机器学习在强对流监测预报中的应用进展*
2021-04-20周康辉郑永光董万胜
周康辉 郑永光 韩 雷 董万胜
1 国家气象中心,北京 100081 2 中国海洋大学信息科学与工程学院,青岛 266100 3 中国气象科学研究院,北京 100081
提 要: 近年来,机器学习理论和方法应用蓬勃发展,已在强对流天气监测和预报中广泛应用。各类机器学习算法,包括传统机器学习算法(如随机森林、决策树、支持向量机、神经网络等)和深度学习方法,已在强对流监测、短时临近预报、短期预报领域发挥了积极的重要作用,其应用效果往往明显优于依靠统计特征或者主观经验积累的传统方法。机器学习方法能够更有效提取高时空分辨率的中小尺度观测数据的强对流特征,为强对流监测提供更全面、更强大的自动识别和追踪能力;能够有效综合应用多源观测数据、分析数据和数值预报模式数据,为强对流临近预报预警提取更多有效信息;能够有效对数值模式预报进行释用和后处理,提升全球数值模式、高分辨率区域数值模式在强对流天气预报上的应用效果。最后,给出了目前机器学习方法应用中存在的问题和未来工作展望。
引 言
人工智能的迅速发展将深刻改变人类社会生活,改变世界。机器学习属于人工智能范畴,是人工智能领域的一个重要分支,主要研究对象是如何在经验学习中改善具体算法的性能。自1956年达特茅斯会议上,机器学习(machine learning)的概念被首次提出以来,成为数学、计算机科学、神经科学等多学科的活跃研究方向(万赟,2016),其算法也被广泛应用到大气、海洋等众多学科领域。传统机器学习算法主要包括逻辑回归、决策树、随机森林、人工神经网络、支持向量机、贝叶斯分类器、聚类算法等。虽然其发展历程跌宕起伏,经历了多个发展高潮与低谷,但是在不同的发展时期,机器学习均展示了旺盛的生命力,在各个发展领域得到广泛的应用。
Hinton and Salakhutdinov(2006)提出“深度学习(deep learning)”的概念,证明了深层神经网络的可训练性,展现了深层神经网络更强大的特征提取和非线性拟合能力,奠定了此次人工智能发展浪潮的基础。但该论文主要以理论分析为主,当时并未有重要的应用产生,因此在计算机学界并未立刻产生重大影响。在接下来的十年中,直到两个标志性事件的出现,才使得深度学习分别取得了计算机领域内和全世界范围内的认可。第一个事件是2012年Alex Krizhevsky与Geoffrey Hinton在国际上著名的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)图像识别竞赛中,用深度学习方法(即AlexNet)以绝对优势取得第一名。2013年起几乎所有参加该竞赛的队伍全部采用深度学习方法。在ILSVRC这种世界级的竞赛中,一种方法几乎能够在一夜之间完全胜出,这在以前是无法想象的。另一事件是2016年基于深度学习的围棋程序AlphaGo战胜世界冠军李世石,这不仅引起了全世界范围内对人工智能技术巨大进步和未来发展潜能的关注,也引发了世界范围内对人工智能产业的投资潮。目前,深度学习及其他人工智能技术仍在以前所未有的速度发展着。
根据训练数据是否有标记信息,机器学习任务可分为监督学习和无监督学习。常见的无监督学习算法如聚类算法、主成分分析等算法。监督学习又可分为回归和分类。回归问题预测连续值,如气温、降水量;分类问题则预测的是离散值,如晴或雨。目前,机器学习,尤其是深度学习,在分类问题上取得了巨大的成功,如图片分类竞赛中其效果超越人类(Russakovsky et al,2015),在回归问题中效果次之。无监督学习仍亟待更进一步突破(LeCun et al,2015)。
机器学习算法,特别是深度学习,需要大量的历史数据进行建模并训练,从而从历史数据中学习到规律。天气预报,经过长时间的发展,积累了海量历史观测数据、数值预报模式数据,具备“大数据”属性,能够为机器学习提供训练所需的大量数据,因此,一直以来,机器学习在天气预报领域有众多成功应用(Karpatne et al,2019)。
强对流天气预报主要关注时空尺度较小、发展剧烈的天气现象,如冰雹、雷暴大风、短时强降水、龙卷等恶劣天气。由于局地性强、发展迅速,强对流天气具有极高的预报难度(郑永光等,2015)。由于其强度强,易于造成严重的人员和财产损失(王秀荣等,2007),比如2015年“东方之星”翻沉事件(郑永光等,2016a)和2016年江苏阜宁EF4级龙卷事件(郑永光等,2016b)。
由于强对流天气系统的中小尺度特性,因此强对流天气预报特别关注监测和临近预报。对于天气雷达、气象卫星、闪电探测仪、自动气象站等具备高时空分辨率的数据使用,提出很高的要求。然而,海量的观测数据,已经很难完全由预报员主观监测识别。传统的客观做法,根据物理机理、预报员经验和统计结果,通过对观测数据设置一定阈值,对强对流天气进行识别和监测,通常会造成虚警率偏高(Schultz et al,2009;Harris et al,2010)。目前,强对流天气临近预报极大地依赖实况监测,以雷达或者卫星观测结果进行线性或非线性外推预报为主,尤其缺乏对流生消演变的预报能力,因此应用效果具有较大的局限性(俞小鼎等,2012;郑永光等,2015)。
