作业调度软件LoadLeveler在气象模式中的应用
2021-04-20张明杨效邹丽唐艳娟张燕
张明 杨效 邹丽 唐艳娟 张燕
(甘肃省气象信息与技术装备保障中心,兰州 730020)
引言
气象业务需要处理大量的数据,对计算机的计算能力等方面有着较高要求[1]。西北区域气象中心高性能计算集群中计算节点CPU总核数832个,峰值处理能力为25 TFlops,存储空间72 TB。为了实现作业提交、调度和资源管理,西北区域气象中心高性能计算集群使用作业调度软件LoadLeveler来管理集群作业。LoadLeveler可以根据业务模式优先级、资源需求和资源的可用性对作业进行调度,并处理作业相关的管理、执行和记账,它为集群资源的最优化利用提供了动态调度和工作负载均衡的功能[2]。陈晓霞等指出LoadLeveler允许系统管理员对批处理环境进行完全控制并与操作系统紧密耦合集成以实现资源管理、抢占式调度、和记账等功能[3]。马骁等提出提高整个系统的资源利用率是高性能计算集群管理的核心,通过合理的使用调度算法协调各节点间的资源分配,提高系统的使用率和吞吐率[4]。
系统运行至今,较未采用调度软件LoadLeveler来管理集群作业前的月平均作业数、CPU利用率等指标有了大幅提升:月平均作业数2万余个,系统月 CPU 平均利用率达到40%左右,业务模式运行正点率满足国家局考核要求。随着模式预报精度的提高,模式规模也越来越大,所需资源迅速增加,如何利用LoadLeveler加强气象部门高性能计算资源管理,充分发挥气象部门高性能计算集群资源效益成为系统管理员要解决的重要问题。
1 技术思路
LoadLeveler集群由配置文件来定义,采用关键字格式。在配置文件LoadL_config中可以指定使用的admin文件的位置、定义cluster范围的配置参数、指定管理员、指定安装目录以及相关文件的存放位置、配置记账相关参数、包含调度器的调节参数等。在配置文件LoadL_admin中可以定义Machine的角色及相关配置参数、定义用户、组、队列、集群等。
系统管理员结合区域气象中心高性能计算资源总量和资源需求配置LoadLeveler文件关键字定义队列、设置调度算法和调度器调节参数等。除此以外,管理员通过编辑JCF(作业定义文件)指定作业运行参数、定义资源需求,利用命令行、脚本及API接口管理集群资源及运行的作业,将作业的处理需求与可用资源进行匹配。
2 LoadLeveler的作业管理
2.1 队列设置
气象模式可以为不同区域尺度的天气变化研究提供数据支撑[5],因此在天气预报中应用极为广泛。西北区域气象中心高性能计算机系统管理员在 LoadLeveler 中使用队列来对模式作业在资源上进行调度。队列是LoadLeveler用来决定程序该被分派到哪些节点(Node)运行,以及可使用多少CPU 时间的重要依据[6]。根据作业性质和优先级的不同,西北区域气象中心高性能计算机集群中队列的设置如表1所示。

表1 西北区域气象中心高性能计算机集群中队列划分
管理员在满足区域级的数值预报业务/准业务需求的基础上,对业务研发/科研任务的资源需求进行统筹安排,对数值预报业务/准业务所需的计算资源按运行时段分配所需CPU核资源。西北区域气象中心现有6个业务/准业务模式(表2),业务应用峰值所需CPU核数512个,核算每天需要的计算资源量为 8864 CPU 核小时。
2.2 设置作业调度算法
LoadLeveler使用不同的调度器,由管理员在配置文件中指定。
(1)LL_DEFAULT调度器(默认调度器)。LL_DEFAULT调度器将作业在空闲资源上进行调度,根据任务负载情况启动、挂起或恢复作业。在调度并行作业时,节点在变为可用状态时都会被保留,所保留节点会一直保持空闲状态,直到有足够节点可以用来运行这个并行作业。这种机制在调度大型作业时,会导致系统总体利用率很低,造成资源浪费。
(2)API调度器。通过使用LoadLeveler API(应用程序编程接口)可以编写自己的API调度程序管理作业的资源分配和分派作业,API调度程序任务的主要接口是:ll_query、ll_get_data、ll_start_job_ext等。

