基于多核的进程拓扑感知映射研究
2021-04-23冯慧
冯 慧
(山东科技大学计算机科学与工程学院,山东青岛 266000)
0 引言
多核架构目前为并行计算中较常见的计算架构,未来几年芯片上的核心数量仍会急剧增长,在高性能计算中,集群已从单个网络互连的单处理器转变为复杂且高度分层的结构,如中国超级计算机中心的超级计算机系统神威·太湖之光[1]由40 960 个节点组成。通常每个计算节点包含多个共享内存的多核处理器,节点内的内存访问时间取决于计算核心与内存之间的距离。与不同芯片上的计算核相比,同一芯片上的计算核之间通信延迟要低得多,通信带宽要高得多。因此,编程标准及其实现在充分发挥硬件系统计算潜力方面起着关键作用。在并行编程标准中,消息传递接口(Message Passing Interface,MPI)因其丰富的接口而广受欢迎,但是MPI 是一种跨平台的编程标准,设计成独立于硬件、不提供拓扑感知的进程映射功能。一般的MPI 提供诸如MPI_DIST_GRAPH_CREATE[2]功能创建拓扑,但由于未考虑底层架构,所以并不能提供有效的映射方法。
如何更好地利用多核体系架构是真正的挑战。为在多核环境下获得最佳性能,必须考虑到硬件底层架构和应用特点。关于拓扑感知映射研究有:Hoffler[3]提出结合几种启发式算法的网格互连体系结构的通用拓扑映射策略;Bhatele[4]针对网格互联提出规则通信图的自动映射方法;Hatazaki[5]为特殊的HP 集群实现MPI 拓扑映射功能;Mercier 等[6]使用图分区工具SCOTCH[7]实现加权通信图到加权节点架构图映射,但其没有考虑网络拓扑;Jeannot 等[8]提出TreeMatch 算法计算NUMA 集群中进程到资源的近似最优映射;Wu 等[9]提出递归树映射算法和递归二分映射算法,解决并行应用程序的层次任务映射;Li 等[10]提出一种基于拓扑感知进程映射的同构树映射算法,该算法根据进程间的亲和性将进程分区映射;Brandfass 等[11]通过重新排序MPI 的进程号建立MPI 进程到CPU 内核的映射;Pellegrini[12]提出一种基于应用程序进程图和目标体系结构图的递归双分割映射算法进行映射。
本文针对当前进程拓扑感知映射方法进行测试分析,重点讨论硬件架构和应用通信特点二者在多核环境下进程拓扑感知映射中的影响,总结解决此类问题的研究思路:利用不同类型的应用(CGKernal 和分子动力学)在两种系统(天河1A 和曙光)上进行测试,依据测试结果分析不同架构处理应用时的不同特点,总结进程拓扑感知映射的适用范围,以更好地发挥拓扑感知映射优势处理更复杂的大规模计算问题,硬件的架构选择和不同类型应用的选择在进程拓扑感知映射中同等重要。
1 拓扑感知信息获取及分析
检索有关底层硬件的内存层次结构、内核编号等信息并非易事,目前一些感知工具可获得硬件的底层结构,最常见的工具是HardwareLocality(HWLOC)[13]。这种工具能轻松地提供有关广泛系统上各种高速缓存级别信息,通过HWLOC 收集硬件的详细内部信息,如插槽的数量、计算核心数量以及内存层次信息(包括NUMA 节点中的多级缓存)。使用HWLOC 将硬件结构抽象成树进行建模,其深度与层次结构中硬件组件的深度(如网络交换机、机柜、节点、处理器、缓存、核心)相对应,其叶子节点是架构的计算单元。