与强对流监测和临近预报不同的是,强对流短时(2~12 h预报)和短期预报(12~72 h预报)更侧重于对数值预报模式的释用。近年来,随着高分辨率数值预报模式的发展,强对流天气预报更多地依赖高分辨率数值模式预报。随着时空分辨率越来越高,高分辨率数值模式预报信息量越来越大,对预报员的信息提取能力提出极高的要求。目前,很多强对流天气(如雷暴大风、龙卷等)并没有直接的模式输出产品。经验丰富的预报员需要从大量数据中,提取动力、水汽、能量、地形影响等强对流天气形成条件,最终形成一份可用的强对流预报。
由此可见,强对流监测预报,目前仍大量依靠传统的统计结果和预报员经验。长期的应用结果表明,以上方法具有较大的局限性。首先,不同季节、不同地势分布、不同气候背景区域之间,强对流天气发生发展条件与特征阈值范围必然会存在差异,难以使用一套统一的特征物理量阈值组合来实现不同区域的分类强对流天气的预报(王婷波等,2020);其次,天气预报过程中需要使用大量数据,依靠预报员统计或者主观提取特征物理量和阈值范围,难以完全发现数据中有价值的细节信息或者细微差别,特别是一些中小尺度信息;再次,强对流天气复杂多变,如果预报员对于强对流发生发展规律认识不够深刻、全面,也会忽视其中的有效信息。传统基于物理机理的统计模型等客观方法,由于基于主观认识建立,也难以避免地存在上述问题。
近年来,以深度学习为代表的机器学习算法的兴起,有效结合各类气象大数据,已经成为强对流天气预报的有效手段(McGovern et al,2017;Reichstein et al,2019)。与浅层神经网络、支持向量机等传统机器学习算法相比,深度神经网络不仅能够为复杂非线性系统提供建模,更能够为模型提供更高的抽象层次,从而提高模型的特征提取能力;其优势在于能以更加紧凑简洁的方式来表达比浅层网络大得多的函数集合,并在图像识别、语音处理等领域相比传统方法的性能有了显著提升(Krizhevsky et al,2012;LeCun and Bengio,1995;Szegedy et al,2013)。
本文梳理了机器学习在强对流天气监测、短时临近预报、短期预报等领域的应用和存在的问题,并给出了未来工作展望,以期更清晰地了解机器学习在强对流天气领域的应用情况,为更好地结合物理机理、数值预报等来发展强对流天气领域的机器学习技术提供参考。
1 机器学习在强对流监测中的应用
强对流天气监测依赖于气象卫星、天气雷达、闪电定位仪、自动气象站等具备高时空分辨率的中小尺度监测网, 是强对流预警预报的基础。
1.1 云和降水分类
静止气象卫星观测具有覆盖范围广、时空分辨率高的特点,是监测强对流天气的重要手段。目前,国内外利用卫星遥感技术,进行强对流云团识别的研究已经取得了一定的成果。
白慧卿等(1998)通过人工神经网络方法进行了地球静止气象卫星(GMS)云图中的4类云系[冷锋、静止锋、雹暴云团、强对流复合体(MCC)]识别,识别准确率超过99%,优于贝叶斯方法,认为神经网络方法更适合于云系的特征识别。Tebbi and Haddad(2016)利用支持向量机,输入欧洲第二代静止气象卫星(Meteosat Second Generation,MSG)自旋增强可见光和红外成像仪(spinning enhanced visible and infrared imager,SEVIRI)的12个频谱参数,构建不分昼夜的云分类模型,并对比了神经网络和支持向量机的分类效果,最终发现支持向量机具有更好的效果,其对于层云和对流云的分类临界成功指数(CSI)达到0.55,命中率(POD)达到0.74.
Kim et al(2017a)利用Himawari-8卫星云图,选取与对流云发展密切相关的相关因子(interest fields,IF),构建了随机森林、极端随机树(extremely randomized trees,ERT)、逻辑回归等模型,有效地识别了对流系统的上冲云顶特征,相对于传统的红外云图纹理识别、红外与水汽通道亮温差等算法,有了明显的提高。胡凯等(2017)利用迁移学习中的多源加权Tradaboost算法(内部采用极限学习机作为分类器)对环境与灾害监测预报卫星(HJ-1A/B)的数据进行云的检测,利用人工(多源)标注的大量厚云的样本构成多源辅助样本集,利用少量标注的薄云样板构成目标样本集。结果表明迁移学习可以充分利用容易获得的大样本厚云辅助样本知识,对同类型有关联的小样本薄云分类器进行识别提高。
利用雷达进行对流降水的分类,同样是监测对流发生发展的有效方式。王静和程明虎(2007)利用BP神经网络模型对单站雷达进行了三种降水类型(对流云降水、层状云降水和混合云降水)的分类。Xu et al(2009)将台风外围螺旋云系降水的分割识别化为机器学习的分类问题,利用支持向量机,在雷达反射率图像上,实现了云系降水区域类型的分割,为大风和强降水区域的监测提供了实时依据,算法效果优于最大熵、图像边沿检测等传统算法,具有更好的准确性和鲁棒性。Gagne II et al(2009)基于多普勒雷达资料,利用集成K-means和决策树算法,实现对流风暴识别和对流降水识别。K-means算法实现从线性对流系统中聚类分离出对流系统。决策树则对对流风暴进行分类,将对流单体分为“孤立脉冲风暴”“孤立强风暴单体”“多单体风暴”,将线性对流系统实现“前导层状云”“尾随层状云”“平行层状云”的分类。
综合利用卫星和雷达等多源数据,可以综合获取云和降水分类信息。匡秋明等(2017)提出了一种基于雷达、卫星、地面观测等多源数据的多视角学习晴雨分类方法,该方法应用随机森林方法分别对多视角进行样本学习,得到晴雨分类模型。结果表明,与单独使用卫星、雷达、地面观测站等单一数据源相比,该方法提高了1 km×1 km和6 min时空分辨率晴雨分类的准确率,降低了漏报率和空报率。