表2 西北区域气象中心高性能计算机系统业务/准业务模式
(3)BACKFILL(回填调度算法)调度器。回填调度算法将所有等待的作业存放在一个排过序的队列中,在队列中优先级最高的作业会被优先调度,并且允许抢占作业,以便可以运行优先级更高的作业。为了提高系统的吞吐率,在不影响大作业运行的前提下会运行小作业。如果请求的资源不足,作业会变成“Top Dog”状态并且计算出最早的启动时间。
基于以上特点,为了最大限度地利用资源提高集群效率,管理员指定LoadLeveler采用BACKFILL调度器,在配置文件LoadL_config中指定SCHEDULER_TYPE = BACKFILL。系统先扫描集群中运行的作业之间是否存在时间间隙,然后再据排队作业所需资源的多少和预估时间,将排队的作业插到空闲节点上运行,这样能充分利用资源,提高集群吞吐率[7]。
2.3 设置调度器的调节参数
2.3.1 SYSPRIO(决定作业的顺序)
用户提交给LoadLeveler每个作业都被分配1个基于SYSPRIO关键字的优先级编号,当调度器收到作业时会首先依据SYSPRIO表达式确定作业的优先级,SYSPRIO的值高则作业具有高优先级。
管理员设置SYSPRIO:0-(QDate),Qdate是作业进入等待队列的时间和中央管理节点启动时间的秒数差值。系统会根据作业提交时间创建FIFO(先入先出)队列,就是所有作业按时间顺序排队,当系统资源满足下一个作业的需求时立即执行[8]。同一队列的作业如果不指定墙钟时间,系统认为优先级别一样,先来先服务。如果指定了墙钟时间,则认为墙钟时间短的作业优先级高。
2.3.2 MACHPRIO(决定机器的顺序)
系统也会为每个计算节点分配1个机器优先级编号,基于MACHPRIO关键字表达式。管理员设置MACHPRIO:0-(LoadAvg),LoadAvg是节点当前的负载,为了提高系统性能,LoadLeveler会优先考虑负荷低的节点来运行作业。
负责监控机器资源使用情况的Startd进程每隔一段时间(缺省为5 min)会从系统中获取上1 min 的负载情况并更新到调度节点。使用命令llstatus -L machine时看到的LdAvg值(图1)就是节点当前的负载,但是这个值不是实时更新的,会有一段时间的滞后。

