新冠肺炎疫情微博用户情感与主题挖掘的协同模型研究
2021-04-21王晰巍李玥琪刘婷艳
王晰巍,李玥琪,刘婷艳,张 柳
(1. 吉林大学管理学院,长春 130022;2. 吉林大学大数据管理研究中心,长春 130022;3. 吉林大学网络空间治理研究中心,长春 130022;4. 吉林大学东北振兴研究院,长春 130022)
1 引 言
新浪微博作为目前众多社交平台中在线人数及影响力最为广泛的网络社交媒体之一,已经成为用户获取突发事件相关信息及发表个人舆论的主要阵地。2020 年新冠肺炎引起的舆情事件在微博等社交媒体上快速传播,引起全国人民的广泛关注。2020年3 月,国家互联网信息办公室发布了《网络信息内容生态治理规定》,全国网信系统着力加强和创新互联网内容建设。针对此次新冠肺炎疫情期间的舆情事件,及时了解用户在舆情事件中的情感分类及主题特征,有利于更好地帮助舆情管理部门提高网络治理和舆情引导能力,消除社会恐慌,增强抗击疫情的信心,最终达到有效进行网络空间治理的效果。
目前,国外对于突发事件的情感分析研究,主要关注于采用不同的情感分析方法对用户情感进行分类[1-2],计算及分类模型等不同算法的优化和设计[3],以及对突发事件舆情中情感的传播机制和传播网络等进行分析[4]。国内研究主要关注通过划分阶段与主体等不同方面进行情感态势的演化研究,通过构建舆情发展不同时期的情感图谱对情感演化进行可视化展示[5-6],并分析不同主体[7]情感传播的机制及差异性[8],构建情感演化等多种模型对舆情的演变进行分析[9-11]等。从国内外现有学者的研究成果来看,现有研究主要是通过舆情热点事件先确定文本的主题内容,再对主题进行情感分类。对于新冠肺炎疫情这一突发重大公共卫生事件的期间所引发的大量舆情,如何进行主题情感和主题内容挖掘的关联性分析的研究成果相对较少。
本文主要研究以下三个方面的内容:①基于认知的情感评价模型理论,构建情感分类与主题挖掘的协同分析模型;②结合构建的情感与主题挖掘协同分析模型,对新冠肺炎疫情期间的典型舆情话题进行舆情周期内的情感和主题特征分析;③结合新冠肺炎舆情周期内的情感分布特征,制定相关的舆情引导策略。本文的理论贡献在于通过构建的情感与主题挖掘协同模型,为新冠肺炎疫情期间典型舆情话题的情感与主题挖掘的关联分析提供分析案例;本文的实践价值在于通过对新冠肺炎疫情事件下典型话题的网民情感与主题挖掘模型的实证分析,更好地呈现新冠肺炎期间微博用户的情感及主题的关联特征,为舆情监管部门更好地引导新冠肺炎期间的网络舆情,实现网络生态治理提供一定的参考和借鉴。
2 情感与主题挖掘的协同分析模型
2.1 LDA文本主题分析
潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)是一种基于概率图的三层贝叶斯经典主题模型[12],在微博文本内容主题识别及主题演化过程被多次应用[13-14]。目前,学者们基于研究对象的不同,对LDA 主题模型进行了拓展和改良,最具有代表性的改良LDA 模型包括:基于ATM(Author-Topic Model)的主题建模、Twitter-LDA 主题建模和基于Labeled LDA 的主题建模等。