1.2 定量降水估计与监测
利用卫星、雷达等遥感探测资料,进行定量降水估计,能够有效提高降水观测的时间和空间分辨率,同时对于无气象观测站点的区域,也是很好的补充。利用机器学习,能够有效拟合遥感探测数据与降水量的非线性关系,实现更精确和精细的降水估计结果。
基于MSG卫星的成像仪SEVIRI探测的云顶顶高、云顶温度、云相态和云水路径等因子,Kühnlein et al(2014a;2014b)利用随机森林、Meyer et al(2016) 利用4种机器学习算法(RF、神经网络、平均神经网络、SVM)进行定量降水估计。他们首先区分降水区与非降水区,然后实现对流降水与非对流降水区域划分,最后对不同降水区域使用不同的降水反演因子,实现对中纬度地区全天候的定量降水估计。其中,各种降水区域的降水反演因子由机器学习通过卫星云图和雨量计观测到的降水量拟合得到(Ouallouche et al,2018)。在此基础上,Lazri and Ameur(2018)将算法进行了升级,将支持向量机、神经网络和随机森林等算法进行了集成,同样利用MSG-SEVIRI数据集,改进了训练方式,将分类效果欠佳的样本进行了二次训练和预测,从而达到了比单个分类器更好的训练效果,最终其分类准确率可达到97.4%。
Meyer et al(2017)认为,如果将卫星云图上降水反演点周围的纹理特征等信息加入机器学习模型,将能有效地改进定量降水估计,因此构建了基于MSG和GLCM(grey level co-occurance matrix)的神经网络模型,结果却发现,在增加了反演格点周围纹理信息的情况下,可能由于神经网络模型无法有效提取空间纹理信息等原因,降水反演效果并没有明显改善。
利用雷达Z-R关系进行定量降水估计仍然具有较大的改进空间。邵月红等(2009)利用多普勒雷达的回波强度资料及相应的雨量计观测资料,通过前向反馈(BP)神经网络方法来估测临沂地区的降雨量,对比了Z-R关系估测的降雨量,表明BP神经网络估测精度要明显优于固定Z-R关系式,BP神经网络估测的降雨量与站点实测雨量吻合性较好,而固定Z-R关系式估测的降雨量存在不同程度的低估现象。Grams et al(2014) 在雷达估测降水的基础上,引入快速更新循环分析场中的环境变量,对比了各种变量对于改善定量降水估计的作用,最后发现零度层高度和温度递减率对于改进雷达估测降水最为重要。利用决策树,融合雷达观测数据和数值分析场数据,得到比传统固定Z-R关系更为精确的降水估算。
基于双偏振雷达观测利用机器学习方法更进一步提高了雷达估测降水的精度。Islam et al(2012) 集合并对比了支持向量机、神经网络、决策树、邻近聚类等算法,利用双偏振雷达观测反射率因子、差分反射率因子、交叉相关系数、速度和谱宽等,实现了地面杂波、海浪杂波以及其他异常回波的识别,识别准确率可达98%~99%,在去除杂波的基础上有效改进了雨量监测。
1.3 冰雹和雷暴大风监测
冰雹和雷暴大风往往在局地性极强的对流性系统中发展而来,由于局地性很强,现有观测网依然难以完全捕捉(郑永光等,2017),具有很大的观测难度。在目前我国大范围取消人工观测的趋势下(中国气象局,2013),使得冰雹和雷暴大风的直接观测数据更显稀少。因此,采用雷达和卫星等观测资料进行冰雹和雷暴大风的识别,既非常重要,也显得很有必要。
目前气象业务中,由单站雷达PUP(principal user processor)系统生成的强冰雹指数,通常强冰雹空报率过高。王萍和潘跃(2013)为了解决这个问题, 依据概念模型对强冰雹回波单体特点的描述, 设计并实现了 “悬垂度” 等多个特征提取算法。以此为基础, 选用基于径向基核函数的非线性支持向量机得到强冰雹识别模型, 将待测样本远离最优分类超平面的相对程度定义为新冰雹指数。试验表明, 本方法较目前业务上普遍使用的冰雹指数法具有更高的命中率, 同时空报率大大降低。另外,为了区分短时强降水和冰雹天气,王萍等(2016)利用决策树算法,基于系统结构疏密性特征、移出率、液态水含量及累加液态水含量等特征,实现对冰雹和短时强降水的分类识别。试验表明,本文方法对雷达站50 km以内范围的雷暴系统产生的短时强降水击中率达到89.1%,误报率为9.5%;冰雹的击中率为79.8%,误报率为3.5%;平均临界成功指数达到80.0%。
相对于冰雹探测,雷暴大风的探测可借助我国稠密的自动气象站观测数据,在大风观测基础上,利用雷达、卫星资料进行质量控制,能够较好地实现雷暴大风的识别。李国翠等(2013)、周康辉等(2017)在地面气象观测站大风记录的基础上,结合多源数据(包括雷达、卫星、闪电、温度、露点等观测数据),利用模糊逻辑算法,实现对雷暴大风与非雷暴大风的有效识别,可在全国范围对雷暴大风进行实时监测。杨璐等(2018)基于雷达基数据和加密自动气象站数据,利用支持向量机算法建立了雷暴大风天气的有效识别模型。
1.4 风暴识别和追踪
基于卫星、雷达、闪电等观测数据,利用机器学习算法,能够有效实现对对流系统的识别和追踪,提取对流系统的移动方向、移动速度等信息,为对流预警提供重要信息。
