基于MapReduce模型的并行处理优化策略
2021-04-20王鹏刘鹏刘佳祎
王鹏 刘鹏* 刘佳祎
(1.广西师范大学网络信息中心 广西壮族自治区桂林市 541000)(2.桂林理工大学现代教育技术中心 广西壮族自治区桂林市 541000)
1 引言
随着云计算、容器云、物联网及人工智能等信息技术的迅速发展,以互联网数据中心(IDC)发布得预测为依据,预计全球产生的数据总量在2022年将达到54 个ZB,其中我国占18%,近8060个EB[1]。由于数据的获取技术在不断的更新突破,我们在获取越来越多数据同时,更加重视对数据的管理及治理 。若数据产生量在GB 级和TB 级之间,我们可以通过文件的共享方式如Docker 技术[2]等来进行存储。当数据的产生量达到 PB 级别时,可能会有非常多的不可控因素发生,存储系统的需求也会非常高。云存储[3-4]则满足上述条件不但存储性能高,而且还可以保障数据的安全性,由此利用云存储系统对数据进行存储将成为必然的趋势。
目前很多IT 公司踊跃加入到研发云存储系统的项目中,用以解决自身在公司发展中产生海量数据的存储问题。部分公司逐渐从销售软硬件转向可以为各企业和租户提供按需收费的各类云存储服务。目前相对成熟,已投入商用的云存储平台有如:国外的Google文件系统、Amazon 基础存储服务,及国内的淘宝订单系统,图床的图片存储系统等,同时在国内,一些大公司也开始逐渐向外界推出自己的云存储服务,如华为、百度等[6]。与此同时,以Hadoop的 HDFS[7]和 Open Stack 的 Swift[8]为首的开源云存储平台也随之而来。
云存储技术的核心就是文件的传输,其在传输过程中也是耗时占比相对最重的环节,节省的传输时间可以同时降低物理机和服务器这两方面的使用和功能的消耗。因此本文提出一个利用并行处理技术优化传输过程的新算法用于增加传输效率,同时将传统框架运用到MapReduce 模型中改变其工作运行架构,使Mapper 和Reducer 机制可以同时运行减少时间提高工作效率。

图1:并行处理模块
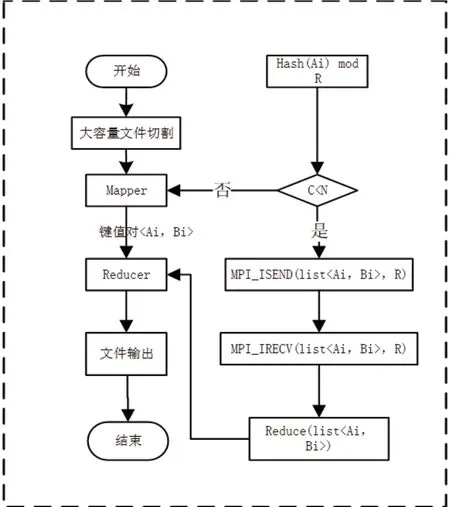
图2:MPI 技术并行化流程图