HWLOC 的灵活性使其允许跨操作系统对硬件架构进行建模。HWLOC 实现了众多功能的库函数,可被其它软件调用,因此可用来动态建立模型。另一种分析硬件方法是使用LINUX[14]查看CPU 信息指令,虽然可以通过进一步分析得出硬件的架构信息,但前提是必须对硬件信息比较了解,才能准确无误地分析出硬件信息。另外,通过LINUX 自带的命令分析出来的硬件信息并不完整,cache的层次不能得到完整构建。相反,通过HWLOC 可以检测到任意节点的硬件信息,通过命令行方式以PDF 或XML格式对硬件信息进行输出,使硬件信息更加直观,这也是使用HWLOC 的一大便利。
2 应用通信获取及分析
为获得应用的通信信息,Zhang 等[15]提出OPP 方法,根据通信库中集合通信的实现,将集合通信转换为一系列点对点通信操作;Buntinas[16]通过修改MPICH2[17]和Open MPI 堆栈中的低级通信层,在点对点和集合通信情况下详尽跟踪数据交换信息。由于该收集应用通信信息的方法比较简单,因此不会影响应用程序的执行。还有其他的MPI 实现者也采用这种方法,Chen 等[18]结合应用程序代码的静态分析和对修改后的应用程序动态执行,使该应用程序执行速度更快,同时保留了与原始应用程序相同的通信模式,目的是将确定通信模式所需的时间减少几个数量级;Bosilca 等[19]提供了基于MPI 工具信息接口标准的MPI,在不修改应用程序情况下进行通信信息追踪。要注意的是,在所有方法中都必须执行原始版本或更简单版本的应用程序。
应用通信特点在拓扑感知映射过程中的作用至关重要,可从两个方面去考虑应用通信类型:①应用通信是否规则;②应用通信占比大小。较规则的通信应用特点是每个进程和其它所有进程进行通信传送的信息量几乎一样。另外不能忽略应用通信占比,一般来讲,应用通信时间占总体运行时间较小的应用对拓扑感知映射效果不会很好。
3 测试
3.1 测试环境及测试程序
在两类架构上对两种类型应用进行测试。
3.1.1 两种架构
(1)TH-1A。登陆节点由8 个CPU 插槽组成,每个CPU 由8 个计算核心组成(不考虑开启超线程情况),登陆节点一共有64 个计算核心。每个CPU 上的8 个核心分别拥有32KB 的一级指令cache、32KB 的一级数据cache 和256KB 的二级cache,同时每个CPU 上的8 个计算核心通过片上互联共享18MB 的三级cache;TH-1A 登陆节点的8个CPU 通过PCI 总线技术共享256GB 内存。
(2)曙光集群单节点架构。曙光登陆节点由2 个CPU插槽组成,每个CPU 由8 个计算核心组成(不考虑开启超线程情况),登陆节点一共有16 个计算核心,每个CPU 上的8 个核心分别拥有32KB 的一级指令cache、32KB 的一级数据cache 和256KB 的二级cache,同时每个CPU 上的8 个计算核心通过片上互联共享20MB 的三级cache;曙光登陆节点的2 个CPU 通过PCI 总线技术共享64GB 内存。
3.1.2 两类应用