雷达观测能够提供近地面的风暴的三维结构特征,因此利用雷达数据可有效进行风暴的识别和追踪。Lakshmanan et al(2000)利用遗传算法,从雷达图像中逐层识别,进而实现对风暴的识别,能有效分辨对流系统的分裂和合并情况。在此基础上,Lakshmanan et al(2005)发展了中气旋识别算法,在三维雷达图像上识别风暴尺度的旋转,并建立神经网络,将中气旋特征和环境条件特征作为输入,进一步识别中气旋风暴是否会发展成龙卷,在实际应用中取得了很好的效果。
Haberlie and Ashley (2018a;2018b)基于雷达拼图数据,利用机器学习算法,构建了对流识别、追踪算法。首先,将雷达回波进行分割,识别并分割水平尺度大于100 km的深对流系统的连续或半连续区域。将分割好的对流系统,根据降水人为主观地为每个样本分配下列标签之一:(1)中纬度MCS,(2)无组织对流,(3)热带系统,(4)天气系统,(5)地面杂波和/或噪音。然后训练随机森林,梯度增强(gradient boosting)和XGBoost,结果表明算法具有良好的对流云识别效果。最后,在此基础上,利用空间匹配的方式,实现对MCS的追踪。
基于闪电数据的雷暴识别,追踪与外推算法也有一些尝试。侯荣涛等(2012)、周康辉等(2016)分别利用K近邻法(k-Nearest Neighbor,kNN)、密度极大值搜索算法等聚类算法,实现对闪电簇的识别,从而实现对雷暴活动区域的识别,进而分别利用路径曲线拟合、Kalman滤波器等算法,实现对雷暴的追踪与临近预报。
1.5 深度学习在强对流监测中的应用
雷达、卫星等观测数据本质属于图像的范畴,而深度学习近年来在图像识别领域取得极大成功。因此,利用深度学习可以有效从雷达图像、卫星云图中识别出强对流天气。
利用深度学习,可以有效利用雷达探测的三维空间数据,提取冰雹事件的三维结构特征,如冰雹在即将发生或者发展过程中,在雷达回波图像上,具有很明显的诸如三体反射、弱回波区(WER)、回波悬垂等特征。Wang et al(2018)利用深度学习算法,基于单站雷达的三维探测数据,输入不同高度的雷达扫描切面,提取产生冰雹的对流云中的有界弱回波区等特征,从而取得比传统方法更好的冰雹识别效果。
最近,郑益勤等(2020)利用Himawari-8卫星图像,构建了用深度信念网络(DBN)进行强对流云团自动识别的方法,该方法可以有效识别处于初生到消散不同阶段的强对流云团,并在一定程度上去除卷云。与单波段阈值法、多波段阈值法和支持向量机这三种方法相比,其提出的方法能够提高强对流云团的识别精度(对流区域识别效果如图1)。

图1 2017年3月14日08时使用深度学习进行强对流云识别的结果(郑益勤等,2020)(a)TBB08-TBB13,(b)初始识别结果,(c)闭运算后结果Fig.1 The identical results of convective storm of satellite images with deep learning method at 08:00 BT 14 March 2017 (Zheng et al, 2020)(a) TBB08-TBB13, (b) initial recognition result, (c) result of closed operation
深度学习也可以从气象要素场中识别天气系统。Lagerquist et al(2019)利用深度卷积神经网络,从温度、比湿、风场、位势高度等变量中,成功实现对冷锋和暖锋识别,通过与人工标记的冷锋和暖锋对比后发现,如果误差250 km以内算正确,其命中率达到73%,虚警率为35%,临界成功指数达到52%。
2 机器学习在强对流临近预报中的应用
2005年,世界气象组织(WMO)定义的临近预报(或称为甚短时预报)为0~6 h的天气预报,现已得到了广泛认可(俞小鼎等,2012;Wilson et al,2010;Sun et al,2014)。不过我国预报业务通常将0~2 h的天气预报称为临近预报(俞小鼎等,2012),因此,本文将0~2 h的预报称为临近预报,2~12 h称为短时预报,12~72 h为短期预报。传统的线性外推算法无法判断对流的生消演变,利用机器学习算法,能够从雷达反射率因子、卫星云图等观测数据中,提取对流初生、发展、消散等特征,从而为判断对流演变起到一定作用。
2.1 基于雷达回波的外推预报
将机器学习应用于强对流临近预报,最直观的设想是利用机器学习改进雷达回波外推预报。传统的外推方法,如TITAN(Dixon and Wiener,1993)、SCIT(Johnson et al,1998)以及光流法(Bechini and Chandrasekar,2017)等等,能够有效判断对流的移动趋势,但是无法判断对流系统的生消演变等特征,因此无法给出对流初生、增强或减弱等预报(Wilson et al,1998)。利用机器学习,一定程度上能够克服上述问题。
Yu et al(2017)将过去时次的雷达回波反演的降水量、海拔、经纬度作为预报因子,构建随机森林和支持向量机,进行0~3 h降水量预报,并对比了随机森林和支持向量机的预报效果,结果表明两种算法都能较好地实现0~3 h降水量预报,而支持向量机在此任务中表现更好。Foresti et al(2019)从10年的雷达组合反射率图片中,识别和追踪对流系统,提取包括位置、风场、冻结层高度和时间等变量作为预报因子,应用神经网络,预报降水系统的加强与减弱。预报结果表明,神经网络能够有效预报对流系统的增强和减弱,预报均方根误差相对拉格朗日外推降低20%~30%。
2.2 基于静止气象卫星资料的临近预报