基于ATM 的主题建模,是通过引入文本的作者信息来指导LDA 主题的生成,较好的解决了微博的稀疏性问题[15]。Twitter-LDA 主题建模,在ATM模型基础上补充了背景模型φB,同时假设用户发布的每个文本仅有一个话题,允许在用户和文本两个层面同时建模。基于Labeled LDA 的主题建模,将微博视为被用户打过标签的文本,利用已经存在的标签资源进行主题挖掘[16]。
另外,也有学者将时间序列引入LDA 模型中,研究随时间序列主题挖掘的模式,如DTM[17]、On-LineLDA[18]等。Sievert 等[36]搭建了一个基于网络的交互式可视化系统LDAvis[19],该系统利用基于Rel‐evance 公式改进的LDA 模型,允许用户通过交互式界面调整,来确定表征特定话题的主题词。
2.2 文本情感倾向性分析
文本情感倾向性分析,主要是对文本内容所暗含的情感倾向及观点、喜好进行检测、分析及挖掘。目前,国内外对文本情感倾向性分析的研究,主要集中在采用无监督的基于情感词典的方法,以及有监督的采用机器学习的方法进行分析。
基于情感词典的分析方法,国外有较为成熟的SentiWordNet 和Inquirer 情感词典,通过计算文本中关键词与情感词典中情感词汇的相似度,结合模糊集的语义模式来计算情感强度[19]。国内常用的情感词典包括:大连理工大学的情感词典[20]、知网情感词典[21]、台湾大学的NTUSD 中文情感极性词典[22]等。但使用情感词典进行情感倾向性分析的研究,依赖于情感词典与研究主题的契合性及情感词典的完善性,对于句子级内容的情感分析容易忽略上下文语境,从而影响最终的情感分类效果。
采用机器学习的方法进行文本内容情感倾向性分析中,Pang 等[23]最先采用朴素贝叶斯、支持向量机以及最大熵学习分类器对电影评论的情感进行分类研究。随着深度学习在自然语言处理领域的普及应用,在采用朴素贝叶斯[24]、SVM(Support Vector Machine)[25]等方式进行情感分类研究的基础上,有学者又提出基于CNN(Convolutional Neural Net‐works)对情感分类的模型[26-27],发现可以更好的结合上下文信息进行有效的短文本分类任务,以及采用深度双向LSTM(Long Short-Term Memory)神经网络模型进行Twitter 及新浪微博文本[28]的情感分析和观点提取等。
2.3 基于认知的情感评价模型
基于认知的情感评价模型,即OCC 模型,是由Ortony、Clore 和Collins 于1988 年在《情感的 认 知结构》一书中提出的,以计算机实现为目的的情感认知理论[29]。其基本原理是根据相应的评价标准将主体对环境诱因作出的反应分为正向情感和负向情感,然后根据评价标准取值的不同配置来确定相应的情感类型[30]。OCC 模型从事件的结果、对象的行为和对象的描述三个角度,共定义了22 种情感类别,通过情感评价标准的树形结构形象全面展示了不同类型的情感[31]。OCC 模型中每一类情感类型的出现都由不同的情感维度值触发。
