融入景点标签的矩阵分解个性化推荐
2021-04-23许璐璐
张 鑫,许璐璐
(1.山东科技大学测绘与空间信息学院,山东青岛 266590;2.烟台市钰丰地质技术服务有限公司,山东烟台 264010)
0 引言
近年来,互联网旅游业呈现爆炸式增长,给人们的生活带来了巨大影响。在线旅游评论数据作为一种反馈机制,为用户决策提供了重要依据。然而,海量的旅游景点在为用户提供更多选择的同时,出现了信息过载问题。景点推荐是解决当前问题的有效方法,其基本思想是通过景点及用户信息,自动为用户推荐其感兴趣的旅游景点,从而达到景点个性化推荐。
1 相关工作
协同过滤(Collaborative Filtering,CF)是目前使用最为广泛的推荐技术[1-2],主要是利用用户相似性[3-4]或物品相似性[5-6]预测目标用户对物品的评分值。现有基于协同过滤的景点推荐方法主要是基于用户的协同过滤[7-9](Userbased Collaborative Filtering,UBCF),即通过用户的相似用户对景点的评分值预测目标用户的景点评分值,从而对目标用户进行景点推荐。最初,研究者利用景点评分、浏览时间、打卡次数等数据计算用户之间的相似度[10-12],从而预测用户对景点的评分值,该方法有效利用了用户间的关联进行景点推荐,但由于景点评论数据比较稀疏,因此计算精度不高。随后,许多学者对UBCF 方法进行了改进。Huang 等[8]在计算相似度时加入季节因素,从时间和景点两个维度分析用户的旅游历史,从而为用户进行景点推荐;Zhu 等[13]将景点的位置标签引入用户相似度计算,充分考虑了位置信息对用户进行景点选择的影响;陈氢等[14]、Xu 等[15]在为用户进行景点推荐的同时引入景点位置、旅游季节和天气因素,充分挖掘了景点的时间和空间信息;李雅美等[16]综合考虑景点的区域、时间、主题、类型特征,为景点构建标签,并利用用户对标签的评分值计算用户间的相似度,从而利用相似用户对目标用户进行景点推荐。以上方法均是对用户相似度计算进行改进,通过对景点进行更加细粒度的分析,从而综合考虑影响用户相似度的各种因素,加强了各景点间的关联,并在一定程度上缓解了数据稀疏对结果的影响,但仅采用用户对景点的评分不足以表达用户对景点标签的喜爱程度,忽略了用户、标签、景点之间的关联。
近年来,基于模型的协同过滤算法——矩阵分解[17-19](Matrix Factorization,MF)推荐技术成为研究重点,它通过对用户特征矩阵及物品特征矩阵的预测计算用户对物品的评分。传统基于矩阵分解的推荐算法通常引入大量未知参数进行物品特征描述[20-21],无法真实反映物品特征,且容易出现过拟合现象,Ma 等[22]、Luo 等[23]通过引入电影类别标签探究用户、项目、标签之间的关联,并采用矩阵分解为用户进行推荐,取得了较好效果;宋威等[24]、方冰等[25]在电影类别的基础上加入用户标注标签,进一步反映了物品的真实特征。