2 云存储中MapReduce工作运行流程(MapReduce workflow in cloud storage)
建立在分布式环境上的MapReduce 模型在并行处理上有相当大的优势,它不但斟酌怎样调度工作机制实现系统的负载平衡同时还考虑到如何保障数据间的通信顺畅等问题。在MapReduce 进行代码编写时用户完全不用考虑其如何实现,只需了解可以分割数据集的Map 机制和结果汇聚集的Reduce 机制。故用户所提交的务必是可以拆分成很多块的并且能够完成自身计算任务的数据文件。
MapReduce 的作业运行流程步骤[9]:
(1)客户端启动MapReduce 开始作业;
(2)JobClient 向 JobTracker 请求一个作业号;

图3:实验数据分布图
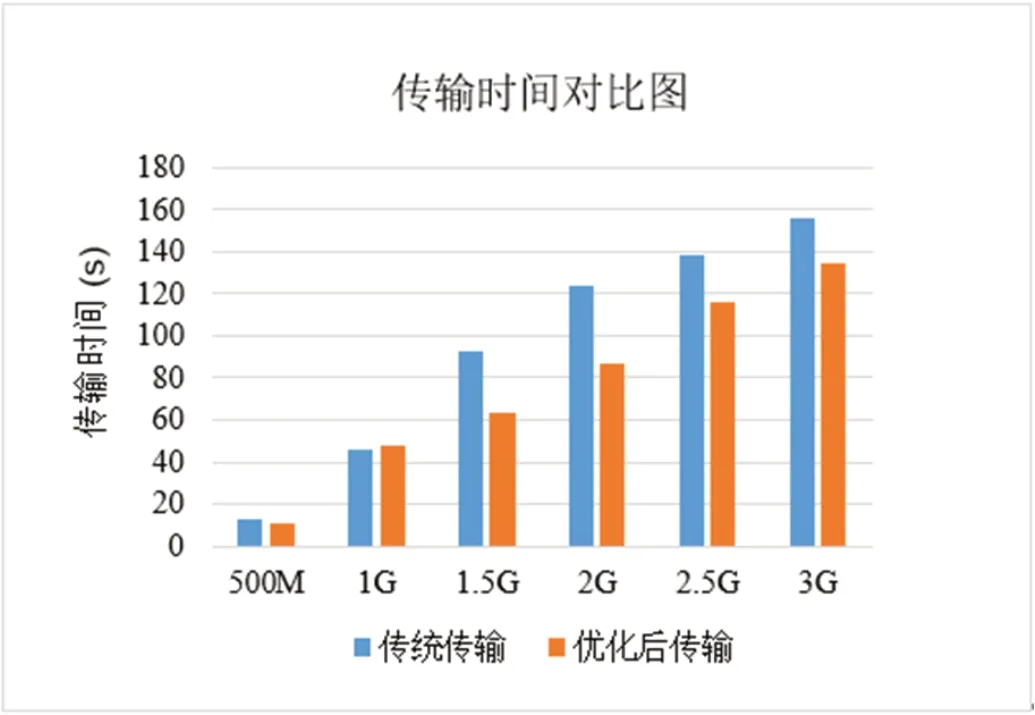
图4:传输时间对比图
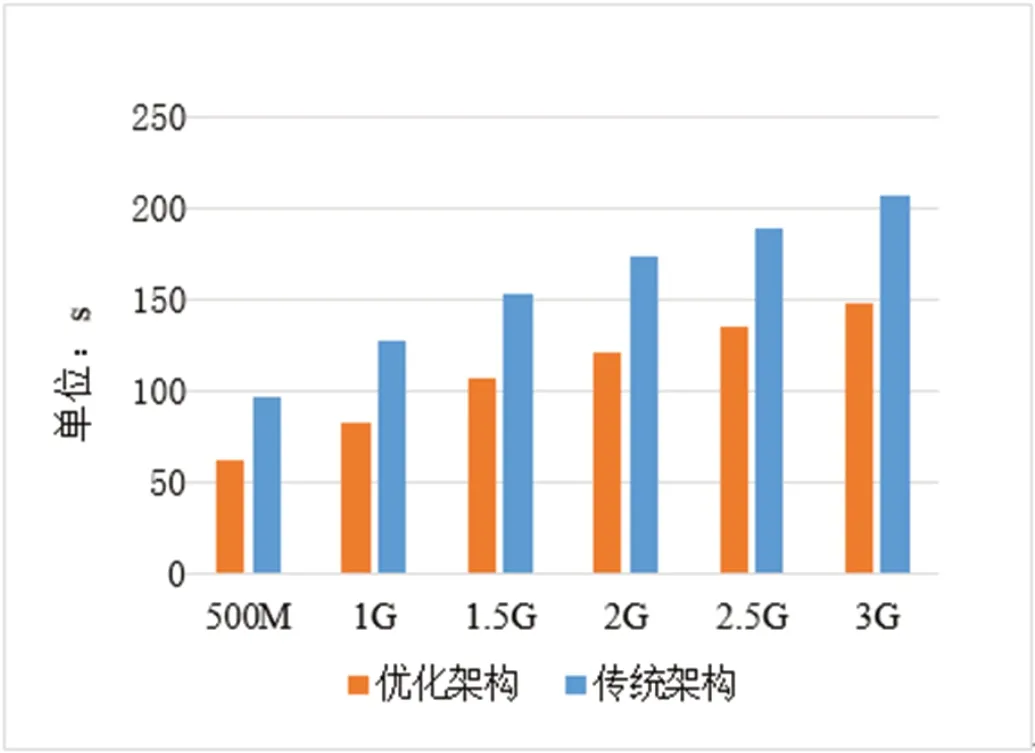
图5:文件计算时间对比图
(3)同步作业所需的各类依赖包及配置文件等,如MapReduce 中JAR 包、配到HDFS 上;
(4)工作调度:运算迁移而数据不动;
由于在Map 端数据是本地化,此时任务将会被分发传到不同的TaskTracker 上。当JobTracker 端接收到相应消息后,依据一定策略排列等待进入作业,并实时动态的采用不同的计算策略进行相应的调度。
(5)TaskTracker 每隔一段时间向 JobTracker 发送一个信号。
3 用于提高云存储效率的MapReduce模型的并行处理优化策略
3.1 云存储中文件传输并行处理算法
针对云存储过程中通常是接收全部的文件包后再打包、解包,这对大批量文件从本地传输到服务器端这一过程来说,该传输过程是耗时最久的而且这种传输也存在效率低等问题。因此,本文提出一种并行处理优化策略。该算法通过设定一个阈值,在打包文件的同时对其进行相应的解包操作,并利用MD5 值验证法[10]对文件的完整性进行验证。由于传输来文件随着时间递增容量不断的变大,因此,在解包的过程中耗时也会逐渐变长,但并行处理优化算法在某种程度上表现出良好的传输效率。并行处理模块示意图如图1所示。
3.2 基于传统框架的MapReduce模型优化策略