有研究者已经开始应用OCC 模型进行社会化媒体的情感分类研究。国外学者对OCC 模型在具体人物的情感分类的应用进行了定量分析,并对原本22 种情感分类模型进一步整合[32]。国内学者基于OCC 模型从网民认知角度建立情感规则,采用LSTM 模型进行深度学习对财经微博文本情感分类[33]。也有学者提出,基于OCC 模型和贝叶斯网络的情感句分类方法,通过分析OCC 模型的情感生成规则,实现句子级文本的情感分类[34];还有学者基于OCC 模型,建立了突发自然灾害网络舆情情感规则,采用LSTM 模型对其训练,得到突发灾害事件网络舆情多情感识别模型[32]。以往研究的情感分类过程中的人工标注环节,由于标注过程因人而异,无固定规则可循因,具有较强的随意性。为解决该问题,本文引入OCC 模型建立多任务情感识别模型,OCC 规则的引入使情感样本的标注更具有规范性和一致性,从而减少由标注产生的人工误差。
2.4 情感与主题挖掘的协同分析模型构建
本文构建的情感与主题挖掘协同分析模型如图1 所示,采用情感分类与主题挖掘协同分析方法对舆情事件进行分析。首先对收集到的网民评论数据进行情感分类,得到网民评论数据的不同情感分布;整理得到的不同情感评论文本样本;分别对正向评论样本、负向评论样本及中性评论样本进行主题挖掘,达到情感与主题的协同分析的目的。
在情感分类环节,综合来看,情感词典的分类方法更加依赖于词典的全面性和准确性,而机器学习的方法通过训练集的学习及处理具有更强的准确性和客观性。本文采用目前情感分析机器学习方法中最常用的朴素贝叶斯模型(Naive Bayesian Model,NBM)进行情感分类。NBM 对于文本分类有着独特的优势,在垃圾邮件分类中,准确率可以达到90%以上,并且其原理简单,分类可靠,支持增量式训练;不需要构建情感词典,就能得到分类概率值[35]。本文采用基于认知的情感评价OCC 模型进行情感标注。从事件的结果和对象行为两个角度出发,根据事件演变的结果是否符合期望和事件中对象的行为是否符合用户行为规则,将情感分为正向情感和负向情感[33-34]。
在文本主题挖掘环节,本文采用基于Relevance公式的LDA 文本主题挖掘模型,采用Sievert 等搭建的基于网络的交互式可视化系统LDAvis 进行主题抽取。LDA 主题挖掘中最重要的环节是超参数调整,即主题数K的选取及确定过程。所采用的主题数量设定方式,是将主题建模结果可视化,在二维空间上查看主题距离与交叠程度。LDAvis 工具允许用户通过交互式调整来确定表征特定话题的最有用的词语,从而提高话题的可读性和独立性,本文采用这一方法抽取话题表征词。Relevance 公式为
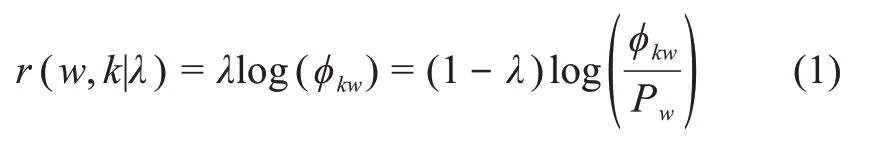
