但是,要求导游尽量降低俚语的使用程度。俚语的使用情况会酌情扣分。即用SER和WER作为识别和评分的重要部分。
2.4 韵律性及情感性
这个方面会作为比重很大的一个方面,由于导游的职业性质、韵律性和情感性一定是吸引游客的重要方面,所以这一定是评分重点,这方面的评分我在前面语音识别的位置有提及,主要还是以大环境为基本基调,再加上语音语调等多种情感辨别的路线,大体得到导游在测试中得到的情感基调,再加上语言的韵律性,给出权重的成绩。
3 语音评分算法研究
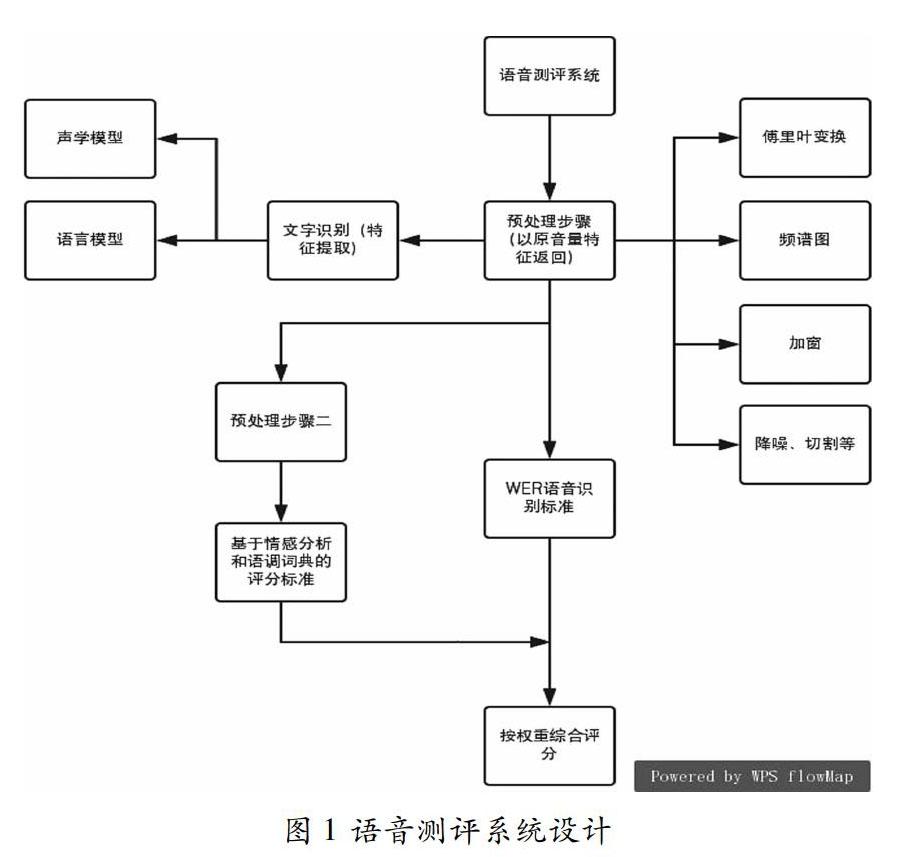
3.1 语音测评系统设计
首先用傅里叶变换、频谱图、加窗、降噪、切割等预处理步骤,然后利用声学模型和语言模型的文字识别,接着用WER语音识别标准以及基于情感分析和语调词典的评分标准的预处理,处理完之后将结果和大数据对接,得出尽可能精准的评判。接着再进行情感分析和句词词典的评分标准,最后得出权重得分,具体设计如图1所示。
3.2 语音评测系统架构
综合语音评测系统包括需求分析和现有的语音识别技术三个部分,综合语音评价系统的体系结构:标准模板库的建立、用户语音预处理和特征提取、模态匹配。
(1)标准模板库的构建是基于阅读评价系统的用户特点,儿童发音与成人发音差异较大,需要寻找更符合阅读标准的阅读声音,并进行预处理和特征提取,构建标准模板库。(2)用户的预处理和特征提取由用户的阅读语音输入和存储,并提取预处理和语音特征。(3)在模式匹配中,模式匹配与对应标准模板库的语音特征进行匹配,并度量相似度。
3.3 语音特性分析
语言是信息交流的工具,语言是话语的组合体。时域阈值是周期性的。在频域中存在共振峰结构。大部分能量集中在低频段。它在频域和时域上具有明显的负序特性,类似于白噪声。人类语言系统的生理结构变化率有限,第一次(10~30ms)的变化率,声带通道的形状和相对稳定性,由于相同的恒定功能,短期的音频音乐分析和相对稳定的短期wea。通过声音,常数的频谱可以增强。音频信号稳定,但不慢且稳定,适合短时处理技术。语音信号参数的区域特征、短时能量、短时能量和短时能量比均为零。时域分析,计算简单,计算量小,物理意义明确。时域特征提取方法简单,但不能压缩维数,不能用来征服分数表。应用于傅里叶变换和短时区域的短期频率分析。短时间内的频谱称为“对应频谱”。频域参数对语音识别系统的识别效果更好。该谱从频域特征参数、频谱包络、逆共振峰值因子得分等不同方面反映了振幅分数的特性。
3.4 关键字词评分
通过关键的字词,为了让识别出来的字词序列和标准的字词序列之间保持相同,需要进行词句的替换,删除,或者插入。这些替换,删除,插入的字词的总个数,除以标准的词序列中词的个数的百分比,即为WER,其计算公式如下所示:
需要注意的是,因为有插入词,所以WER有可能大于100%。需要注意的是,由于括号,我们WER可能大于100%。
在语音识别中,除了WER外,还有一个非常重要的句子识别错误率指标,即SER。SER可以理解为一个句子中有一个非常重要的单词识别错误是不可替代的,那么这个句子就被认为是一个识别错误,即句子识别错误数除以句子总数就是SER。
3.5 语音情绪识别分类算法
(1)高斯混合模型GMM。作为音频信号的一个基本特征,语音特征向量经过特征提取后,实际上是一个概率密度函数,该特征向量可以看作是一个状态数连续分布的隐马尔可夫模型。相应的高斯混合模型可以看作是一个状态下的大量概率密度函数。同时,每种语音情感产生的概率密度分布具有模型和参数相对稳定等相对简单的优点,能够体现声学的基本特征。高斯混合模型比马尔可夫模型更有效。
(2)使用GMM识别流程。①提取语音情感数据的特征;②聚类方法可以是常用的聚类方法,如k-means、AP聚类等;③同时计算高斯分布函数的均值、协方差矩阵和概率值,得到训练模板用于训练各种语音情感;④将每个语音情感测试数据输入到训练模板中,得到语音属于每种情感的后验概率。后验概率最大的训练模板是语音情感数据的输出结果。
最后用一个sum加和语句得到最后的成绩,用户在通过这个成绩,以及每个板块得到的分数,除每个板块的总分,得要一个相对应的比值分,在通过这个比值分得知自己哪方面的不足,进而去提升练习。
4 结语
在导游服务系统中,机器不仅要有听懂人的声音的能力,而且要有識别说话人情绪的能力。提出了一种改进的基于高斯混合模型(GMM)的序列分类与识别方法,并将该方法引入到语音情感识别的研究中。该方法有效地提高了语音情感识别的准确率,改善了导游服务语音系统。
参考文献:
[1]刘庆升,魏思,胡郁.基于语言学知识的发音质量评价算法改进[J].中文信息学报,2017,21(4):92-96.
[2]张茹,韩纪庆.一种基于音素模型感知度的发音质量评价方法[J].声学学报,2015(2):201-207.
[3]严可,魏思,戴礼荣.针对发音质量评测的声学模型优化算法[J].中文信息学报,2016,27(1):98-108.
[4]于俊婷,刘伍颖,易绵竹,李雪,李娜.国内语音识别研究综述[J].计算机光盘软件与应用,2015,17(10):76-78.
[5]李超雷.交互式语言学习系统中的发音质量客观评价方法研究[D].中国科学院研究生院(电子学研究所),2017.
[6]Martin R.Spectral Subtraction Based on Minimum Statistics[J].in Proc.Eur.Signal Processing Conf,2014,6(11):1182-1185.
