Kafka 与HBase 在健康监测大数据平台中的应用研究
2021-04-23王勇,张跃
王 勇,张 跃
(北京工业大学信息学部,北京 100124)
0 引言
大数据时代带给社会的不仅仅是数据变大、资源增多,更有思维模式改变以及随之而来的数据处理技术不断创新、数据利用能力飞速发展。健康大数据技术应用和发展已作为国家重大战略付诸实施[1]。相关研究有:Abderrazak 等[2]将hadoop 框架以及开源相关组件应用于仓储问题,提高医疗数据的仓储性能,对健康数据平台建设具有一定的借鉴意义,缺点是不太符合健康监测数据特点;文献[3]利用HBase 和Phoenix 构建高性能的健康监测大数据平台,并对平台读写性能进行优化,然而其未对数据采集传输和发布共享进行研究;文献[4-5]分别研究了适合健康监测大数据的接入协议和发布协议,为健康监测数据采集和发布共享提供了思路,但仍需要在具体实施中进一步验证。
大规模健康监测数据的采集存储和共享利用仍然存在很多问题,本文详细研究了Kafka[6]、HBase[7]等大数据相关技术,实现一款面向用户健康服务的、可扩展的健康监测大数据处理平台,有效解决健康监测数据生态系统中大规模数据的采集传输、存储以及发布共享问题,填补了研究空白。通过研究HBase 组织与存储模式,设计出适合存储健康监测大数据的HBase 存储模型。对Kafka 分布式消息中间件的发布订阅模式进行研究,实现健康监测大数据的采集传输与发布共享架构。引入Kafka 作为架构中枢,不仅能屏蔽数据源的异构型,保证各个服务模块之间高内聚、低耦合,还能使数据通道变得简单,减轻下游数据库系统的压力,提高系统扩展性。
1 健康监测大数据平台设计
健康监测大数据理想化状态是:由健康监测设备产生的数据,通过数据采集接口传入数据中心进行集中存储,利用健康监测大数据平台提供的数据发布接口获取平台数据,实现数据共享,经过分析与处理后的数据也可通过数据发布接口发送给用户。
如图1 所示,健康监测大数据平台系统架构包括应用平台和支撑平台,应用平台主要实现数据应用,如数据分析和挖掘,数据发布是将最终的分析结果以及相关数据共享给用户;在支撑平台中,有分布式数据采集传输模块与存储模块,分布式数据采集传输模块对不同来源的健康监测数据进行采集和传输,存储模块主要实现数据持久化,负责将数据高效存储在大数据集群上,为数据应用提供支持。
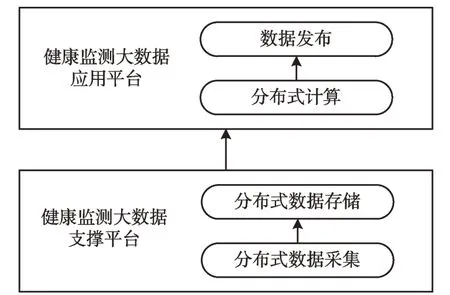
Fig.1 Health monitoring big data platform architecture model图1 健康监测大数据平台架构模型
1.1 Kafka 与数据采集传输
Apache Kafka 是Hadoop 生态系统中的一个工具,用于处理事务日志和其它实时数据。Kafka 是一个流媒体平台,能够以发布/订阅的形式传递流数据[8]。在发布—订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者,消息被持久化到一个topic 中,消费者可以订阅一个或多个topic 并消费该topic 中所有的数据,其体系结构如图2 所示。
健康监测大数据平台需要实时将采集到的健康监测数据信息存入数据中心进行持久化存储,当信息采集平台将这些变化的数据信息写入或更新到数据库时,数据库产生很大的压力,对数据采集系统性能提出了很高要求。利用kafka 分布式、高吞吐、基于发布/订阅的特性,可在廉价的PC Server 上搭建大规模的消息系统[9]。
Kafka Connect 是一种用于在Kafka 和其它系统之间可扩展、可靠的流式传输数据工具,使用它能快速将大量数据集移入和移出Kafka 连接器。Kafka Connect 可获取整个数据库,或从所有应用程序服务器收集指标数据到Kafka 主题,使数据用于流处理。导出作业可将数据从Kafka topic 传输到二次存储或查询系统,或传递到批处理系统进行离线分析。Kafka 数据采集与传输模型如图3 所示。