其中,w表示语料库中的词语;k表示话题;Pw表示词语w在话题-词语分布矩阵φ中的边际概率;φkw表示词语w与话题k的相关度;λ是一个在[0, 1]取值的可变参数,λ趋近于0 时,表示话题表征词具有排他性(即在本话题下更独有、更特殊的词与本话题的相关性越强);λ趋近于1 时,表示在本话题下出现次数更多的词,能表征该话题。用户可以通过给定λ值,调节词语w与话题k的相关程度,即r(w,k|λ)[36]。
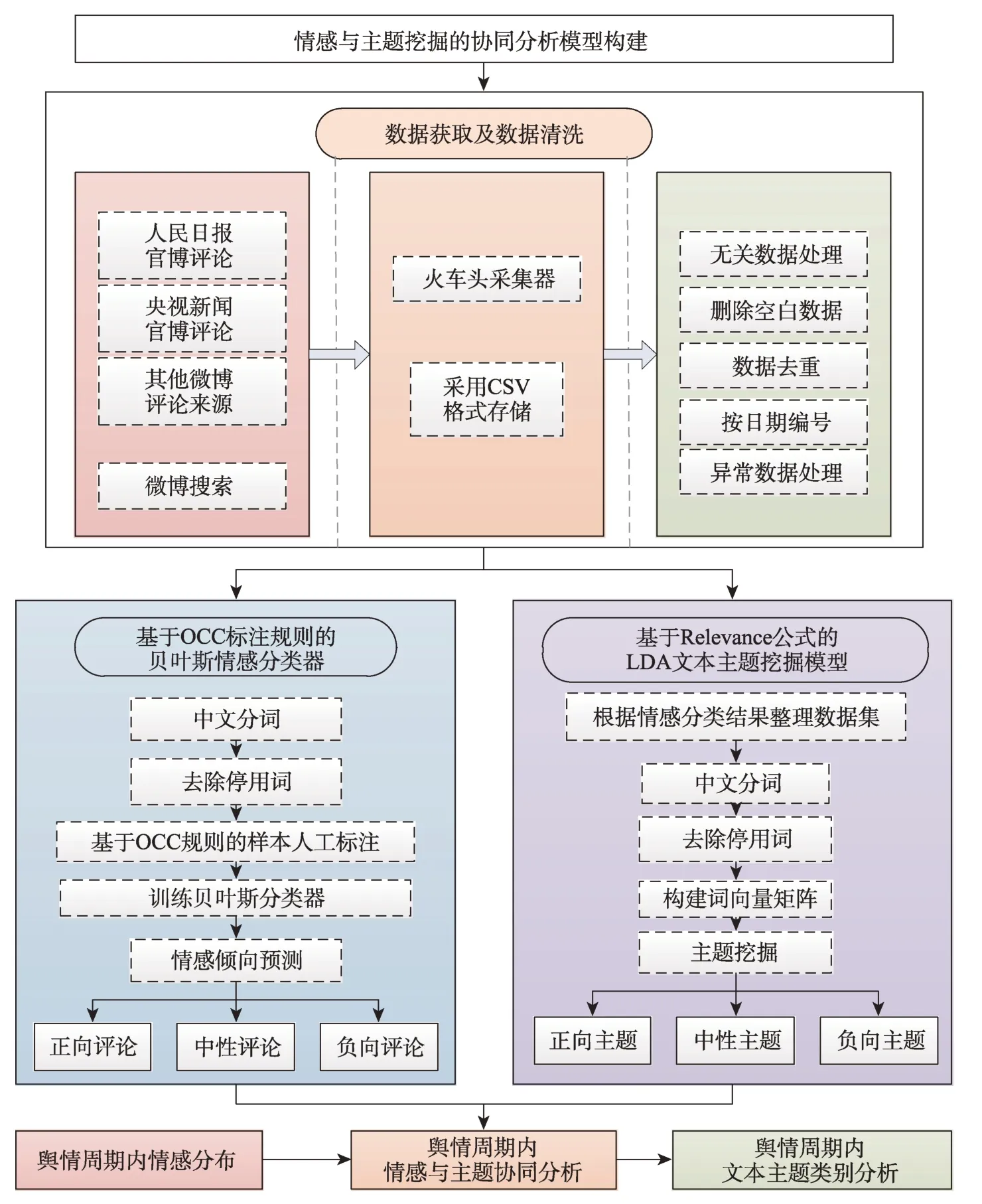
图1 情感与主题挖掘协同分析模型
3 数据采集及处理
3.1 数据源采集
在社交网络综合评价网站Alexa 中,新浪微博是众多平台中在线人数及影响力最为广泛的网络新媒体,具有独特鲜明的传播模式,并逐渐成为各类新闻、热门话题事件的第一发布平台。在新冠肺炎疫情期间舆情话题的选择上,选取了全球新冠肺炎疫情爆发早期公众关注的新浪微博热点事件 “日本钻石公主号邮轮” 作为舆情话题来源。根据百度指数统计数据,该话题讨论度在事件发展高峰期讨论指数达10 万[37],衍生相关话题用户讨论量累积达10 万条[38],因而选择该话题进行舆情分析具有一定的代表性。
采集的数据包括人民日报官方微博、新京报、央视新闻、环球时报、人民网等多家官方媒体,相关微博评论及部分大V 的微博发帖评论信息,共获取微博原文、评论及转发数据共22458 条,在后续研究中使用了正文、评论及转发数据。采用网络爬虫火车头采集器爬虫软件获取用户数据,数据字段包括ID、用户昵称、微博评论内容和转发时间等。在数据处理环节,本文利用火车头脚本编辑器爬虫软件实现海量情感文本的爬取;用户评论以结构化的形式保存在电子表格中;删除缺失数据、无关数据和异常数据,将清洗后的数据用CSV 格式存储;将日期格式转化为计算机程序可以识别的形式,最终获得有效数据21071 条。
3.2 舆情事件周期划分
根据百度指数的统计数据,关键词 “钻石公主号” 邮轮新冠肺炎疫情事件舆情周期为2020 年2 月5 日至2020 年2 月26 日,舆情事件在2020 年2 月19日达到顶峰。根据舆情发展态势大多数学者[39]将舆情周期划分为四阶段[40],结合本次舆情事件特点将舆情周期划分为形成期、扩散期、爆发期和终结期四阶段[41],如图2 所示。在形成期,话题进入网民视野引发热议,但讨论量较低;在舆情扩散期,随着事态发展网民参与范围扩大,话题热度逐渐升高,此阶段网民评论数逐渐增加,并出现大量子话题;爆发期为2 月15 日至2 月19 日,网民评论数、话题热度迅速增加达到顶峰,呈现爆发期的特质;终结期为2 月19 日至2 月26 日,话题热度减退,转发和讨论的信息量骤减,参与的网民数量也逐渐减少,话题逐渐终结,舆情事件消散。
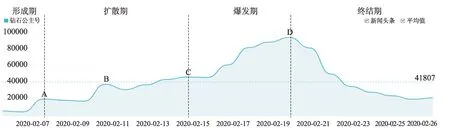
图2 “日本钻石公主号邮轮” 事件舆情生命周期划分图①
4 数据结果
4.1 舆情周期内情感分布