静止气象卫星能够监测对流云形成初始阶段的相关特征,如云体厚度快速增加、云顶温度急剧下降、云顶相态的变化(Mecikalski et al,2010a;2010b)。因此,应用静止气象卫星监测数据,能够有效实现对对流初生(CI)的监测预警(Mecikalski and Bedka,2006;Mecikalski et al,2013;Walker et al,2012)。
国内外研究人员开展了相关工作,基于静止气象卫星数据,开发了大量对流初生预报算法。但传统方法很大程度上依赖于研究人员的物理认识、统计结果和经验,针对卫星观测数据的物理特性,设计对流初生的判据。如当前美国静止气象卫星的CI采用的判据包括10.7 μm通道亮温低于0℃,10.7 μm通道亮温时间变化趋势小于-4℃/15 min等等。
基于卫星数据,应用机器学习方法能够自动实现CI的预测。Han et al(2015)利用通信与海洋气象卫星(COMS)成像仪数据,应用决策树、随机森林、支持向量机等方法,提取了卫星红外、可见光、水汽等通道中的对流初生特征,成功实现了对流初生判断与预报,对流初生预报的提前量达30~45 min。Bessho et al(2016)利用Himawari-8卫星中的多通道信息和通道变化趋势,以及简单的逻辑回归模型,实现对快速发展的对流区域(RDCAs)的识别,为即将发展的对流提供提前告警信息。Lee et al(2017)利用决策树、随机森林、逻辑回归等模型,基于Himawari-8成像仪的多通道数据,选取12个IF,提取其变化特征,进行对流初生的预报。
2.3 综合多源资料的临近预报
静止气象卫星具备对对流初生的观测能力,观测对流云顶的发生发展特征;天气雷达观测对流风暴的内部分布特征;数值模式预报数据可提供对流发展的环境条件。多源观测数据表现形式、物理意义各异,如何将多源数据实现有效融合,也是当前面临的挑战之一。
机器学习算法能够自动学习并提取特征,为多源数据融合提供了新的思路。如Mecikalski et al(2015)基于静止气象卫星数据结合数值模式数据,选取了25个相关要素,利用逻辑回归和随机森林,实现了欧洲地区的对流初生预报。 Ahijevych et al(2016)利用随机森林,融合雷达、卫星云图和数值模式数据,进行0~2 h的对流初生预报,模型有效探测了99%以上(总数550个)的初生系统。Han et al(2017)利用支持向量机算法,基于多普勒雷达数据和高分辨率分析场,自动提取雷暴发生发展特征,训练了预报模型,基于多普勒雷达四维变分分析系统(VDRAS)预报场实现了雷暴的临近预报(流程见图2)。
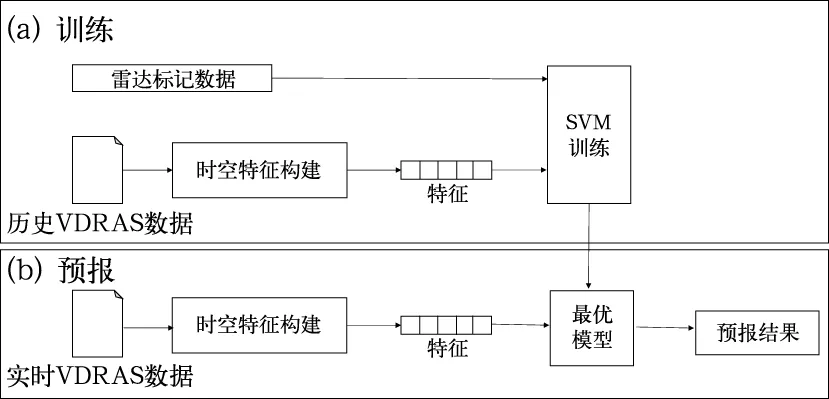
图2 基于多源数据(雷达和VDRAS数据),利用支持向量机进行对流临近预报的流程(Han et al,2017)Fig.2 Flow chart of SVM for convective weather nowcasting with VDRAS data (Han et al, 2017)
Marzban and Witt(2001)和Lagerquist et al(2017)利用机器学习算法,融合使用雷达资料追踪的雷暴特征和对流系统附近的探空观测特征,对对流性大风和冰雹进行临近预报,结果表明,其不仅能够有效预测对流单体内部的大风(提前0~15 min),而且能够预测对流系统10 km以内范围的阵风锋大风(提前60~90 min),具有较好的实用价值。Czernecki et al(2019)利用随机森林,融合了雷达数据、闪电数据和再分析数据的对流参数,进行大冰雹的预报。结果表明,雷达数据在冰雹预报中起到主要作用,而对流参数作用也不可被忽视。McGovern et al(2014)构建了时空决策树模型,基于多源数据包括雷达、地面观测数据、飞机观测数据等,进行强对流天气(龙卷和对流颠簸)的预测。其预测模型能够清晰地显示各个预报因子的作用,从而为更好地理解强对流发展原因,提供较好的思路。
Apke et al(2015) 则用机器学习方法分析了对流环境对于对流初生的作用,研究是否可以将对流参数引入,改进利用卫星进行对流初生的预报效果。他们应用主成分分析(PCA) 和二次判别分析(QDA)进行了相关性分析。结果发现,CAPE和CIN对于改进卫星的对流初生预报具有积极的作用。在高CAPE、低CIN的环境下,对流初生具有更好的预报性。用QDA方法验证了,在实现卫星数据和数值模式预报数据融合应用的情况下,CI预报效果更好。
2.4 深度学习在临近预报中的应用
利用深度学习强大的特征提取能力,能够提取对流系统在雷达回波上生消演变特征,进而为预报其生消演变提供有效参考。Shi et al(2015;2017)、Kim et al(2017b)、Wang et al(2017)、郭瀚阳等(2019)、施恩等(2018)、吴昆等(2018)针对雷达回波外推问题,根据对流系统的演变特征,提出相适应的深度学习网络,主要基于卷积神经网络和循环神经网络,自动学习对流系统的回波演变特征(典型深度学习网络结构如图3),实现了雷达回波的外推预报,并具备一定对流系统生消演变的预报能力,检验表明,在TS评分上优于光流法、TITAN等传统外推方法。然而,目前深度学习外推随着时间推移,其空间分辨率呈现明显的下降,回波平滑问题较为严重,一定程度上影响业务应用效果。
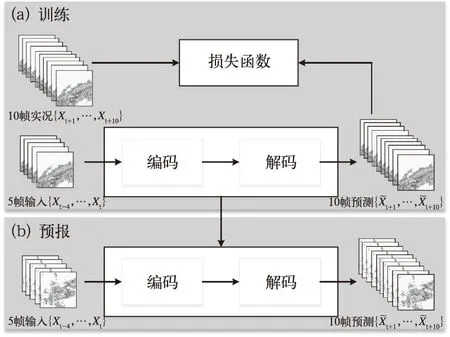