然而,现有基于矩阵分解的景点推荐均采用传统的隐式矩阵表达项目潜在特征,Yong 等[26]在使用传统矩阵分解模型进行景点推荐的同时,加入时间和旅游成本特征,从而为用户进行更好的推荐;李广丽等[27]在传统矩阵分解的基础上,结合出游季节、出游方式、兴趣类别等景点特征计算用户兴趣偏好,从而采用混合推荐方式为用户进行景点推荐。以上方法均在传统的矩阵分解推荐模型基础上加入结合景点特征的推荐结果为用户进行景点推荐,考虑到了景点的部分特征,但在采用矩阵分解时仍采用隐式矩阵表达景点特征,并未真正对景点特征进行挖掘,推荐结果缺乏可解释性。
针对上述问题,本文构建了景点标签,将景点标签引入矩阵分解推荐算法,结合用户—景点矩阵及景点—标签矩阵预测用户在景点标签层面的评分值,从而预测用户对未评分景点的评分值,缓解了传统协同过滤算法的数据稀疏问题,提高了算法预测精度,同时使矩阵分解推荐算法的潜在特征更加具体,增强了算法的可解释性,为景点推荐提供了有力支撑。
2 研究方法
2.1 景点标签抽取
定义用户集合为U={u1,u2,...,um},景点集合为V={v1,v2,...,vn},景点标签集合为L={l1,l2,...,lk}。景点标签是连接用户与景点的重要节点,是对景点细粒度特征的挖掘,它能够将用户—景点之间的二元关系(见图1(a))转换为用户—标签—景点之间的三元关系(见图1(b))。
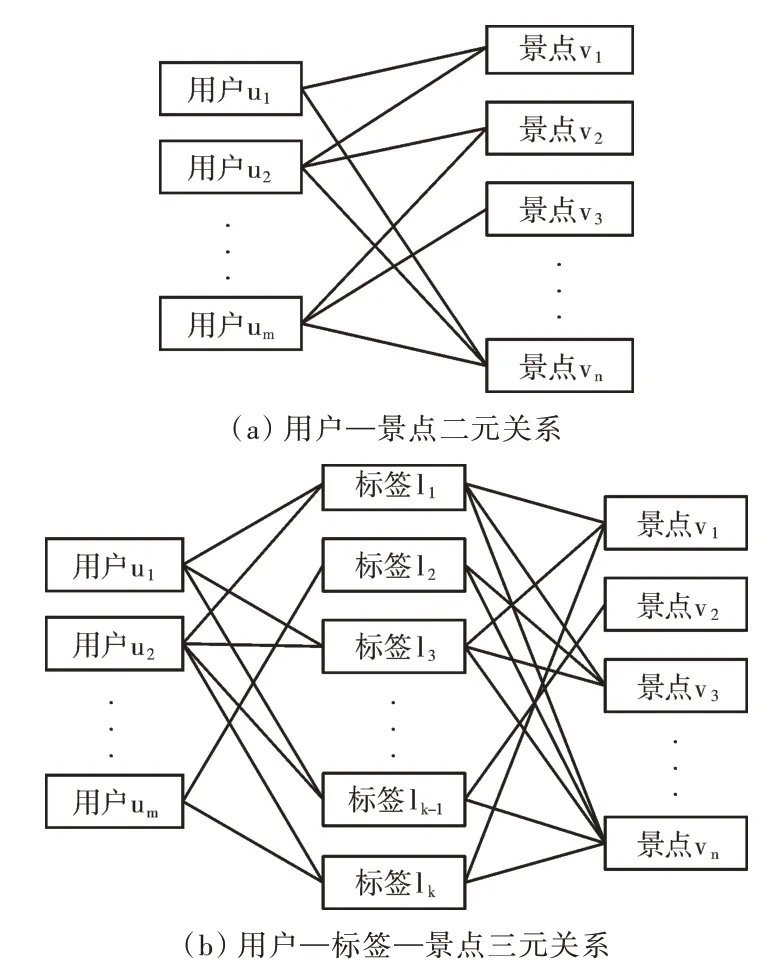
Fig.1 User-attraction/user-tag-attraction relationship图1 用户—景点/用户—标签—景点关系
由图1(b)可以看出,景点标签与景点之间是多对多的关系,为提取它们之间的关联,首先需要对景点评论文本进行特征词提取,通过特征词与景点标签之间的关系判断景点与景点标签之间是否能够建立连接,从而进行景点标签抽取。
(1)特征词提取。在旅游网站中,用户往往通过文字评论表达对景点某些特征的喜好。因此,在海量的景点评论数据中存在大量表达景点细节特征的关键词。本文采用TF-IDF 算法[28-29]计算各景点评论数据中关键词的权重,TF-IDF 代表词频和逆文档频率。词频(Term Frequency,TF)是指关键词在文档中出现的频率,计算公式如式(1)所示。
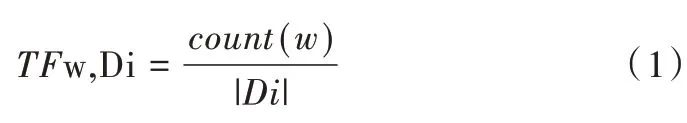
其中,w为关键词,Di为景点评论文本,count(w)表示关键词w在文档Di中出现的次数,|Di|表示Di中的总词数。
逆文档频率(Inverse Document Frequency,IDF)指关键词的普遍程度,计算公式如式(2)所示。

