一种基于机器学习的Tor 网络识别探测技术
2021-04-24卫传征林臻彪段琳琳
张 玲 ,卫传征 ,林臻彪 ,段琳琳
(1.北京赛博兴安科技有限公司,北京 102200;2.郑州大学 信息工程学院,河南 郑州 450001)
0 引言
Tor 匿名网络是一个由全球志愿者维护的各自匿名网络所组成的大型分布式匿名通信网络,其核心技术是美国海军研究室开发的洋葱路由系统,设计初衷是保护政府机关的数据通信隐私。
Tor 用户通过连接一系列虚拟通道在通信的源端与目的端之间建立间接的数据链路,使得包括个人和机构在内的用户在互联网中的数据传输行为匿名化[1]。由于该技术能够有效规避网络监管,成为访问受限网段的有效措施。
洋葱路由技术提供的身份匿名性和数据安全性使得Tor 网络成为网络内容犯罪的温床。同时,区块链、虚拟数字货币等技术的发展为网上非法交易带来便利,更使得包括Tor 网络在内的暗网成为互联网中的法外之地,产生越来越多涉及黄、暴、恐的非法信息和非法交易。鉴于此,本文研究Tor 网络流量的分析和识别。对于给定的真实网络数据,本研究的目标是鉴别其中流量是通过普通网络通信数据还是Tor 流量。在有效识别Tor流量基础上,本文进一步研究Tor 通信行为分类,包括浏览网页、邮件服务、即时通信、流媒体、FTP、VoIP 和P2P 通信等。
1 相关工作
(1)Tor 流量识别
近年来,研究人员提出了若干解决方案来识别Tor网络中产生的数据[2]。LASHKARI A H 等人[3]对网络中Tor 客户端与Tor 网络入口节点之间的通信进行时序分析,通过随机森林分类器对提取的特征达成95%的识别准确率。
HE G 等人[4]提取Tor 流量特征,通过隐马尔科夫模型将Tor 通信分离为P2P、FTP、即时通信和网页4 类,并取得了92%的准确率。
CHAKRAVARTY S 等人[5]提出了一个针对Tor 客户端的流量攻击技术来识别Tor 客户端的IP 地址。对Tor 服务端节点发起主动流量分析攻击,并观测客户端侧产生的摄动,通过统计相关性指标可以识别到一组Tor 流量相关的服务端和客户端。
(2)Tor 网站识别
针对Tor 网站的攻击包括网站指纹识别攻击和洋葱站点枚举攻击[6]。最早针对Tor 网站的指纹攻击由HERRMANN D 等人[7]提出,并只取得了3%的正确率。该研究领域接下来获得了极大的重视和发展,并在不同的场景环境下取得了超过90%准确率,相关研究见参考文献[8]、[9]。
访问Tor 网站极大地依赖洋葱网络中的隐藏服务目录查询协议[10],而该协议被证明容易被仅具有低带宽Tor 中继节点的攻击者进行服务枚举攻击[11],从而测量Tor 网站等洋葱服务的活跃程度。已有相关工作通过枚举攻击方法来研究洋葱服务的生态[12]。当然,该类攻击的威胁可能随着相关协议的更新得到缓解。
上述研究工作主要关注两类问题:(1)有效识别互联网中Tor 节点之间传输的流量;(2)对于Tor 通信流量所承载的应用数据,识别其应用服务类型。与上述研究类似,本文通过机器学习方法来识别网络中的Tor 流量,并进一步识别Tor 流量中承载的8 类应用数据。实验表明,本文提出的方法能够取得较高的预测准确率。
2 本文方法
本文首先通过设置网络探针捕获网络中的流量数据,进而对流量中混杂的数据帧进行组流,将属于相同数据流的帧按照协议和帧顺序进行恢复。然后以数据流为样本,提取其机器学习分类特征,训练分类器,并应用训练后的分类器对目标数据进行分类,分析分类效果。
