改进TextRank 的文本关键词提取算法
2021-04-23王俊玲
王俊玲
(山东科技大学计算机科学与工程学院,山东青岛 266500)
0 引言
关键词提取(Keyword Extraction,KE)是指使用一个词或多个词对文本内容进行高度总结与概括,在文本摘要[1]和文本分类[2]中都发挥着重要作用。随着社交网络的发展及用户数量的急剧增加,每天都产生大量需要处理的文本信息。面对海量信息进行处理与分析,如果能够准确提取文本内容的关键词,即能很好地对文本进行分析与概括,从而节省大量时间,提高效率。
随着研究的不断深入,传统人工方法已经无法满足用户需要。传统方法效率低下,实现过程复杂,无法很好地展现文本关键信息,因此对算法进行改进,找到更简单、便捷的方法成为研究热点。本文提出一种改进的TextRank[3]算法,将传统按句子划分的方法转变成按照部分进行划分,并结合图的概念,在每个部分中构建关键词图,最后根据设定的评价指标进行关键词提取打分,确定最终关键词,本文算法适应于较长的文本。
1 相关工作
关键词提取方法主要分为两类:有监督和无监督的提取方法。利用有监督方法提取关键词的步骤可概括为原始数据收集、文本预处理、数据集构建、特征构建、模型分类及对其进行评估。有监督方法包括基于传统机器学习的方法,如Frank 等[4]提出的KEA3 方法使用朴素贝叶斯模型(Naive Bayes,NB)对候选词进行了分类;Turney[5]在关键词提取任务中对比了遗传算法与C4.5 决策树的效果;Wang等[6]采用支持向量机(Support Vector Machine,SVM)筛选关键词,使用的特征包括单词的词频与位置信息。后来人们对该方法进行了改进,如Turney[7]在NB 模型中加入点互信息(Point-wise Mutual Information,PMI),该方法提高了关键词提取准确率,但忽略了上下文语境。
利用无监督方法提取关键词的步骤可概括为原始数据收集、文本预处理、候选词集合确定、候选词排序以及评价打分确定最终关键词。无监督方法又可细分为:①基于简单统计的方法。其对候选词的一些特定指标进行统计,根据统计结果对候选词进行排序,如使用N-gram[8]、TFIDF[9]、词频[10]、词共现、词性、词的位置等属性为指标设置不同权重,该方法的优势在于应用简单、计算量小,但其只能涵盖单词表层信息,很难发现单词之间深层次的联系;②基于图的方法。该方法中有3 个要素,分别是节点、节点间的连接规则、节点间权重计算方法,其中的典型代表是TextRank,此后又出现了SingleRank、SGRank、Position-Rank、TopicRank 等模型方法。基于图的方法可体现候选关键词之间的联系,缺点是准确率有限且不适用于较短文本。
本文算法对原有的TextRank 算法进行改进,将传统按句子划分的方法转变成将文本分成几部分,在每个部分构建关键词图,最后根据相应评价指标进行综合打分,确定最终关键词。
2 改进的TextRank 算法
TextRank 算法用一个有向加权图G=(V,E)表示TextRank 普通模型,由点集合V 与边集合E 组成,E 为V×V 的子集。用Wij表示任意两点Vi、Vj之间边的权重,对于一个给定的点Vi,ln(Vi)表示指向该点的点集。
2.1 文本划分
首先根据给出的文本T 进行划分,由于传统的TextRank 算法以句子为单位进行划分,使得句子与句子之间的联系被割裂,所以本文的划分不是以句子为单位,而是根据文本长度划分成相应的部分,每一部分P 由若干个句子Si组成,且每一部分的字数大体相同。分段公式为:

