能量最优下的铱星时序信号分析预测
2021-04-25叶宁祁王凤军丁军航原明亭
叶宁祁,官 晟,王凤军,丁军航*,原明亭
(1.青岛大学 自动化学院,山东 青岛 266071;2.自然资源部第一海洋研究所,山东 青岛 266061;3.自然资源部海洋环境科学与数值模拟重点实验室,山东 青岛 266061;4.山东省海洋环境科学与数值模拟重点实验室,山东 青岛 266061;5.青岛海洋科学与技术试点国家实验室 区域海洋动力学与数值模拟功能实验室,山东 青岛 266237)
铱星通信终端由于其全球覆盖的特性,广泛应用于海洋科学研究与野外军事作业[1-3]。由于作业环境的特殊性,铱星通信终端一般需要在自备能源的条件下进行长期不间断工作,故对能量的使用效率需求较高。另一方面,铱星信号的可靠性会直接影响铱星通信终端的通信性能。
铱星是早期发展起来的通信卫星,已有众多学者对铱星的通信信道[4]、信息传输速率[5]、机会信号定位[6]等做了多方面研究,但是由铱星通信终端所处环境造成的信号干扰研究较少。海洋环境下的铱星信号质量干扰因素包括电离层干扰、雨衰、雪衰、日凌和星蚀,所以铱星信号质量数据具有高度的复杂性及随机性[7]。传统铱星信号监测方式是通过测取全天环境信号以判别干扰存在的时期,避免在干扰期向用户端发送数据包。这种方法具有时效慢与能耗大的缺点,而采用分类预测方法可以很好地解决这两类缺点。分类预测方法主要分为传统统计学方法、机器学习和深度学习方法三类。传统统计学方法采用线性拟合预测趋势,此类方法通常无法描述变量的随机性和非线性关系;而深度学习方法用于数据样本量较大的情况,模型收敛速度慢,网络调参复杂,容易陷入局部特征的极小化[8]。机器学习算法的代表XGBoost既可用于铱星时序数据的回归预测,也可用于分类预测,且模型参数少,收敛及预测速度快,对于实时性的铱星信号数据预测具有较高的适用性。
综上所述,文中提出利用滑动窗口算法对信号质量做移动平均整体评估。根据信号质量的评估特性对数据做不同处理,之后采用两种模型评价指标,对模型效果进行评价。0至5共6个类别同时看做是连续值,将信号质量大于等于4判别为优质信号,信号质量小于4判别为干扰,先使用XGBoost模型回归预测,计算预测值和真实值之间的平均绝对值误差(Mean Absolute Error,MAE)作为预测偏差的参考。然后使用综合分类模型评价指标接收者操作特征曲线(Receiver Operating Characteristic curve,ROC)和混淆矩阵来衡量模型效果,计算预测模型的准确率、精准率和召回率。基于以上研究结果给出合理的信号采集预测及数据发送控制方案,实现铱星通信终端的高效能量利用率。
1 铱星信号质量采集系统及数据获取
为了能够对铱星信号质量进行分析,首先使用铱星监测平台,通过高增益天线来采集铱星信号质量数据。然后编写铱星通信上位机程序,对铱星信号数据进行接收及存储。铱星监测平台是基于铱星9602模块设计的。
1.1 铱星信号质量采集系统
9602模块具有数据传输、定位跟踪等功能,波特率为19 200 bps。默认9线制串行接口,但只使用传输、接收、接地三线,用户输入AT指令以获取模块接收到的数据[9]。
使用Labview编写上位机程序, Labview作为模块化编程语言,编程效率高,其编程主要分为前控制面板编程和主程序面板编程。主程序面板中主要分为以下几个模块:串口配置模块、指令发送模块、数据采集模块、数据存储模块和图表显示模块。上位机程序框图如图1所示。