需要特别解释的是,本文中一条通信流由一组具有相同五元组{源IP、目的IP、源端口、目的端口、协议}的数据帧组成,其中Tor 支持的协议为TCP 协议。本文依照该规则,在TCP 协议层进行流重组。
2.1 数据采集
数据准备阶段包括数据生成、数据采集和组流3 个环节。首先需要生成带有类别标签的数据:在沙箱中分别运行包括网页浏览、即时通信、音频流、视频流、电子邮件、VoIP、P2P 数据传输和FTP 文件传输8 种类型的网络应用,并利用架设的Tor 网关服务将相应应用产生的网络流打包传输至Tor 网络中。进而使用tcpdump 应用在Tor 网关两端采集数据帧,即可得到两类实验数据:(1)应用于Tor 流量检测的带Tor 和非Tor 标签的网络帧数据;(2)应用于Tor 通信行为分类的带8 种应用类型标签的Tor 网络帧数据。
接下来,按照五元组将网络帧进行重组,形成网络流。对具有相同五元组的不同网络流,采用TCP 协议中的FIN 帧来进行切分。8 类应用数据流的生成方法描述如下:
(1)页面浏览:通过selenium 自动化工具调用Firefox和Chrome 浏览器的geckodriver 和chromium 内核,遍历访问Alexa 知名网站列表,并对首页内超链接进行深度为2的访问遍历,获得所有HTTP 和HTTPS 流量,数据总量8.5 GB。
(2)即时通信:本文采集的即时通信数据来自微信、QQ、Skype、Telegram、WhatsApp、和Signal,行为包括文本聊天、文件传输等,数据总量1.9 GB。
(3)音频流:QQ 音乐和网易云音乐是中国最大的音频流媒体应用平台,本文分别采集这两个桌面应用自动播放时产生的4.0 GB 流媒体传输数据。
(4)视频流:本文采集了腾讯视频、搜狐视频、优酷视频等自动播放时的7.8 GB 多媒体流。
(5)电子邮件:通过邮件客户端绑定包括采用STMP/S、POP3/SSL 和IMAP/SSL 等协议的网络邮箱,除通过邮件客户端的自动更新功能进行邮件传输外,主动通过各个邮箱发送、接收邮件及其附件,数据总量2.3 GB。
(6)VoIP:采集包括微信语音、Skype 通话、Facebook Messenger 通话和Google Voice 等在内的语音通话数据作为VoIP 标签数据,数据总量2.0 GB。
(7)P2P:国内最知名的P2P 应用是迅雷,然而由于其广告等扩展功能太多,为获得干净的P2P 流量,本实验采用Bittorrent 应用进行数据传输,获得26 GB P2P 协议数据。
(8)FTP:本文在采集FileZilla 的客户端和服务端应用进行文件上传和下载时产生的流量作为FTP 标签数据,采集的数据包括SFTP 协议数据和FTPS 协议数据,数据总量10 GB。
2.2 特征提取
本文对同一个网络流中的上下行流量分别提取特征(规定客户端指向服务端的方向为上行方向,其反方向为下行方向),最终形成27 个的特征:
(1)上行帧时间差(UPward Inter Arrival Time,UIAT):上行帧之间的时间差,包括时间差的均值F0、最小值F1、最大值F2和标准差F3。
(2)下行帧时间差(Downward Inter Arrival Time,DIAT):下行帧之间的时间差,包括均值F4、最小值F5、最大值F6和标准差F7。
(3)帧时间差(Flow Inter Arrival Time,FlowIAT):所有帧之间的时间差,包括其均值F8、最小值F9、最大值F10和标准差F11。