图3 基于深度学习的雷达外推流程(郭瀚阳等,2019)(a)训练过程, (b)预报过程Fig.3 Flow chart of radar reflectivity image extrapolation with deep learning method (Guo et al,2019)(a) training, (b) forcasting
深度学习也可提取VDRAS等快速变分同化分析场中的对流发生发展特征。Zhang et al(2017)基于雷达与实况再分析场,构建了深度卷积网络,实现了对流区(雷达反射率>35 dBz)的有效临近预报,由于算法自动提取了对流系统的时空演变特征,因此也具有对流发展的预报能力。
深度学习在融合多源观测数据进行临近预报方面,也存在巨大的潜力。深度学习能够综合提取多源观测数据中时间、空间上的有效信息。Zhou et al(2020)构建深度学习三维语义分割模型,从雷达回波、卫星云图、闪电密度等观测数据中提取闪电的时空发生、发展特征,实现了有效的0~1 h的闪电预报,且具备一定的对对流生消演变的预报能力。Sønderby et al(2020)构建了深度学习模型Metnet,综合使用卷积、LSTM(long short-term memory)、注意力机制等方法,利用卫星、雷达、降水等观测数据,实现了更长时效(未来0~8 h)的降水预报模型。Metnet预报的时空分辨率可达到2 min、1 km,预测的1 mm降水准确率超过了快速更新同化高分辨率数值模式(HRRR),展示了深度学习方法巨大的应用潜力。
3 机器学习在强对流短时和短期预报中的应用
相对于临近预报中主要使用实时观测数据,短时和短期预报则更专注于数值预报模式的使用。目前,中央气象台强对流短期预报,主观预报使用的主要是“配料法”。该方法由Doswell III et al(1996)提出,在我国有了较多的发展与应用(张小玲等,2010;俞小鼎,2011)。
配料法确定预报的基本构成要素或“配料”,构成要素一般是相对独立的气象变量,给预报员提供了天气预报的清晰思路。基于不同天气的物理模型和“配料法”,中央气象台预报员设计了不同类型强对流天气发生发展的对流环境(水汽、动力、能量等方面)物理参数组合,给出了分类概率预报产品。强对流天气“配料法”等主观预报产品评估表明(吴蓁等,2011;唐文苑等,2017),预报员主观统计提取对流特征并经过“配料组合”得出的强对流预报结果具有较好的有效性和预报能力,但必然也会存在一定的局限性。在观测和模式预报产品越来越庞大的今天,预报员主观分析,提取对流发生发展特征,难度越来越大。因此,有必要利用各种机器学习算法进行上述工作。
3.1 基于探空观测的潜势预报
探空数据能够提供当地的大气层结环境特征,为判断短时预报时效内对流是否发生提供有效依据。Sánchez et al(1998)、赵旭寰等(2009)、陈勇伟等(2013)、杨仲江等(2013)利用探空数据,基于神经网络建立了不同的地区的雷暴或冰雹预报模型,取得了较好的预报效果。Manzato(2013)同样利用探空反演的对流指数因子,构建多个神经网络模型,并用集成学习的思维、Bagging算法,实现集成学习,得到更有效的冰雹预报。
探空数据还能与其他数据进行综合使用。Billet et al(1997),利用探空数据(T850、零度层温度、平均风暴相对入流),结合雷达反演的VIL,构建回归模型,进行对冰雹和直径大于1.9 cm的大冰雹的概率预测。然而探空观测仅能代表当前的大气环境特征,因此预报的时效更短,更长时效的预报则依赖于数值天气预报。
3.2 基于全球数值预报模式的潜势预报
李文娟等(2018)将随机森林算法应用于分类强对流的潜势预测,建立了四分类(短时强降水、雷暴大风、冰雹和无强对流天气)预报模型。选取物理意义明确的对流指数和物理量,开展强对流天气的分类训练,利用实时的NCEP预报场进行预报,结果表明整体误判率为21.9%,85次强对流过程基本无漏报,模型尤其适用于较大范围强对流天气。 Herman and Schumacher(2018)利用NOAA全球集合预报系统数据,构建了随机森林模型,能够实现2~3 d的极端降水预报。为了应对极端降水的极端性,他们不仅将数值预报的对流指数和温压湿风等因子作为预报因子,同时选择了众多背景预报因子。背景预报因子包括1年和10年的格点ARI(average recurrence intervals)最大、最小、中位数值,1年和10年的区域ARI(average recurrence intervals)最大、最小、中位数值,以及经度和纬度值。Liu et al(2019),应用ERA-Interim再分析数据,用贝叶斯方法分析热力和动力因子与高频次闪电雷暴云的相关性,发现CAPE、CIN、底层风切变、暖云厚度等变量与高频次闪电雷暴云最为相关,为高频次闪电雷暴云的预报给予了启发。
3.3 基于高分辨率数值预报模式的强对流天气预报