朴素贝叶斯分类器需要预先在训练样本基础上进行训练,以建立分类模型。为此本文选择获得的数据样本中近二分之一的文本信息进行人工标记,用作训练样本,采用两名情报学研究生进行人工标注,一致性比率为72.17%,保留一致性数据作为训练数据,最终获得训练数据7210 条,训练数据样本极性分布如图3 所示。
根据OCC 模型规则,在人工标注过程中,若样本传达正向情感时,则标注为 “+1” ;若样本传达负向情感时,则标注为 “-1” 。在本文所选择的 “日本钻石公主号邮轮” 话题中,如 “希望乘客平安” “希望经验有用” 等事件的结果是符合网民期望的,文本 “不传谣” 是符合行为规则的,可判断以上文本属于正向情感; “外出接触、立可攻击” “交叉感染” 不符合网民期望,此类文本属于负向情感。根据上述规则得到训练数据,对NBM 进行训练,并使用训练后的分类器对全部评论文本的情感进行预测,得到情感分类结果。
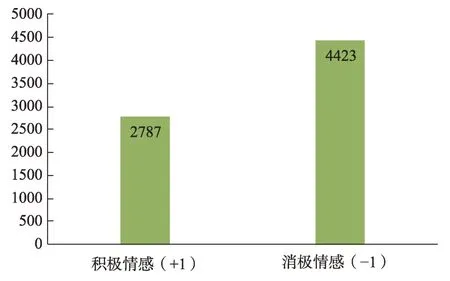
图3 “日本钻石公主号邮轮” 话题训练数据情感极性分布统计
经过训练的分类器,验证性能指标,得到其准确率为0.8342,这说明分类效果较好,与未经OCC规则标注的准确率相比提升了0.0272。结合近年来对网络舆情的情感分类NBM、LSTM、CNN 和SVM 分类方法,本文与其研究结果[32]进行了对比分析,具体结果如表1 所示,证明本次构建的情感分类器具有较好的分类准确率。
为进一步分析文本情感特点,本文依据情感倾向度将情感分为负面情感、中性情感和正面情感,研究各阶段不同类型情感数目占比。以情感数值0~0.4 作为负面情感,0.4~0.6 作为中性情感,0.6~1 作为正面情感[42],分别对四个阶段做统计分析,分析结果如表2 所示。
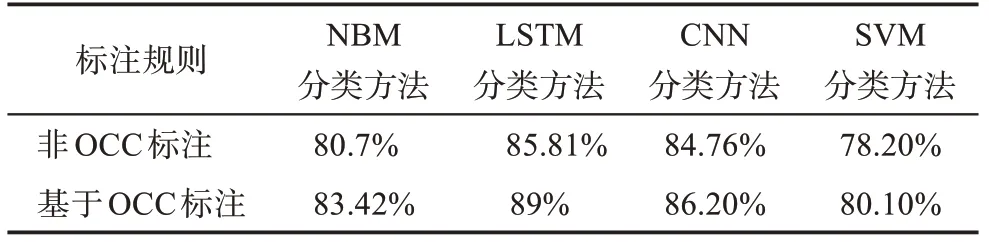
表1 不同分类器准确率比较
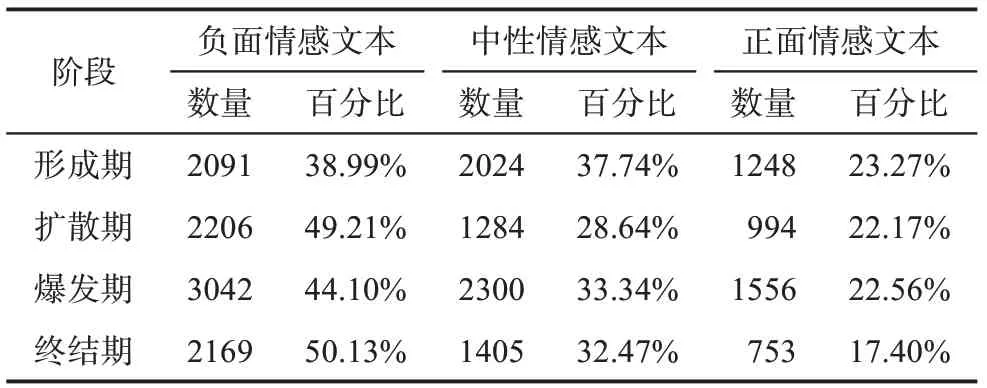
表2 “日本钻石公主号邮轮” 评论文本情感分类统计
舆情周期内情感倾向度分布如图4 所示。结合表2 和图4 的数据分析结果,在 “日本钻石公主号邮轮” 事件发展的全生命周期中,负面评论占比较多,均在40%左右;在终结期负面情感超过了整体情感分布的50%。从数据分析结果来看,正面情感在各个周期占比均很少,在各个周期均占总体评论的25%左右。中性情感倾向占比随事件的发展逐渐变少,在事件发展的形成期及高峰期,中性情感的数据与负面情感数据数量持平。因此,从此次舆情话题事件可以看出,本次事件的整体倾向偏向于负面情感,且在事件发展的尾期用户的负面评论较为激烈,正面情感占比出现低谷。
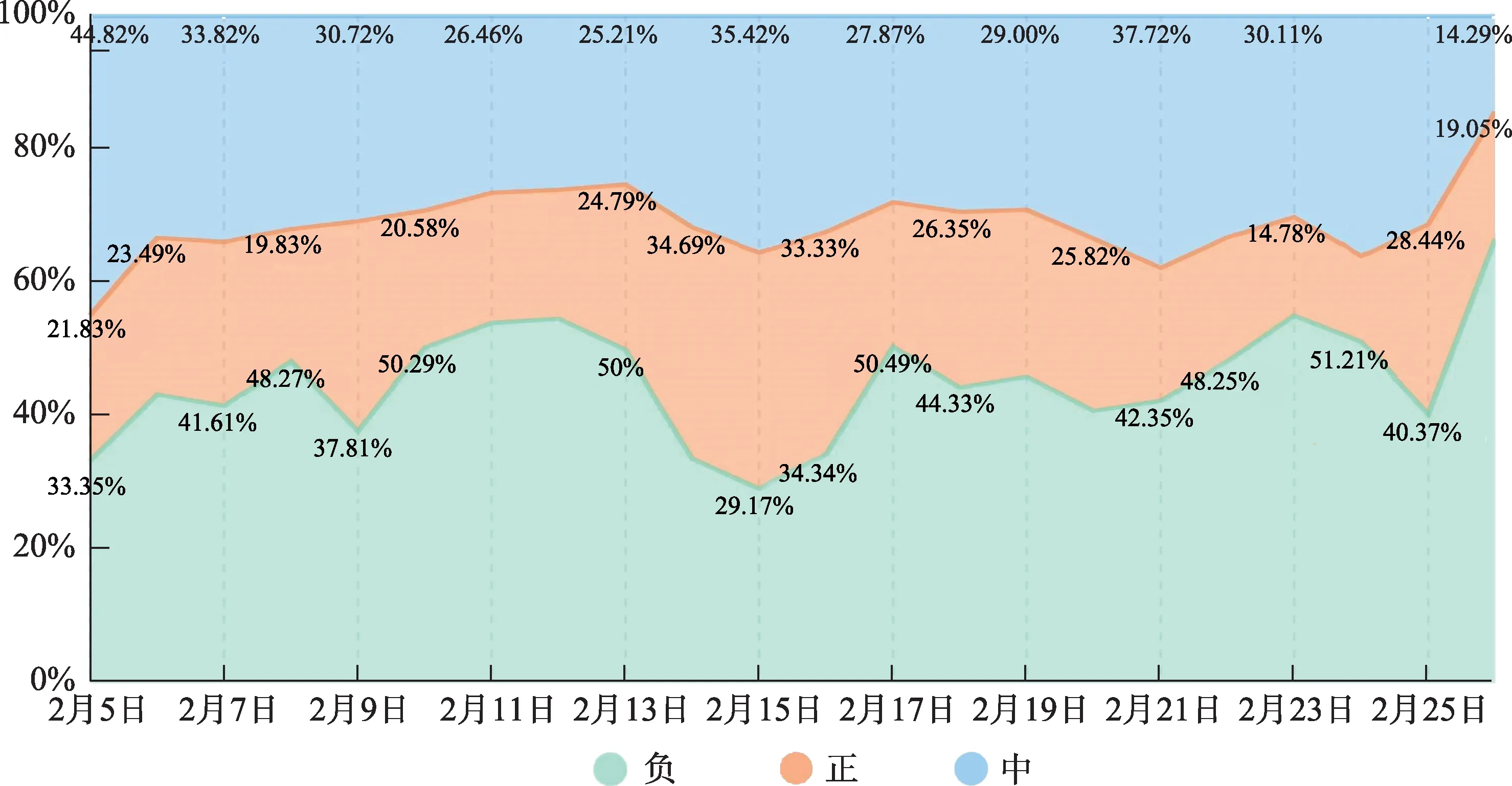
图4 舆情周期评论情感倾向值分布情况(彩图请见http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
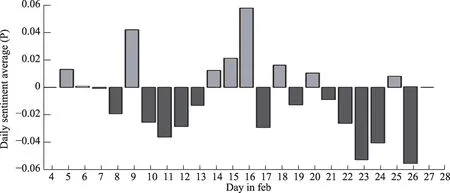