Fig.2 Kafka architecture图2 Kafka 体系结构

Fig.3 Kafka data acquisition and transmission model图3 Kafka 数据采集与传输模型
1.2 HBase 与数据存储
系统使用Hadoop 体系中的HBase 组件对数据进行持久化存储。HBase 是一个使用key/value 键值对的基于列存储的数据库,支持海量数据的高效存储,存储的数据具有稀疏性[10]。
HBase 表的索引称为RowKey 行关键字,RowKey 必须具备唯一性,一般为标志性信息和时间戳组合。Rowkey 长度不宜过长,还应尽量保证散列[11]。本文将健康档案编号或身份证号加入rowkey,健康档案编号或身份证号具有一定的随机性,能够保证rowkey 设计均匀分布在各个Region中。与此同时还要考虑集群查询性能,查询都是基于某个用户的时间序列,本文设计rowkey 的id+时间戳timestamp作为rowkey,用户的信息就会连续存储在一起,查询效率自然提高。
Hbase 的列族也是越少越好,因为Hbase 的列族在内存结构中是一个cf 对应一个store 区域,数据量大的storefile 自然会多,在查询多列族数据时需要跨文件访问数据内容,合并任务自然增多,会降低性能。
基于以上原则,根据中华人民共和国卫生部批准的《城乡居民健康档案基本数据集》[12]建立Hbase 健康监测数据模型,如表1 所示。
健康监测数据包括用户的基础数据、生理数据、运动数据、睡眠数据、环境数据等[13]。HBase 存储模型将这些数据分成基础数据(baseInfo)和健康数据(healthData)两个列族进行存储。基础数据包括身份证号、姓名、性别、年龄、出生日期,健康数据包括身高、体重、体温、血糖、血氧、血压、心率、计步、睡眠质量等数据。

Table 1 HBase storage model of health monitoring data表1 健康监测数据HBase 存储模型
1.3 数据发布与共享
为有效实现健康监测数据利用与共享,健康监测大数据平台可以提供两种数据发布与共享服务:①健康监测数据查询服务;②健康状态监测服务[5]。
1.3.1 健康监测数据查询服务
健康监测大数据平台提供健康监测数据查询服务,其它基于本平台的应用通过客户端主动向健康监测大数据平台服务器发送查询请求消息。健康监测大数据平台使用Kafka 作为健康监测数据采集与发布的媒介,实现健康监测数据查询接口,其交互模型如图4 所示。

Fig.4 Interaction model of health monitoring data query service图4 健康监测数据查询服务交互模型
在Kafka 中,创建专门用于发送和接收查询消息的主题Topic1,第三方数据应用平台通过<table,query-filter,topic>组成的元组向Topic1 发送查询消息,其中table 为想要查询的HBase 表,query-filter 为查询过滤器,topic 为查询结果返回的目标主题。当与Topic1 相对应的消息到达时,查询处理器处理这些消息,然后到指定的table 按照query-filter 过滤出想要的数据,将数据封装成消息返回到指定的topic,第三方数据应用平台获取这些消息,得到想要的查询结果。
HBase 查询实现方式:①按指定RowKey 获取唯一一条记录的get 方法;②按指定条件获取一批记录的scan 方法。对于个人基本信息数据等全量数据表,使用get 方法,而对于基于时间序列采样的健康监测数据则采用scan 方法查询较为方便。
一般基于时间序列采样的健康监测数据,本文的Rowkey 设计为身份证号或健康档案编号+时间戳形式,这样可将查询接口中的Key 和startTime、endTime 值拼接起来形成Rowkey 的startRow 和stopRow,便于在HBase 表中查询相应结果。而对于全量的数据信息表,如个人信息数据表,Rowkey 直接设计为身份证号,这样查询条件中的time可以为空,Key 可直接作为RowKey 进行查询,查询接口设计如表2 所示。
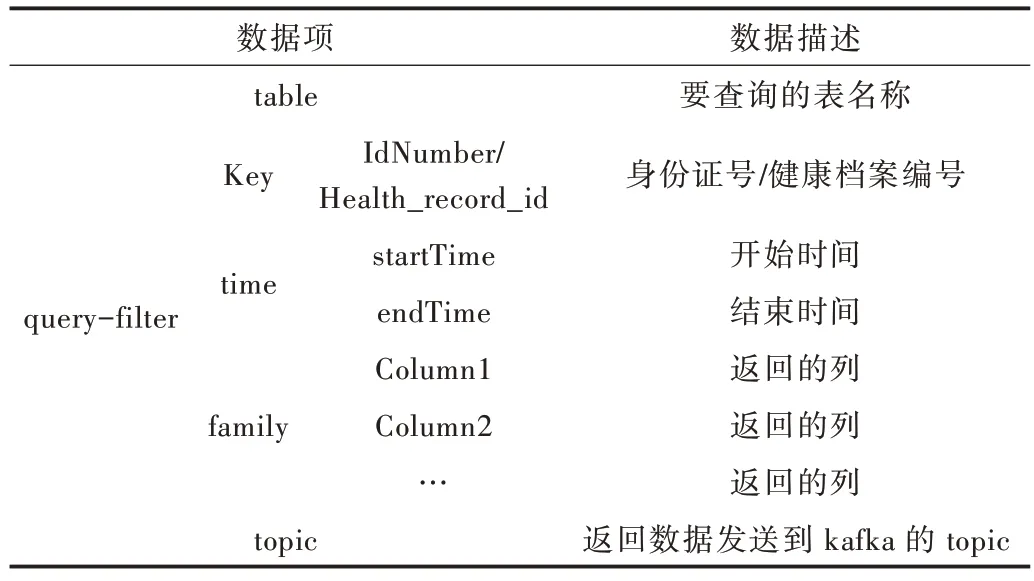
Table 2 Health monitoring data query interface表2 健康监测数据查询接口
1.3.2 健康状态监测服务
健康监测大数据平台还主动提供健康状态监测服务,健康监测大数据平台可整合平台采集存储的数据,将血压、体温、血糖等健康状况异常情况及时发送到健康监测类设备,以供用户了解异常状况,供决策时参考。使用Kafka 作为健康状态监测服务发布媒介,其交互模型如图5 所示。