高分辨率数值模式,具有更高的时空分辨率,能够提供更精细的对流风暴系统结构特征,从而为强对流短时与短期预报提供更多的有效信息。Collins and Tissot (2015) 选取了43个高分辨率数值模式预报的预报因子,训练了18个神经网络模型,其中9个做了特征选择,另外9个包含所有预测因子,展示了特征选取工作的重要性。最终得到预报效果最好的雷暴预报模型,其预报效果媲美于业务预报员。Gagne II(2016)基于CAPS(Center for Analysis and Prediction of Storms)的SSEF(Storm-Storm Scale Ensemble Forecast)集合预报模式,基于决策树算法,构建了方便预报员理解的冰雹预测决策树(图4),能够直观展示通过决策树算法从大量数据中提取的判断流程。Whan and Schmeits(2018) 利用对流可分辨模式HARMONIE-AROME数值模式的大量对流参数作为预报因子,训练了逻辑回归、决策树等模型,实现了荷兰地区的降水预报,结果表明其对于降水量大于30 mm·h-1的短时强降水也具有较好的预报效果。
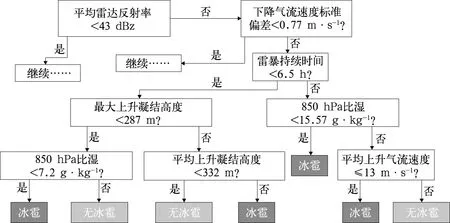
图4 利用决策树算法生成决策树,实现对冰雹的自动化预报(Gagne II, 2016)Fig.4 Visualization of judging process in decide-tree for hail forecasting (Gagne II, 2016)
Gagne II et al(2015;2017)对快速更新的高时空分辨率的数值模式预报做了更精细化的处理,将NWP输出的结果进行了风暴识别,将其识别结果与实况的雷达回波风暴单体进行匹配,然后对其是否发生冰雹进行预测。利用机器学习模型,从风暴的结构特征和对流参数特征,学习风暴单体是否会产生冰雹的特征,进而实现对冰雹的精细化预报。
3.4 深度学习在强对流短时和短期预报中的应用
短时预报可利用深度学习融合实况观测数据和高分辨率数值模式数据。Geng et al(2019)和Lin et al(2019)利用数值预报模式WRF(Weather Research and Forecasting)和闪电观测实况,构建了基于ConvLSTM(convolutional long short-term memory)的深度学习模型,用于提取数值模式数据和观测数据的时空变化特征,进而实现未来6 h或12 h的闪电预报。由于深度学习能够有效综合提取观测数据和数值预报模式数据的信息,因此其预报性能显著优于单纯依赖数值预报模式对流参数化方案的预报效果。而且,综合应用观测数据和数据预报模式数据的深度学习方法预报效果,也明显优于使用单一数据的深度学习方法效果。周康辉等(2021)基于多源观测数据和高分辨率数值天气预报数据的特性,构建了一个双输入单输出的深度学习语义分割模型,使用了包括闪电密度、雷达组合反射率拼图、卫星成像仪6个红外通道,以及GRAPES-3 km模式预报的雷达组合反射率等共9个预报因子。结果表明,深度学习模型能够较好地实现0~6 h的闪电落区预报,具备比单纯使用多源观测数据、HNWP数据更好的预报结果。深度学习能够有效实现多源观测数据和NWP数据的融合,预报时效越长,融合的优势体现的越明显。
短期预报可使用深度学习对全球数值天气预报模型进行释用。Zhou et al(2019)建立了6层的卷积神经网络,应用于分类强对流的潜势预测。利用NCEP再分析资料计算的超过100个对流指数和物理量,开展强对流天气的分类训练。训练好的模型接入实时的NCEP预报场进行预报。结果表明(如表1),其预报效果能够为预报员给出有价值的参考。Zhou et al(2019)基于卷积神经网络的分类强对流预报产品已经成为中央气象台强对流天气预报重要的业务参考产品(张小玲等,2018)。
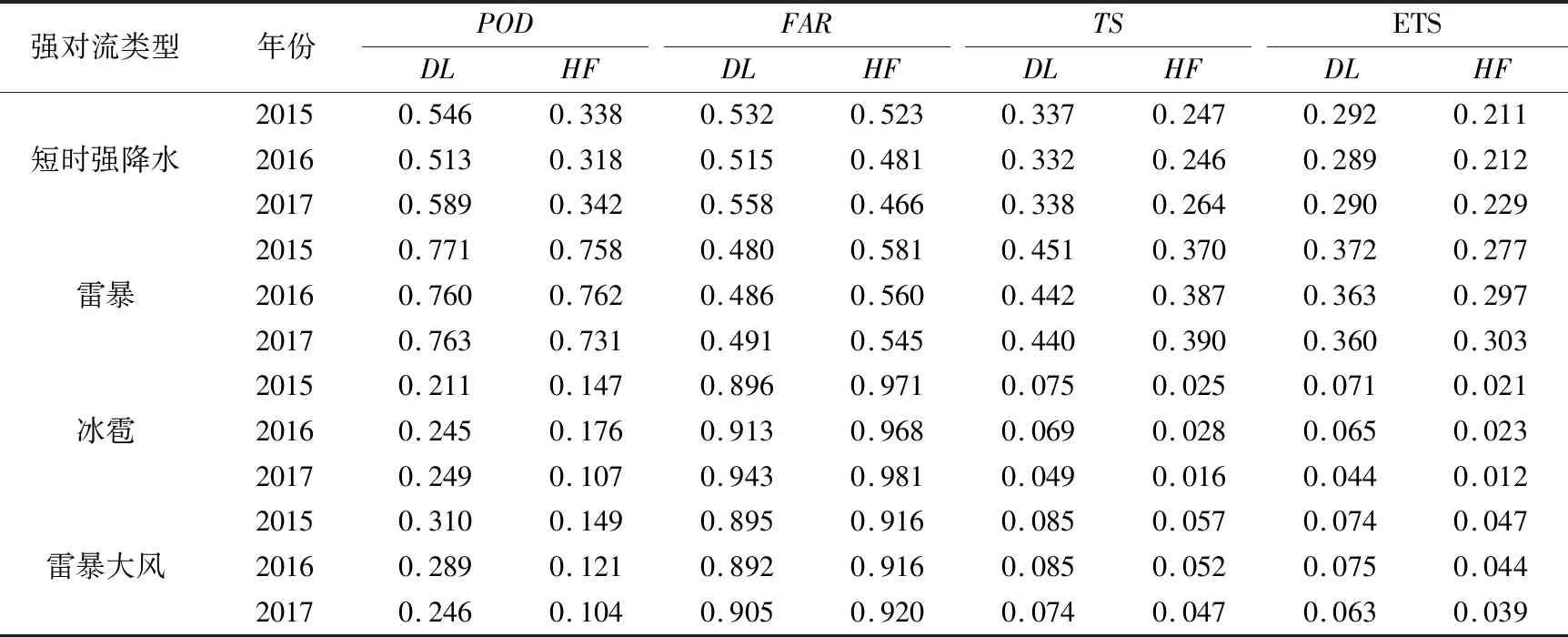
表1 2015—2017年4—9月08时起报的12 h基于卷积神经网络的分类对流潜势预报(DL)和预报员主观预报(HF)的对比情况(Zhou et al, 2019)Table 1 Evaluation of deep CNN (DL) forecasts and human forecasts (HF) from April to September of 2015, 2016 and 2017 (12 h forecast was initiated at 08:00 BT; Zhou et al, 2019)
4 存在的问题和未来发展
目前,机器学习在强对流监测、强对流短时临近预报与短期预报中,已经发挥了重要的积极作用,其应用效果往往优于原有的传统经验和方法。在样本标记充足、标记准确的情况下(如对流云识别、雷达回波外推、闪电预报等),机器学习尤其是深度学习,能够从海量数据中有效提取特征,进而进行有效预报;在样本稀缺且样本标记不确定性较大的情况下(如冰雹、龙卷等极端强对流天气),不管是深度学习或传统机器学习解决此类问题的能力有待进一步提高。总体而言,机器学习目前存在以下问题,未来在以下方面会继续发展。
4.1 存在的问题
(1)相对对流天气未发生(负样本)频率,对流天气的发生(正样本)频率明显偏低。因此存在严重的正负样本不平衡问题。而且,由于对流系统尺度较小,观测网络经常存在漏观测的情况,因此正负样本不平衡的问题进一步突出。目前,有一些相关的算法可解决正负样本不平衡问题,然而对于极端天气事件,其样本不平衡问题仍然非常显著,对于机器学习模型的训练属于一大挑战。
(2)由于机器学习各类算法,本质在于提取特征和标记的相互联系,因此对于特征和标记的质量要求极高。特征和标记的质量越高,其算法分类的效果越好。因此,算法仍然非常依赖观测数据、数值模式预报等输入数据质量。而这些基本数据也是大气科学发展的基础,由此可见,机器学习在大气科学中的应用效果,仍然与大气科学的发展基础息息相关。