其中,P 为部分数量,Z 为单词数量,S 为句子数量。
2.2 文本预处理
在已划分好的部分进行分词与词性标注处理,并对文本中的信息进行过滤。因为文本中包含了许多无用信息,需要对文本作进一步处理,从数据集中去除无意义的符号、停用词等,从而提取出有效关键字。预处理步骤如下:
(1)删除无意义的符号。有些数据集,例如在某话题讨论中经常出现“#”等符号,在转发该信息时就会将此符号带上,这意味着任意用户分享过程中将包含转发符号及字段。这些转发符号对关键字提取没有任何意义,并且起到噪声的作用。因此,这些无意义的符号都将被删除。
(2)停用词删除。创建一个标准的停用词列表,然后将这些停止词从集合中删除。
(3)移除不重要的单词。数据集中有很多单词相对不重要,是关键词的概率较小,因此本文建立一种机制识别与删除这些相对不重要的单词,即小于平均出现频率的单词将从候选关键词集合中删除,使其不会在关键字提取阶段相互竞争,从而提高了关键词提取效率。
2.3 关键词图构建
G(V,E)中V 代表图的节点(候选关键词),E 代表节点之间的共现关系边,使用滑动窗口确定节点之间的联系,一般设计滑动窗口大小为2~10。如果两个词在滑动窗口中出现共现关系,则两个词之间建立联系且赋值为1,若再次出现共现关系则其值再加1,最后构造出每一部分的关键词图,如图1 所示。
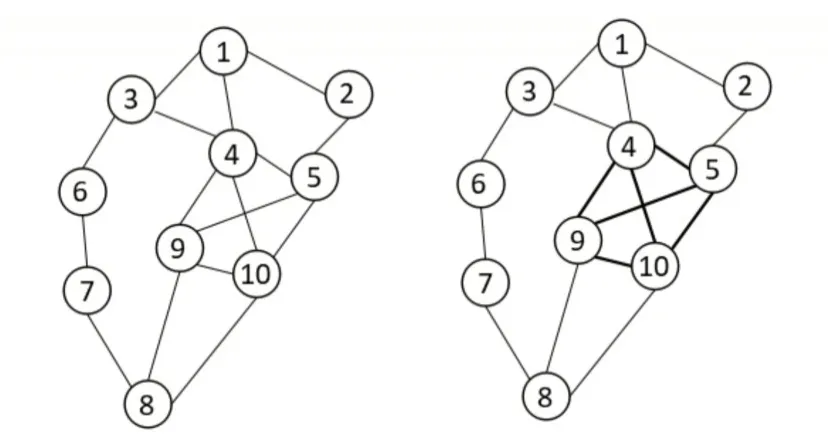
Fig.1 Keyword map图1 关键词图
将图中节点按照所连接边的数量由大到小进行排序,选取连接边数最多的前30%的节点作为该部分关键词。如果出现相同节点连接的边数相同,则比较共现值大小,选择共现值较大的节点,最终得到一个部分的关键词。其余部分关键词图的构成相同,最终确定N 个关键词图,将从这N 个关键词图提取出来的关键词放在一起比较,结果如表1 所示。
在表1 中,Financial crisis、America、financial industry、the whole world、financial market 几个关键词出现频率最高,而且在这几个词中,Financial crisis、the whole world 为名词。从表中可以看出,名词、动词、形容词出现频率最高,所以在提取关键词时,名词、动词和形容词是需要提取的重要单词。

Table 1 Comparison of extracted keywords表1 提取关键词比较
2.4 特征提取与单词评分
由于每个节点的重要性取决于多种因素,计算节点权重的参数如下:
定义1 词频(CP):表示节点Vi的词频,即该单词出现次数占所有单词的百分比。
定义2 词长度(CC):关键词中的单词个数,如financial industry,其词长度为2。单词个数评分如表2 所示。

Table 2 Word number score表2 单词个数评分
定义3 单词位置(CW):单词在每部分出现位置不同,有的在开头,有的在中间,有的在结尾。根据单词出现位置的不同给予不同分数,具体评分情况如表3 所示。
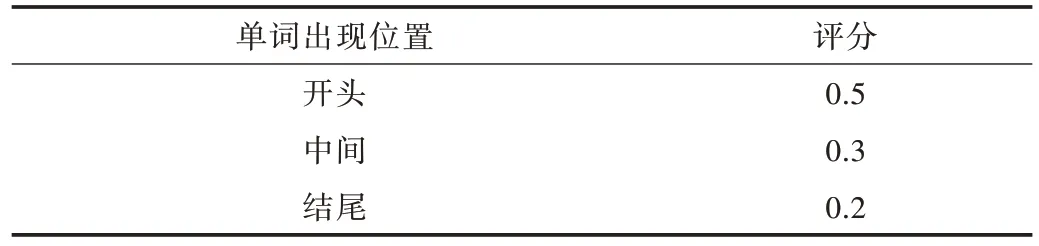
Table 3 Word position score表3 单词位置评分
定义4 词性(CX):即选出的单词是名词、动词、形容词、副词或其他。由于在一段文本中,经过滤后剩下的词多为名词、动词、形容词等,根据词性的重要程度对其进行打分。词性的评分情况如表4 所示。

Table 4 Part of speech score表4 词性评分
定义5 单词最终得分Score:一个单词的整体性得分是提取关键词的最终指标。本文假设以上所有因素的乘积对文档中的单词有重要影响,且在这些因素中词性的影响比其他影响大,并且通过实验验证了所提出评分函数的有效性。因此,定义候选关键词(节点)的最终得分为:
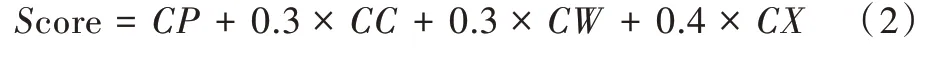
3 实验与分析
本实验采用3 个基准数据集Hulth2003、Krapivin2009和Semeval2010,3 个数据集中包括训练集和测试集。由于本文不需要进行训练,因此采用测试集进行实验。由文献[11]可知,3 个数据集在窗口大小为2 以及对文本进行预处理的实验中效果最好,因此设置本文滑动窗口大小为2。相关数据集信息如表5 所示。