(4)流活跃时间(Active):在流进入空闲状态之前所经历的时间,包括其均值F12、最小值F13、最大值F14和标准差F15。
(5)流空闲时间(Idle):在流进行活跃状态之前,保持空闲状态的时长,包括其均值F16、最小值F17、最大值F18和标准差F19。
(6)流字节速率(Flow Bytes Per Second,FlowBPS):该流平均每秒传输的字节数,用F20表示。
(7)流帧率(Flow Packets Per Second,FlowPPS):该流平均每秒传输的帧数量,用F21表示。
(8)流负载(Flow Payloads,FP):该流上行字节数F22、下行字节数F23、上行帧数F24、下行帧数F25。
(9)流持续时间(duration):流的第一帧和最后一帧的间隔时间F26。
上述特征除流持续时间外,按照特点可分为6 组特征。前3 组分别是上行帧时间差、下行帧时间差和帧时间差特征,着重刻画上下行流量中的时间间隔特征,分别命名为UIAT、DIAT 和FlowIAT;第4、5 组特征关注流在活跃和空间状态之间变化的特点,分别用Active 和Idle 指代;最后一组包括流字节速率FlowBPS、流帧率FlowPPS和流负载FP,关注的是流在不同层面的传输量和传输速率,统一用FP 代替。
2.3 实验流程
首先通过实验验证所提特征集合对Tor 流量和普通流量进行区分的能力。实验分两个阶段,包括:(1)通过假设检验,验证每个特征在Tor 流量和普通流量上数值分布上的差异显著性;(2)通过训练分类器,验证提取的特征对Tor 流量和普通流量进行分类的有效性。
在假设检验阶段中,设零假设H0为:对于Tor 网络流和正常流提取的特征,不存在统计上的显著差异性。进而采用SPSS 软件中非参检验工具集,分别进行Mann-Whitney (MW,p=0.05) 测试和Kolmogorov-Smirnov(KS,p=0.05)测试[13],以增强结论的可靠性。相关测试均可用于验证目标数据与给定分布之间的差异性,实验中风险阈值设定为0.05。
第二阶段,采用机器学习分类器进行效果评估,即基于本文所提的27 维分类特征,采用10 折交叉验证,分别在Tor 流量检测问题和Tor 通信行为分类中测试分类器的效果。
本文采用scikit-learn 机器学习工具集[14],从中分别选择K 近邻分类器(K Nearest Neighbor,KNN)[15]、逻辑回归分类器(Logistic Regression,LR)、C4.5 决策树(Decision Tree,DT)[16]、朴素贝叶斯分类器(Naïve Bayesian,NB)[17]、支撑向量机分类器(Support Vector Machine,SVM)[18]和随机森林分类器(Random Forest,RF)[19]6 种经典分类模型进行分类效果测评。
3 实验结果
3.1 评价指标
本实验分别采用准确率(Precision)、召回率(Recall)、F-测度(F-Measure)、马修斯相关系数(Matthews Correlation Coefficient,MCC)[20]、接受者工作特征曲线(ROC)和精度-召回率曲线(PRC)等测量指标评价Tor 流量的分类效果。
3.2 实验结果