3.2.1 MPI 技术并行优化处理MapReduce 模型
本文将使用MPI 技术以Yarn 框架为基底通过对Mapper 和Reducer 进行并行处理来解决Reduce 机制因为Mapper 尚未执行完毕时长时间处于等待准备状态从而形成资源空闲的问题。MapReduce 详细把执行过程进行分解步骤如下:
(1)将文件拆分为多个相对应的
(2)采用map 法对其进行剖析,得到全新的
(3)键值对
(4)在Reducer 中将(3)得到的键值对
本文结合MPI 技术将第2、4 步并行处理,充分将MapReduce的执行效率得到提高。具体流程如图2所示。
由图2可知,系统在进行数据计算时,相应的文件会作出splits 分割,为数据处理在传递过程中做预处理准备,以便结果执行、统计。
4 实验与结果分析
本文根据上述算法提出了可以提升云存储效率的优化方案。该方案将并行完整性算法与优化后的MapReduce 模型相结合,不仅打破传统传输方式的制约还提升了文件传输时的计算效率。为了检测并行完整算法在优化后的MapReduce 模型上在节约传输时间和存储效率是否能够提升,通过在开源数据集(data.gov)上获取的6种不同的数据集,在Ubuntu 14.10 操作系统、hadoop-2.6.0 版本的电脑上以每批次N=10 的打包量将这些数据集传输到HDFS 系统进行实验测试,实验数据分布图如图3所示。
本文通过6 组文件详细对比传统方法与优化方式在传输时间上的变化情况,如图4所示。通过对比图可知,文件存储量在1G 内两者在传输过程中所用的时间几乎相同,在达到1.5G、2G 时传输时间变化尤为明显。与此同时,本文还与传统构架针对不同容量在文件计算时间进行模拟比较如图5。根据图5可知,均在相同的文件容量内优化后的架构用时更加短。
5 结论
在分析当前云存储效率的基础上,提出一种用于提高云存储效率的MapReduce 并行处理优化策略。本文将并行处理技术运用到文件传输过程中,并且提出新的优化算法加快文件存储时间提升传输效率。与此同时本文还将MapReduce 模型进行优化,缩小由于系统顺序制约、存储制约所带来的资源浪费,充分体现系统的高效性。实验模拟结果表示并行完整性算法及优化后的系统架构,用于解决文件传输时间提高传输和计算效率等问题。