Fig.5 Interaction model of health monitoring service图5 健康状态监测服务交互模型
当健康状况监测模块发现健康状态异常时,健康状况监测模块生成一个告警命令报文,并将监测结果封装成告警消息发送到Kafka 对应的Topic。用户事先订阅该Topic,当告警消息到达时可以实时获取该消息。
2 健康监测大数据平台实现
2.1 Source Connector 实现
Kafka Connect 是一种传输数据工具,主要用于Kafka分布式消息系统与其它系统进行数据传输,分为Source-Connector 与SinkConnector。其中SourceConnector 用于将整个数据库或从应用程序服务器收集的指标导入到Kafka主题,而SinkConnector 与之相反,是从Kafka 主题导出数据到其它系统[14]。
开发Connector 主要是实现两个接口Connector 和Task,若是开发 Source,只要实现 SourceConnector 和SourceTask 两个接口。比如把文件的数据读取到kafka 中,SourceTask 会读取文件的每一行并把它们封装为List<SourceRecord>发送出去。实现SourceConnector 开发的时序如图6 所示。
2.2 Sink Connector 实现

Fig.6 Timing diagram of SourceConnector development图6 SourceConnector 开发时序图
Sink Connector 就是把Kafka 中的数据导入到第三方系统中,比如读取到HDFS、hbase 等,本文设计并实现的SinkConnector 主要是HBase。SinkConnector 的开发与SourceConnector 类似,不同点在于SourceTask 使用poll 接口,而SinkTask 使用put 接口。SinkTask 的put()方法接收集合Collection<SinkRecord>存储到HBase 中。
2.3 健康监测数据查询服务实现
HBase 中的数据表通过划分成一个个Region 实现数据分片,每一个Region 关联一个RowKey 的范围区间,数据按RowKey 的字典顺序进行组织。正是基于这种设计使得HBase 能够轻松应对这类查询:“指定一个RowKey 范围区间,获取该区间的所有记录”。如查询健康档案号为116755244009,日期从20171001 到20191001 的健康监测数据表,healthData 列族中的Blood_pressure 列示例代码如下:

2.4 查询效率优化
HBase 非键列查询效率非常低,因为在查询操作中要扫描整个表。为提高检索效率,引入二级索引机制[15]。实验结果表明,经过优化后的查询性能能够充分满足数据发布服务需要。二级索引原理如图7 所示。
图7 中,二级索引的本质就是建立各列值与行键之间的映射关系[16]。要对F:C1 列建立索引时,只需建立F:C1各列值到其对应的RowKey 映射关系。查询符合F:C1=C11,对应的F:C2 列值步骤如下:①根据C1=C11 得到索引数据查找对应的RK1;②得到RK1 后再根据RK1 在主表中查询C2 的值。
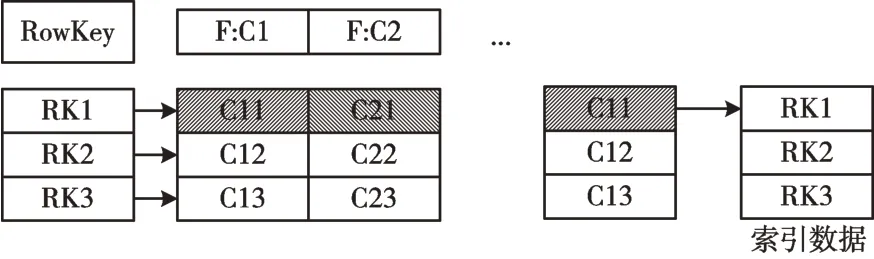
Fig.7 Design idea of HBase secondary index图7 HBase 二级索引设计思路
二级索引表建立和探测数据主表过程如表3 所示。
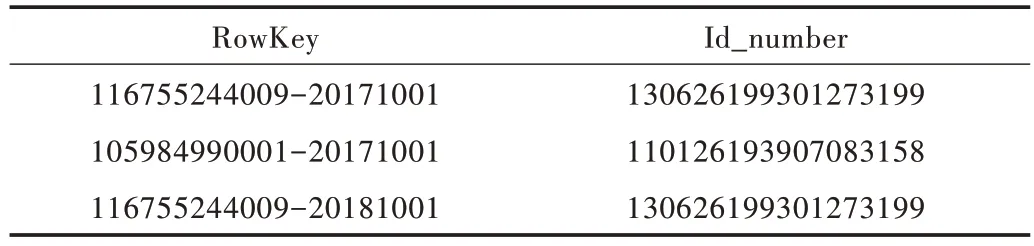
Table 3 Health monitoring data表3 健康监测数据
从表3 数据查询Id_number 列,构建的二级索引表如表4 所示。

Table 4 Secondary index表4 二级索引
客户端发出请求,首先查询二级索引表,从表4 获取相应的Rowkey,然后根据主表中的Rowkey 查询相应的数据记录,详细流程如图8 所示。
3 平台搭建与实验
3.1 运行环境
3.1.1 硬件环境
本文利用两台服务器划分为4 个虚拟机节点搭建系统运行环境。每个虚拟节点配置为:CPU:2.40GHz;内存:4.0G;硬盘:200GB。具体分布如表5 所示。
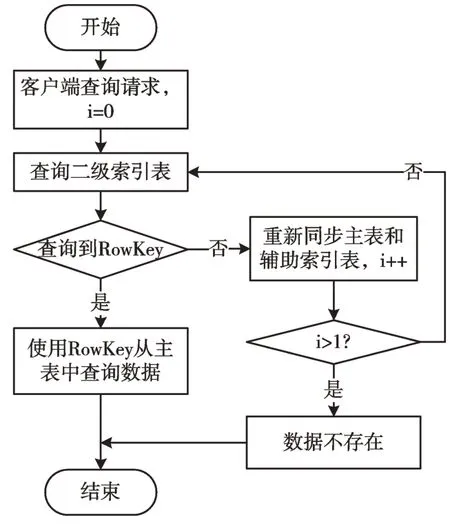
Fig.8 Query flow using secondary index table图8 使用二级索引表查询流程

Table 5 Distribution of cluster system operating environment表5 集群系统运行环境分布
3.1.2 软件环境
系统软件环境及版本如表6 所示。

Table 6 System software environment and version表6 系统软件环境及版本
3.2 系统测试
基于Kafka 和HBase 的健康监测大数据平台系统性能主要考虑健康监测数据的采集传输能力和健康监测数据的查询能力,系统性能测试与优化重点是Apache Kafka 分布式消息队列的吞吐量与HBase 数据库查询效能。
3.2.1 Kafka 分布式消息队列性能测试
将存储在文件中的数据作为数据源,HBase 作为数据持久化存储获取数据。利用Kafka 提供的性能测试工具kafka-producer-perf-test.sh 和kafka-consumer-perf-test.sh脚本对Kafka 的生产者和消费者吞吐速率进行测试。为充分挖掘Kafka 系统性能,结合本平台测试环境设置相关参数如表7 所示。
一般而言,增大批次有利于增加吞吐量(减少了网络IO 次数),但过于增大批次带来的好处无法抵消压缩时间的增长,吞吐率就会降低。分区数决定了Kafka 的并行度,分区数一般是broker 的整数倍。