本节分别进行Tor 流量识别和Tor 通信行为分类。在Tor 流量识别任务中,首先通过假设检验分别验证所提特征在不同类别流量下的分布差异性,进而通过训练分类器验证特征的有效性;在Tor 通信行为分类中,直接通过训练分类器验证特征的有效性。
3.2.1 Tor 流量识别
经过MW 和KS 检验,不同特征的参数分布均拒绝原假设H0,故备择假设成立,表明本文所提特征在Tor流量和普通流量上的概率分布呈现显著差异性,可被有效用于区别两类数据流,因而运用所有27 个特征来完成接下来的分类任务。
表1 给出了Tor 流量识别问题的实验结果,可以看到,所有给出的分类算法都能够有效识别Tor 网络流量。其中,随机森林分类器的预测结果最好,在每个评价指标上都取得了最高分;支撑向量机的分类效果次之;效果最差的分类器是决策树,在F-Measure 等4 个综合评价指标中都得到了最低的得分。
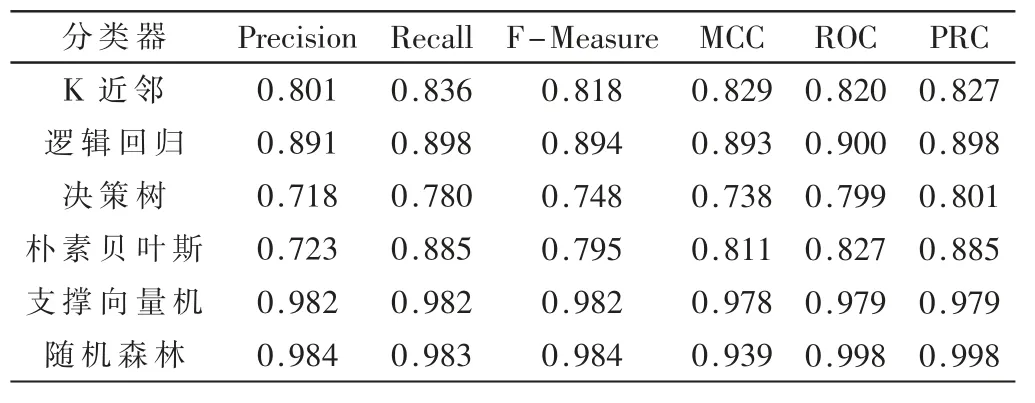
表1 全特征Tor 流量识别
表2 展示了不同特征组在Tor 流量识别任务中的效果,分类算法采用全特征预测时效果最好的支撑向量机和随机森林。由表可知,在两个分类器中,特征组Active 和特征组Idle 的预测效果均最差,仅略高于随机分类,特征组FP 均取得了最好的预测效果;UIAT、DIAT和FlowIAT 的分类效果接近,预测效果介于上述两类特征的预测效果之间。
接下来通过逻辑回归分类器分析预测特征。逻辑回归分类器的优点是除能够给出分类预测结果外,还可以检验自变量与因变量的相关性,并且与自变量相对应的回归系数可以显示自变量与因变量的相关强度以及正负相关性。本文用逻辑回归分类器判断基于内容特征的各项指标是否具有较强的链路预测能力。
对于该二分类问题,将某条流量的类别作为因变量;将27 维特征作为自变量,可得到表3 逻辑回归实验结果的训练结果。其中标准误差项用于评价回归系数是否显著不为0,z 值由回归系数与标准误差之比得到,与p一起用来检验回归系数为0 的零假设。此处同样取显著性水平α 为0.05,当p 小于α 时,说明回归系数显著不为0,即自变量与因变量显著相关。由p 列可知,特征F19的p 值大于显著性水平α,因此除特征“流空闲时间的标准差值”外,在回归模型中,其他预测特征对Tor流量识别均具有显著影响。

表2 特征组Tor 流量识别

表3 逻辑回归实验结果
3.2.2 Tor 通信行为分类
表4 展示了本文所提特征在Tor 通信行为分类任务中的结果。由表可知,支撑向量机分类器取得了最好的预测效果,综合指标值接近0.85。相较于支撑向量机和随机森林,K 近邻、决策树和逻辑回归的模型拟合能力较差,因而预测效果较差。
4 结论
本文针对Tor 流量的检测与识别问题,提出了一种基于机器学习的Tor 流量探测技术。通过主动生成Tor 网络流量,提取网络流特征,训练分类器,对Tor 流量与普通流量进行分类,取得了F-measure 测度值0.98 的效果。更进一步地,在对Tor 服务所承载的多种应用数据进行分类时,该套特征也取得了准确率85.9%和召回率82.1%的预测结果。试验中支撑向量机和随机森林在所有实验条件下取得了最好的分类效果,效果最好的分类特征组是FP。实验表明本文所提方法是有效的。

表4 全特征Tor 通信行为分类
本文的后续工作将考虑在时序特征、网络拓扑结构特征等方面进一步丰富和优化特征集合,以进一步提高Tor 通信类型分类的效果。同时进一步研究Tor 网络中的其他常见通信数据,拓展本文所提方法的应用范围。