图1 使用命令llstatus -L machine查看系统状态
当有作业被调度运行时,中央管理节点会使用Startd进程更新的负载值加上预估的作业负载值来更新计算节点的负载值,这样就相当于降低了分配给作业使用的节点的优先级,使这些节点在下一次调度时尽量不被选取。使用公式如下:
loadavg = sysload + negotiaotr_loadavg_increment×init_count
其中,loadavg就是在中央管理节点内部最终被用于计算节点的优先级,sysload是Startd进程更新的机器的负载值,negotiaotr_loadavg_increment是预估的作业启动时可能的负载值,管理员设置为0.5。
2.4 实现作业抢占功能
LoadLeveler支持抢占,允许高优先级作业抢占低优先级作业以保证有足够的资源优先运行,这是保证重要业务模式运行的关键手段。西北区域气象中心使用suspend抢占模式,该模式下被抢占作业的执行程序还保留在虚拟内存中,当抢占作业完成时,被抢占的作业可以在原来的节点上恢复运行。在LoadL_config文件中抢占配置如下:
PREEMPTION SUPPORT = FULL
DEFAULT PREEMPT METHOD = su
PREEMPT_CLASS[normal] = ENOUGH:su{normal1}
PREEMPT_CLASS[normal2] = ENOUGH:su{normal1}
PREEMPT_CLASS[normal] = ENOUGH:su{normal2}
即队列normal的优先级最高,队列normal2的优先级次之,队列normal1最低。图2为normal队列抢占normal1队列的过程,ST(作业状态)一列中R代表作业处于运行状态,I 代表作业在等待调度,E代表作业已经被suspend方法抢占。
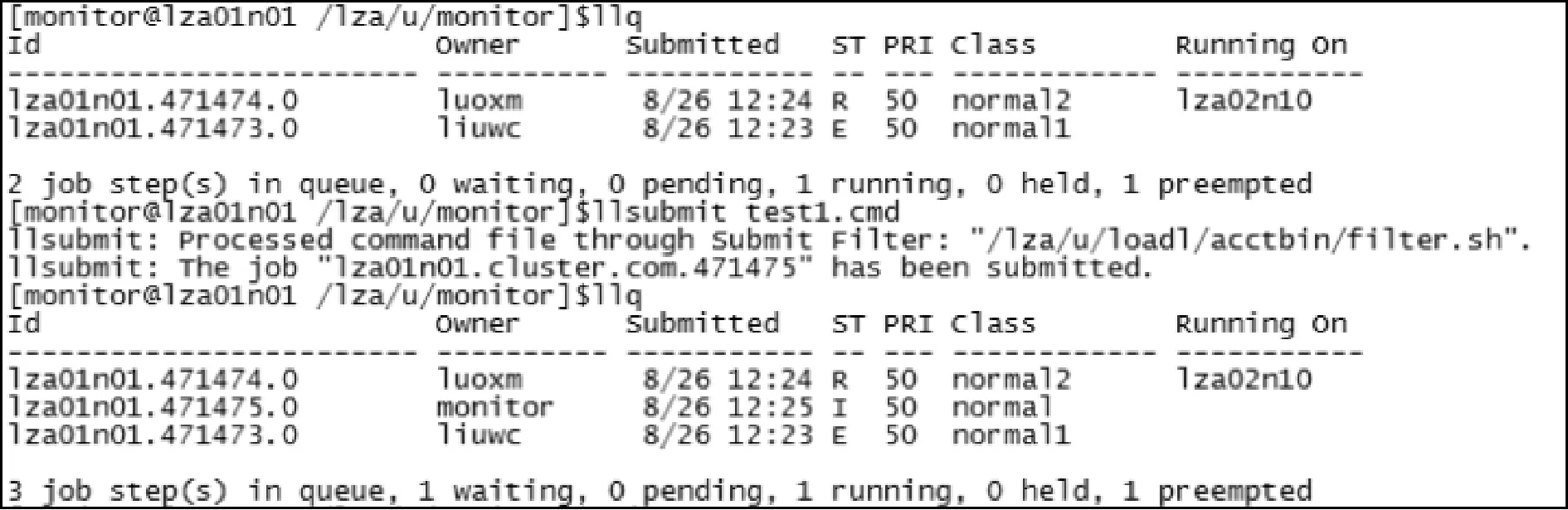
图2 normal队列抢占normal1队列
2.5 作业过滤
为了使管理员充分掌握各类应用模式的资源使用情况,用户必须主动告知作业所属气象应用模式。通过修改LoadL_config配置文件及编写相应脚本程序,强制用户提交作业时对模式类型进行说明,作为对各类应用模式所使用资源统计依据[9]。用户提交的作业定义文件JCF中必须有“#@ comment= 模式名称”关键字,如:# @ comment = GRAPES,模式名称必须是模式列表(model.list)中列出的模式之一,否则作业提交失败,并返回错误信息。
LoadLeveler通过submit filter过滤用户提交的做业,提交成功时如图3所示。

图3 作业成功提交
3 LoadLeveler资源管理
3.1 可消耗资源Consumable Resources和WLM
当系统管理员在配置集群时或用户在规划作业时,需要了解集群中机器的可用资源,因为资源的可用性会随着时间的变化而变化,LoadLeveler将它们定义为可消耗资源Consumable Resources。为了控制作业的资源使用情况,管理员定义LoadLeveler资源强制策略,使用工作负载管理器Workload Manager (WLM)对CPU、物理内存、虚拟内存和大页面等资源进行分配。WLM通过创建不同的服务类并为这些类指定属性来实现控制:当物理内存或CPU超过限制时,该类中的作业进程将接收较低的调度优先级,直到它们的利用率低于限制;当虚拟内存或实际内存限制被超过时,作业进程被终止;如果大页面超过限制,则拒绝任何新的大页面请求[10]。
根据实际使用需求,管理员在LoadL_config文件中为可消耗资源定义适当的选项:SCHEDULE_BY_RESOURCES= ConsumableCpus ConsumableMemory CollectiveGroups指定CPU、物理内存、群组为调度资源;ENFORCE_RESOURCE_USAGE = ConsumableMemory使得WLM能够强制执行可消耗资源。为了让调度器从计算机中分配资源,需在LoadL_admin文件中指定机器资源:resources = ConsumableCpus(all) ConsumableMemory(100 GB)
使用llstatus -R命令(图4)可以看到LoadLeveler集群中所有节点的可消耗资源