图1 数据监测上位机框图
1.2 铱星信号质量数据获取实验
在任何开放环境下,周围不同地貌地物形成各自独特的通信环境,对铱星信号收发造成不同形式的干扰,故需要选择不同测量环境。通过实验研究共选样两处实验环境,一处在城市楼顶宽阔地带,周围有高层建筑遮挡,另一处在周围遮挡物较少的海港船舶上。
安装铱星信号监测平台,启动上位机系统,配置串口,波特率设置为19 200 bit/s。通过指令A1启动铱星模块,发送指令C2给信号处理板采集数据。由于指令发送及信号采集的延时性,故最短采集间隔为30 s采集1次,共连续采集3 d。
按照同样的方式在不同实验环境下分别进行监测。其中采集生成的数据传输给数据存储模块的同时通过图表显示,以便在分析数据前能直观观测出数据整体情况,防止出现大规模数据丢失。
2 铱星信号质量数据分析算法
采集得到的铱星信号质量分为6个类别,分别为0至5,0表示信号质量最弱,5表示信号最强。其中4和5可作为数据收发的优良信号质量,数据流形式为时间序列数据流[10]。目前对时间序列数据分析的算法有很多。经实验数据特性研究对两处环境下采集的信号做移动平均,之后将信号的类别由六类转换为两类,并通过XGBoost的分类预测功能对信号干扰进行预测。
2.1 滑动窗口算法
滑动窗口算法原理如图2所示。算法根据指定时间单位长度框住时间序列,在时间序列上做单位平移,并在每次平移前对当前所框住的时间序列对应的值做计算。计算的指标为均值,由于数据采集间隔为30 s,窗口过大,观察信号质量值容易错过数值分布规律,而窗口过小则样本量较大,不易于直观遍览,故选择窗口大小为5min数据,步长为1。对于大数据而言,遍览整个数据的时间耗费巨大,而滑动窗口算法可以很好地解决这类问题。

图2 滑动窗口算法原理图
2.2 XGBoost分类预测算法
XGBoost是基于梯度提升决策树(Gradient Boosting Decision Tree,GBDT)改进得出的算法,于2016年提出后便受到了广泛关注。其核心思想从决策树中演变而来。相比于其它预测算法,XGBoost采用多线程并行处理,对于线性以及非线性数据都有很好的处理效果[11]。
决策树生成的每个分类树是独立的,而XGBoost是生成多个弱预测模型,将多个预测结果累积得到强预测模型[12]。即:

2.2.1 高集成度 相对于GBDT来说,XGBoost对损失函数一阶展开的基础上进行二阶展开,并加入代价函数Ω(ft)的正则化。当树的深度过高时设置max_depth停止建设决策树,防止过拟合现象,相比于其它模型具有高集成度[13],降低了模型的变化幅度。
2.2.2 内置缺失值处理 XGBoost内置缺失值处理,可在不同结点遇到缺失值时采用不同的处理方法,不用手工添加弥补缺失值,在模型处理上大大简化了工作量。
2.2.3 最优迭代次数 XGBoost允许boosting迭代中使用交叉验证,因此,可以方便地获取到最优迭代次数。
2.3 预测模型评估指标MAE
预测模型评估指标MAE的表达式为:

式中:为预测结果;yi为真实结果。当预测值越接近真实值,则MAE越小,预测模型质量越好。反之当误差越大,MAE越大,预测模型质量也就越差。使用平均误差绝对值计算偏差作为预测模型参考。
2.4 预测模型评价指标
如表1所示利用混淆矩阵达到预测结果的可视化效果,通过混淆矩阵计算得出ROC曲线。并计算综合预测指标,对模型进行综合评估。

表1 二分类混淆矩阵

ROC曲线的纵轴:真阳性率(True Positive Rate);ROC曲线的横轴:假阳性率(False Positive Rate)。ROC左下角覆盖面积AUC代表模型分类准确性,当AUC>0.5的情况下越接近于1表示分类准确性越高。
3 实验数据分析及预测模型评估
3.1 信号质量初步评估
使用时间序列滑动窗口算法对采集得到的两组数据进行分析,绘制得到两组数据的信号质量评估图。信号质量评估图如图3所示。