图5 全时段日平均情感倾向值随时间变化图
全时段日平均用户情感倾向值如图5 所示,获得的情感分析结果呈现为取值区间从0 到1 的实数。本文将情感分析结果数值整体下调0.5,从而使用户文本情感倾向概率分布在基线为 “0” 的左右两侧,大于 “0” 一侧为正面倾向,小于 “0” 一侧为负面倾向,以获得更为直观的可视化效果。全时段日平均情感倾向值可以清晰的表征每日用户评论的情感极性,可以观察到负面情感极性最为强烈的是在事件发生的扩散期和终结期两个阶段。
4.2 舆情周期内主题提取
以用户评论文本形成期阶段正向数据集为例,文本使用jiebaR 进行分词,然后利用向量化工具将文档集合向量化。调用R 语言中LDAvis 工具,依据以往研究预估设定主题数量为4[30]。经过反复可视化调节,确认主题之间无交集情况后,再次确定最终主题数为3。经过50 轮次的迭代过程,多次聚类之后,获得形成期主题的识别结果如图6 所示。LDA 主题模型会采用高频关键字对主题进行描述,参考以往研究为确保主题描述的全面性,本文将主题输出关键字数量设为30[30],其中某一主题(主题之间并没有顺序)的描述关键字序列为 “希望-感染-香港-疫情-船上-加油-10-武汉-3700-钻石公主号-野味-发现-出门-此次-医院-世界-新闻-人民-检察-控制-新型冠状病毒-结束……” 等。

图6 “日本钻石公主号邮轮” 舆情话题形成阶段可视化事例展示
从图6 中可以看出,LDAvis 工具直观地显示出不同主题在二维向量空间上的距离,不同圆圈的大小代表主题包含文本的数量。在二维空间向量上,3 个主题间具有明显的差别,而且没有交叠。这一数据结果表明,指定的3 个主题类别结果是可接受的。在LDA 模型中不存在 “完美结果” 的概念。图6 中主题1、主题2、主题3 的距离中心位置均较分散且平均[43]。同时,可以通过右上方λ参数设置窗口调整λ大小,如图7 所示,以确定某一主题中的词汇更加符合对该主题的描述,此示例经多次试验后选择的λ参数选为0.57。通过对上述主题挖掘及可视化方法,对 “日本钻石公主号邮轮” 舆情事件不同阶段的评论文本进行正面、中性、负面情感倾向的主题挖掘,利用关键词估计主题含义,最终主题结果如表3 所示。
4.3 舆情周期内主题分类
以往研究在进行舆情事件主题分析时,常对主题类型进一步划分,以发现不同类型主题特征,并根据主题类型特征对网民情感内容进行有针对性的引导。参考Qu 等[44]划分方式本文将主题划分为意见相关型、信息相关型、情感相关型和行动相关型四类主题,主题划分结果如表4 所示。综合来看,用户在新冠肺炎疫情事件发生的舆情周期中评论文本的主题倾向性在不同类别上各有侧重。正面情感主题主要集中于情感相关型、行动相关型和意见相关型三种类型;中性情感主题更多分布于信息相关型和意见相关型等类型;负面情感主题集中于信息相关型、情感相关型和行动相关型类型。

图7 “日本钻石公主号邮轮” 话题1关键词隶属主题图展示
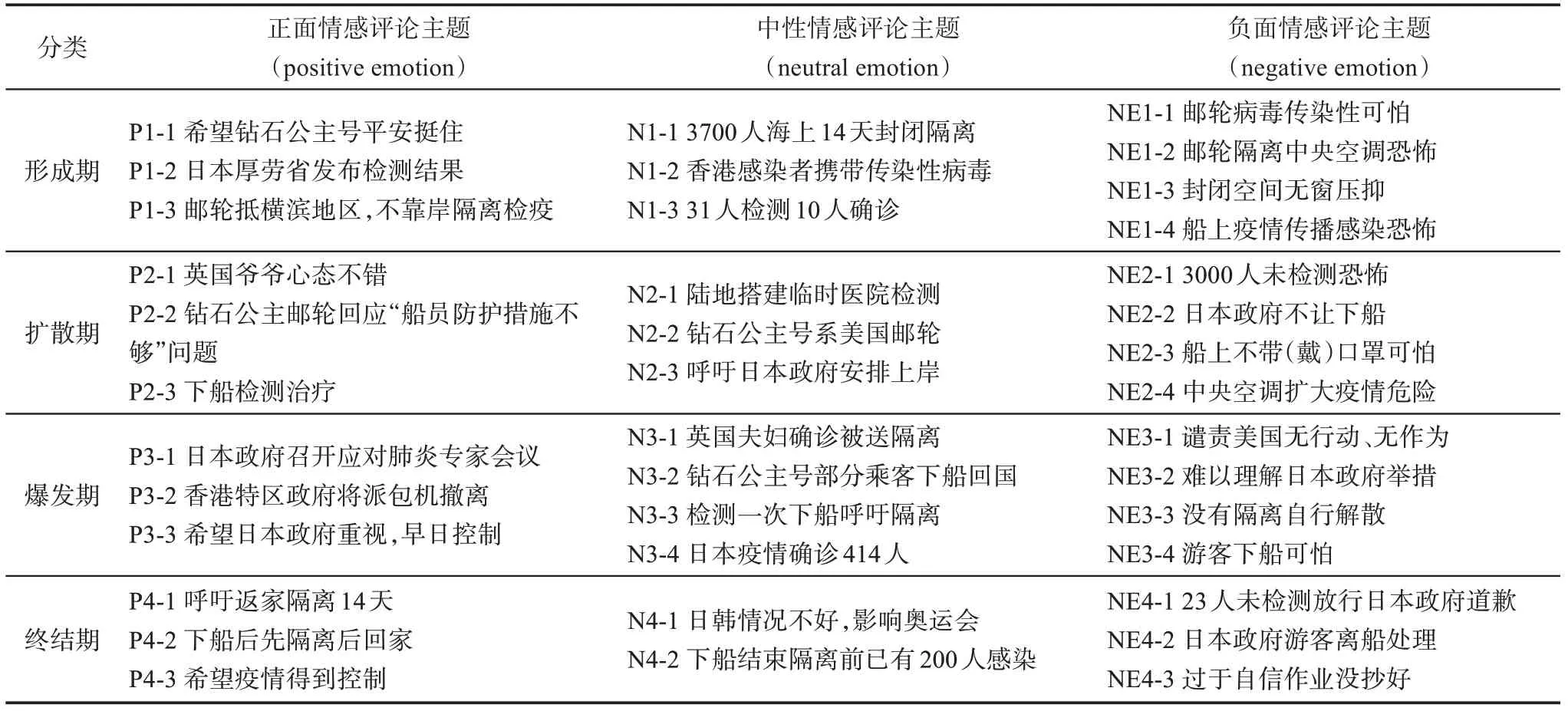