图4 集群可消耗资源
3.2 在作业定义文件JCF中指定资源
利用LoadLeveler进行资源和作业管理时,不能在登录节点上以脚本方式运行作业命令文件,所有作业必须通过作业提交命令llsubmit提交。为了利用llsubmit提交作业,用户必须针对此作业创建作业定义文件JCF,JCF作业定义文件是一个shell脚本,其中包含LoadLeveler关键字指令,以#@为前缀。这些关键字通知LoadLeveler作业的环境,要执行的程序,在何处写入输出文件,作业是串行还是并行,以及作业运行所需要的资源。比如指定任务请求资源的名称和数量:#@ resources = ConsumableCpus(2);指定网络参数:#@ network.MPI = sn_all,shared,US;指定作业总共运行的任务数:#@ total_tasks = n。
3.3 计算资源记账
3.3.1 使用 LoadLeveler对作业进行记账
对高性能计算机系统进行资源记账,需要在配置文件(LoadL_config)中打开记账功能。配置文件中的ACCT的关键字,可以设置为:ACCT = A_ON A_DETAIL。A_ON:打开记账功能,记录作业的CPU使用时间;A_DETAIL:记录作业的详细信息以及作业使用的每个机器的资源情况。
管理员可运行llsummary命令根据记账数据生成报表,统计资源的周期内使用情况,分析不同用户在不同时间使用资源(CPU、内存等)的详细情况[11]。图5展示了管理员使用llsummary -s 02/09/2019 to 02/09/2020命令在系统其中一个登录节点上生成的近一年报表:

图5 使用llsummary -s命令生成报表
3.3.2 使用Prolog/Epilog脚本记账
LoadLeveler允许管理员定义prolog和epilog脚本,在每个作业步骤之前和之后自动运行,提取作业的详细运行信息[12],在/lza/g1/gold_acct目录下生成记录文件。提取的作业信息包括作业类型、作业号、用户账号、使用CPU数、使用节点数等。
在LoadL_config文件中配置JOB_PROLOG和JOB_EPILOG关键字:JOB_PROLOG = /lza/u/loadl/acctbin/prolog.sh;JOB_EPILOG = /lza/u/loadl/acctbin/epilog.sh。脚本使用Perl语言编写,主要代码如图6所示。

图6 Prolog/Epilog脚本部分代码
4 利用应用程序编程接口API
LoadLeveler提供丰富的命令行及API接口管理集群资源及运行的作业,通过使用LoadLeveler编程接口,管理员可以定制LoadLeveler的使用以满足实际需求,在应用程序中调用这些API来与LoadLeveler交互获取LoadLeveler标准命令无法提供的数据,编写自己的API 调度程序,创建新的自定义LoadLeveler命令,获得使用报告等。LoadLeveler支持的接口和功能如表3所示。
头文件llapi.h定义了所有API数据结构和子例程,该文件位于LoadLeveler发行目录的include子目录中,调用任何API子例程时,必须包含此文件[13]。
5 LoadLeveler的CPU亲和性
CPU亲和性(affinity)是一种调度属性(scheduler property),它可以将一个进程“绑定”到一个或一组CPU上,使用LoadLeveler的亲和性时,管理员在配置文件(LoadL_config)中指定关键字: RSET_SUPPORT=RSET_MCM_AFFINITY,指示计算机可以运行请求CPU亲和性的作业。
LoadLeveler将选择几组CPU并将它们附加到任务进程,这些CPU来自相同的MCM(Multiple Chip Modules多芯片模块),可以指定进程在某个(或某些)处理器上运行,从而提高系统性能。用户在作业定义文件JCF中指定:#@ task_affinity = core(number) | cpu(number),如果指定了core,则作业的每个任务都必须尽可能在指定数量的处理器内核上运行;如果指定了cpu,则作业的每个任务都必须尽可能在指定数量的逻辑CPU上运行。在LoadLeveler中,core指物理CPU,cpu指逻辑CPU。
6 结论
西北区域气象中心搭建高性能计算机集群系统作为承载天气预报业务和相关科学研究模式运算的重要平台,采用LoadLeveler来调度管理集群作业,可以根据优先级、资源需求和资源的可用性对串行或并行的作业进行调度,并处理与运行在分布式资源集上的作业相关的管理、执行和记帐。系统具有多个队列和灵活的调度策略,保证高性能计算机系统资源的充分利用,为用户提供高效的计算资源,充分保障了西北区域气象中心数值预报业务模式和科研模式的运行,对于发挥西北区域气象中心高性能计算资源使用效益具有重要的意义。