Table 5 Dataset description表5 数据集描述
为验证本文算法在关键词提取方面的性能,本文采用准确率(PR)、召回率(RR)、F-Measure(F)作为关键词提取评价指标。准确率、召回率、F-Measure(F)计算公式分别如下:

式中,nm表示算法提取的关键词与人工给定关键词相匹配的个数,na为算法提取的总关键词数量,nu为人工给出的关键词数量。
实验1:关键词提取数量对本文算法的影响。本文以Krapivin2009 数据集为例,从基准数据集中提取K 个关键词,K 的范围为20~34(Krapivin2009 文档平均关键词为27),使用准确率、召回率和F 值3 个评价指标比较不同K 值对关键词提取效果的影响。实验结果如表6 所示。
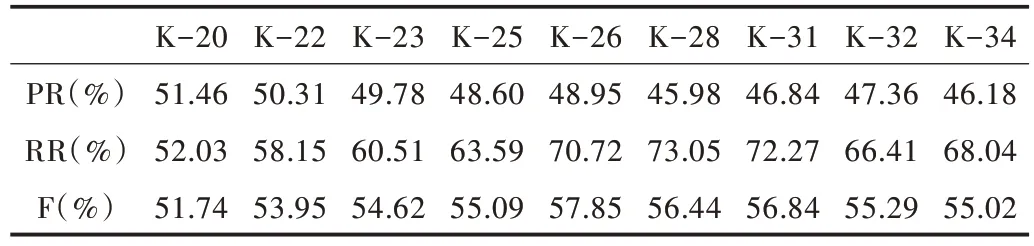
Table 6 The influence of the number of keywords extracted on the algorithm in this paper表6 关键词提取数量对本文算法的影响
从表6 的实验结果可以看出,随着关键词数量的增加,本文算法的准确率不断下降,召回率不断上升,F 值先增加后减小,在关键词数量为26 时达到最大值。因此,对于该数据集而言,当关键词数量为26 时,本文算法性能最好。
实验2:文本长度对本文算法的影响。为了验证本文算法在提取长文本方面的性能,本文从基准数据集中筛选出平均长度分别为500、1 000、2 000、3 000、5 000、6 000 的文档各100 篇,构建6 个测试数据集,分别记为C1、C2、C3、C4、C5、C6。采用本文算法和TextRank 算法进行性能对比实验,本文提取了6 个数据集中共26 个关键词,并计算准确率、召回率和F 值。实验结果如表7 所示。
从表7 可以看出,随着文本长度的增加,本文算法与TextRank 算法的各项指标都在下降。从变化速度来看,TextRank 的下降速度明显加快。为了更清楚地表示文本长度与关键词提取算法之间的关系,本文给出了采用两种关键词提取算法随着文本长度增加的F 值变化曲线,如图2所示。其中,定义横坐标为文档长度,纵坐标为F 值。

Table 7 Influence of text length on algorithm表7 文本长度对算法的影响
从图2 可以看出,在文本长度<2 000 时,TextRank 算法的关键词提取效果优于本文算法。但随着文本长度不断增加,本文算法效果开始优于TextRank 算法。
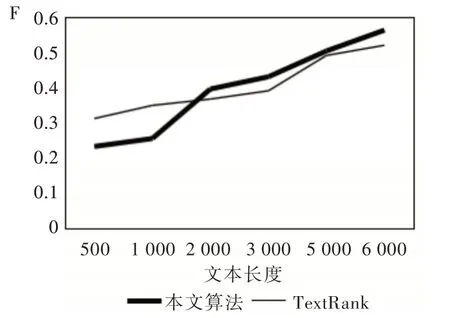
Fig.2 F change graph图2 F 值变化曲线
实验3:本文算法与TextRank 算法的关键词提取性能对比。将本文算法与TextRank 算法在Hulth2003、Krapivin2009 和Semeval2010 3 个数据集上进行关键词性能对比实验,并分别计算准确率、召回率和F 值,实验结果如表8所示。

Table 8 Comparison between this algorithm and TextRank algorithm表8 本文算法与TextRank 算法对比
通过实验可以看出,本文算法的关键词提取性能明显优于TextRank 算法。
4 结语
关键词提取是文本研究的重要任务。本文针对较长的文本提取关键词改进了TextRank 算法,该算法由文本划分、文本预处理、关键词图构建、特征提取与单词评分4 部分组成。通过3 个实验可得出本文算法明显优于原始TextRank 算法。本文算法对于较长文本的关键词提取具有一定优势,但仍然存在不足,比如针对较短文本提取的关键词精确度还不够高。因此,针对较短文本的关键词提取还应作进一步研究,找到一种可适应于各种文本的算法。