其中,N表示总文档数,Di表示含有w的总文档数。
文档Di中关键词w的权重计算如式(3)所示。

在完成关键词权重计算的基础上,本文按照关键词权重进行降序排序,并提取前2k(k表示景点标签的数量)个关键词作为景点的特征词。
(2)景点标签抽取。在景点特征词提取完成后,遍历景点特征词及景点标签特征词表,若特征词包含或包含在某个景点标签的特征词表字符串中,则认为景点具有该标签,否则景点不具有该标签。
2.2 矩阵分解个性化推荐
本文首先通过景点标签抽取构建景点标签矩阵,然后利用景点标签矩阵以及用户景点矩阵预测用户对标签的评分值,最终结合景点对标签的隶属度计算用户对未评分景点的评分值。具体推荐过程如下:
(1)用户— 景点矩阵。对于用户集合U={u1,u2,…,um}中的任意用户ui,依据ui的历史旅游景点及景点评分数据,构建用户—景点向量ri(ri1,ri2,…,rin),其中rij的取值如式(4)所示。
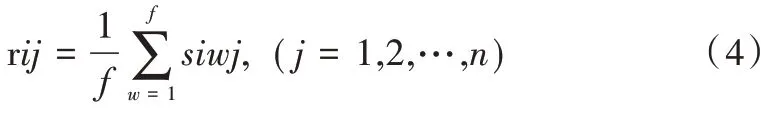
其中,n为景点个数,f表示用户ui去景点vj的次数,siwj表示用户ui第w次对景点vj评分值。对全体用户集合U={u1,u2,…,um},分别采用式(4)计算用户—景点向量,从而得到用户—景点矩阵R={r1,r2,…,rm}。
(2)景点— 标签矩阵。对于景点集合V={v1,v2,…,vn}中的任意景点vi,构建景点—标签向量qj{qj1,qj2,…,qjk},其中qij的取值如式(5)所示。
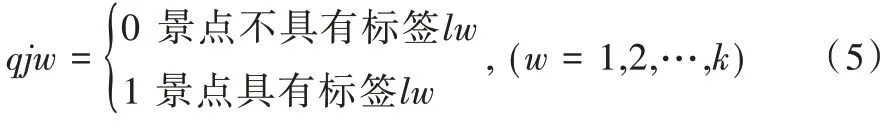
其中,k为景点标签个数,qjw表示景点vj对应标签lw的值。对全体景点集合V={v1,v2,…,vn},分别采用式(5)计算景点—标签向量,从而得到景点—标签矩阵Q={q1,q2,…,qn}。
(3)用户—标签矩阵。在用户—景点矩阵R 以及景点—标签矩阵Q 计算完成的基础上,本文采用含有正则项的矩阵分解模型计算用户对于景点标签的喜爱程度。如上所述,景点标签是对景点特征的细粒度描述,每个景点都有对应的景点—标签向量qj{qj1,qj2,…,qjk}。为此,依据用户评分及景点— 标签向量学习用户— 标签向量pi{pi1,pi2,…,pik},从而得到用户对景点标签的喜爱程度。具体流程如下所示。
初始化用户—标签矩阵:首先,采用随机初始化方式初始化用户—标签矩阵P,利用初始化后的P与QT(景点—标签矩阵Q的转置)的乘积预测用户评分矩阵Rˆ,如式(6)所示。