(1)分子动力学。分子动力学(Molecular Dynamics,MD)模拟指使用数值方法,利用计算机模拟原子核和电子所构成的多体系统运动过程,广泛应用于物理、化学、生物、材料、医学等多个领域,用来研究系统的结构和性质。通过对MD 应用各部分运行时间进行分析,得知该应用的大部分运行时间在进行计算,进程和进程间的通信时间占整个应用运行时间极小部分,几乎可以忽略不计。通过跟踪MD 应用的进程间通信信息,对应用进程间通信的信息量进行分析,发现进程间的通信不规则以及进程之间信息交换总量小,所以MD 属于通信不规则且通信量占比很小的应用。
(2)CG Kernal。CG(Conjugate Gradient)是NAS Parallel Benchmarks(NPB)[20]中的一个核心程序,用于求解大型稀疏对称正定矩阵最小特征值的近似值,它表征了非结构风格计算和非规整远程通信计算类问题。通过跟踪MD 应用的进程间通信信息,对应用进程间通信的信息量大小进行分析,发现进程间通信是不规则的,同时该应用进程间通信的信息总量较大,所以CG 应用属于通信不规则且通信量较大的应用。
3.2 测试结果及分析
分别对MD 和CG 两类应用在TH-1A 和曙光集群上进行3 种映射算法(自动调度、RR 算法、TreeMatch 算法)测试,测试结果见图1—图4。

Fig.1 Molecular dynamics(TH-1A)图1 分子动力学(TH-1A)
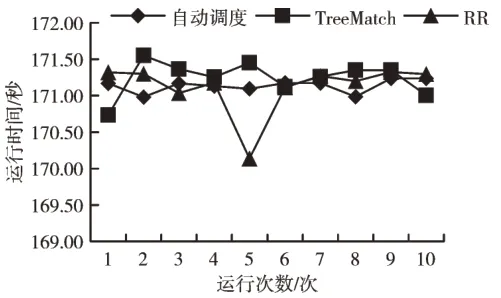
Fig.2 Molecular dynamics(Dawn)图2 分子动力学(曙光)
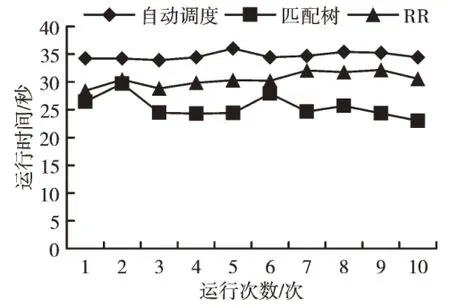
Fig.3 CG Kernal(TH-1A)图3 CG Kernal(TH-1A)
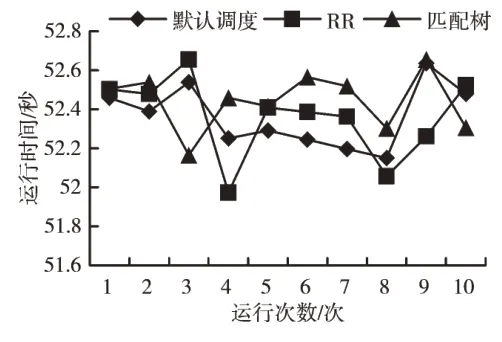
Fig.4 CG Kernal(Dawn)图4 CG Kernal(曙光)
在TH-1A 和曙光架构上分别对3 种调度算法进行分子动力学映射绑定测试。3 种调度映射算法都没有表现出较好的计算结果,这是因为分子动力学中进程间通信的时间占总体执行时间比较小,所以进行拓扑感知映射不能得到好的效果,见图1 和图2。分别对CG Kernal 进行3 种调度测试,CG Kernal 在TH-1A 上使用匹配树算法,和另外两种算法相比表现出较好性能,相反CG Kernal 在曙光上3种调度方式结果差异性不明显,如图3 和图4 的测试结果所示。使用相同应用在不同架构上进行的测试结果相差较大,分析原因是硬件架构不同。在TH-1A 上使用64 个计算核心进行测试,由8 个CPU 插槽组成。由于计算核心数量较多,所以计算核心之间存在的层次关系也较多,需要描述的亲和性信息也更加复杂。而在曙光上使用16 个计算核心,由两个CPU 插槽组成,相较于TH-1A 计算核心数量较少,计算核心之间层次较单一,亲和关系较简单,由此可见硬件架构特点在拓扑感知映射中至关重要。
4 结语
本文针对当前的拓扑感知映射,从系统架构和应用特点两方面分析了进行拓扑感知映射性能优化时需要考虑的问题,并分析了目前该领域相关研究进展及特点。
综合当前存在的拓扑感知映射方法硬件架构差异较大、应用通信特点不同问题,从硬件的架构层次及应用的通信特点两个方面考虑多核环境下进行拓扑感知映射性能提升,这也是未来研究的趋势。