Table 7 Kafka related parameter settings表7 Kafka 相关参数设置
单线程吞吐量显然是有限的,并没有完全利用Kafka集群的高吞吐量,因此采用多线程进行并发读写对此进行优化。对线程数与吞吐率的关系进行测试,结果如图9 所示。
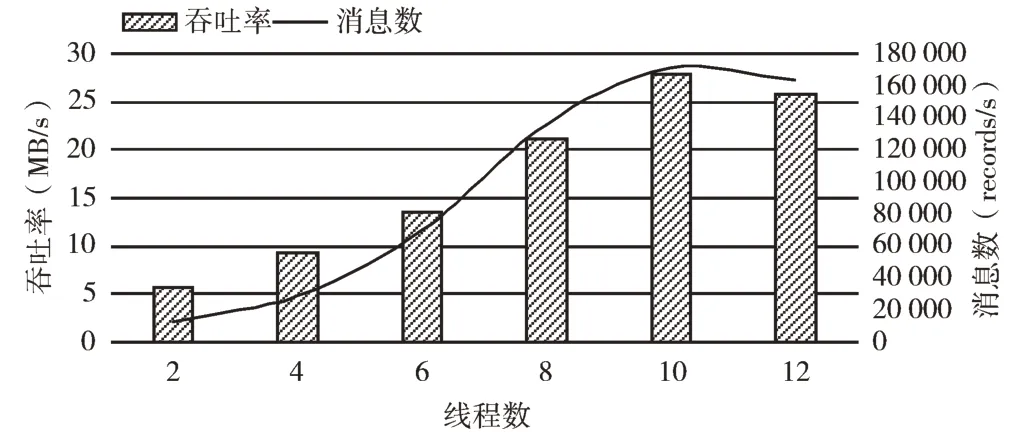
Fig.9 Relationship between thread number and throughput rate图9 线程数与吞吐率关系
优化以后,使用10 个线程写,系统随着线程数的增加吞吐率显著提升到27MB/s 左右,消息数达17 万条/s 以上,可见使用批处理或多线程对提升吞吐率效果明显。
3.2.2 HBase 数据库性能测试
采用HBase 统一的JavaAPI 接口对HBase 数据查询性能进行测试,图10 为采用二级索引前后的查询响应时间对比结果。查询条件为非RowKey,查询数据量从2~12万条记录不等。实验结果显示,二级索引的建立能够使非索引数据的查询响应时间缩短近3 倍。
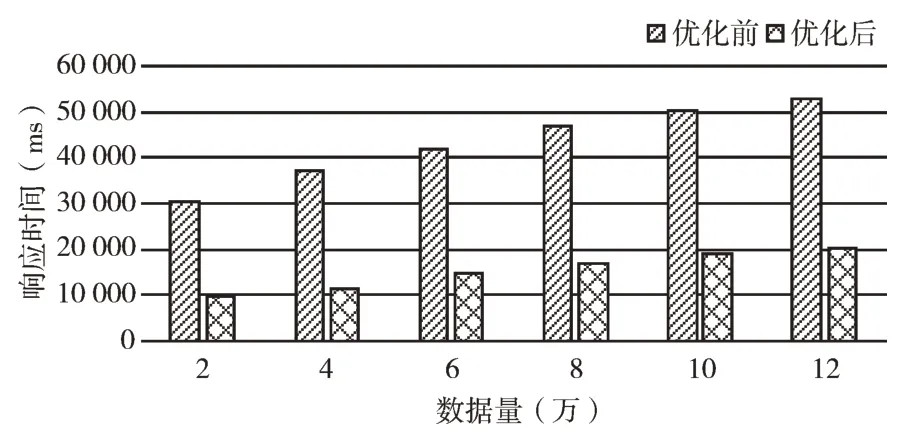
Fig.10 Comparison of query response time before and after optimization图10 优化前后查询响应时间对比
4 结语
本文基于Kafka 分布式消息系统,结合HBase 分布式存储数据库,以解决健康监测数据生态系统中“信息孤岛”问题为出发点,通过开发Kafka Connector 初步形成一个高可靠的健康监测大数据平台。首先研究了Kafka 和HBase在健康监测数据平台建设中的应用,设计了健康监测数据的采集传输、共享架构以及存储模型。然后调整集群设置和参数配置,对查询效率进行优化,以达到平台最佳性能。实验结果表明,总的吞吐量取决于代理节点的数量、数据的主题分区数量以及生产消费消息的节点数量。通常情况下增加分区可以提高Kafka 集群的吞吐量,然而分区过多会增加无效及延迟风险,采用批处理或者多线程都有利于增加吞吐量,但是线程数一般应不大于分区数。建立二级索引是应对HBase 非RowKey 查询的有效方式。本文针对健康监测数据存储特点建立二级索引,能有效提升查询响应速度。
本文研究了大数据关键技术在健康监测数据平台中的应用。要实现生产环境大规模集群的有效配置,需要考虑核心节点数量。随着数据量和组件数量的增加,节点之间的网络带宽或将成为瓶颈。由于健康监测数据本身的复杂性以及HBase 的局限性,要提升复杂查询效率还需进一步研究。