计算损失函数:由式(3)得到用户ui对景点vj的预测评分为=pi*qjT,假设用户实际评分为rij,为计算预测值与真实值之间的误差,引入损失函数eij2,如式(7)所示。

其中,λ(||pi||2+||qj||2)为避免过拟合加入的正则化项;λ为常数,称作正则化参数。
更新用户—标签矩阵:沿着梯度下降方向更新pu,如式(8)所示。

其中,α为步长,pi'为更新后的用户—标签矩阵。
迭代:循环计算eij2并更新pi,直到eij2小于设定的某个阈值或迭代次数达到最大阈值,从而得到训练后的pi。
(4)景点个性化推荐。根据训练得到的用户—标签矩阵能够得到用户对景点标签的喜爱程度,结合景点对标签的隶属度,即可得到用户对景点的评分值,从而将评分值高的景点推荐给用户。
3 实验及结果分析
3.1 景点标签构建
本文结合Beerli 等[30]、高静等[31]、李雅美等[16]对旅游景点特征的描述,构建了包含景点活动、旅游对象、旅游季节、门票类型、人文风俗、旅游场所、购物等七大因素下的66 种景点标签,其结构如图2 所示。
景点标签是对景点特征的总结,每个景点标签都对应了多个特征词,本文通过人工标注方式为景点标签添加了相应的特征词,构建了景点标签特征词表,以人文风俗为例,各标签的特征词如图3 所示。
3.2 实验数据及预处理
本文将携程旅行网(www.ctrip.com)上青岛市排名前100 的旅游景点作为研究对象,获取了2010-2018 年的景点评论数据和网站上公布的用户景点评论数据,共49 338条。在携程网上采集到的数据存在数据缺失、重复评论等情况,因此需要对采集的数据进行清洗,删除以下几种类型的评论数据:①多个重复语句组成的评论;②同一用户在一周之内多次对单个景点的评论;③谩骂或辱骂等不符合法律规定的评论;④由无效字符或特殊表情符号构成的评论;⑤同一用户对多个景点使用同一个文本的评论;⑥非中文表达的评论,如英文、韩文;⑦几乎全部由一个字或某几个字组成的单条评论,如“棒!!!!!!”。

Fig.2 Attractions label structure图2 景点标签结构
Fig.3 Examples of characteristic words in humanities图3 人文风俗特征词示例
经过数据清洗后留下的景点评论数据共48 588 条。为了避免冷启动问题,去除评论数小于8 的用户,共得到559 个用户的10 408 条评论数据。
3.3 评价指标
本文使用平均绝对误差(Mean Absolute error,MAE)和均方根误差(Root Mean Square Error,RMSE)作为评价标准,如式(9)、式(10)所示。

其中,N表示测试集中的总评分记录。由式(9)、式(10)可以看出,MAE 和RMSE 越小,表示预测评分与真实评分之间的差距越小,即推荐精度越高。
3.4 参数校正
融入景点标签的矩阵分解个性化推荐算法中需要确定的参数有步长α和正则化参数λ。为确定算法的最优参数,本文采用控制变量法得到最终参数组合。
在本文实验过程中,首先利用经验将步长α设置为0.01,观察正则化参数λ对实验结果的影响。本文首先通过实验确定λ的大致取值范围,然后通过不断细化的方式确定λ的最终取值,最终结果如表1 所示。

Table 1 MAE and RMSE under different values of λ表1 λ 不同取值下的MAE 与RMSE
由表1 可知,当λ=0.002 时,MAE 和RMSE 的平均值最小,故在实验中λ取0.002。
在确定了λ的取值后,为了选取合适的α取值,继续观察α不同取值下对实验结果的影响,最终结果如表2 所示。