表3 “日本钻石公主号邮轮” 话题评论文本情感类别主题挖掘结果
5 讨论与分析
5.1 基于网民情感分布的舆情疏导
由表2 和图5 可以发现,针对本次舆情话题网民情感走向总体偏向负面情感,这需要相关机构进行合理的引导及关注以防舆情事件走势难以控制。本次事件中网民情感走向呈现两种特点:一是网民的正面情感容易伴随舆情周期的演进出现情感的急速转变,如2 月10 日公布感染人数以及2 月21 日 “日本钻石公主号邮轮” 乘客下船,网民情感迅速由正面转为负面;二是网民的情感走向在舆情周期中出现了反复性的波动,即在扩散期的负面情感聚集后,在终结期再次出现了负面情感聚集。
突发公共卫生事件因涉及广大群众的切身利益,因而舆情话题具有一定的敏感性,网民情感往往容易出现极端片面性,若缺乏合理的引导和缓解,则容易引发舆情危机,故对事件发展舆情周期内的网民情感进行监测是舆情引导的重要基础[45]。首先,相关机构应该确定舆情引导的关键节点,在网民情感出现整体负面趋势时,立刻引起重视,选择合适时机尽早介入。其次,相关机构应该注意在舆情周期中触发网民情感转变的关键主题事件。关注舆情主题事件发生原因及事件类型,并给出解决其及衍生事件的相应对策或紧急声明,从根本上解决网民的需求从而进行网民情感疏导。最后,做好节点的舆情引导工作的同时,还要注意观察舆情走向中衍生主题事件的情感演化特征,对可能出现的舆情热点高峰进行预判,防患于未然。
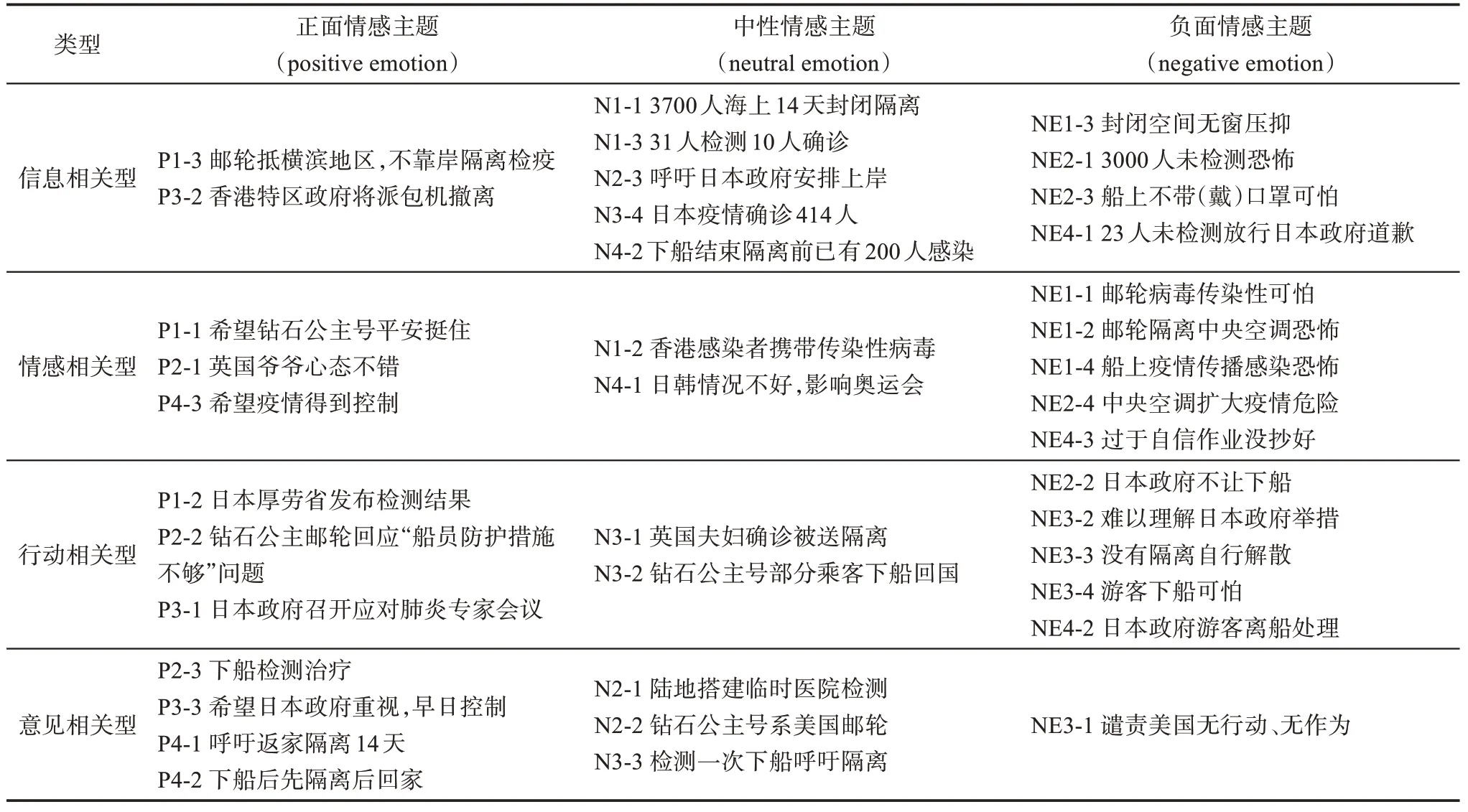
表4 评论文本主题类型划分
5.2 基于情感与主题协同分析的舆情监管
在本次事件中,用户的正面情感主题包括:形成期疫情信息的实时通报、采取措施的描述及检测结果的实时更新等,扩散期用户情感表达的个体案例以及对用户质疑提问的积极回应,爆发期日本政府的紧急措施及国内政府的救援计划等,终结期对乘客行为的呼吁以及对日本政府应对疫情的期望等。用户的中性情感主题较为均匀的分散在事件发生周期的各阶段中,包括用户对事件发生的实况描述、关键信息分享以及用户对当局做法的建议等。用户的负面情感主题主要集中在扩散期和终结期,包含的话题类型为扩散期网民对当局决策的不同意见、疫情实时的紧张局势以及终结期日本的两次决策行为等。
在理解网民情感分布的基础上,相关部门可以确定不同情感类型的网民在不同舆情阶段关注的主题内容,从情感和主题两方面入手对舆情进行有效引导,并对中性情感及负面情感主题进行重点监测及引导。中性情感主题出自网民内生信息需求的网民间信息共享行为,这类主题容易产生网络谣言,相关机构应联合主流媒体、大众媒体等有影响力的意见领袖发布科学准确信息杜绝虚假信息的传播[46],引导舆情向更好的态势发展。对于负面情感主题,相关机构要关注其主题内容及主题类型,帮助相关机构在了解主要触发事件的基础上,发现影响网民负面情感的小数量衍生舆情主题事件,挖掘网民负面情感的来源,从根本上提出全面的、有针对性的网民情感引导举措;在主题类型方面,由于舆情事件发展的反复性,对于主题类型的关注有助于舆情演变后期对可能发生的触发网民情感转变的热点事件进行相似性预测,对网民情感进行疏通及引导。