(3)在强对流监测预报中,大部分问题可以归为分类问题,如对流云识别、强对流天气识别、对流初生预报、基于数值预报模式的强对流分类预报等。目前从各项研究结果看来,强对流监测预报中的分类问题,应用机器学习算法效果显著(Zhou et al,2019; Wang et al,2018)。降水量预报属于回归问题,应用机器学习方法也有较明显的改进(邵月红等,2009;Meyer et al,2017))。深度学习雷达回波外推也属于回归问题,虽然检验指标优于传统方法,但是始终存在图像模糊的问题(Shi et al,2015;2017),应用效果仍待进一步改进。无监督学习,如聚类算法、主成分分析等,在强对流天气领域应用场景有限。由此可见,借鉴目前深度学习等技术的发展趋势,未来可侧重用分类的思路解决强对流监测预报中的相关问题。
(4)根据“没有免费的午餐定理(No Free Lunch Theorem)”(Wolpert and Macready,1997),没有一种机器学习算法,包括深度学习,能够在所有气象应用场景中都取得最好的应用效果。因此,我们仍然需要全面了解各种机器学习的算法的优缺点,根据使用场景选取最合适的算法。未来,各种传统算法依然会在各自擅长的领域中频繁现身。此外,我们也可以使用多种机器学习算法集成的方法,以达到更好的预报效果。
(5)极端强对流天气事件,比如阜宁龙卷(郑永光等,2016b)、开原龙卷(张涛等,2020;郑永光等,2020)、2017年5月7日广州暴雨(田付友等,2018)等,一直以来,属于天气预报领域的重大挑战。对于机器学习而言,由于极端天气样本极其稀缺,因此,直接构建这样的预报模型可能具有较大的难度。这种大气科学的难题,同样也是机器学习的重要挑战,必须通过熟练使用各类机器学习算法,尝试采用迁移学习等方法对此问题进行研究。
(6)深度学习训练过程涉及到大量的并行运算,因此,目前对于高端GPU显卡或者云计算资源的使用不可或缺。对于深度学习网络,其运算需求往往非常巨大。因此,可以预见,未来高性能计算能力建设中,高性能GPU并行计算能力或者云计算资源的建设应该会加速推进。
(7)目前,机器学习算法可以基于雷达或者卫星观测资料提取对流初生等特征,进行有效的临近预报。然而,其尚不能完全考虑大气运动的基本物理规律,因此短期内不能代替数值预报模式进行基于物理方程的数值预报。
4.2 未来发展
尽管目前机器学习在强对流监测和预报中依然存在一些制约,但机器学习所展示出来的性能表现,表明其在未来应该会成为我们越来越有力的工具(Reichstein et al,2019)。未来机器学习应当会在以下几个强对流天气监测和预报方面进一步发展:
(1)利用机器学习方法进行多源数据的更有效融合应用,从而更好地实现强对流的监测和临近预报。卫星、雷达、闪电、自动气象站等观测数据,各有优势与劣势,如果充分发掘各自的优点,进行综合应用,最大化地体现观测数据的优势将成为未来强对流监测和临近预报的一大挑战。此外,高频次的观测数据还可以与高时空分辨率、快速更新同化的数值模型进行有效融合,实现临近预报到短时预报的无缝过渡。
(2)如果能对风暴的不同阶段的演变特征实现有效识别,将能更好地实现强对流天气的提前预警。可以尝试利用机器学习,进行中气旋、上冲云顶、弓状回波等特征的识别,相对于直接利用天气现象作为标记,对于冰雹、雷暴大风、龙卷等强烈对流天气能起到更加提前的预警效果。
(3)依托数值预报模式,利用机器学习,进行数值模式预报订正和释用,将进一步提升和改进预报水平。数值模式依靠大气运动规律,对大气运行进行计算,而机器学习通常只是拟合预报因子和标记间的相关关系,并不注重其物理规律。将数值模式与机器学习相结合,能实现物理规律和相关关系的更好结合,进一步提升模式预报结果的深度应用。机器学习算法如何与物理规律相结合进一步提升监测和预报能力依然任重道远
(4)利用机器学习可实现强对流规律和物理原理的进一步认识。目前,除了决策树等算法,大部分算法拟合过程犹如“黑箱”,虽然其预报效果较通常的统计方法或者主观方法有所提升,但是其过程通常无法理解。目前,将深度学习特征提取过程可视化,也已经成为一个热点研究方向(Yosinski et al,2015; Rudin,2019; McGovern et al,2019),通过这样的可视化与解释,应当会对气象学者进一步理解中小尺度天气现象有启发。
5 结 论
强对流天气监测和预报一直是气象学中最具挑战的领域之一。为了提升其水平,气象学和相关领域的专家在不断求索,迄今为止已经取得了重大进展(张小玲等,2018;McGovern et al,2017;Haupt et al,2018),但与穷究大气变化规律的终极目标仍很遥远(许小峰,2018)。以机器学习为代表的人工智能的运用,为强对流的监测和应用提供了新的途径和方法(Karpatne et al,2019)。
尽管目前机器学习等人工智能技术在多个行业中的应用都如火如荼,但是机器学习并不是万能的。机器学习在大气科学领域的应用基础仍然依赖于高质量的观测数据、可靠的数值模式预报结果以及深刻的天气原理认识,且要根据不同的应用场景结合物理机理选择合适的机器学习方法。究其本质,机器学习只是一个工具,并不能替代基础天气观测数据、数值预报模式、天气学和大气动力学基础理论发展的研究。在利用人工智能技术发展天气预报技术的同时,也需时刻牢记大气科学基础理论才是强对流天气预报的基础和土壤。