Table 2 MAE and RMSE under different values of α表2 α 不同取值下的MAE 与RMSE
由表2 可知,当α=0.01 时,MAE 和RMSE 的平均值最小。因此,融入景点标签的矩阵分解个性化推荐算法α、λ的最优取值组合为{0.01,0.002} 。
3.5 结果对比及分析
矩阵分解是基于模型的协同过滤算法,为验证本文所提出算法的性能,本文选择以下方法进行景点推荐结果比较。
算法1 基于用户的协同过滤景点推荐:该算法首先利用用户的历史旅游数据得到用户对景点的评分值,然后利用用户对景点的评分值计算各用户之间的相似度,最终通过相似用户对景点的评分值预测目标用户对景点的评分值,从而完成景点推荐。
算法2 基于标签的协同过滤景点推荐:该算法为景点构建了景点标签,利用用户对景点的评分值计算用户对标签的评分值,然后利用用户对标签的评分值计算用户之间的相似度,最终利用相似用户对景点的评分值预测目标用户对景点的评分值,从而完成景点推荐。
算法3 融入景点标签的矩阵分解个性化推荐:本文方法。
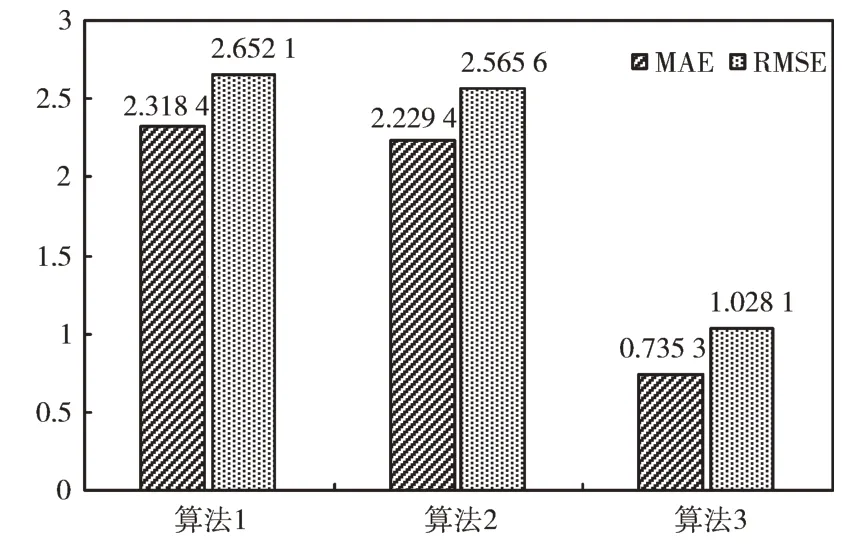
Fig.4 Comparison of experimental results图4 实验结果对比
由图4 实验结果对比可以看出,相比于算法1,算法2的MAE 和RMSE 分别下降了3.84%和3.26%。这表明构建的景点标签能够更加准确地描述景点特征,一定程度上缓解了传统协同过滤算法的数据稀疏性问题。相比于算法1,算法3 的MAE 和RMSE 分别下降了68.28%和61.23%;相比于算法2,算法3 的MAE 和RMSE 分别下降了67.02%和59.93%。这表明相比于仅采用景点评分计算用户对景点标签的评分值,矩阵分解算法能够更加准确地描述用户对景点标签的喜爱程度,本文提出的算法在预测用户对景点评分方面性能更优。
4 结语
本文将景点标签引入矩阵分解推荐算法,在推荐过程中充分考虑景点的实际特征,能够更加准确地反映用户对景点特征的喜爱程度,从而结合景点特征对用户进行景点推荐。实验结果表明,本文方法在预测用户景点评分时明显优于其他算法,能够进一步提高景点推荐算法的性能,从而为用户推荐更加符合其爱好的景点。
同时,融合景点标签的矩阵分解个性化推荐方法研究还需进一步提高,可以加入景点标签的自动化构建,使景点标签更加准确,从而提高算法计算精度。