图3 原始信号质量滑动平均图
图3中,第一组数据在城市楼顶环境测量得到,第二组数据在海港环境测量得到。根据第一组信号质量评估图可得,其信号质量长时间处于4以下,干扰较多,信号质量恶劣。第二组信号质量评估图信号良好,局部出现干扰。
3.2 数据预处理
通过两处环境信号质量的评估可以发现,不同环境下信号干扰因素不同,由此可得出在不同环境下建立不同预测分类器的重要性。将楼顶环境数据放在工作簿1中作为第一组训练样本,取数据列最后200个数据样本作为测试样本。海港环境数据放在工作簿2中作为第二组训练样本,测试数据样本取样方式同上。再将楼顶数据和海港数据合并放在工作簿3中作为第三组训练样本,测试数据样本取样方式同上。分别通过3组数据对训练模型进行参数调优。
两地测量数据中含有大于5及字母类异常值,为了不影响模型预测的准确率,需将异常值剔除。另外,4~5作为优良信号类,4以下作为劣质信号类,将六类别信号转化为二类别信号,构建二分类预测模型。
3.3 模型参数调优
通过实验验证,max_depth和learning_rate两个参数对模型预测效果影响较大,所以本研究主要针对这两个参数进行调优。
3.3.1 参数max_depth调优 参数max_depth为树的最大深度,系统默认值为6,典型值为3~10。max_depth的主要功能用于控制过拟合,max_depth值越大,模型更注重于局部样本,学习更具体。为了选择最优参数,将参数取值范围选为3~13,并分别训练及测试观察ACC和AUC的变化。
如图4所示,max_depth逐渐增大,模型预测效果逐步提升,当到达一定深度时,预测效果开始下滑。

图4 max_depth参数调优
3.3.2 参数 learning_rate 调优 参数 learning_rate 为学习率,系统默认值为0.3,典型值为0.01~0.2。其功能主要用于减少每一步分类的权重,提高模型预测的鲁棒性。同参数max_depth调优方法一样取值范围选为0.01~0.2,观察ACC和AUC的变化。
如图5所示,当learning_rate值慢慢增大时,模型预测效果有一定提升,到达峰值后逐步下滑。依据以上研究,得出不同数据模型的最优参数表,如表2所示。

图5 learning_rate参数调优
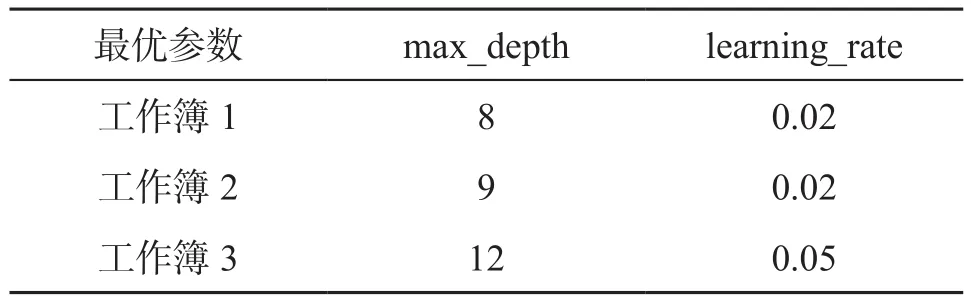
表2 训练模型最优参数表
3.4 最优参数下预测结果评估
三组数据的ROC曲线图如图6所示。工作簿1中MAE为1.2,混淆矩阵为[[24 25][12 139]],AUC面积为0.77,预测分类精确度高但是平均误差相对较大。工作簿2中MAE为0.76,混淆矩阵为[[140 12][36 12]],AUC面积为0.74,预测分类精确度相对较低,但是平均误差小。工作簿3中MAE为0.82,混淆矩阵为[[131 21][25 23]],AUC面积为0.78。由于训练数据类别均衡,综合预测分类效果较为均衡,综合预测评价表如表3所示。
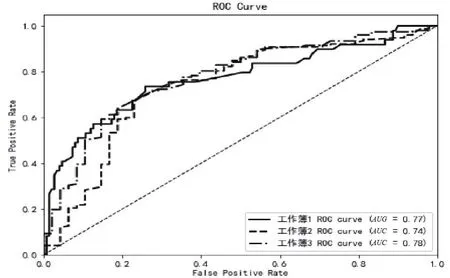
图6 ROC曲线图
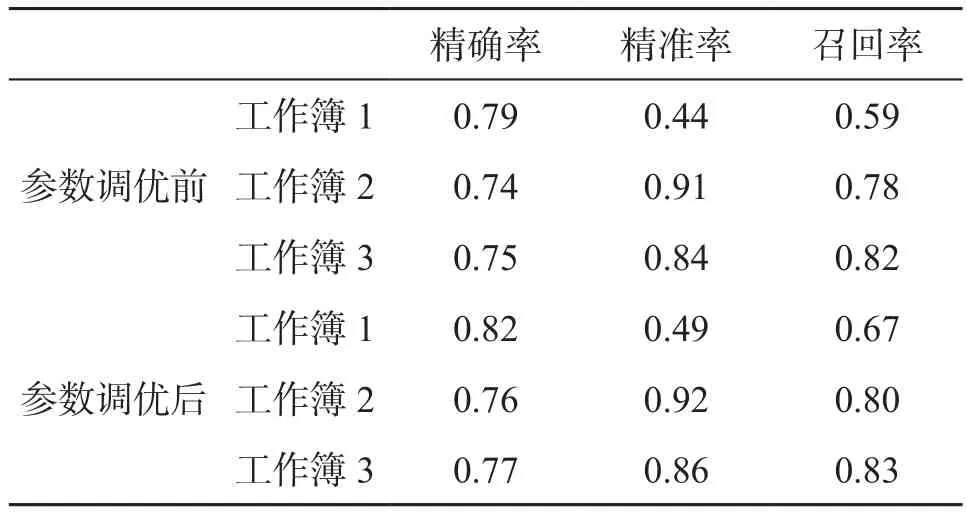
表3 调优前后综合预测效果表
4 系统方案与能量优化
4.1 系统监测方案
铱星通信终端可基于不同研究方式采取不同监测方案与控制方案,目前铱星通信终端在海洋当中的应用主要分为固定监测和流动监测。当监测方式为流动监测时,系统方案:按日期推移,启动时间修订,同时检测当前环境下铱星信号质量,预测接下来信号质量优劣,选择是否发送数据包。当监测方式为固定监测时,系统方案:启动系统后检测一天信号质量,预测第二天数据发送时间点的同时进行数据采样。具体方案流程图如图7所示。