5.3 基于不同主题类型的舆情引导
由表4 可知,信息相关型主题中,用户情感主要集中于中性及负面情感主题。中性主题包括事件实时信息播报及情况描述,负向情感主题包括事件发展的紧张局势及对政府机构采纳的应急措施的评价。情感相关型主题中,中性主题较少,网民情感比较明确;负面情感主题集中于隔离的实际情况和潜在的传染危机等;积极情感主题包含积极情感的个体案例及对日本当局下一步措施的呼吁等。行动相关型主题中,对于政府高效处理措施以及相应部门对网民质疑的回应持有正面情感;对政府的决策、无法理解持有负面情感。意见相关型主题,多为正面及中性情感倾向,内容围绕网民对政府决策的建议以及对乘客相关行为的呼吁。
舆情监管部门可以根据网民在舆情不同时期的网民生信息需求,利用关键时间节点,向网民输送具有时效性的针对性信息,在突发阶段做到实时信息公开,在消散阶段做到后续报道及更进,并与网民有效交互。对于信息相关型主题,相关机构应本着信息公开及信息真实的原则,通过更新事件最新现状,介绍对不良事态采取的补救措施,在事件发酵的早起有效的引导网民情感,从根本上获得网民的理解。对于情感型主题,相关机构应该通过媒体联动效应,搜寻事件发展当事人案例,引导网民关注焦点转化到积极案例的赞同、认可及推广环节。对于行动型相关主题,建议相关机构尽早发布有针对性的应急举措,以提升公信力及办事效率,同时,对不当决策实时发表声明,及时获得网民的支持与理解。对于意见类相关主题,相关机构应及时采纳并及时回应,定期召开会议给予答复,以有效及时的安抚网民情感、回应网民的需求。
6 研究结论
在理论层面,本文构建了情感与主题挖掘协同分析模型,根据OCC 情感规则,采用朴素贝叶斯模型对用户情感进行分类,并基于Relevance 公式改进LDA 主题模型,进行主题提取,丰富了情感与主题挖掘协同分析的研究方法。在实践层面,结合全球关注的突发公共卫生事件新冠肺炎疫情 “日本钻石公主号邮轮” 这一典型舆情话题,通过对用户情感进行分类,得到舆情生命周期的四个不同阶段、不同情感类型下用户关注的主题,并将用户关注的文本主题划分为信息相关型、情感相关型、行动相关型和意见相关型四种类型,并从网民情感分布、情感主题协同分析、不同主题类型三个方面提出网民情感引导的措施。研究结果表明,采用情感与主题挖掘协同分析模型,对训练数据进行标注有助于构建一致的标注原则,从而增强情感分类器的准确率,了解不同用户情感特征及关注主题倾向,并根据不同阶段及主题内容采用相应的突发公共卫生事件的舆情引导策略,从而更好地实现网络生态治理。
另外,本文在研究中也存在一定的局限性:舆情事件的选择,仅采用新冠肺炎疫情事件中 “日本公主号邮轮” 话题进行分析,尚需要结合更多话题的舆情事件对情感与主题挖掘协同分析模型进行进一步验证。后续研究将会结合多话题的舆情事件进行分析,以对本文提出的舆情分析模型进行优化,满足突发公共卫生事件背景下多话题舆情事件分析的需求。