图7 监测方案流程图
4.2 能量优化计算
铱星通信终端发送数据方式为2 min发送一包数据,启动一次等于发送5包数据。按照预测模型的召回率,假设在信号质量劣的环境下发送100包数据,召回率为0.67,总共需要发送149次能够将数据包发送完。未对信号进行预测,传统数据发送方式的发送次数为408次。在信号优的环境下发送100包数据,召回率为0.80,需要发送125次。同上,未预测信号的发送次数为131次。铱星通信终端功率参数如表4所示。

表4 铱星通信终端耗电参数表
劣信号质量环境下传统数据发送方式所消耗的能量为:
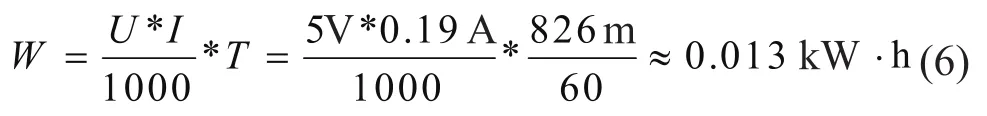
进行信号预测能量消耗为:

优信号质量环境下传统发送数据方式所消耗的能量为:

进行信号预测能量消耗为:

根据以上计算可以得出,信号劣的环境下节能63%,信号优环境下节能4.6%。
5 结 论
本文针对研究生产中铱星信号出现干扰的情况,提出对铱星信号干扰预测的研究。使用Labview语言编写上位机程序对铱星信号进行全天检测,获取铱星信号质量数据。实验证明选择不同环境测量信号的重要性。
根据预测模型的预测指标,计算得出不同环境指标下的能量优化范围为4.6%~63%,证明该预测模型在具有有效性和可行性的基础上,铱星信号越好的情况下能量优化效率越低,反之能量优化效率越高。预测模型预测效果还有待提高,下一步需对ACC及AUC两个指标继续研究,引入更多的分类预测算法进行相关验证,提高分类预测综合效果。
